Deep Learning for Intelligent Wireless Networks: A Comprehensive Survey
Deep Learning for Intelligent Wireless Networks: A Comprehensive Survey
基于智能无线网络的深度学习:全面调查
摘要
As a promising machine learning tool to handle the accurate pattern recognition from complex raw data, deep learning (DL) is becoming a powerful method to add intelligence to wireless networks with large-scale topology and complex radio conditions.
作为一种很有前途的机器学习工具,机器学习可以从复杂的原始数据中处理精确的模式识别,机器学习成为一种强有力的方法来为具有大规模拓扑结构和复杂无线电条件的无线网络添加人工智能。
- wireless networks 无线网络
DL uses many neural network layers to achieve a brain-like acute feature extraction from high-dimensional raw data.
深度学习使用许多神经网络层来实现从高维原始数据中提取类似大脑的确切特征。
It can be used to find the network dynamics (such as hotspots, interference distribution, congestion points, traffic bottlenecks, spectrum availability, etc.) based on the analysis of a large amount of network parameters (such as delay, loss rate, link signal-to-noise ratio, etc.).
基于分析大量的网络参数,例如如延时、损耗率、链路信噪比等,可以发现网络的动态特性,例如例如热点、干扰分布、拥塞点、交通单元、频谱可用性等。
- network parameters 网络参数
- dynamics 动态特性
Therefore, DL can analyze extremely complex wireless networks with many nodes and dynamic link quality.
因此,深度学习可以分析多节点,动态链接质量及其复杂的无线网络。
This paper performs a comprehensive survey of the applications of DL algorithms for different network layers, including physical layer modulation/coding, data link layer access control/resource allocation, and routing layer path search, and traffic balancing.
本文对不同网络层的深度学习算法做了全面的研究,包括物理层调制编码,数据链路层访问控制资源分配,路由层路径搜索和流量均衡。
The use of DL to enhance other network functions, such as network security, sensing data compression, etc., is also discussed.
文中还讨论了如何用深度学习增加其他网络功能,例如网络安全,传感数据压缩等。
Moreover, the challenging unsolved research issues in this field are discussed in detail, which represent the future research trends of DL-based wireless networks.
更多的是对这个领域尚未解决的具有挑战性的问题也被详细讨论了,这代表了基于深度学习无线网络的未来研究趋势。
This paper can help the readers to deeply understand the state-of-the-art of the DL-based wireless network designs, and select interesting unsolved issues to pursue in their research.
这篇论文帮助阅读者深入理解目前基于深度学习神经网络的现状,并选择自己感兴趣的未解决问题进行研究。
关键词
Wireless networks, deep learning (DL), deep reinforcement learning (DRL), protocol layers, performance optimization.
无线网络,深度学习,深度强化学习,协议层,性能优化
第一章 介绍
P1
Human…etc.
P2
DL is a subclass of machine learning which uses cascaded layers to extract features from the input data and eventually forms a decision.
深度学习是机器学习的一个子类,他使用层叠层从输入数据中提取特征,并形成最终决策。
- cascaded layers 层叠层
The application of DL should consider four aspects:
(1) How to represent the state of the environment in suitable numerical formats, which will be taken as the input layer of the DL network;
(2) How to represent/interpret the recognition results, i.e., the physical meaning of the output layer of the DL network;
(3) How to compute/update the reward value, and what is the proper reward function that can guide the iterative weight updating in each neural layer;
(4) The structure of the DL system, including how many hidden layers, the structure of each layer, and the connections between layers.
深度学习的应用需要考虑4个方面:
(1)如何用合适的数值格式表示环境的状态,将其作为深度学习神经网络的输入层;
(2)如何表示和解释识别结果,即DL网络输出层的物理意义;
(3)如何计算/更新奖励值,以及在每个神经层中,什么样的迭代函数可以指导迭代权值的更新;
(4)DL的系统结构,包括隐藏层的数量,每一层的结构,以及层之间的联系。
P3
**Currently, many DL systems are tied with Reinforcement Learning (RL) models , which comprises three parts: **
1) an environment which can be described by some features,
**2) an agent which takes actions to change the environment, **
and 3) an interpreter which announces the current state and the action the agent takes.
Meanwhile, the interpreter announces the reward after the action takes effect in the environment, as shown in Fig. 1. The goal of the RL is to train the agent in such a way that for a given environment state, it chooses the optimal action that yields the highest reward. Therefore, one of the main differences between DL and RL is that the former usually learns from examples (e.g., training data) to create a model to classify data, however, the latter trains the model by maximizing the reward associated with different actions.
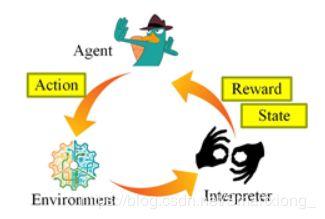
目前,许多DL系统都与强化学习模型绑定,它目前包括三个部分:
1)一个可以用一些特征描述的环境,
2)一个代理采取行动来改变环境,
3)一个解释器,宣布当前状态和代理采取的行动。
同时,当动作在环境中生效后,解释器会公布奖励信息,如图1所示。RL的目标是训练agent在给定的环境状态下选择最高回报的最优行动。因此,DL和RL的主要区别是,深度学习通常从例子中创造一个模型来分类数据,而强化学习通过最大化不同行动的回报来训练模型。
P4
DL has already shown astonishing capabilities in dealing with many real-world scenarios, such as the success of Alpha Go, the face recognition on mobile phones, etc.
Researchers in computer network areas also cast strong interests in DL applications. By using DL model the complex network environment can be represented, abstract features can be obtained, and a better decision can be achieved finally for the computer network nodes to achieve improved network quality-of-service (QoS) and quality-of-experience (QoE).
深度学习在处理真实场景时已经展现出惊人的能力,例如Alpha Go的成功以及手机上的人脸识别等。计算机网络领域的研究人员也对DL应用产生了浓厚的兴趣。使用DL模型可以表示复杂的网络环境,获得抽象特征,最终为计算机网络结点做出更好的决策,以实现改进的网络质量服务和体验质量。
P5
Wireless networks yield complex features, such as communication signal characteristics, channel quality, queueing state of each node, path congestion situation, etc.
On the other hand, there are many network control targets having significant impacts on the communication performances, such as resource allocation, queue management, congestion control, etc.
To handle the complicated situations, machine learning technique has been extensively explored . Chen et al. presented a comprehensive summary towards the ML applications in wireless networks, including wireless communications and networking using Unmanned Aerial Vehicles (UAVs), wireless virtual reality, mobile edge caching and computing, spec- trum management and co-existence of multiple radio access, Internet of Things, etc. The applications of ML in these areas present astonishing improvement compared to traditional methods.
