Java并发——Fork/Join框架原理解析
前言
最近有个哥们问我一个实际项目的问题,大致如下:需要给一个目录下的所有文件的路径生成对应的MD5签名。这个哥们首先想到的是采用递归的方式处理,这个思路是没问题的,但是完全没有必要自己造轮子。因为Java已经提供了成熟的工具可以使用了,那就是Fork/Join并行执行任务框架。基于此契机,本篇文章将记录自己理解Fork/Join框架原理的心得。
在JDK1.7版本中,J.U.C包迎来了新的成员Fork/Join并行执行任务框架。Fork/Join框架的思想其实就是分而治之的思想。
什么是Fork/Join框架?
我们通过Fork和Join这两个单词来理解它。Fork就是把一个大任务分解成若干个子任务,然后并行执行这些子任务,从这里可以看到,子任务是一个独立的任务,它们互不影响但又都是大任务下的一部分;Join就是把这个子任务执行的结果汇总。最终得到大任务的结果。下面这张图就是Fork/Join运行的流程图:
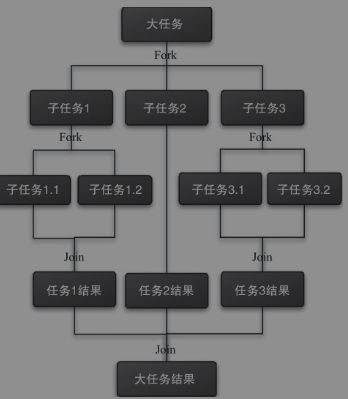
Fork/Join框架的设计思路
基于以上介绍,如果让你来实现一个类似功能的框架,应该怎么来设计呢?借助这个问题的思考来一探Fork/Join框架的设计思路。
分割任务:首先,我们需要一个fork类将大任务分割成子任务,然而,子任务依然可能很大,因此还要继续分割子任务直到任务粒度足够小。
执行任务合并结果:分割的任务分别放到双端队列中,然后启动几个线程,分别从双端队列中获取任务来执行任务,执行的结果放到另一个队列中,由一个线程来合并执行的结果。
在Fork/Join框架中,提供了两个类来完成以上两个步骤。
- ForkJoinTask
在使用Fork/Join框架,必须要先创建一个ForkJoin任务。ForkJoinTask便提供了这个能力,并且提供了fork()和join()的工作机制。通常情况下,我们不需要继承ForkJoinTask,而是继承它的子类来完成我们的实际需求。它有两个子类区别如下:
| 类名 | 说明 |
|---|---|
| RecursiveAction | 用于没有返回结果的任务 |
| RecursiveTask | 用于有返回结果的任务 |
- ForkJoinPool
ForkJoinTask需要通过ForkJoinPool来执行。分割的子任务会被添加到当前工作线程所维护的双端队列中,当一个工作线程的队列中暂时没有任务时,会从其他工作线程的队列尾部窃取任务来执行。
使用Fork/Joink框架
接下来,我们基于以上的介绍来实际使用一把Fork/Join框架来计算1+2+3+…+100。
public class ForkJoinTest {
public static void main(String[] args) throws ExecutionException, InterruptedException {
// 创建ForkJoinPool,指定并发线程数
ForkJoinPool forkJoinPool = new ForkJoinPool(2);
// 创建目标任务
MyAddTask myAddTask = new MyAddTask(1, 100, 20);
// 将目标任务提交到ForkJoinPool执行
ForkJoinTask<Integer> forkJoinTask = forkJoinPool.submit(myAddTask);
// 获取任务执行的结果
Integer result = forkJoinTask.get();
System.out.println("计算结果:" + result);
}
}
class MyAddTask extends RecursiveTask<Integer> {
// 阈值
private int threshold;
private int start;
private int end;
public MyAddTask(int start, int end, int threshold) {
this.start = start;
this.end = end;
this.threshold = threshold;
}
@Override
protected Integer compute() {
int sum = 0;
// 如果粒度足够小,则直接计算
if (end - start <= threshold) {
for (int i = start; i <= end; i++) {
sum += i;
}
} else {
// 否则继续分割任务
int middle = (start + end) / 2;
MyAddTask left = new MyAddTask(start, middle, threshold);
MyAddTask right = new MyAddTask(middle + 1, end, threshold);
// 分割子任务
ForkJoinTask<Integer> leftTask = left.fork();
ForkJoinTask<Integer> rightTask = right.fork();
// 执行子任务计算结果
Integer leftResult = leftTask.join();
Integer rightResult = rightTask.join();
sum = leftResult + rightResult;
System.out.println("子任务合并结果:sum=" + sum + " start=" + start + " end=" + end);
}
return sum;
}
}
执行结果如下:
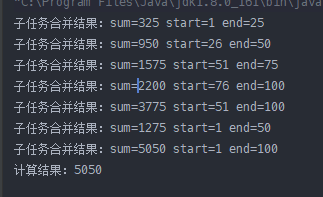
可以看到,最后一个子任务合并的结果总是前两个子任务的结果之和。这说明我们的任务确实被分割了。
Fork/Join框架的原理解析
ForkJoinPool
在上面的例子中是通过new ForkJoinPool();然而这并不是作者Doug Lea推荐的方式。在ForkJoinPool主类的注释说明中,有这样一句话:
A static commonPool() is available and appropriate for most applications. The common pool is used by any ForkJoinTask that is not explicitly submitted to a specified pool.
