分布式数据库
1)华为FusionInsight, 官网:http://developer.huawei.com/ict/cn/site-bigdata/solution/site-fusionInsight
FusionInsight HD是华为面向众多行业客户推出的,基于Apache开源社区软件进行功能增强的企业级大数据存储、查询和分析的统一平台。它以海量数据处理引擎和实时数据处理引擎为核心,并针对金融、运营商等数据密集型行业的运行维护、应用开发等需求,打造了敏捷、智慧、可信的平台软件、建模中间件及OM系统,让企业可以更快、更准、更稳的从各类繁杂无序的海量数据中发现全新价值点和企业商机。
华为FusionInsight HD是一个分布式数据处理系统,对外提供大容量的数据存储、查询和分析能力,可解决各大企业的以下需求:
- 快速地整合和管理不同类型的大容量数据
- 对原生形式的信息提供高级分析
- 可视化所有的可用数据,供特殊分析使用
- 为构建新的分析应用程序提供了开发环境
- 工作负荷的优化和调度
FusionInsight HD在FusionInsight解决方案中的位置如下图所示:
华为FusionInsight HD发行版紧随开源社区的最新技术,快速集成最新组件,并在可靠性、安全性、管理性等方面做企业级的增强,持续改进,持续保持技术领先。
FusionInsight HD的企业级增强主要表现在以下几个方面。
- 安全
- 架构安全
FusionInsight HD基于开源组件实现功能增强,保持100%的开放性,不使用私有架构和组件。
- 认证安全
- 基于用户和角色的认证统一体系,遵从帐户/角色RBAC(Role-Based Access Control)模型,实现通过角色进行权限管理,对用户进行批量授权管理。
- 支持安全协议Kerberos,FusionInsight HD使用LDAP作为帐户管理系统,并通过Kerberos对帐户信息进行安全认证。
- 提供单点登录,统一了Manager系统用户和组件用户的管理及认证。
- 对登录FusionInsight Manager的用户进行审计。
- 文件系统层加密
Hive、HBase可以对表、字段加密,集群内部用户信息禁止明文存储。
- 加密灵活:加密算法插件化,可进行扩充,亦可自行开发。非敏感数据可不加密,不影响性能(加密约有5%性能开销)。
- 业务透明:上层业务只需指定敏感数据(Hive表级、HBase列族级加密),加解密过程业务完全不感知。
- 架构安全
- 可信
- 所有管理节点组件均实现HA(High Availability)
业界第一个实现所有组件HA的产品,确保数据的可靠性、一致性。NameNode、Hive Server、HMaster、Resources Manager等管理节点均实现HA。
- 集群异地灾备
业界第一个支持超过1000公里异地容灾的大数据平台,为日志详单类存储提供了迄今为止可靠性最佳实践。
- 数据备份恢复
表级别集群全量备份、增量备份,数据恢复(对本地存储的业务数据进行完整性校验,在发现数据遭破坏或丢失时进行自恢复)。
- 所有管理节点组件均实现HA(High Availability)
- 易用
- 统一运维管理
Manager作为FusionInsight HD的运维管理系统,提供界面化的统一安装、告警、监控和集群管理。
- 易集成
提供北向接口,实现与企业现有网管系统集成;当前支持Syslog接口,接口消息可通过配置适配现有系统;整个集群采用统一的集中管理,未来北向接口可根据需求灵活扩展。
- 易开发
提供自动化的二次开发助手和开发样例,帮助软件开发人员快速上手。
- 统一运维管理
2)Hypertable 简介 一个 C++ 的Bigtable开源实现
一 Hypertable 是什么:
Hypertable 是一个正在进行中的开源项目,以google的bigtable论文为基础指导,使用c++语言实现。
目标:
- 是为了解决大并发,大数据量的数据库需求。
- 目前只支持最基本的查询功能
缺点:
- 不支持事物, 不支持关联查询.
- 对单条查询的响应时间可能也不如传统数据库(要看数据量,量越大,对hypertable越有 力)。
优点:
- 并发性: 可以处理大量并发请求,和管理大量数据。
- 规模:可扩缩性好,扩容只需要增加集群中的机器就ok了。
- 可用性: 任何节点失效,既不会造成系统瘫痪也不会丢失数 据。在集群节点足够的情况下,并发量和数据量对性能基本没有影响。
注意:Hypertable不是关系数据库。而且它对稀疏数据是只存储其有效部分的。举个例子来说,假设一个表有10列。表中的一条记录,只有第三列有 值。那么实际上只有第三列被存储了,无值的列没有保留空位。这些特点使得 Hypertable 在使用的时候与关系数据库不同。
二 hypertable 的总体架构
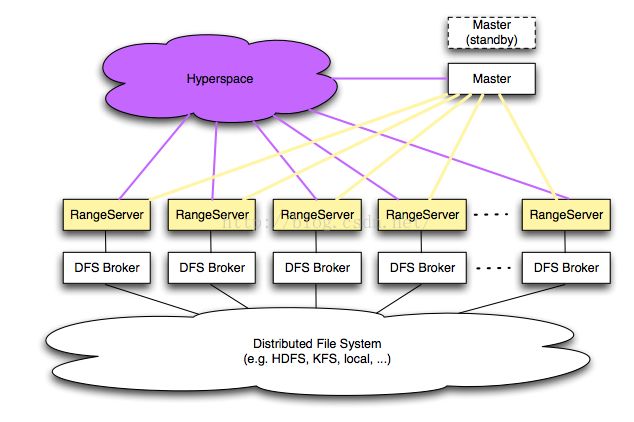
3)GreenPlum
简介及适用场景
如果想在数据仓库中快速查询结果,可以使用greenplum。
Greenplum数据库也简称GPDB。它拥有丰富的特性:
第一,完善的标准支持:GPDB完全支持ANSI SQL 2008标准和SQL OLAP 2003 扩展;从应用编程接口上讲,它支持ODBC和JDBC。完善的标准支持使得系统开发、维护和管理都大为方便。而现在的 NoSQL,NewSQL和Hadoop 对 SQL 的支持都不完善,不同的系统需要单独开发和管理,且移植性不好。
第二,支持分布式事务,支持ACID。保证数据的强一致性。
第三,做为分布式数据库,拥有良好的线性扩展能力。在国内外用户生产环境中,具有上百个物理节点的GPDB集群都有很多案例。
第四,GPDB是企业级数据库产品,全球有上千个集群在不同客户的生产环境运行。这些集群为全球很多大的金融、政府、物流、零售等公司的关键业务提供服务。
第五,GPDB是Greenplum(现在的Pivotal)公司十多年研发投入的结果。GPDB基于PostgreSQL 8.2,PostgreSQL 8.2有大约80万行源代码,而GPDB现在有130万行源码。相比PostgreSQL 8.2,增加了约50万行的源代码。
第六,Greenplum有很多合作伙伴,GPDB有完善的生态系统,可以与很多企业级产品集成,譬如SAS,Cognos,Informatic,Tableau等;也可以很多种开源软件集成,譬如Pentaho,Talend 等。
greenplum起源
Greenplum最早是在10多年前(大约在2002年)出现的,基本上和Hadoop是同一时期(Hadoop 约是2004年前后,早期的Nutch可追溯到2002年)。当时的背景是:
- 互联网行业经过之前近10年的由慢到快的发展,累积了大量信息和数据,数据在爆发式增长,这些海量数据急需新的计算方式,需要一场计算方式的革命;
- 传统的主机计算模式在海量数据面前,除了造价昂贵外,在技术上也难于满足数据计算性能指标,传统主机的Scale-up模式遇到了瓶颈,SMP(对称多处理)架构难于扩展,并且在CPU计算和IO吞吐上不能满足海量数据的计算需求;
- 分布式存储和分布式计算理论刚刚被提出来,Google的两篇著名论文发表后引起业界的关注,一篇是关于GFS分布式文件系统,另外一篇是关于MapReduce 并行计算框架的理论,分布式计算模式在互联网行业特别是收索引擎和分词检索等方面获得了巨大成功。
下图就是GFS的架构