无线网络具有复杂的特性,如通信信号特征,通道质量,每个结点的排队状态,道路阻塞情况等。另一方面,很多网络控制目标对通信功能有重大影响,如资源分配,队列管理,阻塞控制等。为了解决这些复杂的情况,机器学习技术已经被广泛的讨论。chen对ML在无线网络中的应用做了全面总结,包括无人机无线通信与组网,无线虚拟现实,移动边缘缓存与计算,频谱管理与多址共存物联网等。与传统方法相比,ML做这些领域有了令人惊讶的改进。
P6
另一方面,对DL更多的需求,以及DL和人脑的相似处,DL与传统方法相比有哪些改进
P7DL与人脑3点相似处
- 对不完整和错误信息的容忍
- 处理大量输入信息
- 作出控制决定的能力
P8此文主要3个贡献
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JGJIEJi2-1593298431928)(C:\Users\YY\AppData\Roaming\Typora\typora-user-images\image-20200611184808753.png)]
- DL在不同层中的应用
- DL在安全和其他网络功能上的优势
- 未来趋势 介绍10个关于DL增强无线网络的问题

P9路线图
- 第二节——为准备讨论DL在无线网络功能中的应用,首先介绍DL的基本数学模型,包括他与通用机器学习和图形学基本框架的关系。
- 第三节——讨论信号干扰和调制分类中基于DL的物理层加强。
- 第四节——数据链接层设计中数据挖掘的重要性,基于DL的增强解释一些典型的MAC设计案例。
- 第五节——基于DL的路由层的路径建立和优化操作。
- 第六节——数据挖掘在安全性和其他网络功能方面的应用
- 第七节——总结了在无线网络研究中广泛应用的数据挖掘平台
- 第八节——提出了接下来需要解决的十个具有挑战性的研究问题
- 第九节——提出了结论
第二章 深度学习基础
深度学习源于机器学习
A.从机器学习到深度学习
一个典型机器学习系统包括三个部分
1)输入层:将预处理后的数据作为系统输入
2)特征提取和处理层:采用单一的数据处理层提取数据样本
3)输出层:根据ML模型的任务,溢出分类,聚类,密度估计或降维的结果
输入到学习系统的原始数据非常多样化,从自然信息如图像、音频和视频,到各种定量的事件描述。虽然学习系统的输入可能不同,但核心数据学习模块要求输入数据具有统一的表单,并根据表单对输入事件进行分类。因此,为了使学习过程能够“识别”输入数据,需要对原始的自然数据进行预处理。需要将原始数据转换成合适的表达式或特征向量,从而为ML 分类系统所接受。这种预处理需要精心设计,以保持原始自然数据与分类相关的特征。数据预处理方案对分类精度有显著影响。机器学习系统通常只有一个隐藏的在输入层和输出层之间的层。这种学习方式系统也被称为浅学习网络,它在一个隐层中提供具有足够隐单元的任意函数逼近器,从输入层学习或多或少独立的特征。例如,Chen等人[20]提出了一种无线地图基于分项列低学习网络学习系统,它使用机器学习方法,利用分割模型和信号强度的模式DAV-assisted无线网络和建构精确结构化无线地图来改善服务覆盖。
相反,大多数深度学习系统在输入层和输出层之间有不止一个隐藏层,其中上层的输入是下层的输出,如[21]-[24]中提出的学习网络。DL技术避免了复杂的输入数据预处理,在输入层和输出层之间设置多个隐藏层,如图3(b)所示。 自然数据以原始形式输入到学习系统中。DL系统然后自动提取适当的表示用于分类或检测目的。从自然数据开始,每一层从输入数据中提取不同的特征逐步放大与决策更相关的特征
制作和压制无关的特征。每一层都与相邻的层相连,并附加不同的权重的连接。为了确定权值,大量的样本被发送到系统用于训练目的,这可以是监督学习或非监督学习。在监督学习中,对每个权值计算一个梯度向量,表示误差随权值变化的量。根据梯度向量对权值进行调整,减小误差。

B.深度学习框架
人类利用强化学习和层次感知处理系统相结合的方法, 自发地与环境进行交互作用,完成物体识别[25]、调节和选择[26]等任务。在动物行为的启发下,深入强化学习被提出并引起了计算机智能领域的广泛关注。DL模型包括两个关键元素:前向特征抽象和后向错误反馈。培训过程通常需要这两个元素,而验证过程只实现前者。
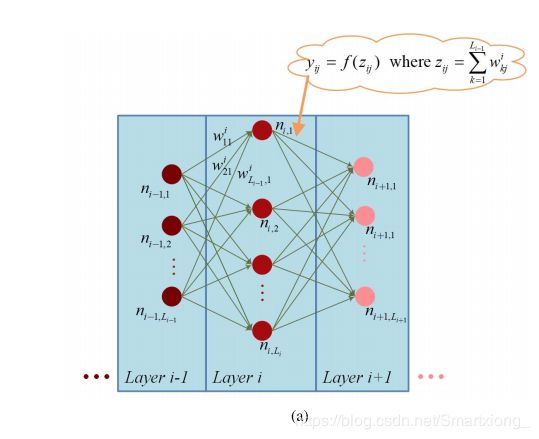
前部特性抽象:假设有N个层的DL网络如图4所示。对于层i中的j个节点,记为nij,通过两步得到输出。节点nij首先计算其所有输入的加权和,记为Zi j,然后将Zi j发送给非线性函数f(),得到节点nij 的输出Yij。

wjk是节点ni - 1,k到节点ni j的权值,Li- l为第i- 1层的节点数。对于非线性函数f()的选择, 直线单元(ReLU) f (z) = max (O, z),即双曲正切函数[e xp(z) + exp(- z)],其中logistic函数f (z) = 1 /[1+ exp(- z)]是比较流行的选择[7]。
反向误差反馈:初始权值为随机值或经验值。为了提高学习系统最终输出的精度,这些权值通过向后误差反馈技术进行调整。即反馈分类精度,并根据分类精度对连接权值进行修正。对于最底层的节点,比如节点nNj,误差导数为YNj - tNj,其中YNj和tNj分别是生成的输出和正确的输出。
则下层连接的误差导数为

对于第i层第j个节点(i = 1,2,…, N - 1),首先是计算所有输入(来自更深一层)到节点的误差导数的加权和, 记为aE OYi•j,则下层连接的误差导数为
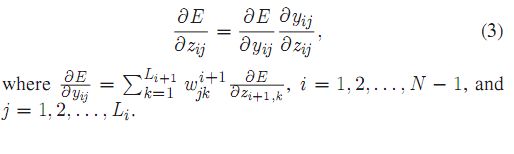

在实际应用中,随机梯度下降(SGD)被广泛应用于[7]中,因为SGD能够以较快的速度找到一组较好的权值。SGD的训练过程是多轮的,每轮训练都是由一小组样本完成的,最终的梯度是每轮的平均值。在一些有用的环境特征可以手工制作,或者环境状态空间低维且可以完全观察的情况下,强化学习的性能是有限的。此外,当使用非林耳函数逼近器来表示奖励时,强化学习往往不稳定甚至发散。针对这些问题,提出了深度q网络(deep Q-network, DQN), 采用了两种新的策略来克服深度学习的能力问题。[27]、[28]回放和迭代更新。在DQN中,代理通过一系列具有目标的动作与环境进行交互最大化累积回报。假设环境在t时刻状态为s, 代理人根据策略采取行动,则环境根据环境转移环概率p在时刻t + 1转移到下一个状态,同时在时刻给予奖励。代理人的目标是累积报酬最大化Qt
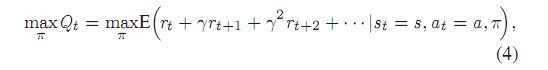
其中γ是未来奖励折扣,因为当前的行为不仅会影响当前奖励,而且会削弱未来奖励。[27]表示奖励
