TensorFlow分布式采坑记
文章目录
- 前言
- 单机单卡
- 单机多卡
- 分布式训练
- 分布式训练架构:parameter server
- 分布式训练策略:模型并行与数据并行
- 模型并行
- 数据并行
- 复制训练: Replicated training
- in-graph replication
- between-graph replication
- 分布式参数配置
- MonitoredTrainingSession
- 异步训练
- 同步训练
- Distributed_mnist
- 加载模型预测
- 容错性
- 定时saver
- 节点挂了
- 后记
- 参考资料
前言
为什么需要分布式训练?简而言之,就是数据量很大、模型参数很大,大到在一台机器上无法执行前向和后向计算,这时候就需要分布式系统来训练更大更复杂的模型。这种模型往往是深度学习模型(废话),而稳坐深度学习框架头把交椅的 TensorFlow 自然会想到这一点,TensorFlow官方从0.8版本开始支持模型的分布式训练,后续版本也不断在优化,现在的TensorFlow支持 单机多卡、多机多卡、同步、异步等训练方式。在这篇文章里,将简单介绍下TensorFlow分布式的基础知识,然后用几个实例(采坑)来演示下在TensorFlow中如何分布式地训练模型,不足之处,还望各位 TF Boys 们轻捶。
单机单卡
在 TensorFlow 中,变量是可以复用的,变量通过变量名唯一确定,变量和计算图都可以和设备绑定。如果一个图计算时需要用到变量a,而变量a不在该设备上,则会自动生成相应的通信代码,将变量a加载到该设备上。
因此变量存放到哪个设备上对于程序的正确性没有影响,但会导致通信开销有所差异。下图展示的代码是一个单机单卡的例子,将参数 w, b 放在 CPU 上,然后将计算过程放在 GPU 上。
def one_gpu():
'''
单机单卡
对于单机单卡,可以把参数和定义都放在GPU上,不过如果模型较大参数较多,全放在GPU上显存不够时
可以把参数定义放在CPU上,如下所示
'''
with tf.device("/cpu:0"):
w = tf.Variable(tf.constant([[1.0, 2.0], [4.0, 5.0]]), name="w")
b = tf.Variable(tf.constant([[1.0], [2.0]]), name="b")
with tf.device("/gpu:0"):
addwb = tf.add(w, b)
mulwb = tf.matmul(w, b)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
val1, val2 = sess.run([addwb, mulwb])
print(val1)
print(val2)
单机多卡
我现在的机器上只有单卡GPU,没办法演示多卡,不过可以看看 tensorflow 官网提供的 cifar10 单机多卡的例子,重点在170行左右。这里我也提供了一个单机多卡的示例,代码也是参考的 cifar10。
这里只讲下cifar10是如何实现单机多卡的,大体思路是每块GPU分别从 data_queue 里去 dequeue 一个 batch 的数据,然后在当前GPU上执行前向计算的过程,并收集这次的所有梯度。当循环到下一个GPU时,该次训练所使用的参数和上个GPU是一样的,代码中体现在tf.get_variable_scope().reuse_variables()这一句。也就是说一次梯度更新前,所有GPU之间是共享模型参数的。然后等所有GPU都收集完梯度后,CPU会统一做一次梯度的平均(grads = average_gradients(tower_grads)),然后用平均梯度去更新参数(opt.apply_gradients(grads,global_step)。需要注意的是这个收集梯度的过程是同步的,必须等所有 GPU 结束后CPU才开始平均梯度的操作,很明显整个模型的训练速度取决于最慢的那块 GPU 卡。整个过程,可以用下图一图以蔽之。
解释下从哪看出 cpu 负责收集梯度然后更新的,从代码开始出可以看到,整个 train 的计算图默认是在 cpu 上的(with tf.Graph().as_default(), tf.device('/cpu:0')),只有前向计算 loss 和计算梯度的过程是被带有 gpu 的 with 块包起来的,这与上图的描述也是一样的,感兴趣的同学可以把代码拉下来,自己跑一遍。土豪可以用多块 GPU 感受下飞一般的速度,中产阶级可以用多 CPU 代替多 GPU,我等屌丝只能望其项背。。
with tf.Graph().as_default(), tf.device('/cpu:0'):
# Create a variable to count the number of train() calls. This equals the
# number of batches processed * FLAGS.num_gpus.
global_step = tf.get_variable(
'global_step', [],
initializer=tf.constant_initializer(0), trainable=False)
# Calculate the learning rate schedule.
num_batches_per_epoch = (cifar10.NUM_EXAMPLES_PER_EPOCH_FOR_TRAIN /
FLAGS.batch_size / FLAGS.num_gpus)
decay_steps = int(num_batches_per_epoch * cifar10.NUM_EPOCHS_PER_DECAY)
# Decay the learning rate exponentially based on the number of steps.
lr = tf.train.exponential_decay(cifar10.INITIAL_LEARNING_RATE,
global_step,
decay_steps,
cifar10.LEARNING_RATE_DECAY_FACTOR,
staircase=True)
# Create an optimizer that performs gradient descent.
opt = tf.train.GradientDescentOptimizer(lr)
# Get images and labels for CIFAR-10.
images, labels = cifar10.distorted_inputs()
batch_queue = tf.contrib.slim.prefetch_queue.prefetch_queue(
[images, labels], capacity=2 * FLAGS.num_gpus)
# Calculate the gradients for each model tower.
tower_grads = []
with tf.variable_scope(tf.get_variable_scope()):
......