总体架构
greenplum的总体架构如下:

数据库由Master Severs和Segment Severs通过Interconnect互联组成。
Master主机负责:建立与客户端的连接和管理;SQL的解析并形成执行计划;执行计划向Segment的分发收集Segment的执行结果;Master不存储业务数据,只存储数据字典。
Segment主机负责:业务数据的存储和存取;用户查询SQL的执行。
greenplum使用mpp架构。

基本体系架构

master节点,可以做成高可用的架构

master node高可用,类似于hadoop的namenode和second namenode,实现主备的高可用。

segments节点

并行管理
对于数据的装载和性能监控。

并行备份和恢复。

数据访问流程,数据分布到不同颜色的节点上

查询流程分为查询创建和查询分发,计算后将结果返回。

对于存储,将存储的内容分布到各个结点上。

对于数据的分布,分为hash分布和随机分布两种。

均匀分布的情况:

总结
GPDB从开始设计的时候就被定义成数据仓库,如果是olap的应用,可以尝试使用GPDB。
HBase的基本概念和定位
HBase是一个分布式的、面向列的开源数据库,该技术来源于 Fay Chang 所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”。就像Bigtable利用了Google文件系统(File System)所提供的分布式数据存储一样,HBase在Hadoop之上提供了类似于Bigtable的能力。HBase是Apache的Hadoop项目的子项目。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是HBase基于列的而不是基于行的模式。
HBase – Hadoop Database,是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。
选择合适的HBase版本
官网版本:http://archive.apache.org/dist/hbase/
CDH版本(稳定,推荐):http://archive.cloudera.com/cdh5/
HBase的用途
- 海量数据存储
- 准实时查询
HBase的应用场景及特点
- 交通
- 金融
- 电商
- 移动(电话信息)等
HBase的特点
- 容量大
HBase单表可以有上百亿行、百万列,数据矩阵横向和纵向两个维度所支持的数据量级都非常具有弹性。
2. 面向列
HBase是面向列的存储和权限控制,并支持独立检索。列式存储,其数据在表中是按照某列存储的,这样在查询只需要少数几个字段的时候,能大大减少读取的数据量。
- 多版本
HBase每一个列的数据存储有多个Version(version)。
- 稀疏性
为空的列并不占用存储空间,表可以设计的非常稀疏。
- 扩展性
底层依赖于HDFS
- 高可靠性
WAL机制保证了数据写入时不会因集群异常而导致写入数据丢失:Replication机制保证了在集群出现严重的问题时,数据不会发生丢失或损坏。而且HBase底层使用HDFS,HDFS本身也有备份。
7.高性能
底层的LSM数据结构和Rowkey有序排列等架构上的独特设计,使得HBase具有非常高的写入性能。region切分、主键索引和缓存机制使得HBase在海量数据下具备一定的随机读取性能,该性能针对Rowkey的查询能够达到毫秒级别。
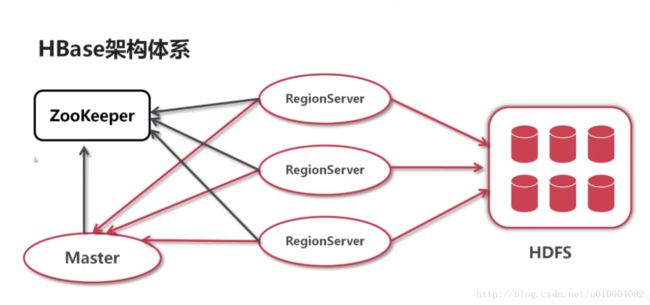
HBase架构体系与设计模型
HBase架构体系
HBase数据模型
- 一张表的列簇不会超过5个
- 每个列簇中的列数没有限制
HBase与关系型数据库表结构的对比
| HBase | 关系型数据库 |
|---|---|
| 列动态增加 | 列动态增加 |
| 数据自动切分 | 数据自动切分 |
| 高并发读写 | 高并发读写 |
| 不支持条件查询 | 复杂查询 |
就是bigTable 支持数十亿列 Apache HBase是一个使用Java语言编写的、 以谷歌BigTable技术为基础的开源非关系型列式分布数据库, 可运行在HDFS文件系统之上。HBase提供了很好的存储容错能力和快速访问大量稀疏文件的能力。HBase遵循Apache 2许可证。 Hbase的优点: 1 列的可以动态增加, 并且列为空就不存储数据,节省存储空间. 2 Hbase自动切分数据, 使得数据存储自动具有水平scalability. 3 Hbase可以提供高并发读写操作的支持 Hbase的缺点: 1 不能支持条件查询, 只支持按照Row key来查询. 2 暂时不能支持Master server的故障切换,当Master宕机(死机) 后,整个存储系统就会挂掉.
5) Apache CouchDB CouchDB也是一个流行的开源NoSQL数据库, 它以文档方式(JSON) 存储数据。 CouchDB使用JavaScript语言作为查询语言, 集成MapReduce技术。 IBM Lotus Notes的开发人员Damien Katz在2005年构建了CouchDB, 用于大规模对象的数据存储系统。 CouchDB遵循Apache 2许可证, 英国广播公司(BBC) 使用CouchDB存储动态内容, 瑞士瑞信银行(Credit Suisse) 的商品部也采用了它。 couchDB,对它的特点做以下总结 一、 key/value型 分布式数据库。 二、 支持海量数据存储, 提供高于传统数据库性能优势。 三、 按照CAP原理: 支持分区容忍性和数据可用性。 四、 数据一致性:couchDB支持数据最终一致性。 五、 提供 rest 方式数据访问API, 个人感觉可以很大程度简化开发过程。 