表示为Qt (s, a, 0i),其中0i是Q-network在第i次迭代时的权重。t时刻,代理人的经验,et = (st, at, rt, s+t 1),存储在经验库U(D)中。每次当代理人在学习过程中需要采取某个动作时,代理人会随机选择存储的经验的一个样本。因此,
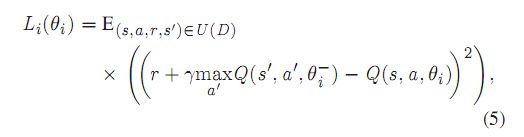
θi为第i次迭代时用于计算目标的Q-network的权值,仅更新权值为0。i每c步骤和固定之间的个别更新(c是一个常 数)。每个动作的奖励Q的参数化是由一个神经网络实现的, 其中每个可能的动作都有一个单独的输出单元。因此,对于每一个可能的动作,只有状态表示作为网络的输入,产 生特定动作的预测Q值。
DQN的一个经典应用是视频游戏(Atari 2600)[27],如图5所示。对于瞬间t,状态为游戏截图,记为Xt。(注意,观察者无法访问游戏的内部状态。相反,只能看到屏幕。)雅达利的行动是操作模拟器,表示在,和游戏奖励分数获得由于行动,表示与充分观察,学习策略的状态输入DQN即时t 是一个有限马尔可夫决策过程(MDP),指示当前的观测和前面的观察那些行动,如表所示,假设游戏终止在即时t,未来贴现在即时奖励t是Rt = L i t r ni- t。显然,那个代理人的目标是即时t是采取行动,使未来的回报最大化与当前的观察表示和策略1r。
。。。。。。
C.图形结构数据的深度学习
在许多实际应用中,数据往往具有结构特征,节点在空间上或时间上相互连接,或者两者都连接。例如,当预测一个人在厨房的行为时,人与电器之间的互动是通过时间或空间连接的。在这种情况下,考虑到DL框架中节点间的时空关系,我们可以使用基于图的结构来实现良好性能[29]。
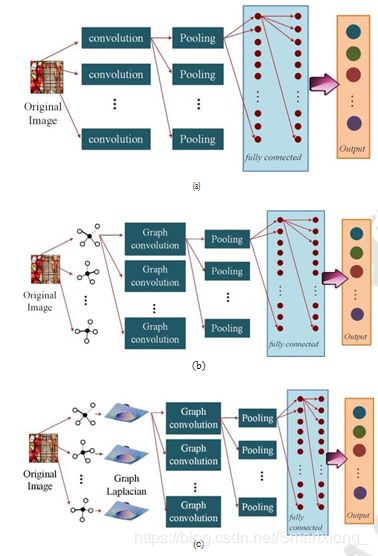
目前,图结构数据通常被推广为卷积神经网络(CNNs)。 一个CNN是一个层序列,每一个层都通过可微函数将一个活动卷转移到另一个卷。通常在CNN架构中有三种主要类型的层,即卷积层、池化层和全连接层。图形导向的CNN和通常的CNN主要的区别在于前者为学习系统中的每一个神经节点建立图像关系,在DL模型中表示图,输入 数据表示为顶点和边,即 G = (V, E, A),其中V表示顶点的集合,E表示边的集合,A是加权邻接矩阵。然后将图单块输入到学习系统中。图DL可以在光谱域进行,也可以在空间域[30]进行。空间方法利用图的空间结构对CNN进行概括,将卷积的本质捕捉为空间上相邻的参数的内积,如图6(b)所示。Bruna等人[31]使用多尺度聚类来定义网络架构,其中为每个聚类定义卷积。然而,对于非网格数据,空间方法往往很难找到位移不变性卷积。为了克服这个问题, Hechtlinger等人[32]提出了一个使用相对距离的空间CNN。节点之间设G = (V, E)为图,其中
第三章 物理层设计中的深度学习
DL在无线网络的物理层(PL)中起着重要的作用。例如, DL可以根据对复杂无线电条件(包括频谱可用性、干扰分布、节点移动性、应用程序类型等)的综合分析,帮助确定最合适的调制编码方案。在接下来的讨论中,我们将提供一些典型的PL函数控制DL应用程序。
A.DL用于干涉对准
干涉对准(IA)目前引起了广泛的兴趣,因为它提高了信道利用率,允许多个收发对通过同一无线电信号进行通信。在多输入多输出(MIMO)网络中,IA采用线性预编码技术对跨任务信号进行对齐,使干扰信号位于每个接收[38]、[39] 的一个降维子空间中。这种发射机与接收机的协调,突破了MIMO天线干扰带来的吞吐量限制。
He等人[40]提出在启用缓存的机会主义的 IA网络中使用deep Q-learning来获得最优IA用户选择策略,如图7 所示。在该方案中,中心调度程序收集每个用户的通道条件和缓存状态,并为每个用户分配通道资源。所有用户都连接到中心调度程序总容量为Cot的回程网络,频道具有有限状态马尔可夫模型的时变特征。每个发送器都配备了一个高速缓存,用于存储大量经常需要的信息。这种网络内缓存设计有效地减少了重复内容的传输。假设有L个候选对象想要加入IA网络,在每个时隙中确定一个动作, 表明根据候选对象当前的信噪比选择哪些候选对象分配通信资源

系统在时刻t的状态定义为
x (t) = {1 (t), c (t), 2 (t) c2 (t)。, ')'L (t), cL (t)},其中Yi (t)和Ci (t)分别表示候选i的通道状态和缓存状态(i = 1,2 ,…系统动作表示为a(t) = {a1(t), a2(t),…, aL(t)} , 其中ai(t) = 0 表示候选i 未被选中作为allo cated通信资源,ai(t) = 1表示被选中。奖励功能被定义为最大化IA网络的吞吐量。如果被请求的内容在本地缓存中,候选被IA提供最大的数据率。但是,如果内容不在候选缓存中,则需要使用一定的带宽进行内容传输。
需要注意的是,该方案需要一个中央调度器,它收集信道状态信息作为深Q网络的输入,并实现资源分配。这种结构引起了整个系统的脆弱性。此外,使用中央调度器是棘手的。
B.抗干扰力DL
在认知无线电网络中,当二级用户(SUs)不自觉地使用无 线网络时。为了加入网络,他们需要1)避免与主要用户(cpu)和2)干扰。扩频是最常用的抗干扰技术之一。然而, 智能的协同干扰器仍然可以屏蔽部分信道并窃听控制信道。
Han等人[41]提出了一种基于深度q学习的、由SUs执行的二维抗干扰方案。它利用频率跳变和SU的移动性来对抗智能干扰,如图8所示。在该方案中,SU执行的动作表示为E{O, 1,…N},式中,当= l, 2,…, N表示SU要访问哪个频率通道(跳频),由于严重的干扰(机动性),SU将离开该地区并找到另一个接入点(AP)。但是,没有明确地说明SU是如何移动的。有效的SU移动策略对于寻找最佳访问点和避免重复请求至关重要。该方案在表I中进行了求和,其中N是频率信道的数量,W是内存长度,r是SU的效用由于决策过程中频道数量大,时间紧,因此我们使用[27] 中使用的卷积神经网络来估计每个动作的报酬,它由两个卷积层和两个全连通层组成(图5)。

C.调制分类DL
调制分类识别所接收信号的调制类型。为了提高复杂调制信号的分类精度,Peng等人提出了一种基于CNN的DL方案。由于不同的调制方法可能会有特定的星座图,本方案利用AlexNet对星座图进行分类,从而明确调制方法。AlexNet 是一个基于CNN的深度学习模型,由数千个neu和数百万个 连接组成,它可以将120万幅图像分成1000个类[4],[43]。仿真表明,该方案能够准确区分QPSK、SPSK、16QAM和64QAM信号,与传统的基于cumu lant的方案和基于支持向量机的方案具有相当的精度。基于dll的调制分类是一个很 有前途的课题。但是,仅考虑星座图的图形模式可能会限制分类效果。通过对图像调制参数的分析,可以提高图像的分类性能。
D. 物理编码DL