从上面单机单卡和单机多卡的例子中,可以知道模型参数或者计算图是可以拆开放到不同的设备上的,不同的设备通过变量名可以共享参数。
分布式训练
重头戏来了,当单机多卡也无法满足训练的速度需求的话,那就需要上分布式,搞多台机器一起训练了,也可以说是多机多卡吧。谈到分布式,必不可少的一个概念就是集群,先来看下TensorFlow官方对集群的定义:
A TensorFlow “cluster” is a set of “tasks” that participate in the distributed execution of a TensorFlow graph. Each task is associated with a TensorFlow “server”, which contains a “master” that can be used to create sessions, and a “worker” that executes operations in the graph. A cluster can also be divided into one or more “jobs”, where each job contains one or more tasks.
翻译一下就是,Tensorflow 集群是一系列分布式执行计算图的tasks, 每一个 task 与一个 server 相对应,一个server 包含 master service 和 worker service。Master service 负责创建 session,worker 负责执行图中的计算操作。一个集群也可以被切分成多个 jobs,每个 job 包含一系列相同功能的 tasks。
为了创建集群,需要在每个task上开启 TensorFlow 的 server,每个 task 通常对应一台机器。然后在每个task上都需要做如下的事情:
- 创建一个 tf.train.ClusterSpec ,来描述集群中的所有tasks。这部分对于所有tasks都是一样的
- 在每个task上创建一个 tf.train.Server ,在构造时候传入tf.train.ClusterSpec ,并且用 job_name 和 task_index 来标识当前task ,这样每个server在启动时就加入了集群的信息,可以和集群中的其他 server通信。需要注意的是,sever的创建需要在自己所在 host 上,一旦所有的 server 在各自的 host 上创建好了,整个集群就搭建好了。
用代码描述一下就是:
# 创建一个tf集群,包含2个job,job1有3个tasks, job2有2个tasks
# cluster接收的其实就是一个字典,字典里面包含了各个task所在host的主机地址
cluster = tf.train.ClusterSpec({
"job1": [
"job1_task0.example.com:2222",
"job1_task1.example.com:2222",
"job1_task2.example.com:2222"
],
"job2": [
"job2_task0.example.com:2222",
"job2_task1.example.com:2222"
]})
# 在机器 job1_task0.example.com:2222 上启动server
server = tf.train.Server(cluster, job_name="job1", task_index=0)
''''''
# 在机器 job2_task1.example.com:2222 上启动server
server = tf.train.Server(cluster, job_name="job1", task_index=1)
好,现在为止出现了几个概念,先来汇总一下,以免大家绕晕:
- cluster,TensorFlow 集群定义,包含一个或多个 jobs,每个 job 被切分成一个或多个具有相同功能的 tasks
- job,一个 job 由一系列相同目的的tasks组成,一个 job 中的 task 通常运行在不同的机器上
- task,一个t ask 完成一个具体的任务,被 job 中的 task_index 唯一标识,通常对应一台机器 ,与一个具体的TensorFlow Server相关联
- TensorFlow Server,运行
tf.train.Server实例的进程,是集群中的一个成员,可以和集群中的其他server 通信,通常包括 master service和 worker service - Master service,一个GRPC service,提供到多个分布式设备的远程访问,表现形式是session.target,master service对应master_service.proto,可以看到里面有 createSession, closeSession等接口。所有的TensorFlow server都实现了master service
- Worker service,一个GRPC service,用指定设备来执行部分计算图操作。worker service对应worker_service.proto,主要作用是在当前设备上执行计算图。所有的TensorFlow server也都实现了worker service
- client,client概念上面没有提到,但是对于下面的内容至关重要,所以放在这里一并介绍了。一个client通常是一段构造TensorFlow计算图的程序,同时构造了一个 TensorFlow session 来与集群交互。说白了前面创建的cluster与server只是搭建分布式环境,真正要执行计算需要创建
client。那么创建session就很简单了,sess=tf.Session() 对吧。But,在分布式环境下可不是这么随意的,对于tf.Session这个类,其第一个参数是target,一般情况下大家确实用不到,因为不指定这个参数的话,Session 就默认调用本地设备,但是在分布式环境就需要指定了,指定的这个值就是server里面的master(server.target提供这个参数)
