对titanic.csv数据进行预测生死
数据集:http://download.csdn.net/detail/u010343650/9844427

survived:乘客最后的生存情况,这个是我们预测的目标变量 (0代表否,1代表是)
pclass:社会经济地位 (1代表上层阶级,2代表中层阶级,3代表底层阶级)
name:姓名
sex:性别
age:年纪
sibsp:船上兄弟姐妹或者配偶的数
parch:船上父母或者孩子的数量
ticket:船票的号码
fare:船票价格
检查数据的完整性 # coding:GBK
__author__ = 'Mouse'
import pandas as pd
full_data = pd.read_csv('titanic_dataset.csv')
print full_data.info() 
代码一:正确率60%-70%之间
# coding:GBK
__author__ = 'Mouse'
import sys
from sklearn.preprocessing import OneHotEncoder
from sklearn.preprocessing import LabelEncoder
reload(sys)
sys.setdefaultencoding('utf8')
from sklearn_test import *
def read_data(data_file):
data = pd.read_csv(data_file)
data = data.drop('ticket', axis=1) #删除票信息
data = data.drop('name', axis=1) #删除姓名
#one-hot编码
le_sex = LabelEncoder().fit(data['sex'])
sex_label = le_sex.transform(data['sex'])
ohe_sex = OneHotEncoder(sparse=False).fit(sex_label.reshape(-1, 1))
sex_ohe = ohe_sex.transform(sex_label.reshape(-1, 1))
data['sex_0'] = sex_ohe[:, 0]
data['sex_1'] = sex_ohe[:, 1]
data = data.drop('sex', axis=1)
train = data[:int(len(data)*0.6)]
test = data[int(len(data)*0.6):]
train_y = train.survived
train_x = train.drop('survived', axis=1)
test_y = test.survived
test_x = test.drop('survived', axis=1)
return train_x, train_y, test_x, test_y
if __name__ == '__main__':
data_file = "titanic_dataset.csv"
thresh = 0.5
model_save_file = None
model_save = {}
test_classifiers = ['NB', 'KNN', 'LR', 'RF', 'DT', 'SVM', 'SVMCV', 'GBDT']
classifiers = {'NB': naive_bayes_classifier,
'KNN': knn_classifier,
'LR': logistic_regression_classifier,
'RF': random_forest_classifier,
'DT': decision_tree_classifier,
'SVM': svm_classifier,
'SVMCV': svm_cross_validation,
'GBDT': gradient_boosting_classifier
}
print 'reading training and testing data...'
train_x, train_y, test_x, test_y = read_data(data_file)
for classifier in test_classifiers:
print '----------------------- %s ----------------------' % classifier
start_time = time.time()
model = classifiers[classifier](train_x, train_y)
print 'training took %fs!' % (time.time() - start_time)
predict = model.predict(test_x)
if model_save_file != None:
model_save[classifier] = model
#if is_binary_class:
precision = metrics.precision_score(test_y, predict)
recall = metrics.recall_score(test_y, predict)
print 'precision: %.2f%%, recall: %.2f%%' % (100 * precision, 100 * recall)
accuracy = metrics.accuracy_score(test_y, predict)
print 'accuracy: %.2f%%' % (100 * accuracy)
if model_save_file != None:
pickle.dump(model_save, open(model_save_file, 'wb'))
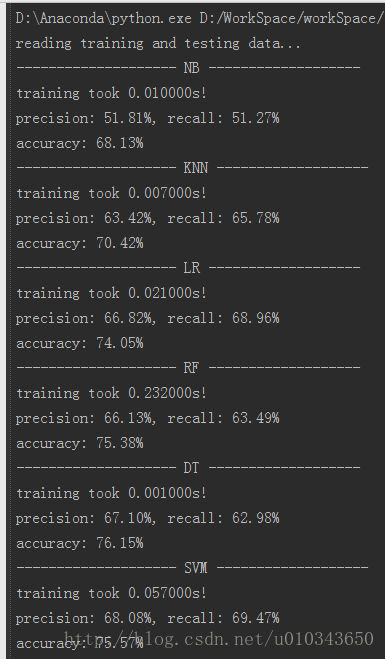
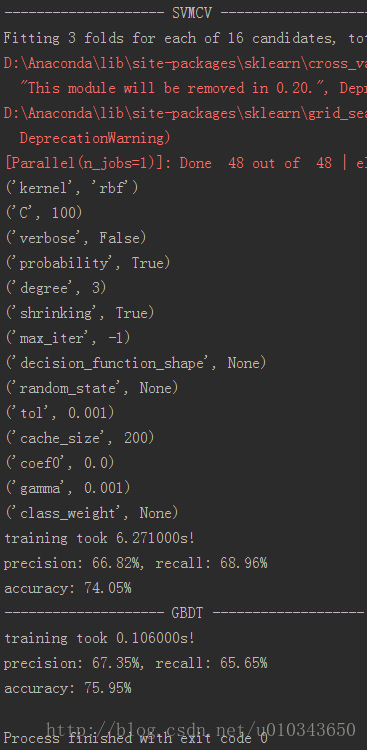
代码二:正确率68%-76%之间
# coding: utf-8
__author__ = 'Mouse'
import pandas as pd
from sklearn_test import *