此外,深度学习也被用于纠错码。在[44]和[45]中,对 低密度匹配校验码的信念传播(BP)解码算法进行了DL改进。坦纳图在BP译码过程中得到了广泛的应用。然而,建立一 个可用坦纳图的边表示的有效的奇偶校验矩阵是一项具有 挑战性的任务。Nachmani等人[45]给Tanner图的每条边分 配了权值,然后使用随机梯度下降训练这些权值。使用经 过DL训练的Tanner图,大大降低了误码率。在[46]和[47] 中,通过采用训练的译码算法来提高极坐标编码的性能DL。这些作品代表了DL的一个重要应用,即。,学习一种基于结构码的译码网络。此外,DL网络也用于信号检测, 如多输入多输出(MIMO)信号检测[48]、[49]和化学信号检测[50]。利用DL优化的检测模型,可以更准确地推导出传输信号,从而降低误码率。
O’Shea和Hoydis[51]提出了将物理层作为端到端自动编码器的新思想。该编码器包括调制、纠错编码、信号分类等功能。然后自动编码器被训练成一个CNN。该方法已在端到端通信系统、多收发系统和无线电变压器网络中进行了测试。相比交易调制方法(例如,BPSK和QAM)和纠错代码(例如,汉码)autoencoder减少块错误率(提单)通过在多个transmitterrreceiver系统1 - 5倍,并减少在瑞利衰落通信场景1 - 7次的提单(无线电变压器网络)。表二比较了DL在错误校正码和信号检测中的应用。

E. 浅谈DL在物理层中的应用
在无线网络中,考虑到节点数量大、节点的移动性、信道条件的变化和复杂的频率使用等因素,干扰对准和抗干 扰是最棘手的两个问题。DL是处理复杂问题的理想工具, 因为它从混合的大量物理层参数中抽象出了内在模式。此 外,调制和纠错编码是物理层的基本功能,在现代网络中 往往需要大量计算,如正交频分复用(OFDM)调制、网格编 码调制(TCM)、Turbo码、LDPC码等。DL技术可以显著提高这些操作的性能。然而, 由于大多数物理层问题在求解时间上都有严格的限制,因此数据挖掘服务器的使用和计算复杂度的控制是物理层数据挖掘应用的关键问题。
第四章 数据链路层中的DL
A. 频谱分配的DL
LTE-U允许小型基站(SBS)访问unli中心的频谱,从而在无线电频谱利用方面提供了一个有效的解决方案。为了高效、主动地对未授权频谱进行调适,Challita等[52]提出了一种采用强化学习和长短期记忆(RL-LSTM)的LTE在未授权频谱中的资源分配方案(LTE- u)。该方案将时域划分为多个时间窗口,记为t,每个window进一步划分为多个时间epoch,记为t,假设有J个SBSs和M - J个WiFi站。每个节点都有一个LSTM编码器单元,该单元学习一个表示SBS或WiFi站[53]的历史流量负载的向量,如图9所示。所有的LSTMs都包含一个流量编码器。然后,多层感知器(MLP)将所有的历史流量负载向量抽象为一个单一向量,从而得出所有SBSs和WiFi站点的流量值未经授权的渠道。最后,一个动作解码器将抽象向量解释为SBSs的多个预测动作序列。对于SBS j,目标是最大化总数吞吐量,u1,在它与选择的分配的通话时间通道C和时间窗口T,即

式中,a1为SBS j的动作向量,a_1为除j外其他SBSs的动作向量,a1,c,t为SBS j在c通道上可以及时实现的播出时间分数和rj,c,t是一个与通道相关的参数。为了实现优化目标,使用RL算法训练流量编码器和动作解码器的权重, 其奖励被定义为SBS的近似值吞吐量,u1(a1, a_1)。通过对pol icy参数的梯度使期望回报u1(a1, a_1)最大化,可以得到RL神经网络的权值训练有素的[54],[55]。模拟在[56]提供的数据集上运行。与传统的反应性相比,这个方案将为LTE-U分配的平均通话时间增加了约18%。
云无线接入网(RAN)被提议用于未来的蜂窝网络,例如5G, 这是一个集中式的云基于计算的无线电接入网。在运行的云中,云中有一个中央基带单元(BBU)池,用户附近有许多分布式远程无线电头(RRHs)。RRHs只维持基本的传输功能,com按下和转发用户的无线电信号到BBUs通过fronthaul链接。资源分配问题, 即如何在满足用户需求的同时最小化RRHs的功耗,成为云RANs的主要任务之一。为了解决这个问题,Xu等人[57]提出了一种基于DL的RANs节能资源分配方案。该方案通过两步进行决策: 首先,使用deep Q-learning算法确定哪些RRHs应该打开或切换到睡眠状态;其次,利用凸优化算法计算所有主动RRH到用户的波束形成权重。第一步的参数, 即。, Q-learning算法如表三所示。的状态表示
时段t为Bt = (m1, m2,…,先生,首被告,次被告,… du),mi E{0,1}表示第i个RRH是active还是sleep, R为RRHs的总数,d1E [du1 in, d11ax]表示第j个active RRH的需求。在每个时间段内,DRL代理决定哪个RRH是活动的。即时奖励定义为最大可能耗电量Pmax与实际耗电量之间的差距,即。, Pmax - P (A, S, G),为实际功耗P(A, S, G)包括实际功耗和过渡功率(由于睡眠主动开关), 即

弯角,波束形成重量是11从用户RRH r u, rJz的排水效率恒定功率放大器,A, S, G代表的活跃,睡眠和过渡RRH u是用户组,分别和公关,活跃,P r,睡眠和公关,tran sition RRH 功耗的活跃,睡眠和过渡模式,分别。
对于第一步选择的主动RRHs, DRL代理通过求解以下优化问题来计算最优波束形成权值:

其中Ru为用户u要求的数据速率,Pr为RRH r的最大允许发射功率,171= rm (2R…B - 1) (B为信道带宽,rm为依赖于调制的信噪比间隙)。与单一的BS协会相比
结果表明,当需求量较大时,该方案能更好地满足用户的需求。与全协调关联方法相比,该方法功耗更低。
Sun等人[58]提出了一种基于dll的无线资源匹配方案。该方案将资源放入一个“黑箱”中,对DNN进行训练,使每个发射机的功率分配得到优化,使系统吞吐量达到最大。款是完全连接的输入层,多个隐藏层使用修正的线性联合(ReLU)、马克斯(x, 0),激活函数,和出把层使用min (Pmax 马克斯•(x, 0))摄取资源的限制,在切除酶神经节点的输入和Pmax每个发射机的功率预算。拟议的DL-based功率分配方案进行高斯干扰通道(IC)和多单元多址干扰通道(IMAC), 分别是显示最大随机功率分配和功率分配相比,基于DL的方案提供了更高的吞吐量,并比WMMSE [59], DL-based方案的吞吐量接近WMMSE而计算时间要短得多。

Naparstek和Cohen[60]提出了一种深度多用户约束学习方法,以使多用户无线网络的信道效用在较少的计算量和有限的观测量下达到最大。假设有N个用户随机访问K个正交通道。在每个时隙,用户以一定的概率访问一个信道。如果在通道访问期间没有干扰,并且消息被成功接收,一个积极的ACK将被接收