六、 支持不同节点数据库之间的数据增量复制。 七、 数据格式json, 更开放。 八、 贴切移动开发, 提供android和IOS版 客户端数据库。 九、 数据格式无限制, free‐schema, 系统扩展更便利。 十、 支持云计算。 Apache CouchDB 项目还处于早期发展阶段。 CouchDB 是一款正在测试中的软件。CouchDB 在 Web 应用程序、 iPhone 应用程序和 Facebook 应用程序中越来越流行。 到目前为止, 强大的 wiki、 博客、 讨论论坛和文档管理软件都致力于改善关系数据库, 让它们能够更高效地储存文档形式的数据。 然而, 随着 CouchDB 的发行版越来越稳定,CouchDB 数据库越来越受到这些类型的软件的青睐, 从而避免了文档修订管理和不断变化的模式需求带来的烦恼。 总体而言, 到目前为止用户对 CouchDB 的反馈都是正面的, 尽管很多人觉得有必要在博客和论坛上讨论哪种数据库更好 — 关系型或面向文档型。 不过, CouchDB 从来没有打算取代关系数据库, 也不期望成为数据库开发的新标准。 当然, 在很多场景中, CouchDB 的简单性使其不能与 DB2 和 Oracle 相媲美。 不过在很多其他场景中, 数据库的简单性确实是必要的, 传统的 RDBMS 产品被过度吹捧了, 并且耗费的资源太多。
6) MongoDB MongoDB 是一种单独的系统数据库 MongoDB是一个基于分布式文件存储的数据库, 由C++语言编写。 旨在为Web应用提供可扩展的高性能数据存储解决方案。MongoDB是非常流行的JSON文档式NoSQL数据库, 许多公司都非常认同MongoDB。 MTV Networks、 craigslist和迪斯尼互动传媒集团, 纽约时报以及Etsy都是MongoDB的客户。 MongoDB遵循GNU Affero通用许可证, 语言驱动遵循Apache许可证, 10gen公司提供商业化的MongoDB许可证。 MongoDB 是一个面向文档的数据库系统。 使用 C++编写, 不支持 SQL, 但有自己功能强大的查询语法。 MongoDB 使用 BSON 作为数据存储和传输的格式。 BSON 是一种类似 JSON 的二进制序列化文档, 支持嵌套对象和数组。 MongoDB 很像 MySQL, document 对应 MySQL 的 row, collection 对应 MySQL 的 table。 MongoDB 是一个基于分布式文件存储的数据库。 由 C++语言编写。 意在为 WEB 应用提供可扩展的高性能数据存储解决方案。 它有一下几个特点: 1 .模式自由。 ( 像 json 数据一样可以自由的宽展) 2.支持动态查询。 3.支持完全索引, 包含内部对象。 4.支持查询。 5.支持复制和故障恢复。 6.使用高效的二进制数据存储, 包括大型对象(如视频等) 。 7.自动处理碎片, 以支持云计算层次的扩展性。 8.支持 RUBY, PYTHON, JAVA, C++, PHP,C#等多种语言。 9.文件存储格式为 BSON(一种 JSON 的扩展) 。
7) Cassandra :最好的BigTable和Dynamo 只支持java写入比查询多,只支持Java Cassandra 项目是 Facebook 在 2008 年开源出来的, 随后 Facebook 自己使用 Cassandra 的另外一个不开源的分支, 而开源出来的 Cassandra 主要被 Amazon 的 Dynamite 团队来维护, 并且 Cassandra 被认为是 Dynamite2.0 版本。 目前除了 Facebook 之外, twitter 和 digg.com 都在使用 Cassandra。 Cassandra 的主要特点就是它不是一个数据库, 而是由一堆数据库节点共同构成的一个分布式网络服务, 对 Cassandra 的一个写操作, 会被复制到其他节点上去, 对 Cassandra 的读操作, 也会被路由到某个节点上面去读取。 对于一个 Cassandra 群集来说, 扩展性能是比较简单的事情, 只管在群集里面添加节点就可以了。 我看到有文章说 Facebook 的 Cassandra 群集有超过 100 台服务器构成的数据库群集。 Cassandra 也支持比较丰富的数据结构和功能强大的查询语言, 和 MongoDB 比较类似, 查询功能比 MongoDB 稍弱一些, twitter 的平台架构部门领导 Evan Weaver 写了一篇文章介绍Cassandra: http://blog.evanweaver.com/articles/2009/07/06/up‐and‐running‐with‐cassandra/,有非常详细的介绍。 Cassandra 是一个混合型的非关系的数据库, 主要特点是它不是一个数据库, 而是由一堆数据库节点共同构成的一个分布式网络服务, 对 Cassandra 的一个写操作, 会被复制到其它节点上, 对 Cassandra 的读操作, 也会被路由到某个节点上面去读取。 Twitter 已经证实, 它计划将数据库迁移到 Cassandra。
8)Sector/Sphere 是一个分布式存储/ 分布式计算系统。 此系统工作在集群的普通计算机上。 Sector 提供了用户端工具, 来管理系统中数据的存储。 还提供了开发 API, 用来进行分布式数据计算的应用开发。 这是 2006 年启动的一个开源项目(C++), 包括 Sector 和 Sphere 两个子系统 Sector 是一个分布式存储系统, 能够应用在广域网环境下, 并且允 许用户以高速度从任何地理上分散的集群间摄取和下载大的数据 集。 另外, Sector 自动的复制文件有更高的可靠性、 方便性和访问 吞吐率。 Sector 已经被分布式的Sloan Digital Sky Survey 数据系统所使用。 Sphere 是一个计算服务构建在sector 之上, 并为用户提供简单的编 程接口去进行分布式的密集型数据应用。 Sphere 支持流操作语义, 这通常被应用于GPU 何多核处理器。 流操作规则能够实现在支持 MR 计算的应用系统上。
