mysql-group_concat函数,将多行记录合并为一行
前景: 今天做一个需求 把A表的ip字段数据更新到B表里面的ip字段;
A表是如果有两个IP地址就存入的是两条记录,例如:(id ip )111 10.1.1.1 111 10.1.1.2
B表是如果有两个IP地址存的是一条记录且用","分隔开;例如: (id ip )111 10.1.1.1,10.1.1.2
涉及:首先要把A表的两条记录合并为一条,且用","隔开,然后直接更新到B表
要用到mysql的group_concat函数,也会讲解concat()、concat_ws()函数的运用
语法:
group_concat这个函数能将相同的行组合起来,完整的语法如下:
group_concat([distinct] 要连接的字段 [order by asc/desc排序字段] [separator'分隔符'])例子:
先查询A表的数据:
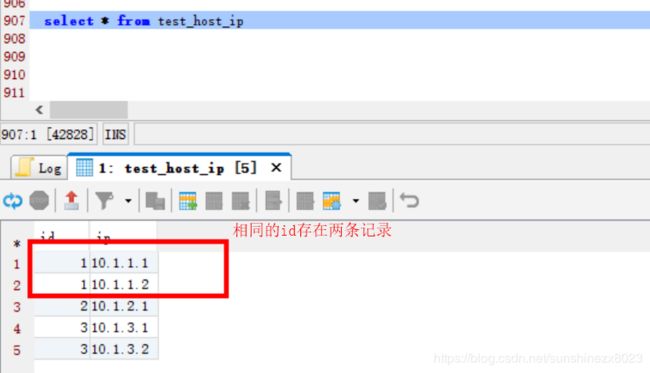
基本查询运用:和里面的distinct、order by 、separator的运用
1.group_concat(字段名) 直接合并ip记录
select group_concat(ip) from test_host_ip结果:我们发现并不是我们想要的结果,因为没有分组,所以他是把所有数据的ip字段都合并在一起了
![]()
2.group_concat(字段名) 添加了group by分组 以id分组 合并ip字段的值(默认以','分隔)
select group_concat(ip),id from test_host_ip group by id
结果:加了group by之后得到了我们想要的结果,所以大家用的时候千万不用忘记你要根据哪个字段进行合并(记得group by奥)!OK!

3.group_concat(字段名 separator ';') 以id分组 合并ip字段的值,以':'分隔
select group_concat(ip separator ':'),id from test_host_ip group by id
结果:我们发现结果就变成了用‘ :’来分隔了

4. group_concat(字段 order by 字段 asc/desc )
select id, group_concat(ip order by ip desc separator ':') from test_host_ip group by id
结果:我们发现ip的顺序已经变了,且是用‘:’分隔

5.group_concat( distinct 字段 order by 字段 desc/asc separator '/')
select id, group_concat( distinct ip order by ip desc separator '/') from test_host_ip group by id
结果:会去掉重复的ip,并以'/'分隔,ip 排序,如果只想去重,不想排序,去掉后面的order by就行,看自己实际的运用

补充:
contact() 函数:将多个字符串连接成一个字符串。
concat(字段, 字段2,...)例子:
select concat(id,ip) as ip from test_host_ip
结果:把id与ip字段拼接成了一个字符串
concat_ws()-concat with separator函数:与concat相比,可以指定分隔符号
concat_ws(separator, 字段1, 字段2, ...)例子:
select concat_ws(',',id,ip) as ip from test_host_ip
结果:把id与ip拼接,并以','隔开(可以自定义设置)

end :给大家贴一下最后的sql,亲测,无问题:
update test_host h inner join (select id, group_concat(ip) as ip from test_host_ip group by id) i on i.id = h.id
set h.ip = i.ip