分布式训练架构:parameter server
上面介绍了,如何创建分布式的环境。下面来介绍下TensorFlow的分布式训练时所使用的架构。我们知道,一般机器学习的训练过程可以分为以下两步:
- 根据已有参数计算梯度
- 根据梯度来更新参数
对于超大规模的训练,数据量大,模型参数多,不仅计算梯度的过程要放到多个CPU或GPU上执行,参数的存储和更新也需要放到多个CPU或GPU上执行,这就需要多台机器来进行计算能力的扩展。在parameter server (参数服务器)架构中,集群中的节点被分为两类:parameter server 和 worker。
其中 parameter server 负责存放模型的参数和更新梯度的操作,而worker负责计算参数的梯度。在每个迭代过程中,worke 节点从 parameter sever 节点中获得参数,再将计算的梯度回传给 parameter server,parameter server 聚合从所有 worker 传回的梯度,然后开始更新参数。整个架构如下图所示,这里只简单介绍下,想要深入理解参数服务器架构,可以看下沐神的这两篇文章,Parameter Server for Distributed Machine Learning
和Scaling Distributed Machine Learning with Parameter Server,这里只抛砖引玉。而且TensorFlow的分布式本身只是采用了 parameter server 的思想,与沐神的PS架构并不完全对等。
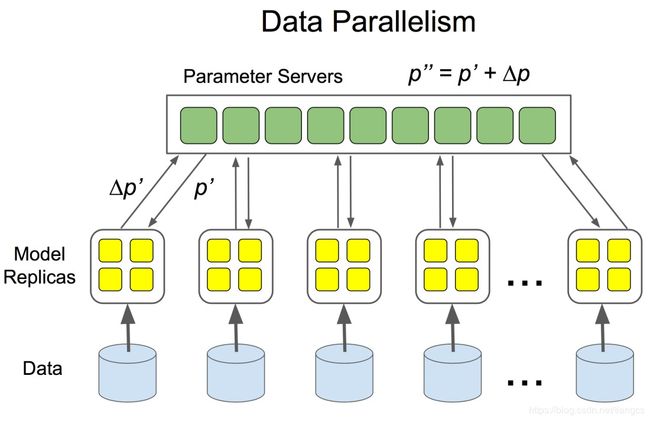
在tensorflow的分布式中,同样也将集群中的节点分为 ps 和 worker 两类:
- ps节点就是参数服务器,简称 ps(parameter server), 负责参数的存储和更新,ps 节点可以不止一个,也可以拿多台机器来充当ps节点。
- worker节点,从 ps 节点上 pull 下最新参数,加载数据,执行计算图,获得梯度,然后将梯度 push 给 PS 节点。
现在再回想下刚才创建 cluster 的过程,不是按 job 划分的吗?那么现在就可以划分为两类 job,ps job 和 worker job,
tf.train.ClusterSpec({
"worker": [
"worker0.example.com:2222",
"worker1.example.com:2222",
"worker2.example.com:2222"
],
"ps": [
"ps0.example.com:2222",
"ps1.example.com:2222"
]})
可以看出,cluster接收的其实就是一个字典,字典里面包含了各个task所在host的主机地址,这个 cluster 共包含两类job:ps和worker,共5个task:
/job:worker/task:0
/job:worker/task:1
/job:worker/task:2
/job:ps/task:0
/job:ps/task:1
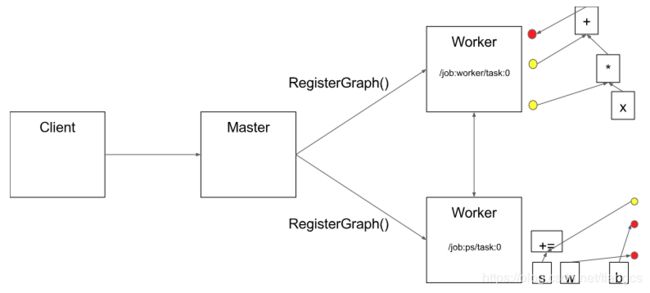
再加上刚才的client概念,就有了下面这两张图,来自TensorFlow Architecture, 上面有一系列这样的图,对理解分布式的概念很有帮助。再来梳理下,client负责创建计算图,然后要跑计算时,先把计算图以及要执行的节点(Graph中的Node)发给master,master负责资源调度(就是这个计算该怎么执行,在哪些设备执行),最终的执行需要各个worker进程去做(使用本地设备执行计算),所以每个 server 会包含master和worker两个部分。

上面简单介绍了下如何创建分布式环境、server和client等一些基本概念、还有深度学习中常用的ps架构。在单机单卡和单机多卡的例子中,还知道了可以指定具体的设备来存储参数,那么如何在分布式的环境中把这些整合起来呢?由于创建分布式集群的过程对于每个节点都是一样的,然后每个 server 要到各自的机器上去启动,所以一般通过命令行的方式传入 ps 的 hosts 和 worker 对应的 hosts,看下面的示例代码 (完整代码在此):
import tensorflow as tf
tf.app.flags.DEFINE_string("ps_hosts", "localhost:2222", "ps hosts")
tf.app.flags.DEFINE_string("worker_hosts", "localhost:2223,localhost:2224", "worker hosts")
tf.app.flags.DEFINE_string("job_name", "worker", "'ps' or'worker'")
tf.app.flags.DEFINE_integer("task_index", 0, "Index of task within the job")
FLAGS = tf.app.flags.FLAGS
def main():
'''
这些代码对与所有server都是一样的
'''
ps_hosts = FLAGS.ps_hosts.split(",")
worker_hosts = FLAGS.worker_hosts.split(",")
# create cluster
cluster = tf.train.ClusterSpec({"ps": ps_hosts, "worker": worker_hosts})
# create the server
server = tf.train.Server(cluster, job_name=FLAGS.job_name,
task_index=FLAGS.task_index)
server.join()
if __name__ == "__main__":
main()
这里使用 localhost 环境模拟多机环境,假设上述代码在 example.py 文件中,在本地分别执行下面三个命令启动三个 server
