使用命令行编译打包运行MapReduce程序 Hadoop2.7.3
网上的MapReduce WordCount教程对于如何编译WordCount.Java几乎是一笔带过… 而有写到的,大多又是 0.20 等旧版本版本的做法,即 javac -classpath /usr/local/Hadoop/hadoop-1.0.1/hadoop-core-1.0.1.jar WordCount.java,但较新的 2.X 版本中,已经没有 hadoop-core*.jar 这个文件,因此编辑和打包自己的MapReduce程序与旧版本有所不同。
本文以 Hadoop 2.7.3环境下的WordCount实例来介绍 2.x 版本中如何编辑自己的MapReduce程序。
Hadoop 2.x 版本中的依赖 jar
Hadoop 2.x 版本中jar不再集中在一个 hadoop-core*.jar 中,而是分成多个 jar,如运行WordCount实例需要如下三个 jar:
- $HADOOP_HOME/share/hadoop/common/hadoop-common-2.7.3.jar
- $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-client-core-2.7.3.jar
- $HADOOP_HOME/share/hadoop/common/lib/commons-cli-1.2.jar
- 实际上,通过命令
hadoop classpath我们可以得到运行 Hadoop 程序所需的全部 classpath 信息。若未将Hadoop路径加入PATH中则使用/usr/local/hadoop/bin/hadoop classpath
编译、打包 Hadoop MapReduce 程序
我们将 Hadoop 的 classhpath 信息添加到 CLASSPATH 变量中,在 ~/.bashrc 中增加如下几行:
export HADOOP_HOME=/usr/local/hadoop
export CLASSPATH=$($HADOOP_HOME/bin/hadoop classpath):$CLASSPATH
别忘了执行 source ~/.bashrc 使变量生效,接着就可以通过 javac 命令编译 WordCount.java (自己手动在/usr/local/hadoop中创建wordcount文件夹,然后文件夹里创建WordCount.java)了(使用的是 Hadoop 源码中的 WordCount.java,源码在文本最后面):
- javac WordCount.java
编译时会有警告,可以忽略。编译后可以看到生成了几个 .class 文件。
使用Javac编译自己的MapReduce程序
接着把 .class 文件打包成 jar,才能在 Hadoop 中运行:
jar -cvf WordCount.jar ./WordCount*.class
打包完成后,运行试试,创建几个输入文件:
Mkdir input
echo "echo of the rainbow" > ./input/file0
echo "the waiting game" > ./input/file1
创建WordCount的输入
如果读者的Hadoop环境已经配置成伪分布式,那么读者还需要进行执行下列操作命令:
要使用 HDFS,首先需要在 HDFS 中创建用户目录:
- ./bin/hdfs dfs -mkdir -p /user/hadoop
教材《大数据技术原理与应用》的命令是以"./bin/hadoop dfs"开头的Shell命令方式,实际上有三种shell命令方式。
1. hadoop fs
2. hadoop dfs
3. hdfs dfs
hadoop fs适用于任何不同的文件系统,比如本地文件系统和HDFS文件系统
hadoop dfs只能适用于HDFS文件系统
hdfs dfs跟hadoop dfs的命令作用一样,也只能适用于HDFS文件系统
- # 把本地文件上传到伪分布式HDFS上
- /usr/local/hadoop/bin/hadoop fs -put ./input input
会把本地的input文件夹上传到HDFS中input文件夹中,即/user/hadoop/input/input/*。
开始运行:
/usr/local/hadoop/bin/hadoop jar /usr/local/hadoop/wordcount/WordCount.jar WordCount input/input output
使用自带的wordcount
1.找到examples例子
我们需要找打这个例子的位置:首先需要找到你的hadoop文件夹,然后依照下面路径:
/hadoop/share/hadoop/mapreduce会看到如下图:
hadoop-mapreduce-examples-2.2.0.jar
第二步:
我们需要需要做一下运行需要的工作,比如输入输出路径,上传什么文件等。
1.先在HDFS创建几个数据目录:
hadoop fs -mkdir -p /data/wordcount
hadoop fs -mkdir -p /output/
2.目录/data/wordcount用来存放Hadoop自带的WordCount例子的数据文件,运行这个MapReduce任务的结果输出到/output/wordcount目录中。
首先新建文件inputWord:
vi /usr/inputWord
新建完毕,查看内容:
cat /usr/inputWord
将本地文件上传到HDFS中:
hadoop fs -put /usr/inputWord /data/wordcount/
可以查看上传后的文件情况,执行如下命令:
hadoop fs -ls /data/wordcount
可以看到上传到HDFS中的文件。
通过命令
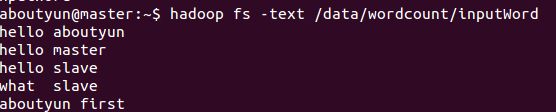
hadoop fs -text /data/wordcount/inputWord
看到如下内容:
下面,运行WordCount例子,执行如下命令:
hadoop jar /usr/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.2.0.jar wordcount /data/wordcount /output/wordcount