源节点。为优化信道效用,将用户n在时隙t上的动作定义为大小为K + 1的向量,
即。, an(t) =(0,0,…), 0, 1, 0,…, 0),其中单个1表示用户选择的通道。(如果第一个元素为1,则表示没有选择通道。)与此同时,定义作为除用户n之外的任何其他用户的动作。ACK消息作为观察,i。e ., on(t) = 1表示成功交货,on(t) = 0表示失败交货。 对于用户n , 历史记录定义为Hn(t) = (an(l),…, an(t), On(l),…,对(t)), pol icy ern (t)是历史Hn (t - 1)映射到动作an (t)的权重集。累积的折现奖励
用户n的值为Rn = L=-i L 1t - 1 Rn (t),其中Rn (t)是奖励用户n在时隙t时的,它既依赖于(t - 1),也依赖于
a- n(t - 1), 1′为折现因子,为时间持续时间。对于任意的用户,比如用户n,培训的目标是找到一个最大化期望累积回报的策略用户,即。,maxE Rnlcrn -a n用于频谱访问的多用户DQN体系结构 用户n的优化如图10所示。用户的输入是由n的行动(t - 1), 每个通道的能力,和用户的观察n, (t - 1)。一个LSTM采用维持内部状态和聚合observa,由于网络状态是部分观察和 取决于多个用户。由于有些状态是独立于用户行为的,因 此采用决斗DQN来实现准确的判断。V-value DQN估计状态V(sn(t))的平均q值。A值DQN估计每个行动的优势A(an(t))。然后是动作的最终q值an(t)由V(sn(t))和A(an(t))组成。系统的输出是一个大小为K + 1的向量,其中每个元素指示在相应信道中传输消息的估计q值,包括没有传输(由输出的第一个元素确定)。结果表明, 与传统的slotd - aloha方案相比,该方案的平均信道利用率几乎提高了一倍[61]。
大多数基于dll的频谱分配方案首先估计信道条件。基于 与通道相关的参数,一个行动的回报(例如吞吐量、功耗等) 由深度学习系统决定。例如,(11)中使用与信道相关的参 数来计算小基站的吞吐量,Xu等人的在[57]方案中,使用与信道相关的参数计算用户的可达数据率。然而,实际信道可能过于复杂,导致信道估计不准确, 从而对深度训练产生偏差,从而导致频谱匹配决策的恶化。因此,在基于深度学习的频谱分配模型中,对信道条件的准确估计是一个非常关键和具有挑战性的问题。

B. 流量预测DL
现有的资源优化分配方案大多都是在给定的条件下进行的,如流量负载、频谱使用等。然而,Wang等[62]指出,这些因素在时间和空间上都存在显著差异。因此,简单地假设 这些参数值为定值可能会恶化资源分配的效果。为了解决这 个问题,文献[62]提出了一种基于混合DL的时空建模方案来 预测蜂窝网络中的流量。该方案采用一个全局堆叠自动编码器(GSAE)和多个局部堆叠自动编码器(LSAEs)组成的自动编码器模型进行空间建模。同时采用long short-tenn memory units (LSTMs)进行时态建模,如图11所示。当预测一个细胞的流量时,收集细胞本身(红色六边形)和邻近细胞(绿色六边形)的历史数据。每个单元格都有其用于表示编码的LSAE。同时,GSAE获取所有单元数据并生成一个全局表示。将局部表示和全局表示相结合,实现空间建模和预测。将spa模型的输出发送到LSTM进行时态建模和预测。利用该时空模型,计算了一个拥有2844个基站的大型LTE网络的流量(BSs)和覆盖6500公里2的精确预测,和
通过测量均方误差(MSE)、平均绝对误差(MAE)和测井损失等 参数来评价预测性能。与时间序列分析中应用最广泛的自回归综合移动平均(ARIMA)[63]和支持向量回归(SVR)[64][65] 相比,该方法有明显的改进。

为了预测一个细胞的流量,细胞本身及其邻居的流量都被输入到LSAE和GSAE中。相邻区域的大小应在预测精度和计算量之间谨慎把握。在[62]的仿真中,使用了一个11 x 11的正方形作为邻接区域。对于每个单元,考虑其 120个相邻单元的流量。流量预测的另一个棘手问题是时间相关性,它可能在天、周、月和年的范围内具有周期性。
C. 用于链接计算的DL
由于现代网络规模庞大、结构复杂(如多层结构、异构特性、混合网络资源等),网络优化问题往往规模巨大。因此, 降低计算复杂度是一个关键问题。对于基于链路评价的优化问题,Liu等人[66]提出减少问题规模,而不是降低算法复杂度。在他们的方案中,所有虚拟链路的一种可能状态被定义为网络模式(记为set a),目标是通过适当地调度所有模式来最小化总功耗。该优化目标可以通过求解一个线性规划(LP)问题来实现。这里Pa是耗电量模式a, ta是活动时间。但是,由于虚拟链接数量较多,问题规模较大。为了减少问题的规模,作者建议网络的许多虚拟链接不被安排,或者只携带少量的流量。如果将这些环节排除在LP问题之外,计算量会大大减少,而优化目标不会有很大的降低。因此, 我们首先使用深度信念网络(DBN)[67],然后再使用LP模型来评估链路质量。
DBN的输入是流信息,流需求向量X = (x1, x2,…), XN),其中N为网络节点总数。Y中的每个元素Yi表示属于链路i的输入流的概率(i = 1,2,…显然,Yi的值越高,表示这个链接i更有可能被流使用。根据评估结果,不太可能被调度到流程中的链接将被排除在链接优化过程之外。该方法有效地减小了链路优化问题的规模。仿真结果表明,该方案在不降低优化性能的前提下,减少了至少50%的计算量。
D.浅谈DL在数据链路层中的应用
DL在数据链路层的应用大多是资源分配,交通预测,和链接国际化程度的度量问题,产量有前途的性能提高,如表四所示,考虑到现代网络的大尺寸,DL系统通常需要读DLL参数做出决定。因此,如何限制计算量和数据量是DLL中深度学习应用面临的巨大挑战。同时,对信道条件的准确估计对于深度学习系统做出准确的DLL决策至关重要,但由于信道变化快,决策过程的时间限制,这一决策具有挑战性。
第五章 DL在路由层中的应用
为无线网络开发的现代路由协议基本上分为四种类型:基于路由表的主动协议、按需反应协议、地理协议和基于ML/DL的路由协议。基于深度学习的路由协议由于其在复杂网络中的优越性能,在过去几年中得到了广泛的研究。
A.生命感知路由
水下传感器路由通常面临两大挑战,由于使用声信道导致很大的传播延迟,以及高功率占用和充电的不便,也需严格控制用电。为了解决这些挑战,一个均衡的路由协议分配流量均匀的所有传感器,有充足的容量,能量使用高效的生命周期提醒模型被提出,叫做QELAR基于Q-Learning算法。
一段公式和定义。。。。。。
与水下传感器网络中流行的路由协议VBF方案相比,QELAR的生命周期延长了20%。QELAR建立了基于节点间任务间隔的路由拓扑,在链路条件良好的情况下,可以显著提高电池的使用寿命。然而,在现实网络中,节点数据发送缓冲区队列大、机动性强、信号强度弱、干扰等因素会影响链路质量。链路质量的下降会降低端到端传输质量,增加分组重发。结果导致电池的寿命缩短。因此,考虑其他因素和任务平衡可能是一个很好的路由策略,特别是当无线网络很大或负载很重时。