nohup python example.py --job_name=ps --task_index=0 > ps0.log &
nohup python example.py --job_name=worker --task_index=0 > worker0.log &
nohup python example.py --job_name=worker --task_index=1 > worker1.log &
现在分布式环境已经成功运行了,集群中有1个PS,2个worker在跑。且三个server都处在等待状态,现在创建一个 client 来执行一个计算图。上面已经说过了,创建 session 的时候,默认是使用本地设备,但是在分布式环境下,可以使用某个 server 对应的 target 来创建 session, 这里使用worker0这个server对应的target,即 “grpc://localhost:2223” 来创建 Session,如下所示,完整代码在example_distributed_client.py
import tensorflow as tf
if __name__ == "__main__":
# 指定设备:格式,/job:job_name/task:task_index/gpu:gpu_index
# 参数存储在ps节点上
with tf.device('/job:ps/task:0/cpu:0'):
input_data = tf.Variable(
[[1., 2., 3.], [4., 5., 6.], [7., 8., 9.], [10., 11., 12.]],
name="input_data")
b = tf.Variable([[1.], [1.], [2.]], name="w")
inputs = tf.split(input_data, 2)
outputs = []
# 使用worker0对应的session创建计算图
with tf.Session("grpc://localhost:2223") as sess:
init_op = tf.global_variables_initializer()
sess.run(init_op)
# 2 means 2 workers
for i in range(2):
# 把计算任务放到GPU上执行,对应实际中计算梯度的过程
with tf.device("/job:worker/task:%d/gpu:0" % i):
print(sess.run(inputs[i]))
outputs.append(tf.matmul(inputs[i], b))
# 每个worker计算完,都将结果收集到outputs中,然后在ps节点上汇总处理,这里只concat模拟一下
with tf.device('/job:ps/task:0/cpu:0'):
output = tf.concat(outputs, axis=0)
print(sess.run(output))
执行这段程序的进程就是一个 client,但是在计算时需要依靠 cluster 中的 worker0 和 worker1 的设备来计算,参数存储在PS上,遵循了标准的 ps 架构。
分布式训练策略:模型并行与数据并行
模型并行
所谓模型并行指的是对于同一批样本数据,当神经网络模型很大时,由于显存限制,它是难以在跑在单个GPU上,这个时候就需要模型并行。做法是把模型拆分成不同部分,然后分散到多个设备上进行并行训练,如下图所示:
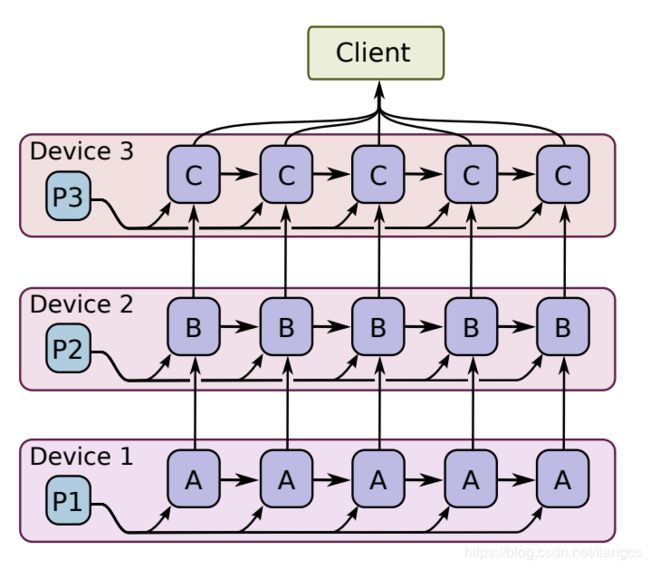
但是深度学习模型一般包含很多层,如果要采用模型并行策略,一般需要将不同的层运行在不同的设备上,但是实际上层与层之间的运行是存在约束的:前向运算时,后面的层需要等待前面层的输出作为输入,而在反向传播时,前面的层又要受限于后面层的计算结果。所以除非模型本身很大,一般不会采用模型并行。但是如果模型本身存在一些可以并行的单元,那么也是可以利用模型并行策略来提升训练速度,比如GoogLeNet的几个Inception模块。
数据并行
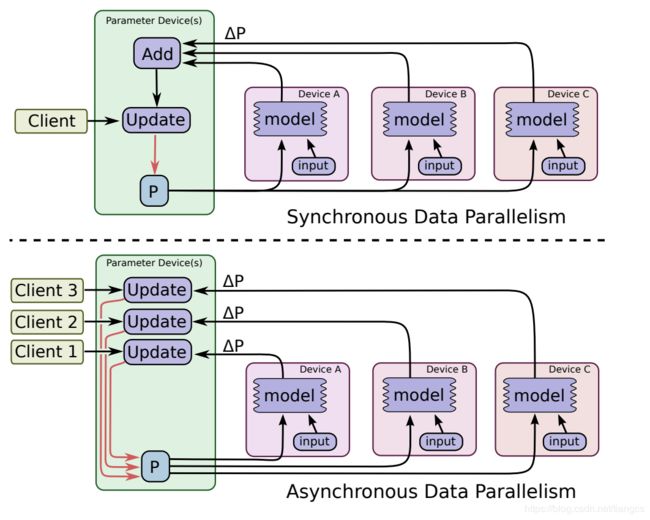
数据并行是分布式中比较常用的一种并行策略,因为实际中往往是数据量很大。数据并行就是在不同机器上放置相同的模型,然后每个机器喂给不同的训练样本来计算梯度。上面说的 cifar10 单机多卡例子就是数据并行,其实TensorFlow中的分布式将的也是数据并行。数据并行根据其参数更新的方式又可以分为同步更新和异步更新。同步更新很简单,如下图所示,就是等待所有设备都计算完才开始更新参数,迭代速度取决于速度最慢的那个机器。异步更新就是各个机器自己干自己的,计算完梯度就去更新。
复制训练: Replicated training
TensorFlow中的分布式策略是数据并行,并且把这种策略换了个名字叫复制训练 (Replicated training),就是说多个 worker 使用不同的 batch 数据来训练相同的模型,计算出的梯度放到ps上用于更新参数。TensorFlow也增加了一些库函数来简化复制训练的实现。在 TensorFlow 中共有四种不同的方式来实现复制训练:
- in-graph replication:只构建一个client,这个 client 构建一个 Graph,Graph中包含一套模型参数,放置在ps上,同时Graph中包含模型计算部分的多个副本,每个副本都放置在一个worker上,这样多个worker可以同时训练复制的模型。上面单机多卡的 cifar10分类模型 和 example_distributed_client 的那段代码,都属于这个类型。这种方式的缺点也很明显,一旦唯一创建 client 的那个 worker 挂了,整个系统就全崩溃了,容错能力差,因此在实际中使用较少。
- Between-graph replication:每个worker都创建一个 client,这个 client 一般还与 task 的主程序在同一进程中。各个 client 构建相同的 Graph,但是参数还是放置在ps上。这种方式就比较好,一个 worker 的client挂掉了,系统还可以继续跑。