9) Riak 是一个去中心化的 key-value 存储服务器,提供一个灵活的 map/reduce 引擎,一个友好的 HTTP/JSON 查询接口。 优点: Riak 没有主节点的概念, 因此在处理故障方面有更好的弹性, Riak 的数据模型更加灵活。 Riak 的另一个优势是它是用 Erlang 编写的。 而 MongoDB 和 Cassandra 是用通用语言(分别为 C++和 Java) 编写, 因此 Erlang 从一开始就支持分布式、 容错应用程序, 所以更加适用于开发 NoSQL 数据存储等应用程序, 这些应用程序与使用 Erlang 编写的应用程序有一些共同的特征。
10) hypertable是一个开源、 高性能、 可伸缩的数据库, 它采用与Google的Bigtable相似的模型。 在过去数年中, Google为在PC集群 上运行的可伸缩计算基础设施设计建造了三个 关键部分。 第一个关键的基础设施是Google File System( GFS), 这是一个高可用的文件系统, 提供了一个全局的命名空间。 它通过跨机器( 和跨机架) 的文件数据复制来达到高可用性, 并因此免受传统 文件存储系统无法避免的许多失败的影响, 比如电源、 内存和网络端口等失败。 第二个基础设施是名为Map-Reduce的计算框架, 它与GFS紧密协作, 帮 助处理收集到的海量数据。 第三个基础设施是Bigtable, 它是传统数据库的替代。 Bigtable让你可以通过一些主键来组织海量数据, 并实现高效的 查询。 Hypertable是Bigtable的一个开源实现, 并且根据我们的想法进行了一些改进。
11) Memcached Memcached 是一个高性能的分布式内存对象缓存系统, 用于动态 Web 应用以减轻数据库负载。它通过在内存中缓存数据和对象来减少读取数据库的次数, 从而提供动态、 数据库驱动网站的速度。 Memcached 基于一个存储键/值对的 hashmap。 其守护进程 (daemon ) 是用 C 写的,但是客户端可以用任何语言来编写, 并通过 memcached 协议与守护进程通信。
12) Neo4J Neo4j 是一个嵌入式, 基于磁盘的, 支持完整事务的 Java 持久化引擎, 它 在图像中而不是表中存储数据。 Neo4j 提供了 大规模可扩展性, 在一台机器上可以处理数十亿节点/关系/属性的图像, 可以扩展到多台机器并行运行。
13)SequoiaDB巨杉数据库
链接:https://www.zhihu.com/question/49082483/answer/114402304
equoiaDB(巨杉数据库)是一款企业级分布式NewSQL数据库,自主研发并拥有完全自主知识产权,没有基于任何其他外部的开源数据库源代码。SequoiaDB支持标准SQL、事务操作、高并发、分布式、可扩展、与双引擎存储等特性,并已经作为商业化的数据库产品开源。
具体来说sequoiadb的技术特性包括以下几点
系统架构
SequoiaDB作为典型Share-Nothing的分布式数据库,同时具备高性能与高可用的特性。SequoiaDB采用分片技术为系统提供了横向扩展机制,其分片过程对于应用程序来说完全透明。这样的机制解决了单台服务器硬件资源(如内存、CPU、磁盘 I/O)受限的问题,并不会增加应用程序开发的复杂性。
下图为SequoiaDB的整体架构
<img src="https://pic2.zhimg.com/50/v2-912ba992856b6c2e5a4fbd224fba1584_hd.jpg" data-rawwidth="556" data-rawheight="331" class="origin_image zh-lightbox-thumb" width="556" data-original="https://pic2.zhimg.com/v2-912ba992856b6c2e5a4fbd224fba1584_r.jpg">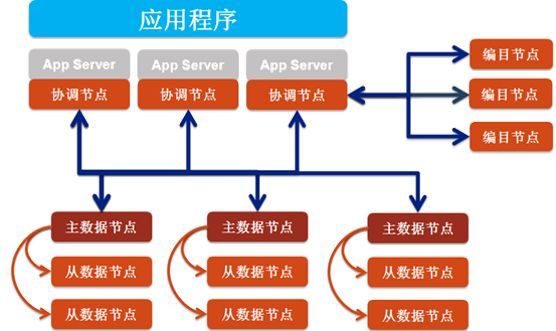
协调节点:负责调度、分配、汇总,是SequoiaDB的数据分发节点,本身不存储任何数据,主要负责接收应用程序的访问请求;
编目节点:负责存储整个数据库的部署结构与节点状态信息,并且记录集合空间与集合的参数信息,同时记录每个集合的数据切分状况;
数据节点:承载数据存储、计算的进程,提供高性能的读写服务,且在多索引的支持下针对海量数据查询性能优越。多个数据节点可以组成一个数据节点组,根据选举算法自动选择一个主数据节点,其余节点为备数据节点。
高性能标准SQL的支持
硅谷新一代分布式数据库的主流发展方向是NoSQL和SQL的融合。目前大多数分布式数据库系统的SQL引擎技术存在许多不足,既不能完整支持标准SQL,同时其性能也存在较大瓶颈。SequoiaDB 从“2.0时代”开始,已经全面支持标准SQL,提供高性能的SQL引擎组件。提供完整的CRUD及事务的支持,真正成为新一代的NewSQL数据库。2.0企业版包含了标准SQL2003引擎、深度数据压缩等多项全新功能,在100%支持和兼容原有JSON特性的基础上,提供了标准SQL2003的语法支持,能够兼容传统应用,并最大程度满足传统应用开发人员对于数据库SQL访问方式的需求。
灵活的数据类型定义
SequoiaDB采用JSON文档类型定义数据存储模型(类对象存储)。JSON作为当今应用设计中主流的存储与通讯协议格式,使用的数据模型与平台、语言无关,从而为企业内异构数据的整合提供了标准方式。传统企业内存在大量的结构化数据资产需要用分布式大数据的手段处理,同时又希望尽量保留其关系型结构,JSON数据模型则恰好满足这些需求。