B. 深度学习用于路由路径搜索
在许多网络中,路由器的情况随时变化,包括饱和的缓存,过载的路由器,故障的硬件,等等。这些因素都可能导致路由器性能的恶化。在一个有许多路由器的网络中,数据转发能力在每个时隙在每个局域网络区域中都是不同的。
由于通信会话可能涉及许多从源到目的地的多次跳转,在高度动态的网络环境中,路由算法面临着在众多候选节点之间寻找全局最优路径的巨大挑战,有些节点在提供良好的局部传输性能的同时,会降低全局端到端路由性能。
寻找全局最优路径需要大量的计算量。深度学习是一种有效的缓解路径搜索负担的方法。
Kato等人提出了一种用于异构网络中流量控制的深度学习方法。首先,传统的路由协议如开放最短路径优先(OSPF)在网络中执行,以提高网络性能。一旦收集了足够的参数,就会实现一个有监督的训练过程。在训练阶段,每个节点训练M个模型,其中M为整个网络中潜在接收机的数量。训练过程由贪婪的分层训练方法初始化,并由反向传播算法进行微调。一旦训练完成,就可以在运行阶段找到最佳路径。为了找到从源到目标的最优路径,源节点需要运行深度学习模型k轮,其中k是源到目标的跳数。对于每一轮,网络中所有路由器的流量模式历史作为输入,只选择一个路由器作为输出。
图13给出了一个示例。假设整个网络中有10个路由器,源节点为n1 ,目的节点为n10。运行阶段的第一步是找到紧挨着源的最佳路由器。要做到这一点,DL模型DL1,10 由n1 运行。DL1,10的输入为向量A = [a1, a2,…a10]在输出端,每10个路由器中选择一个路由器,表示源选择的路径上的第一次跳转,在这个例子中就是n3。然后,节点n1运行模型DL3,10来查找第二跳节点。重复此操作,直到到达目标节点。与OSPF 相比,该方案减少了约70%的路由开销,提高了约2%的吞吐量。显然,不需要中央控制器来实现基于深度学习的路由算法,增强了灵活性。
然而,源节点需要训练许多DL模型,这对每个节点都需要巨大的计算能力和存储空间。Mao等人将该方法与可编程路由器相结合,取得了良好的性能。
C.深度学习用于其他路由性能优化
自然灾害和恐怖袭击可能会破坏通信基础设施。在这些情况下,基础设施设备和无线节点之间的协同工作对于维持有效的通信至关重要。这种混合无线网络的路由设计具有挑战性。Lee提出了一种基于深度学习的路由方案,将连通性作为路由优先级。在他们的方案中,首先使用DL 算法计算,用节点的度数来表示节点的连通性。然后利用Viterbi算法生成考虑节点度的虚拟路由。然后,在混合网络中实现了一个基于ip的路由过程。与AODV、OLSR和ZRP路由协议相比,该方案提高了可达性。需要注意的是,在这个方案中需要路由国家服务器(RIS),它使用深度学习算法和特定的硬件来确定节点的度。
Stampa等人利用深度强化学习优化路由性能,以降低传输时延。DRL网络以流量矩阵作为状态,以从源到目的地的路径作为动作,以端到端延迟的均值作为奖励。该方案只考虑流量矩阵,以流量的带宽请求作为状态,不考虑其他网络因素,如节点队列大小、链路质量等。如果考虑更多的条件,可以进一步优化路由结果。为 了测试表现情况,他们使用OMNET++离散事件模拟器来收集给定流量和路由参数下的传输任务延迟。实验结果表明,与基准路由方案相比,该方案在不同流量强度下的传输时延有显著提高。
Valadarsky等人分别将机器学习和DRL应用于网络路由。在DRL方法中,网络环境由需求矩阵(DM)来描述,其中元素dij表示源节点i与目的节点j之间的流量需求。(i, j= 1,2,…), N, N为整个网络的节点数。DRL的回报是链路利用率。在每个时隙中,代理根据路由策略和DMs选择路由方案。然后DRL系统学习从DMs到路由方案的映射,使折扣奖励最大化。他们的仿真使用了TRPO的开源实现,结果表明,从历史路由方案中学习并考虑需求矩阵和链路利用率,为代理智能选择未来数据转发的最优路由拓扑提供了一种有效方法。
Valadarsky的方案与Stampa的方案有一些相似之处,只是使用了不同的奖励对象。从他们的工作中可以看出,如何选择奖励函数是路由层DL应用的关键问题。根据网络特性和环境特性,设计人员选择最重要的属性进行优化,可以是吞吐量、端到端延迟、链路利用率、流量完成时间等。
D.浅谈DL在路由层中的应用
对于基于深度学习的路由方案来说,集中式路由与分布式路由是一个棘手的选择。这是因为深度学习过程需要大量的参数作为输入来进行决策,同时也需要大量的计算来训练神经网络。如果采用集中式路由策略,应仔细解决三个主要问题。
首先,大量的网络节点的能量状况、队列大小、信号强度等环境数据需要发 送到中央控制器。在这种情况下,环境数据产生的传输负载巨大,过多的开销降低了网络的良好吞吐量。其次,需要在有限的时间内建立路由拓扑。然而,信道环境数据在 传输到中央控制器时可能会延迟,从而导致路由形成的延迟。第三,灵活性较差。运行深度学习算法的中心节点并不总是可用。如[73]提出的路由方法采用集中式DL策略, 在基站中训练DL模型,从而对节点的关联程度进行分类。然而,对于某些自组网络,很难找到具有巨大计算能力和合适地理位置的中央服务器。
另一方面,如果使用分布式路由策略,每个节点(或每个源节点)必须训练几个DL模型。因此,每个节点都需要巨大的计算能力和存储空间。 例如,QELAR[68]和Kato[70]采用了分布式DL策略,其中源节点触发DL过程,使用训练好的模型生成路由拓扑。因此,对于基于深度学习的路由设计,集中式和分布式策略之间的选择是非常复杂的,需要考虑很多因素,如网络结构和规模、路由算法、深度学习方法等。
第六章 DL用于其他网络功能
A.车辆网络调度
B.传感器数据简化
C.硬件资源分配
D.网络安全(流量识别,入侵检测)
第七章 基于DL的无线网络平台实施
DL实现方法丰富多样,其中一些已经在无线网络中实施。 在下文中,给出了DL实现的总结,这些方法已经在无线测试平台中使用。
(1)Matlab神经网络工具箱
(2)TensorFlow
(3)Caffe
(4)Theano
(5)Keras
(6)WILL
(7)定制模型
第八章 研究趋势
为了帮助当前的研究人员识别这一重要领域中尚未解决的问题,本节我们将解释10个具有挑战性的问题,并指出未来的研究趋势。尽管这10个问题并未代表基于DL的无线网络的所有未解决的研究主题,但他们还是对当今流行的无线基础设施有着长远影响,包括认知无线电网络,软件定义网络,露水/云计算,大数据网络等。
A. (挑战1)DL用于传输层优化
拥塞控制是传输层的主要功能。然而现有的拥塞控制方法大多是基于端到端ACK或NACK反馈来间接推断拥塞的发生。例如,TCP使用ACK反馈来推断拥塞事件。最准确的方法是直接分析路由路径中每个节点的队列,精确地确定哪个节点的队列发生了溢出事件,该事件表示该节点的拥塞。