- Asynchronous training:异步方式训练,各个 worker 自己干自己的,不需要与其它worker来协调,前面也已经详细介绍了异步训练,上面两种方式都可以采用异步训练。
- Synchronous training:同步训练,各个 worker 要统一步伐,计算出的梯度要先聚合才可以执行一次模型更新,对于 In-graph replication 方法,由于各个 worker 的计算子图属于同一个 Graph,很容易实现同步训练。但是对于 Between-graph replication 方式,各个 worker 都有自己的 client,这就需要系统上的设计了,TensorFlow 提供了tf.train.SyncReplicasOptimizer来实现
Between-graph replication的同步训练。
下面来详细讲述下这四种方式
in-graph replication
还是以上面example_distributed_client的例子来说明,不过这次改下代码。上面的代码中每个server启动后都会join(),然后一直 block,并没有人告诉它结束。但worker节点做完了理应结束的,所以改下刚才的代码,判断下如果是ps节点,就 block,这样ps节点一直处于监听状态,等待着worker节点传入参数,而worker节点会把一些参数定义在ps节点上。这样改完后,worker干完整个计算图就结束了,而ps节点进程其实还一直存在。
为了直观地感受创建client及计算图执行的过程,这里用 timeline 来记录最终的 output op的执行过程,并用TensorBoard可视化计算图,代码在example_in_graph.py中,执行这个脚本分别传入 ps_hosts, worker_hosts和对应的 task_index
nohup python example_in_graph.py --job_name=ps --task_index=0 > ps0.log &
nohup python example_in_graph.py --job_name=worker --task_index=0 > worker0.log &
nohup python example_in_graph.py --job_name=worker --task_index=1 > worker.log &
过一会woker0, worker1执行结束。查看两个worker的log可以发现,worker0.log中多了一条tensorflow/core/distributed_runtime/master_session.cc:998] Start master session 5eeddba53ed488e2 with config:, 而对应的worke1的log,并没有start master session的输出信息,说明只在worker0的节点上创建了session,用来执行计算,证明这是图内复制模式。
保存的timeline_client.json文件记录了计算图的执行轨迹,在Chrome中输入chrome://tracing/, 然后load 这个json文件,可以看到可视化的轨迹。可以看到有两个Mat操作分别在worker0上和worker1上,concat操作发生在ps上,这与代码一致。

通过tensorBoard的可视化,也可以看到整个图的计算过程,及每一步的device.

between-graph replication
图间复制是TensorFlow比较常用的一种方式,着重介绍下。
分布式参数配置
图间复制方式,每个worker都各自包含一个client,它们构建相同的计算图,然后把模型参数推送到PS节点上,多个worker共享ps上的参数。上面我们介绍的都是只有一个ps的情况,那么如果有多个PS节点时,变量存储和更新怎么分配呢?万能的TensorFlow提供了一个神奇的设备函数,可以用不同的设备函数来创建不同的参数放置策略。这个神奇的设备函数就是 tf.train.replica_device_setter 来做,它会循环地分配变量,自动把把Graph中的参数放到PS上,而同时将计算部分放在当前worker节点上。只需要你在实现时,把整个模型构建的代码用这个函数包起来即可。先看一个应用tf.train.replica_device_setter的例子,来自TF官网
# To build a cluster with two ps jobs on hosts ps0 and ps1, and 3 worker
# jobs on hosts worker0, worker1 and worker2.
cluster_spec = {
"ps": ["ps0:2222", "ps1:2222"],
"worker": ["worker0:2222", "worker1:2222", "worker2:2222"]}
with tf.device(tf.train.replica_device_setter(cluster=cluster_spec)):
# Build your graph
v1 = tf.Variable(...) # assigned to /job:ps/task:0
v2 = tf.Variable(...) # assigned to /job:ps/task:1
v3 = tf.Variable(...) # assigned to /job:ps/task:0
# Run compute
先看下这个函数的API:
- ps_tasks: ps job中的task数量,如果提供了cluster参数,则可以忽略
- Ps_device: ps job的字符串名字,默认就是”ps"
- worker_device: worker job的字符串名字,默认就是”worker"
- cluster: ClusterDef proto或者ClusterSpec
- ps_ops: 需要放到ps节点上的op列表,默认是STANDARD_PS_OPS,在源码中的定义如下:可见所有的Variable变量都会被默认放到PS节点上