<img src="https://pic2.zhimg.com/50/v2-60069f313d026b560a9036750583bc18_hd.jpg" data-rawwidth="899" data-rawheight="461" class="origin_image zh-lightbox-thumb" width="899" data-original="https://pic2.zhimg.com/v2-60069f313d026b560a9036750583bc18_r.jpg">
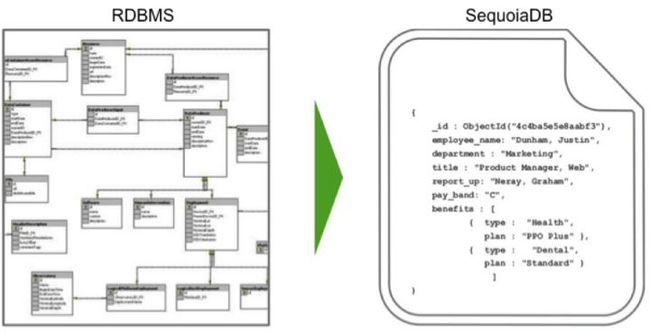
以下链接为关于JOSN的使用介绍,供大家学习参考
https://zhuanlan.zhihu.com/p/23211647?refer=sequoiadb
JSON与块存储双引擎
除了JSON存储引擎以外,为了提高非结构化文件的读写性能,SequoiaDB核心引擎提供了分布式块存储模式,可以将非结构化大文件按照固定大小的数据块进行切分并存放于不同分区。当用户需要管理海量的小文件(例如照片、音视频、文档、图片等)时,SequoiaDB的双存储引擎特性能够帮助用户快速搭建一个高性能、高可用的内容管理与影像平台系统。使用SequoiaDB搭建的影像平台系统架构相对简单,元数据与内容数据均可使用SequoiaDB服务器的本地磁盘存放,不再需要额外购买昂贵的外部存储设备,节省企业的开发和运维成本。
集成Spark内存计算框架
作为全球获得Databricks认证的14家发行商之一,SequoiaDB企业版通过深度集成最新的Spark内存计算框架,实现了批处理分析、流处理等贴近应用的功能。存储层和计算层两层分离的架构、技术互补,是硅谷大数据新架构的主流,这样分布式计算与分布式存储的能力便能够发挥到极致。
以下为具体介绍
http://blog.sequoiadb.com/cn/Detail-id-11
多维度分区
在大部分新型分布式数据库中,表或集合中的数据一般只能通过针对主键或分区键进行散列,来判断某一条记录应当被存储在哪个物理分区中。这种做法是一维分区。SequoiaDB是引入了多维分区的概念,除了使用分区键将记录散列在不同节点以外,还能在每个节点内部根据其他维度进一步分区,使在高存储密度服务器中的大表按照额外提供的维度被进一步切分缩减。这种机制在管理海量数据时会大幅度提升性能,降低磁盘访问开销。
下图显示了在一个分区内,SequoiaDB按照时间维度进行切分,使每一个子分区仅包含指定时间范围内的数据。
<img src="https://pic7.zhimg.com/50/v2-17d43b4fd80cfff13c8bd390736bd675_hd.jpg" data-rawwidth="1228" data-rawheight="292" class="origin_image zh-lightbox-thumb" width="1228" data-original="https://pic7.zhimg.com/v2-17d43b4fd80cfff13c8bd390736bd675_r.jpg">
使用多维分区技术时,开发人员不需要关注底层数据库集合的具体切分逻辑。数据库会自动根据查询条件判断,该查询只需要查找特定某些子分区,或需要在全部子分区上进行检索。
以下为企业级解决方案,有兴趣的朋友可以具体了解:
近线数据服务平台http://solution.sequoiadb.com/cn/Detail-cat_id-5-id-19
企业内容管理 http://solution.sequoiadb.com/cn/Detail-cat_id-5-id-20
大数据湖 http://solution.sequoiadb.com/cn/Detail-cat_id-5-id-18
360度全量数据视图 http://solution.sequoiadb.com/cn/Detail-cat_id-5-id-17
感兴趣的朋友可以访问巨杉数据库开源社区
bbs.sequoiadb.com
下载链接:
http://Download.sequoiadb.com/cn
14) OceanBase数据库
2016年双11,支付宝核心交易、支付、计费、会员、账务等核心数据链全都运行在阿里巴巴/蚂蚁金服从零开始自主研发的分布式关系数据库OceanBase上。为什么阿里巴巴/蚂蚁金服不是基于开源数据库,而是从零开始研发OceanBase?
【2010年数据库对淘宝/支付宝的制约】
【关系数据库的门槛】
【OceanBase的机会】
【为什么OceanBase没有基于已有的开源数据库进行开发】
【小结】
【2010年数据库对淘宝/支付宝的制约】
2010年的淘宝/支付宝(现在的阿里巴巴/蚂蚁金服)正在重构业务代码,以便把业务系统从商业数据库迁移到开源的MySQL上,数据库的硬件也从中高端服务器(小型机)和中高端存储(共享存储)迁移到普通PC服务器上。根据我当时的理解,原因有几个:
第一,昂贵的商业数据库软件成本。迅速发展的淘宝/支付宝,需要的数据库实例,在迅速增加。
第二,昂贵的商业数据库硬件(小型机和共享存储)成本。迅速发展的淘宝/支付宝,小型机和共享存储同样在迅速增加,硬件及其服务成本,也十分高昂。
第三,在高可用的要求下,数据库的主备镜像无法做到主库与备库完全一致。如果必须保证主库与备库完全一致,那么一旦备库异常或者主库备库之间的网络异常,数据库系统的写入就会被卡住;反之,如果允许主库与备库之间的事务不同步,一旦主库异常,则备库的数据通常就不完整。如果没有使用高可靠的硬件(例如高可靠服务器和高可靠存储),这个问题会频繁发生。

