Hadoop2.6.4伪分布式环境搭建
- 1.下载Hadoop
- 2.上传解压
- 3.移动目录
- 4.执行命令vi /etc/profile配置hadoop的环境变量
- 5.执行命令source /etc/profile使配置立即生效
- 6.执行命令hadoop version查看环境变量是否设置成功
- 7.修改hadoop的配置文件
- 7.1修改hadoop环境变量脚本文件hadoop-env.sh
- 7.2修改hadoop核心配置文件core-site.xml
- 7.3修改HDFS配置文件hdfs-site.xml
- 7.4修改MapReduce配置文件mapred-site.xml
- 7.5修改YARN配置文件yarn-site.xml
- 8.格式化文件系统
- 9.启动hadoop
- 10.执行命令jps查看进程,确认是否成功启动
- 11.使用端口访问页面查看hadoop状态
- 12.运行wordcount的MapReduce计算
- 12.1找到hadoop-mapreduce-examples-2.6.4.jar
- 12.2执行命令hadoop jar hadoop-mapreduce-examples-2.6.4.jar
- 12.3查看如何执行wordcount程序
- 12.4上传一个文件到hdfs中
- 12.5查看是否上传到hdfs中
- 12.6运行wordcount
- 12.7查看wordcount运行结果
- 13.停止hadoop
1.下载Hadoop
下载Hadoop,这里选择2.6.4版本
2.上传解压
下载好的Hadoop包使用Xftp移动到/root/Downloads/目录下,解压缩
cd /root/Downloads/
tar -zxvf hadoop-2.6.4.tar.gz![]()
3.移动目录
执行命令mv hadoop-2.6.4/ /usr/local/移动到/usr/local/目录下,为了方便操作可以重命名,此处不再命名
![]()
4.执行命令vi /etc/profile配置hadoop的环境变量
可以用Xftp或直接在虚拟机里查看/usr/local/hadoop-2.6.4/的目录结构,发现hadoop2.6.4的各种运行命令是在sbin文件夹下的,将sbin配置到系统路径上,配置如下:
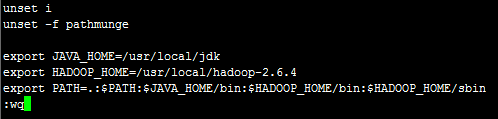
5.执行命令source /etc/profile使配置立即生效
![]()
6.执行命令hadoop version查看环境变量是否设置成功

7.修改hadoop的配置文件
配置文件所在目录:$HADOOP_HOME/etc/hadoop,需要修改4个配置文件。目前的任务是先把hadoop跑起来,以下是安装hadoop伪分布模式的最小化配置。以下四个配置文件的修改可使用Xftp工具选择要修改的文件,右键用记事本编辑,修改保存即可。