# This is a tuple of PS ops used by tf.estimator.Estimator which should work in
# almost all of cases.
STANDARD_PS_OPS = ("Variable", "VariableV2", "AutoReloadVariable",
"MutableHashTable", "MutableHashTableV2",
"MutableHashTableOfTensors", "MutableHashTableOfTensorsV2",
"MutableDenseHashTable", "MutableDenseHashTableV2",
"VarHandleOp", "BoostedTreesEnsembleResourceHandleOp")
-
ps_strategy:既然模型参数都会被放到PS节点上,那如果有多个PS节点,是如何决定哪个参数放到哪个节点上的呢?就是这个参数来控制的,默认是round-robin 策略,就是按出现次序将参数挨个放到各个PS上,由上图中也可以看出一共2个PS节点,v1先出现就被放到ps0上,接着v1放到ps1上,然后v2又被放到ps0上。图下图所示:
-
但是这种方式可能不能使ps负载均衡,在2个PS的情况下可能会出现,所有的W都在ps0,所有的偏置b都在ps1上,这显然会给ps0带来更大的负载压力。如果需要更加合理的分配,可以使用tf.contrib.training.GreedyLoadBalancingStrategy策略, 这是一个简单的贪婪策略,它可以根据参数的内存字节大小来放置到内存合适的ps节点上,从而带来更好的负载均衡,如下图所示:

以上讨论的都还是小字节的参数,每个PS都还可以单独处理一个变量。但当遇到超大字节的变量,比如可能 是千万甚至亿级别的特征,该如何处理?TensorFlow提供了一个分割变量的方法,对于这种超大字节的变量,可 以使用一个分隔符,把这个变量分成多个部分,分发到不同的ps节点上去,如下图所示:

现在解决了参数如何放置的问题,按照惯例下一步就是创建Session了,上面图内复制模式下是这样创建session的: with tf.Session(“grpc://localhost:2223”) as sess, 这里传入一个url: grpc://localhost:2223, 后面的地址对应着worker0的 host:ip ,字符串 grpc://localhost:2223 等价于server0.target, server0就是 server = tf.train.Server(cluster, job_name=“worker” task_index=0), 如果打印此时server.target,发现其值就是 grpc://localhost:2223, 那么问题来了?worker0有target, worker1也有target,那么在各自的节点上用各自的server创建session,不就实现单独创建client了吗?实际上,图间复制模式也是这样做的,下面来总结下图间复制模式下创建session的步骤:1 定义一个ClusterSpec;
2 然后创建一个tensorflow Server,它代表集群里的一个特定任务
3 如果是ps节点就 server.join(), block在这里,等待worker节点的接入
4 如果是worker节点,就先用tf.train.replica_device_setter 包起来,作用是自动分配参数到ps节点,而把计算部分留给当前worker 。然后用当前的server创建session,
with tf.sessioon(server.target) as sess:
MonitoredTrainingSession
好,现在解决了参数如何放置、如何单独创建session的问题,那么问题又来了,由于各个worker都拥有独立的client,但是都拥有相同的计算图,对于图中的一些公共操作,如模型参数初始化、checkpoint文件保存、summary等,如果每个client都独立进行,显示会出现重复操作而且也是对集群资源的浪费。为了解决这个问题,一般会设定一个worker为chief workr,这个chief worker就作为各个worker的管家,协调它们之间的训练,并且完成一些公共操作如模型初始化、模型保存和恢复、summary等。一般来说使用worker0作为chief worker, 因为worker是从0开始计数的,所以总会有worker0存在。
万能的TensorFlow也替我们做好了这个事情,你只需要告诉它哪个worker是chief workr即可。刚才我们创建session都是用tf.Session()来创建,tf还提供了一个更强大的tf.train.MonitoredTrainingSession,在创建时可以指定哪个worker是chief worker。(有的文章里写的是tf.train.Supervisor, 这个API即将被弃用,TF官方建议使用新的tf.train.MonitoredTrainingSession), 然后MonitoredTrainingSession的代码会自动帮你初始化参数,连sess.run(tf.global_variables_initializer())这一显示的初始化操作都给省了,而且传入的chief worker会帮你完成上述的公共操作。
异步训练
下面用一段示例程序来演示图间复制下的异步训练,完整代码在example_between_graph.py, 这里模拟一个线性运算,采用图间复制模式+异步训练+chief_worker, 从运行log中可以看出在worker0和worker1上各自启动了一个master session,这与代码里的逻辑也吻合,因为创建session时用的是server.target, 这样每个worker都会创建一个master session, 继而创建创建client ,构造计算图.
每个worker拥有独立的client, 下图中左边是worker0,右边是worker1,可以看到step是交叉打印的,说明是异步训练,每个worker自己干自己的。这个模拟过程发现会有重复step出现,可能是这个模拟数据太小,worker训练很快,导致同时开始一个step?之后用稍大数据再逐个step测试。。。
同步训练
如果想用同步训练怎么办呢?tensorflow提供了对同步训练的支持,使用tf.train.SyncReplicasOptimizer可以实现同步训练,官网上有使用教程,清晰明了。现简单介绍下几个初始化参数:
-
opt, 实际的优化器函数,如 tf.train.GradientDescentOptimizer
-
replicas_to_aggregate, 每次梯度更新时要聚合 replicas_to_aggregate 个steps的计算结果,注意这replicas_to_aggregate个结果没有要求必须是来自全部worker的,假如有一个worker计算特别慢,而其他worker已经计算replicas_to_aggregate步,那么也会收集这些梯度执行一次梯度更新。
-
total_num_replicas,所有的worker 副本数,这个与replicas_to_aggregate不同,如果total_num_replicas > replicas_to_aggregate, 那么剩下的total_num_replicas - replicas_to_aggregate个将成为备份复制。如果total_num_replicas < replicas_to_aggregate,则一个worker可能会执行多个mini_batches,然后ps节点才开始收集梯度。一般replicas_to_aggregate = num_workers,在各个worker的计算能力相同的情况下,每个worker计算一步后开始收集梯度进行更新。、
-
use_lockint, 如果True,用自己设置的locks来执行梯度更新操作
同步训练的代码也在example_between_graph.py, 只需要在启动脚本时设定is_sync=True即可。同步训练结果如下:

左边是worker0,右边是worker1,可以看到刚开始worker1速度比较快,导致开始时并没有实现真正的同步,worker1训练2个step然后就更新一次梯度(2个step是因为tf.train.SyncReplicasOptimizer(opt, replicas_to_aggregate=2,total_num_replicas=2)),直到step10开始,两个worker基本同时打印相同的step,对于同一个step,可以看到weight和biase是一样的,也证明了这是同步模式,但是loss不一样,因为batch数据不同。这里是worker1开始比较快,实验过程中还出现过worker0 刚开始快,后面同步的情况,还有worker0或者worker1直接从step0干到step2000结束, 然后另一个worker一直没开始的情况,所以同步有风险,使用需谨慎。
几个需要注意的地方:
- 两个worker同步训练,如果一个worker启动较慢,那么刚开始就是另一个worker一直在更新,会发现global step有重复出现,重复出现次数就是replicas_to_aggregate的值。然后到某个step开始,两个worker基本同步,同时打印一个global step.