第四,传统数据库越来越无法容纳和处理互联网带来的飞速增长的数据,传统数据库这个“小引擎”无法容纳和处理这些海量的数据。

第五,业务发展被数据库严重制约。作为互联网/互联网金融公司,淘宝/支付宝需要对市场做出快速反应,数据库高昂的软件硬件成本使得其服务能力不能有很大的余量,小型机与共享存储的三个月甚至更长的购买、安装和调试周期成为了业务发展的严重桎梏,许多的促销或新业务因为数据库性能不足而被迫妥协甚至取消。
【关系数据库的门槛】
从关系数据库本身的特征来看,像OceanBase这样从零开始研制一款全新的关系数据库,看起来并不那么明智:
首先,关系数据库是一个非常成熟的产品,上个世界90年代中期之后,关系数据库的理论和产品都没有新的突破和大的变化。
其次,关系数据库是企业信息系统和生产经营系统的基石,关系数据库的任何异常,诸如功能失效、性能异常,都会妨碍企业的生产运作甚至使之陷入停顿,更不用说关系数据库的崩溃或者数据错误、数据丢失。
第三,关系数据库功能十分丰富、系统非常复杂,正确性与稳定性的挑战很大。商业的关系数据库和开源的关系数据库的正确性稳定性经过了20~30年的沉淀,数据库正确稳定与用户使用的关系类似于鸡与蛋的关系:没有被证明是正确稳定的数据库用户不愿意使用,而数据库的正确稳定只能通过用户使用来证明。
第四,关系数据库的性能挑战非常大,主要关系数据库厂商在性能提升上耗费了大量精力,投入了大量的资源。
因此无论是正确性、稳定性、功能还是性能几个方面来看,关系数据库都有很高的门槛(不是“门”,更多的是“槛”),“新玩家”进入十分困难:

从这个角度来讲,从零开始做一个数据库通常并不是一个好的选择。
【OceanBase的机会】
换一个角度来看,上述情况也正是OceanBase的机会:
第一,2010年数据库对淘宝/支付宝的制约,其实反映了以互联网为代表的新兴社会生产力对数据库的需求,例如传统的商业银行和商业门店,开业后连接数据库的终端数量是确定的,店面扩展、新开分店可能要半年甚至更长时间,对应数据库系统的扩容有足够的时间窗口。而互联网则完全不同,访问的用户数量无法确定,并且可能在几天甚至几小时内增长数倍,传统数据库的垂直扩展方式根本无法应对。

第二,数据库软件的正确性稳定性非常关键却又十分困难,但淘宝/支付宝有数以千计的数据库生产系统,完全能够把一个有价值的自研数据库打磨得非常稳定可靠。
第三,PC服务器和分布式技术给OceanBase提供了在大幅度降低数据库硬件成本的同时,进一步提升数据库可用性的机会,比如三副本和Paxos协议完全可以在单机/单机群故障的情况下避免数据丢失,并且保证服务持续可用(至多若干秒的服务中断)。

第四,PC服务器机群天然的水平扩展能力解决了数据库的小马(数据库引擎有限的容纳和处理能力)拉大车(海量数据)的尴尬局面,也消除了数据库对淘宝/支付宝的业务发展的制约。