Using the common pool normally reduces resource usage (its threads are slowly reclaimed during periods of non-use, and reinstated upon subsequent use).
翻译过来的大致意思如下:
ForkJoinPools类有一个静态方法commonPool(),这个静态方法所获得的ForkJoinPools实例是由整个应用进程共享的,并且它适合绝大多数的应用系统场景。使用commonPool通常可以帮助应用程序中多种需要进行归并计算的任务共享计算资源,从而使后者发挥最大作用(ForkJoinPools中的工作线程在闲置时会被缓慢回收,并在随后需要使用时被恢复),而这种获取ForkJoinPools实例的方式,才是Doug Lea推荐的使用方式。代码如下:
ForkJoinPool forkJoinPool = ForkJoinPool.commonPool();
ForkJoinPool提交任务的方式对比
| 方法名 | 说明 |
|---|---|
| invoke(ForkJoinTask t) | 提交任务并一直阻塞直到任务执行完成返回合并结果。 |
| execute(ForkJoinTask t) | 异步执行任务,无返回值。 |
| submit(ForkJoinTask t) | 异步执行任务,返回task本身,可以通过task.get()方法获取合并之后的结果。 |
ForkJoinTask
FOrkJoinTask主要提供了fork()和join()两个方法来分割子任务以及合并子任务计算的结果。这两个方法的源码看似很难,因为其内部有较多的算术运算、位运算与逻辑运算。但如果仔细梳理的话,整体的脉络还是很容易把握的。fork()方法最主要的目的是将fork出来的子任务添加到任务队列中;join()方法最主要的目的是合并子任务执行的结果。
工作线程和工作队列
ForkJoinPool可以处理ForkJoinTask及其子任务之外,还可以处理Runnable、Callable类型的任务。我们先探讨ForkJoinTask下的执行原理。
ForkJoinPool中的工作线程采用的是ForkJoinWorkerThread。它继承了Thread类。内部有两个非常关键的变量如下:
final ForkJoinPool pool; // the pool this thread works in
final ForkJoinPool.WorkQueue workQueue; // work-stealing mechanics
pool表示这个工作线程所属的ForkJoinPool实例;
workQueue表示与这个工作线程对应的待执行子任务队列。
WorkQueue是ForkJoinPool的一个内部类,它并没有像Java中的其他队列那样,继承BlockingQueue提供offer/poll等方法来入队和出队。而是基于双端链表单独实现的,提供了push()/pop()方法来操作,队列中的元素其实就是被分割的子任务。它支持任务窃取,这一切的操作也必须要求是线程安全的,因此内部也大量的应用到了UnSafe基础类来保障线程安全。
工作窃取
为了减少线程之间的竞争,Fork/Join框架会将子任务放到不同的队列中,并且为每一个队列创建一个单独的线程来执行队列里面的任务。线程和队列一一对应。比如线程A负责执行队列1中的任务,线程B负责执行队列2中的任务。有些线程总会提前完成执行,为了提升整体的执行效率,这些先执行完任务的线程会“窃取”其他队列中的任务来执行。这便是Fork/Join框架中的“工作窃取”特性。
异常处理
ForkJoinTask在执行的过程中,可能会抛出以后,但是主线程是无法感知到的,所以没有办法在主线程中捕获异常。ForkJoinTask提供了isCompletedAbnormally()方法来判断它是否抛出了异常。如果判断抛出了以后,则可以通过getException()方法获取到Throwable对象。如果任务被取消了则返回CancellationException。如果任务没有完成或者没有抛出异常则返回null。
总结
本篇文章主要介绍了Fork/Join框架的概念和使用以及实现的原理,源码没有进行仔细的分析,但思路其实就是源码的提现了。Fork/Join框架的这种分而治之思想和大数据领域的MapReduce有着异曲同工之妙。只不过Fork/Join框架是单机版的而已。