- 启动worker或者ps必须在其对应的机器上启动, 如启动worker执行task0, 需要在worker_0对应的host上启动,否则会报Could not start gRPC server错误, 从日志中可以看出会自动把当前角色的host当成localhost,但是创建session时是按照集群中的host去找的。
- 如果ps节点有多个且不在同一个机器上,那么checkpoint_dir必须用hdfs 路径,这样各个ps节点才可以共享读写
Distributed_mnist
好了,上面介绍了复制训练的几种模式,其中图间复制模式比较常用,常见的配置是图间复制模式+异步训练。这里用TensorFlow官网提供的分布式训练mnist数据的例子,来介绍一个细节。完整代码再此, 这里做了一些修改,主要是tf.train.Supervisor替换为tf.train.MonitoredTrainingSession, 使用2个ps,2个worker进行训练。
实验时发现的问题:tf.train.StopAtStepHook是设定停止条件,从文档上来看(下图是部分源码截图), 是总共训练10000步之后就停止session,last_step是训练最大global_step >= last_step 时停止session。使用tf.train.StopAtStepHook(num_step=10000)作为停止条件时发现,如果一个worker训练较快,global先到10000然后就停止了,这时候另外一个worker还会一直训练到某个step停止,而停止的这个step是不受控制的。仔细看StopAtStepHook源码会发现,请求停止的关键语句是:global_step >= self._last_step
def begin(self):
self._global_step_tensor = training_util.get_global_step()
if self._global_step_tensor is None:
raise RuntimeError("Global step should be created to use StopAtStepHook.")
def after_create_session(self, session, coord):
if self._last_step is None:
global_step = session.run(self._global_step_tensor)
self._last_step = global_step + self._num_steps
def before_run(self, run_context): # pylint: disable=unused-argument
return SessionRunArgs(self._global_step_tensor)
def after_run(self, run_context, run_values):
global_step = run_values.results
if global_step >= self._last_step:
run_context.request_stop()
也就是内部是已last_step为停止条件的,如果指定last_step=10000, 那么任何一个worker判断出global_step >=10000,就会停止当前session,如果指定的是num_steps=10000, 那么每个worker内部会计算出last_step = global_step + num_steps, 就是这个global_step,每个worker拿到的值是不一样的。2个worker的情况下,较快的worker从global_step=0开始,它计算出的last_step=10000, 可能它训练了1000个step了,然后另一个慢的work开始了,慢的worker此时也会计算last_step=global_step + num_steps=1000+10000=11000,慢的worker就会一直训练直到global_step > 11000然后停止当前session。为了验证这个判断,自己写了个Hook打印下after_create-session和after_run时的step值:
class MyStopAtStepHook(tf.train.StopAtStepHook):
def after_create_session(self, session, coord):
if self._last_step is None:
global_step = session.run(self._global_step_tensor)
self._last_step = global_step + self._num_steps
print("now global_step is %d after create session, num_steps: %d, last_step:%d :"
% (global_step, self._num_steps, self._last_step))
def after_run(self, run_context, run_values):
global_step = run_values.results
if global_step >= self._last_step:
print("global_step is %d when stop." % global_step)
run_context.request_stop()
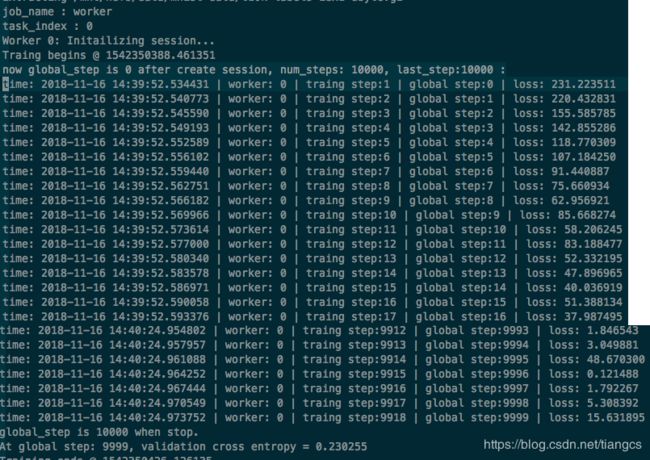
再次训练,查看运行log,证明和猜测一致, 所以以后尽量使用last-step来控制停止条件,如果是从checkpoint开始训练的,记得调整这个值,加上要训练的num_steps即可。下图中上边是worker0,下边是worker1,可以看到worker0开始训练前,打印global-step=0, num-steps=10000, last_step=10000, 最后在gloabal_step=10000停止,而worker1速度较慢,在global_step=8390时才开始创建session, 这时计算到的last_step=10000+8390=18390, 最后停止训练时的global_step也是19390。

加载模型预测
TensorFlow提供了分布式训练的支持,训练的结果同样也会保存checkpoint文件等信息,如果要加载分布式训练出的模型进行预测,过程和加载单机模型是一样的。这里也提供了一个示例,这个没什么可说的。
容错性
上面的内容介绍了分布式训练的过程,但是这样就完了吗?万一跑一个很长时间的training任务时,worker突然挂了怎么办,难道之前的training都付之东流了吗?当然不,伟大的谷歌爸爸在设计时肯定会考虑这个问题, 且听我娓娓道来。
定时saver
在长时间的训练任务中,推荐使用saver来不断把checkpoint保存到磁盘上,这样万一某个节点挂了,还可以从最近的checkpoint恢复, 在tf.train.MonitoredTrainingSession中提供了checkpoint_dir参数可以设置保存路径,需要注意的是如果是多个ps,需要写入HDFS,这样多个PS才可以共同访问。
其中save_checkpoint_secs参数设置了默认的保存间隔,默认是600秒,可以根据自己需求来设置。
此外TensorFlow提供了一个默认的saver来做保存的事情, 这个saver封装在CheckpointSaverHook中,如果没有指定saver,会创建一个默认的saver,代码如下:
def _get_saver_or_default():
"""Returns the saver from SAVERS collection, or creates a default one.