full_data = pd.read_csv('titanic_dataset.csv', header =0 )
# 统计家庭成员的个数
full_data["familysize"] = full_data["sibsp"] + full_data["parch"] + 1
# 家庭成员(包括自己)等于一个人的为1,大于1人为0
full_data['is_alone'] = 0
full_data.loc[full_data['familysize'] == 1, 'is_alone'] = 1
# 替换性别,女 0,男 1
full_data['sex'] = full_data['sex'].map({'female': 0, 'male': 1}).astype(int)
# 费用化简
full_data.loc[full_data['fare'] <= 7.91, 'fare'] = 0
full_data.loc[(full_data['fare'] > 7.91) & (full_data['fare'] <= 14.454), 'fare'] = 1
full_data.loc[(full_data['fare'] > 14.454) & (full_data['fare'] <= 31), 'fare'] = 2
full_data.loc[full_data['fare'] > 31, 'fare'] = 3
full_data['fare'] = full_data['fare'].astype(int)
# 替换年龄
full_data.loc[full_data['age'] <= 16, 'age'] = 0
full_data.loc[(full_data['age'] > 16) & (full_data['age'] <= 32), 'age'] = 1
full_data.loc[(full_data['age'] > 32) & (full_data['age'] <= 48), 'age'] = 2
full_data.loc[(full_data['age'] > 48) & (full_data['age'] <= 64), 'age'] = 3
full_data.loc[full_data['age'] > 64, 'age'] = 4
full_data['age'] = full_data['age'].astype(int)
# 选出我认为重要的特征作为数据集和测试集
drop_elements = ['name', 'ticket', 'sibsp', 'parch', 'familysize']
full_data = full_data.drop(drop_elements, axis=1)
# 划分数据集 前百分之60的数据用于训练数据,后百分之40的数据用于测试
train = full_data[:int(len(full_data) * 0.6)]
test = full_data[int(len(full_data) * 0.6):]
X_train = train.values[:, 1::] # 除去survived
y_train = train.values[:, 0] # 只有survived
X_test = test.values[:, 1::]
y_test = test.values[:, 0]
model_save_file = None
model_save = {}
test_classifiers = ['NB', 'KNN', 'LR', 'RF', 'DT', 'SVM', 'SVMCV', 'GBDT']
classifiers = {'NB': naive_bayes_classifier, # 朴素贝叶斯分类
'KNN': knn_classifier, # 邻近算法
'LR': logistic_regression_classifier, # LR分类器
'RF': random_forest_classifier, # 随机森林
'DT': decision_tree_classifier, # 决策树
'SVM': svm_classifier, # 向量机
'SVMCV': svm_cross_validation, # 交叉验证
'GBDT': gradient_boosting_classifier # 梯度提升决策树
}
print('reading training and testing data...')
for classifier in test_classifiers:
print('-------------------- %s -------------------' % classifier)
start_time = time.time()
model = classifiers[classifier](X_train, y_train)
print('training took %fs!' % (time.time() - start_time))
predict = model.predict(X_test)
if model_save_file != None:
model_save[classifier] = model
# 正确率 = 提取出的正确信息条数 / 提取出的信息条数
# P = TP/(TP+FP)
precision = metrics.precision_score(y_test, predict, average='macro')
# 召回率 = 提取出的正确信息条数 / 样本中的信息条数
# R = TP/(TP+FN) = 1 - FN/T
recall = metrics.recall_score(y_test, predict, average='macro')
print('precision: %.2f%%, recall: %.2f%%' % (100 * precision, 100 * recall))
# A = (TP + TN)/(P+N)
accuracy = metrics.accuracy_score(y_test, predict)
print('accuracy: %.2f%%' % (100 * accuracy))