第五,服务器内存的增加和固态盘(SSD)的普及为OceanBase提供了很好的机会。传统的数据库需要对硬盘进行大量的随机读和随机写,SSD擅长随机读而不擅长随机写,大量随机导致写入放大严重影响性能,同时影响SSD寿命,当前最新的“读写型”SSD则以增加成本和降低容量为代价。OceanBase采取了数据库的基线数据在硬盘(特别是SSD)、增量数据(增删改数据)在内存(辅以事务日志写盘)的模式,消除了硬盘的随机写,提升了性能。例如即使数据库一天10亿笔写事务,每笔1KB,总容量也不过1TB,分配到10台机器上,单机100GB,这个容量单机内存完全能够支撑。每天OceanBase的三个机群(zone)轮流地把内存数据批量整合到硬盘(称为每日“轮转合并”),正在整合的机群不对外提供服务(但接收事务日志并且参与Paxos投票),消除了每日合并对业务的影响。这个方案使得OceanBase得以使用比“读写型”SSD性价比高得多的“读密集型”SSD,降低了成本,却没有影响性能。每日合并批量写盘也对SSD十分友好,降低了SSD的故障率。

【为什么OceanBase没有基于已有的开源数据库进行开发】
基于成熟的开源数据库做二次开发,投入小、见效快,项目周期短、风险小。然而,由于开源数据库在技术方案上与商业数据库一脉相承,商业数据库厂商已经有了几十年的技术和生态积累,OceanBase在人力物力的投入上比领先商业数据库厂商低不止一个数量级,作为后来者在类似技术方案下在性能等方面超越先行者十分困难,这就好比在同样的路线上骑自行车去追赶跑车:

此外,基于已有的开源数据库进行二次开发,还会使得OceanBase丧失自己的一些关键优势,例如:
·消除随机写盘带来的性能提升。
·“读密集型”SSD带来的成本节省。
·传统关系数据库使用定长数据块,而OceanBase使用边长数据库,使用完全一样的数据压缩方法,OceanBase通常能够有50%的存储空间节省。
·传统关系数据库在刷脏页到硬盘的同时还在提供读写服务,而OceanBase每天轮转合并(参见“为什么OceanBase架构特别适合双十一”)的机群只接收事务日志和进行Paxos投票(其他机群提供读写服务),对CPU和硬盘IO消耗不敏感,因此不需要复杂的刷盘策略,也可以使用压缩速度较慢但压缩率较高的算法(通常还需要兼顾解压缩速度),以得到更好的压缩效果。
【小结】
从2010年5月调研、6月25日立项开始,OceanBase的目标就是商业关系数据库,虽然说一开始OceanBase的关系数据库的功能很弱:2012年底才支持简单的SQL,2014年也只支持比较有限的SQL,直到2016年基本兼容了MySQL,对SQL的支持才比较丰富。
时至今日,OceanBase的关系数据库内核才有了初步的模样,这使得OceanBase的架构优势开始显现,例如准内存数据库的性能优势,读密集型SSD的成本优势,三副本的高可用性优势,变长数据块的存储空间优势、每日合并时压缩倍率更高的压缩算法等等。这些都得益于OceanBase从零开始的研发以及对应的全新的架构。
15) TiDB
链接:https://www.zhihu.com/question/57369798/answer/192249563
现在我们已知的生产环境的用户已经超过100家。我说一下一些在线用户的实践及用法还有典型场景。
1) 替换 MySQL Sharding 作为主生产数据库
这个场景其实是 TiDB 设计的初衷,在单机 MySQL 数据量太大后,过去能选的基本就是分库分表,再分不开的话就只能 Sharding,但是分库分表 Sharding 其实不管是维护成本和开发改造成本都很高,所以 TiDB 给这些用户提供了一个可以弹性扩展的,用起来就像单机 MySQL 一样的,支持事务和复杂查询的分布式数据库,同时还支持多副本自动的高可用,当然很爽。
这部分用户一般一开始上线前都会用 TiDB 的 Syncer, 将 TiDB 集群作为线上 MySQL 的从库,实时同步线上的 MySQL 主库,观察一段时间稳定性兼容性、进行压力测试后,直接将线上库指向 TiDB,不用修改一行代码。
这类用户比如:
- Mobike,目前 TiDB 在摩拜部署了数套集群,近百个节点,承载着数十 TB 的各类数据,其中包括核心 OLTP 生产库。到现在已经稳定运行超过半年。TiDB 在摩拜单车在线数据业务的应用和实践
- 今日头条,目前 TiDB 在支撑今日头条的最核心的对象存储的元信息服务,写入大约几十万的 TPS,具体的数字就不方便透露了。
- 凤凰网,TiDB 在凤凰网新闻内容业务的创新实践
- 猿题库,TiDB 在猿辅导数据快速增长及复杂查询场景下的应用实践
- 360,TiDB 在 360 金融贷款实时风控场景应用
- 万达金融,TiDB 帮助万达网络科技集团实现高性能高质量的实时风控平台
等等.
2) 替换 HBase/C*/ES 等 NoSQL 数据库
这类用户主要是过去用着 NoSQL,希望在拥有弹性伸缩能力,可以线性扩展的实时并发写入能力,再能拥有更强大的查询能力,比如二级索引点查,比如复杂的 Join 支持。典型的应用场景是客服查询,User profile 系统等等。
通常这类用户的数据量巨大,可能单库都有上百 T,TiDB 能很好的满足:
- 大海捞针式的精准查询
- Ad-hoc 分析
这一切都是在不牺牲实时写入能力的同时拥有的。
一些客户案例:
- 去哪儿,去哪儿网机票团队用 TiDB 替换 HBase,Qunar 高速发展下数据库的创新与发展 - TiDB 篇
- 饿了么,饿了么内部已经部署了多套 TiDB 集群,甚至直接使用 TiKV 用来替换 C*, 案例的文章正在撰稿,近期会发布
3) 使用 TiDB 作为实时数据仓库
这类用户是我们在刚开始做 TiDB 的时候完全没想到的,随着 TiDB 的 SQL 能力越来越强,并且随着 TiDB 的子项目 TiSpark 的发布,让用户在拥有关系数据库的事务写入能力同时可以在同一份数据上进行复杂的分析;这类用户一般用 Syncer 将所有线上生产数据库同步到一个大的 TiDB 集群上(Syncer 支持多源同步,合并分库分表等功能),然后直接在这个 TiDB Cluster 上通过 TiDB 或者 TiSpark 进行分析。
一些典型的用户案例:
- 易果生鲜,TiDB / TiSpark 在易果集团实时数仓中的创新实践
- 盖娅互娱,日均数据量千万级,MySQL、TiDB 两种存储方案的落地对比
- 游族网络
坑已经基本踩得差不多了,惊喜倒是不少,每次用户发现我们,基本都是惊喜。。。
TiDB 简介
TiDB 是 PingCAP 公司受 Google Spanner / F1 论文启发而设计的开源分布式 NewSQL 数据库。
TiDB 具备如下 NewSQL 核心特性:
- SQL支持(TiDB 是 MySQL 兼容的)
- 水平弹性扩展(吞吐可线性扩展)
- 分布式事务
- 跨数据中心数据强一致性保证
- 故障自恢复的高可用
- 海量数据高并发实时写入与实时查询(HTAP 混合负载)
TiDB 的设计目标是 100% 的 OLTP 场景和 80% 的 OLAP 场景,更复杂的 OLAP 分析可以通过 TiSpark 项目来完成。
(联机事务处理OLTP(on-line transaction processing)、联机分析处理OLAP(On-Line Analytical Processing)。OLTP是传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,例如银行交易。OLAP是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果.)
TiDB 对业务没有任何侵入性,能优雅的替换传统的数据库中间件、数据库分库分表等 Sharding 方案。同时它也让开发运维人员不用关注数据库 Scale 的细节问题,专注于业务开发,极大的提升研发的生产力。
三篇文章了解 TiDB 技术内幕:
- 说存储
- 说计算
- 谈调度
TiDB 整体架构
要深入了解 TiDB 的水平扩展和高可用特点,首先需要了解 TiDB 的整体架构。