显然,单个节点的队列无法反映整个路径中的拥塞分布。 在不同节点之间执行多队列协同建模以检测“拥塞传播”是很重要的。 例如,在早期阶段,一个节点可能具有非常轻的拥塞(稀疏地发生溢出);然而,多个稀疏的拥塞可以在另一个节点上累积到严重拥塞。 多队列协同建模可以帮助找到这样的累积模式。
特别地,DL可用于执行大规模网络队列分析。 假设每个节点通过带外控制信道向中心节点报告其队列状态(例如大小,输入流量速率,输出流量速率等),然后中心节点可以运行DL来分析队列的数据累积状态 。 例如,它可以找出流量是否在特定节点的队列中累积并且可能导致溢出的概率很高。 DL还可以帮助找到最佳解决方案来缓解拥堵情况。 例如,它可以在大多数时间找
到一个队列相对较小的节点,并且该节点可以接受更高的传输速率; 或者,它可以在RED区域(即,具有拥塞队列的网络区域)中找到另一组节点,以建立备用路径以从主路径转移拥塞的业务。
在上述情景中可以研究许多有趣的研究问题。 例如,我们如何提出一种时间演化的DL算法来检测多队列进化模式? 我们如何定义拥塞阈值,即哪个队列大小是RED区域的良好指示?如何将拥塞控制方案与备用路由路径建立协议集成? 如果拥塞发生在不是邻居的多个节点中,我们如何控制拥塞/非拥塞节点中的流量速率以实现整个路径的平稳流? 等等诸如此类
B.(挑战2)使用DL促进大数据传输
如今大数据应用十分广泛,如大规模智能城市监控,国家医疗管理,空气污染监测等。大数据的无线传输在遥感和恶劣环境中是必要的,而不需要部署电线。 例如,在大城市中,许多移动电话可以将其数据(例如用户轨迹,用户行为,患者医疗保健数据等)发送到附近的无线基站(可以是Wi-Fi接入点,蜂窝网络塔,5G路由器等),最终到达云服务器。
由于以下三个原因,大数据的传输是一项具有挑战性的任务:
首先,没有标准/协议规定无线网络操作可以有效地每秒输送>100T比特的数据。
其次,现有的路由协议不能提供“厚”数据管道来同时每秒输送> 1T数据包。 第三,由于在很短的时间内存在巨大的交通密度,因此网络状态实时监控非常困难(大数据具有4V特征,即体积,速度,准确性和多样性)。
DL是一种很有前景的分析方法。 大数据传输动力学在大流量的路由延迟分析,节点之间的流量平衡和链路访问控制方面。 例如,我们可以使用DL来分析每一跳中巨大流量的时空模式,并找出具有最大数据流量的网络的热点。 通过比较逐跳大流量传输延迟,我们可以了解每一跳的平均链路质量/稳定性,然后可以确定不同链路中的流量分配,以避免可能的流量瓶颈。
此外,还需要研究许多研究问题。 例如,DL如何帮助构建/维护每秒可传输> 1T数据包的厚路由管道? 我们如何应用DL来预测某些跳跃中的链路故障?适当的MAC参数(例如后退窗口大小,时隙长度,RTS/CTS时序等)适应大流量的巨大速度/容量的QoS要求 在一组相邻节点中? 诸如此类
C. (挑战3)基于DL的网络群集
有许多有趣的无线网络群集应用。 一个典型的例子是无人机聚集,即大量的无人机建立各种网络拓扑来完成不同的任务(如环境监测,敌人狩猎,森林火灾控制等)。其他应用场景包括聚集而至海底资源探索海洋资源; 合作性战争机器人等。
蜂群控制中的一个具有挑战性的问题是基于任务和通信要求的节点布局。在网络部署开始时,所有节点都是随机分布的。 那些节点可能具有不同的密度分布(一些地方具有更密集分布的节点,而其他地方可能是稀疏的)。然后问题是:如何引导每个节点的移动轨迹实现两个目标:
(1)形成所需的蜂拥形状;
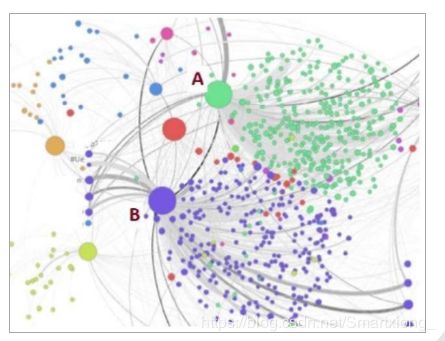
(2)保持良好的沟通架构? 一些节点可能具有比其他节点更强的通信能力,例如,它们可能具有更强大的定向天线,更高的无线电链路速度,更快的CPU速度等。这些节点可以放置在地层中的“桥接”位置(图17中A和B的位置)。 这些桥接位置在蜂拥形状维护以及通信连接增强方面发挥着关键作用。 一旦它们破碎,不同的蜂拥区域就会被隔离。
整个群集网络可以具有不同的群集分布,即,一些群集具有比其他群集更多的节点(更高的密度)。 这使节点放置成为一项艰巨的任务。 应该将哪些类型的节点移动到不同的集群或这些集群之间? 这里可以使用DL来描述拓扑配置文件,例如节点通信/计算容量,到期望的转换位置(对于每个节点)的距离,移动速度等。桥接点可以基于它们的位置加权(即,确定它们的重要级别)。 在不同类型的集群之间。 可以将节点分派到基于拓扑配置文件的那些位置。
D.(挑战4)将DL与软件定义网络配对(SDN Software-Defined Network)
软件定义网络(SDN)通过集中控制极大地简化了路由和交换管理,成为一种有效的网络方案。采用控制面板(CP)和 数据面板(DP)分开管理。CP由一个或多个控制器组成,控制器将流量转发控制规则发送给DP。DP中的流表接受这些规则来执行数据转发函数。在SDN网络中,传统的特定于供应商的路由交换机已经被DP中的通用的、简单的数据转发设备(称为交换机)所取代。DP不运行协议特定的数据链路物理层原型。相反,它们只是简单地解释流表规则,并使 用规则将数据包转发到DP中的下一个交换机。从以上SDN特性可以看出,DL和SDN合作十分完美,有两点原因:
(1)控制面板具有全局网络监控功能。 这是因为数据面板中的每个交换机/路由器可以实时地向CP控制面板反馈其数据转发性能(例如排队延迟,链路速率,丢包率等)。因此,CP控制面板能够构建全局网络配置文件。
(2)CP具有中央控制权。 可以在CP控制器中执行DL以分析网络配置文件并确定DP中的流表的规则变化。
上述场景中存在一些研究问题:首先,我们需要解决网络配置文件的形成问题。 需要从DP收集哪些类型的参数? 什么类型的大数据架构适合于网络配置文件描述,例如,大张量,大图或大时间序列? DL应该用于什么目的,例如路由决策,队列控制或调度控制? 多个CP控制器如何相互协调以实现对整个网络的一致视图? 还有很多其他问题。
E.(挑战5)无线节点的分布式DL实现
虽然DL是一种提取网络动态数据的强大方案,但如果在单个网络节点上运行,可能会带来很大的负担。同时通过降低DL算法的复杂度,可以减轻运行节点的开销。另一种有效的方法是将加载分配到多个节点,使用分布式DL实现。
在使用分布式DL模型时,需要解决一些具有挑战性的问题。
首先,DL算法的哪些部分可以分解为分布式任务?通过将“神经细胞”分配到不同的节点上,可以将梯度神经网络层权值更新算法传播到一组相邻节点上。其次,不同的无线节点如何交换输入参数和输出数据与彼此通过MAC协议?
注意,这样的MAC应该通过使用调度良好的RTSSCTS交换或基于TDMA(时多分址)的传输来最小化通道访问冲突。
第三,哪个节点负责最终的DL输出层组装?这个节点如何保证分布式算法收敛到一个稳定的结果?