7.1修改hadoop环境变量脚本文件hadoop-env.sh
cd /usr/local/hadoop-2.6.4/etc/hadoop/
vi hadoop-env.sh![]()
修改设置JAVA_HOME
export JAVA_HOME=/usr/local/jdk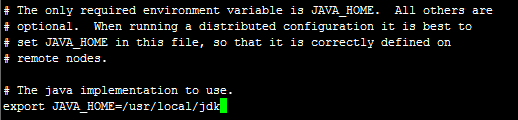
7.2修改hadoop核心配置文件core-site.xml
执行命令vi core-site.xml,修改配置
![]()
<configuration>
<property>
<name>hadoop.tmp.dirname>
<value>/home/hadoop/tmpvalue>
<description>hadoop运行临时文件的主目录description>
property>
<property>
<name>fs.default.namename>
<value>hdfs://cyyun:9000value>
<description>HDFS的访问路径description>
property>
configuration>其中cyyun表示设置的Linux主机名。
7.3修改HDFS配置文件hdfs-site.xml
执行命令vi hdfs-site.xml,修改配置
![]()
<configuration>
<property>
<name>dfs.replicationname>
<value>1value>
<description>存储副本数description>
property>
configuration>7.4修改MapReduce配置文件mapred-site.xml
使用vi命令并按Tab键补全发现其中没有mapred-site.xml
![]()
需要拷贝mapred-site.xml.template并重命名
执行命令cp mapred-site.xml.template mapred-site.xml进行拷贝重命名
![]()
执行命令vi mapred-site.xml,修改配置
![]()
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
<description>指定mr运行在yarn上description>
property>
configuration>7.5修改YARN配置文件yarn-site.xml
执行命令vi yarn-site.xml,修改配置
<configuration>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>solangvalue>
<description>指定YARN的老大(ResourceManager)的地址description>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
<description>reducer获取数据的方式description>
property>
configuration>以上,hadoop配置完成。
8.格式化文件系统
hdfs是文件系统, 在第一次使用之前需要进行格式化 。
执行命令hadoop namenode -format格式化
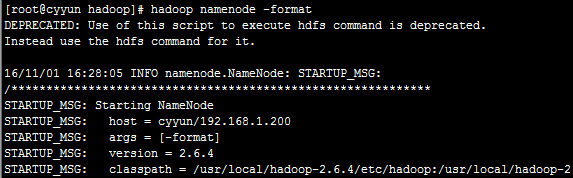
注:只在第一次启动的时候格式化,不要每次启动都格式化。如果真的有必要再次格式化,请先把core-site.xml文件中配置的属性hadoop.tmp.dir目录下的文件全部删除。
9.启动hadoop
使用start-dfs.sh和start-yarn.sh或执行start-all.sh启动hadoop
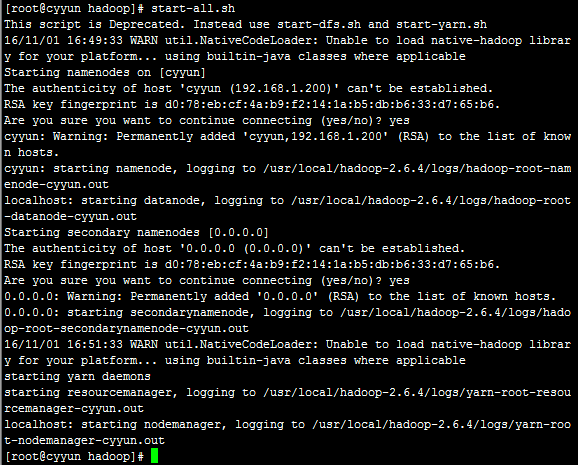
第一次启动需要确认,直接输入yes回车即可。
10.执行命令jps查看进程,确认是否成功启动

若有上面这些进程名称,说明hadoop成功启动了。
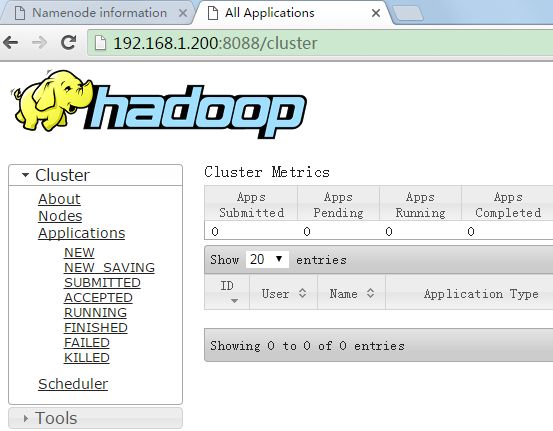
11.使用端口访问页面查看hadoop状态
在Linux系统中配置了主机和ip的映射,浏览器地址使用192.168.1.200:50070(ip:50070)或者cyyun:50070(主机名:50070)都可访问;如果在windows下用浏览器访问,使用ip可直接访问,如果要使用主机名:50070访问,可在C:\Windows\System32\drivers\etc目录下找到配置文件hosts,编辑打开,增加一行内容,和Linux下配置一样。