TiDB 集群主要分为三个组件:
TiDB Server
TiDB Server 负责接收 SQL 请求,处理 SQL 相关的逻辑,并通过 PD 找到存储计算所需数据的 TiKV 地址,与 TiKV 交互获取数据,最终返回结果。 TiDB Server 是无状态的,其本身并不存储数据,只负责计算,可以无限水平扩展,可以通过负载均衡组件(如LVS、HAProxy 或 F5)对外提供统一的接入地址。
PD Server
Placement Driver (简称 PD) 是整个集群的管理模块,其主要工作有三个: 一是存储集群的元信息(某个 Key 存储在哪个 TiKV 节点);二是对 TiKV 集群进行调度和负载均衡(如数据的迁移、Raft group leader 的迁移等);三是分配全局唯一且递增的事务 ID。
PD 是一个集群,需要部署奇数个节点,一般线上推荐至少部署 3 个节点。
TiKV Server
TiKV Server 负责存储数据,从外部看 TiKV 是一个分布式的提供事务的 Key-Value 存储引擎。存储数据的基本单位是 Region,每个 Region 负责存储一个 Key Range (从 StartKey 到 EndKey 的左闭右开区间)的数据,每个 TiKV 节点会负责多个 Region 。TiKV 使用 Raft 协议做复制,保持数据的一致性和容灾。副本以 Region 为单位进行管理,不同节点上的多个 Region 构成一个 Raft Group,互为副本。数据在多个 TiKV 之间的负载均衡由 PD 调度,这里也是以 Region 为单位进行调度。
核心特性
水平扩展
无限水平扩展是 TiDB 的一大特点,这里说的水平扩展包括两方面:计算能力和存储能力。TiDB Server 负责处理 SQL 请求,随着业务的增长,可以简单的添加 TiDB Server 节点,提高整体的处理能力,提供更高的吞吐。TiKV 负责存储数据,随着数据量的增长,可以部署更多的 TiKV Server 节点解决数据 Scale 的问题。PD 会在 TiKV 节点之间以 Region 为单位做调度,将部分数据迁移到新加的节点上。所以在业务的早期,可以只部署少量的服务实例(推荐至少部署 3 个 TiKV, 3 个 PD,2 个 TiDB),随着业务量的增长,按照需求添加 TiKV 或者 TiDB 实例。
高可用
高可用是 TiDB 的另一大特点,TiDB/TiKV/PD 这三个组件都能容忍部分实例失效,不影响整个集群的可用性。下面分别说明这三个组件的可用性、单个实例失效后的后果以及如何恢复。
TiDB
TiDB 是无状态的,推荐至少部署两个实例,前端通过负载均衡组件对外提供服务。当单个实例失效时,会影响正在这个实例上进行的 Session,从应用的角度看,会出现单次请求失败的情况,重新连接后即可继续获得服务。单个实例失效后,可以重启这个实例或者部署一个新的实例。
PD
PD 是一个集群,通过 Raft 协议保持数据的一致性,单个实例失效时,如果这个实例不是 Raft 的 leader,那么服务完全不受影响;如果这个实例是 Raft 的 leader,会重新选出新的 Raft leader,自动恢复服务。PD 在选举的过程中无法对外提供服务,这个时间大约是3秒钟。推荐至少部署三个 PD 实例,单个实例失效后,重启这个实例或者添加新的实例。
TiKV
TiKV 是一个集群,通过 Raft 协议保持数据的一致性(副本数量可配置,默认保存三副本),并通过 PD 做负载均衡调度。单个节点失效时,会影响这个节点上存储的所有 Region。对于 Region 中的 Leader 结点,会中断服务,等待重新选举;对于 Region 中的 Follower 节点,不会影响服务。当某个 TiKV 节点失效,并且在一段时间内(默认 10 分钟)无法恢复,PD 会将其上的数据迁移到其他的 TiKV 节点上。