F. (挑战6)基于DL的跨层设计
虽然以上部分涵盖了DL应用程序方面的不同个层次,但跨层设计可能是一种更有效的方法,用来充分探索所有层用于长期网络性能优化的信息。事实上,每个层都可以提供许多有价值的性能指标,可用于实现跨层全局网络性能优化。 例如,信道质量,天线波束方向,节点移动性等可用于确定天线的每个波束中的业务分配。 路由选择器逐跳延迟和分组丢失率可用于确定传输层拥塞窗口大小。 可以使用MAC层单跳链路访问成功/失败信息来确定路由路径选择。
DL是融合上述各种跨层指标并提取用于协议优化的内在网络模式的完美工具。 通过使用大张量概念,我们可以将上述度量安排到多类张量记录中,然后应用张量分解来提取基本模式。 这些模式可以告诉我们网络在不久的将来是否会出现严重的数据包丢失,并将网络拓扑分类为热点和轻型流量区域。 模式还可以指示整个网络中的链路干扰分布,并帮助我们避免高干扰区域。
基于DL模式提取结果,不同的层应该彼此协作以执行跨层优化。 例如,如果DL指示一组节点形成高丢包率的“暗洞”,则MAC层应使用更强的FEC来克服该区域中的比特错误; 路由层可以重新建立一条新的路径来围绕这样一个洞; 并且传输层可以使用更小的拥塞控制窗口大小。
G. (挑战7)基于DL的应用层增强
到目前为止,我们还没有对基于DL的应用层(AL)增强进行过多讨论,因为这项调查主要关注核心网络协议设计问题。 然而,从任务要求的角度来看,AL对其他层面有重大影响。 例如,如果我们的任务是向组播用户提供HDTV流,则AL应指定视频流的所有QoS和QoE(体验质量)要求。 然后,较低层可以将这些QoS / QoE参数作为性能目标并调整它们的相应协议操作。
DL可用于根据收集的网络性能参数了解网络状态(参见表VII)。然后DL输出建议的性能目标变化inAL。 例如,如果网络只能提供> 100ms的端到端延迟,则建议AL使用不同的视频编码方法来满足网络限制。
此外,DL可以直接用于提高性能。例如,它可以用来分析网页显示性能(刷新速度、显示速度、图像分辨率等)。它还可以用来进行网络安全分析,以检测垃圾邮件和恶意网站。
这里具有挑战性的问题是基于AL性能目标或应用程序配置文件数据定义低复杂度DL模型,并解决DL问题以生成一系列有用的结果,这些结果可由较低层解释以用于协议操作控制目的。 例如,如果AL具有视频流应用程序,我们如何定义AL模型以将QoS / QoE性能目标转换为具体的拥塞控制和路由参数? 如何将不同的应用程序分类为各种跨层协议设计选项?
H. (挑战8)基于DL的Dew-Fog-Cloud(露雾云)计算安全
我们总结了DL算法在网络安全性中的应用,如入侵检测。 这是一个关键领域,并将继续吸引许多研究兴趣,因为无数新的攻击不断涌现。 在这里,我们想要指出DL将在一个有前途的网络基础设施——露水/雾/云计算的安全性中发挥重要作用。
这种新的网络架构具有以下两个重要特征:
(1)通过计算单元收集数据:大量露水计算设备(如传感器,RFID芯片等)可以在任何地方部署,并通过无线网络连接(例如Zigbee-基于系统)。雾计算基础设施包括一系列远程无线中继,例如Wi-Max节点或手机信号塔,以将聚合的计算数据传送到任何云服务器。
从安全角度来看,上述露雾云架构给对手带来了许多攻击机会。例如,人们可以通过伪造传感器数据来“污染”部分露水计算数据,或者误导雾计算段中的路由路径选择。 声称有更好的道路,等等。
为了处理大规模露水计算源和并发雾计算路由拓扑,DL是解析所有无线节点/链路参数并减少可能的攻击位置和类型的自然选择。 例如,我们可以使用所有露点节点的传感器数据作为样本,并运行基于DL的数据聚类测试以
找出潜在的数据样本中毒攻击。 这里具有挑战性的问题是基于特定的网络安全问题清楚地定义具有适当的输入/输出层解释的DL模型。 不同的安全/隐私问题意味着DL应具有不同的输入/输出/梯度参数更新结构。 例如,隐私保护强调保护敏感数据属性(例如患者姓名),并且可以使用各种ID隐藏模型来定义DL梯度权重更新过程。
I. 挑战9:从DL到DRL:认知无线电网络控制的应用
DL专注于“被动”数据学习,以识别隐藏在数据中的内在模式。 然而,对于每个提取的数据模式,它没有具体的“反应”。深度强化学习使用马尔可夫决策模型来指导基于状态转换模型的不同“动作”的选择。 因此,在许多实际应用中,DRL比DL算法起着更重要的作用。
在这里,我们强调DRL对认知无线网络(CRN)控制的好处。 由于其灵活的频谱接入,CRN是一种重要类型的无线网络,即,节点可以抓取任何可用(免费)频道发送数据,并且如果主要用户(PU)返回使用频道,则可以及时再次腾出频道。
DRL可用于控制以下CRN操作:
(1)频谱感知:DRL模型可用于确定信道扫描顺序。 应首先扫描一些具有较高空闲机会的通道。请注意,如果需要扫描和分析数千个通道,则频谱扫描是一个耗时的过程。 通过首先检查免费频道,我们可以节省频谱感知时间。
(2)频谱切换:当PU返回时,则应切换到其他信道。 信道切换时间和切换到哪个信道是两个至关重要的问题。 我们是否应该等待PU的即将到来的事件来决定频道切换操作,还是我们可以预测PU的传输时间并预先搜索备份频道? 显然,后者具有更好的通信质量,可以避免一些丢包事件。
需要根据各种CRN操作要求明确定义适当的DRL模型。 例如,DRL可以与排队模型集成以确定频谱切换延迟,即,用户可以基于PU流量分析占用现有信道多长时间,以及用户何时应该开始寻找新信道。
J.挑战10实际无线平台中的高效DL/DRL实现
上述DL/DRL算法最终需要在实际的无线网络产品中实现。 然而,由于以下挑战,无法在无线设备中简单地理解纯粹的理论理解:
难以收集DL输入层的网络参数:所有DL算法都需要训练和测试阶段。 在每个阶段,深度神经网络的输入层由数据样本的参数组成。 样本越完整(就数据属性而言),准确地说DL就可以识别网络特征。许多网络参数来自MAC和路由层,涉及许多中继节点的响应。 然而,由于不可预测的链路延迟和无线电干扰,thosenodes可能没有关于其通信状态的快速反馈。 因此,DL模型应设计为容许输入层中的某些参数未命中或数据错误。
无线设备的资源限制:许多无线产品的内存和CPU能力有限。 Theydo不允许将复杂算法编程到现有协议中。 由于DL具有迭代执行性质,因此可以延长系统响应时间。 DL算法应该最小化中间计算参数以保存存储空间,优化算法以减少执行时间。
不完整的培训样本集:DL需要完整或接近完整的培训样本,以准确识别网络模式。 然而,由于难以针对每种可能的网络状态收集如此多的数据点,因此训练样本可能非常有限。 这要求DL在识别新模式失败后应具有添加新样本的能力。 新添加的样本可以提高DL模型的准确性。
此外,网络工程师/程序员应该仔细定义DL数据格式,因为不同的网络参数具有非常不同的数据属性和格式要求。 应明确定义一些适当的数字表示和数据规范化方法,以将多个网络参数聚合到同一DL输入层中。
第九章 结论
本文综述了应用DL方案提高无线网络性能的方法。
(1)由于DLL, DRL具有类似人脑的模式识别能力,因此在智能无线网络管理中非常有用。随着当今无线产品硬件性能的提高, 其采用变得更加容易。
(2)它在 多个协议层中起着关键作用。我们总结了其在物理层、MAC层和路由层中的应用。它使网络更智能地实现整个拓扑结构和链路条件的变化, 有助于生成更合适的协议参数控制。
(3)可与当今各种无线网络方案(包括CRNs、SDNs等)集成,实现资源集中或分布式配置和流量均衡功能。
本文还列举了该领域近期需要解决的十个重要研究问题。它们涵盖了一些有前景的无线应用, 如网络群集、CRN频谱传递、SDN流表更新、dew/fog(露雾计算安全)计算安全等。本文将帮助读者了解最先进的深度学习增强无线网络协议,并发现一些有趣的和具有挑战性的研究课题,以推动这一关键领域的研究。