This method is used by other members of the training module, such as
`Scaffold`, or `CheckpointSaverHook`.
Returns:
`Saver`.
Raises:
RuntimeError: If the SAVERS collection already has more than one items.
"""
collection_key = ops.GraphKeys.SAVERS
savers = ops.get_collection(collection_key)
if savers:
if len(savers) > 1:
raise RuntimeError(
"More than one item in collection {}. "
"Please indicate which one to use by passing it to the constructor.".
format(collection_key))
return savers[0]
saver = Saver(sharded=True, allow_empty=True)
if saver is not None:
ops.add_to_collection(collection_key, saver)
return saver
重点是里面的saver = Saver(sharded=True, allow_empty=True)这句话,其中sharded=True这个参数是设置分片数据,也就是说假如有3个PS任务,则会将checkpoint分片为3份来并行写,提高写入速度。看到一些教程中说要主动构造一个saver,并设置sharded=True,其实不用这么做,因为tf.train.MonitoredTrainingSession中默认就是这样设置的。
节点挂了
节点挂了可以分为几种情况:
-
最好的情况就是
非Chief的worker task出错了,因为这些task实际上是无状态的。那么当遇到了这种错误,当这样的一个worker task恢复的时候,它会重新与它的PS task建立连接,并且重新开始之前崩溃过的进程。

-
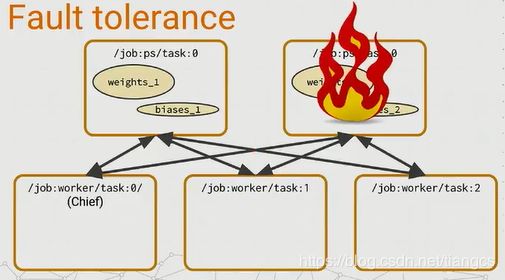
比较差的一种情况就是PS task失败了,那么就有一个麻烦,因为PS task是有状态的,所有的worker task需要依赖他们来发送他们的梯度并且取得新的参数值。所以这种情况下,他们的
chief worker task负责监测这种错误,如果发生了这种错误,chief worker task就打断整个训练,并从上一个检查点恢复所有的PS tasks。
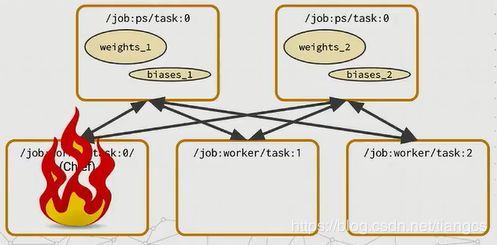
- 最糟糕的情况就是
chief worker task失败了,因为我们让它负责其他所有的任务,我们就要确保它失败了,能够让集群里所有的任务都回到一个很好的状态。所以我们做的就是打断训练,并在当它恢复了时候从上一个好的检查点恢复。这样的处理方式很简单,但也依赖于机器的健壮性。这里也抛出了一个想法,或许可以使用一个配置比如Hadoop ZooKeeper 或Etcd来选举chief worker task而不是简单地定义为task0。
注:以上容错性所有截图和参数分配策略部分的截图均来自2017TensorFlow开发者峰会,TensorFlow主管研发Derek Murray做了半小时左右的关于TensorFlow分布式设计的演讲,干货满满,本篇博客也有部分文字是根据这个视频翻译过来的,感兴趣可以看下。这里先放张 Derek Murray的帅照,大家意淫一下?

后记
感谢大家听我扯皮,坚持看到最后。好了,现在到了最关键的时刻,大家有钱的捧个钱场,没钱的出个脑场(这是什么词,我自己也不知道o(╯□╰)o),只能来清空我的TODO List 了?。
- 如何读取数据并行
上面的例子中,每个worker都是从HDFS读取全量数据,然后在自己机器上next_batch去训练。如何实现多个worker共用一份数据? - 如何优雅地结束PS
官网很多例子,都没有讲如何优雅地结束ps节点?ps从一开始就block在那里,worker进程干完就结束了,但是ps一直还在,只能暴力kill掉(据说MXNet更粗暴,PS运行完import mxnet就block了)。 这里贴一个美团云的做法:
采用队列通信的方式同步。
1. 为PS和每个worker创建一个队列
2. PS在server创建后,对队列进行worker数量的dequeue操作,如果完成worker次dequeue说明每个worker都结束了,这时候ps就可以自己退出了
3. 每个worker在完成后,对队列进行一次enqueue操作
- ps/worker数量的设置
PS和worker的数量如何设置?这个需要大量的实验,一般的策略是模型参数多,就开PS多一点,数据量很大,就开worker多一点。但是没有绝对的平衡点,当PS太多时variable的分片也多,网络额外开销会大,当PS太少时worker拉参数会发生瓶颈。我自己实验时,在上面distributed_mnist的例子中,2个PS2个worker的配置反倒比1个PS1个worker还慢。
一个人可以跑的很快,一群人可以跑的很远 ~
参考资料
- 官网 Distributed TensorFlow
- TensorFlow Architecture
- Distributed TensorFlow(2017 TensorFlow 开发峰会)
- MNIST实例:Distributing TensorFlow
- TensorFlow白皮书
- TensorFlow分布式博客