可以看到控制台输出程序运行的信息
查看结果,执行如下命令:
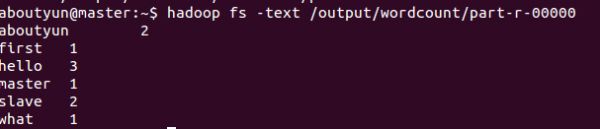
hadoop fs -text /output/wordcount/part-r-00000
结果数据示例如下:
登录到Web控制台,访问链接http.//master:8088/可以看到任务记录情况。
WordCount.java 源码
文件位于 hadoop-2.7.3-src\hadoop-mapreduce-project\hadoop-mapreduce-examples\src\main\java\org\apache\hadoop\examples 中:
/*** Licensed to the Apache Software Foundation (ASF) under one* or more contributor license agreements. See the NOTICE file* distributed with this work for additional information* regarding copyright ownership. The ASF licenses this file* to you under the Apache License, Version 2.0 (the* "License"); you may not use this file except in compliance* with the License. You may obtain a copy of the License at** http://www.apache.org/licenses/LICENSE-2.0** Unless required by applicable law or agreed to in writing, software* distributed under the License is distributed on an "AS IS" BASIS,* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.* See the License for the specific language governing permissions and* limitations under the License.*/package org.apache.hadoop.examples;import java.io.IOException;import java.util.StringTokenizer;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.Reducer;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import org.apache.hadoop.util.GenericOptionsParser;public class WordCount {public static class TokenizerMapperextends Mapper<Object, Text, Text, IntWritable>{private final static IntWritable one = new IntWritable(1);private Text word = new Text();public void map(Object key, Text value, Context context) throws IOException, InterruptedException {StringTokenizer itr = new StringTokenizer(value.toString());while (itr.hasMoreTokens()) {word.set(itr.nextToken());context.write(word, one);}}}public static class IntSumReducerextends Reducer<Text,IntWritable,Text,IntWritable> {private IntWritable result = new IntWritable();public void reduce(Text key, Iterable<IntWritable> values,Context context) throws IOException, InterruptedException {int sum = 0;for (IntWritable val : values) {sum += val.get();}result.set(sum);context.write(key, result);}}public static void main(String[] args) throws Exception {Configuration conf = new Configuration();String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();if (otherArgs.length != 2) {System.err.println("Usage: wordcount" System.exit(2);}Job job = new Job(conf, "word count");job.setJarByClass(WordCount.class);job.setMapperClass(TokenizerMapper.class);job.setCombinerClass(IntSumReducer.class);job.setReducerClass(IntSumReducer.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);FileInputFormat.addInputPath(job, new Path(otherArgs[0]));FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));System.exit(job.waitForCompletion(true) ? 0 : 1);}}