12.运行wordcount的MapReduce计算
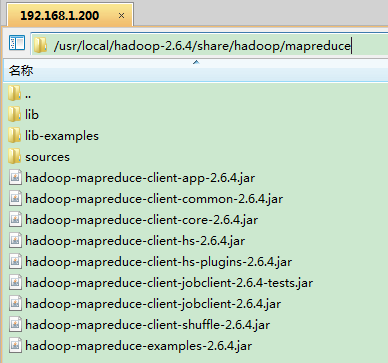
12.1找到hadoop-mapreduce-examples-2.6.4.jar
在$HADOOP_HOME/share/hadoop/mapreduce找到hadoop-mapreduce-examples-2.6.4.jar的jar包
cd /usr/local/hadoop-2.6.4/share/hadoop/mapreduce![]()
12.2执行命令hadoop jar hadoop-mapreduce-examples-2.6.4.jar
执行命令hadoop jar hadoop-mapreduce-examples-2.6.4.jar查看jar中程序的命令

选择wordcount来运行,统计文件中单词的出现次数
12.3查看如何执行wordcount程序
执行命令hadoop jar hadoop-mapreduce-examples-2.6.4.jar wordcount查看如何执行wordcount程序

in和out表示后面要跟输入路径和输出路径
12.4上传一个文件到hdfs中
将$HADOOP_HOME下的README.txt文件上传到hdfs中
hadoop fs -put /usr/local/hadoop-2.6.4/README.txt /
有一个警告,先不管它,不影响正常使用
12.5查看是否上传到hdfs中
hadoop fs -ls /
可以看到刚刚上传的README.txt文件
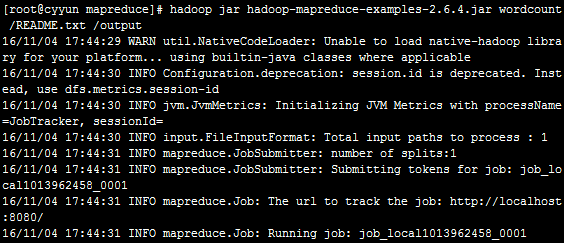
12.6运行wordcount
hadoop jar hadoop-mapreduce-examples-2.6.4.jar wordcount /READEME.txt /output将结果放到hdfs的output文件夹下
12.7查看wordcount运行结果
命令执行结束,运行的结果就会存在输出路径的文件夹中
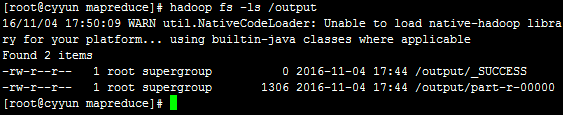
执行命令hadoop fs -ls /查看output输出文件夹有没有生成

执行命令hadoop fs -ls /output查看输出文件夹下执行的结果文件part-r-00000
执行命令hadoop fs -text /output/part-r-00000查看输出内容
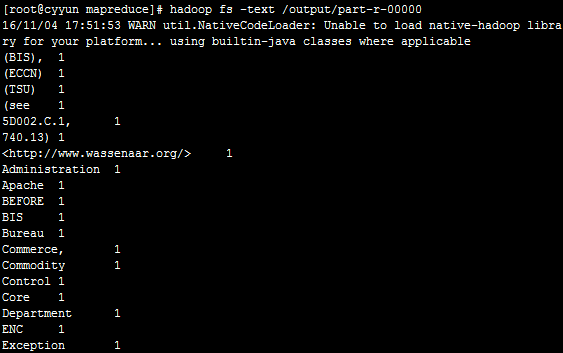
显示结果是按照字符的字段顺序排列的,每一行显示字符及出现次数。
13.停止hadoop
执行stop-all.sh停止hadoop
![]()
jps查看是否停止
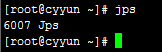
此时hadoop2.6.4的伪分布式模式搭建成功。