MySQL索引的失效场景
今天在工作中遇到索引失效的场景,这里记录一下,因为工作的sql不方便贴上,线下创建测试表进行复现
一、准备实验数据
CREATE TABLE `test_order` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`order_name` varchar(20) NOT NULL DEFAULT '' COMMENT '订单名称',
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '订单创建时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;一张订单表,包含 订单id,订单名称,订单创建时间三个字段
创建存储过程用于插入数据
create procedure insertBatch()
begin
declare i int;
set i=1;
while i<=10 do
insert into test_order(order_name) values(concat('test-',i));
set i=i+1;
end while;
end; == 数据量不多,十条,执行存储过程插入
call insertBatch();数据库中数据如下
mysql> select * from test_order
-> ;
+----+------------+---------------------+
| id | order_name | create_time |
+----+------------+---------------------+
| 11 | test-1 | 2019-10-26 21:20:48 |
| 12 | test-2 | 2019-10-26 21:20:48 |
| 13 | test-3 | 2019-10-26 21:20:48 |
| 14 | test-4 | 2019-10-26 21:20:48 |
| 15 | test-5 | 2019-10-26 21:20:48 |
| 16 | test-6 | 2019-10-26 21:20:48 |
| 17 | test-7 | 2019-10-26 21:20:48 |
| 18 | test-8 | 2019-10-26 21:20:48 |
| 19 | test-9 | 2019-10-26 21:20:48 |
| 20 | test-10 | 2019-10-26 21:20:48 |
+----+------------+---------------------+
10 rows in set (0.00 sec)此时对test_order 表的order_name 和 create_time 字段均加上索引
alter table test_order add index idx_time(create_time);
alter table test_order add index idx_name(order_name); 再次查看表结构,索引的确是加上了
CREATE TABLE `test_order` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`order_name` varchar(20) NOT NULL DEFAULT '' COMMENT '商品名称',
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '商品创建时间',
PRIMARY KEY (`id`),
KEY `idx_name` (`order_name`),
KEY `idx_time` (`create_time`)
) ENGINE=InnoDB AUTO_INCREMENT=21 DEFAULT CHARSET=utf8二、开始测试不同的sql索引命中情况
1. 如果要根据商品名称进行检索,我们使用sql
select * from test_order where order_name='test';在sql前加 explain 查看执行计划
mysql> explain select * from test_order where order_name='test'\G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: test_order
type: ref
possible_keys: idx_name
key: idx_name
key_len: 62
ref: const
rows: 1
Extra: Using index condition
1 row in set (0.00 sec)我们关注 possible_keys 和 key 两个列,都为 idx_name ,说明这个sql在执行中可选的索引idx_name ,最终使用的也是该列,该次测试索引命中,符合预期
2.如果要根据create_time 时间范围进行检索
select * from test_order where create_time < '2019';查看执行计划
mysql> explain select * from test_order where create_time < '2019'\G; *************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: test_order
type: ALL
possible_keys: idx_time
key: NULL
key_len: NULL
ref: NULL
rows: 10
Extra: Using where
1 row in set, 2 warnings (0.00 sec)竟然没有命中
这个问题纠结了很久,最终通过搜索相关sql的资料,得出的结论是, timestamp在数据库中存储的实际上是时间戳,通过select 查询出来的格式 yyyy-HH-dd HH:mm:ss 实际是mysql服务引擎转换后的,既然是这样,那么查询索引的时候,我们输入的yyyy-HH-dd HH:mm:ss 也会被转换成时间戳,然后再去检索mysql的索引,所以我们输入的 '2019' 不是规范的 yyyy-HH-dd HH:mm:ss 格式,是不能去检索索引的。
我们尝试来验证
使用
explain select * from test_order where create_time < '2019-01-01 00:00:00'\G;执行计划为
mysql> explain select * from test_order where create_time < '2019-01-01 00:00:00'\G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: test_order
type: range
possible_keys: idx_time
key: idx_time
key_len: 4
ref: NULL
rows: 1
Extra: Using index condition
1 row in set (0.00 sec)此时已经命中 idx_time 索引,我们的猜想正确
3.同样是按照日期进行检索,我们换个条件
explain select * from test_order where create_time > '2019-01-01 00:00:00'\G;这里我只是将上个例子中的create_time < '2019-01-01 00:00:00' 换成了 create_time > '2019-01-01 00:00:00'
仅此而已,我们看看执行计划
explain select * from test_order where create_time > '2019-01-01 00:00:00'\G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: test_order
type: ALL
possible_keys: idx_time
key: NULL
key_len: NULL
ref: NULL
rows: 10
Extra: Using where
1 row in set (0.00 sec)此时key为 NULL!!我只是查询语句换了个大于小于,竟然不能命中了,震惊
通过搜索一大波资料,终于找到原因:mysql在使用索引时,如果预估数据超过了20%,则不选择命中索引,直接扫描全表
为了验证这个结论,我们将表的数据稍作修改
+----+------------+---------------------+
| id | order_name | create_time |
+----+------------+---------------------+
| 11 | test-1 | 2019-10-26 21:20:40 |
| 12 | test-2 | 2019-10-26 21:20:40 |
| 13 | test-3 | 2019-10-26 21:20:48 |
| 14 | test-4 | 2019-10-26 21:20:48 |
| 15 | test-5 | 2019-10-26 21:20:48 |
| 16 | test-6 | 2019-10-26 21:20:48 |
| 17 | test-7 | 2019-10-26 21:20:48 |
| 18 | test-8 | 2019-10-26 21:20:48 |
| 19 | test-9 | 2019-10-26 21:20:48 |
| 20 | test-10 | 2019-10-26 21:20:48 |
+----+------------+---------------------+执行如下的sql,此时应该查询到的数据为 id 11和12的列,占20%
explain select * from test_order where create_time<'2019-10-26 21:20:48';此时结果,命中索引idx_time
mysql> explain select * from test_order where create_time<'2019-10-26 21:20:48'\G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: test_order
type: range
possible_keys: idx_time
key: idx_time
key_len: 4
ref: NULL
rows: 3
Extra: Using index condition
1 row in set (0.00 sec)将<改为 <=,此时肯定会命中所有的数据
explain select * from test_order where create_time<='2019-10-26 21:20:48';此时结果为
mysql> explain select * from test_order where create_time<='2019-10-26 21:20:48'\G;
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: test_order
type: ALL
possible_keys: idx_time
key: NULL
key_len: NULL
ref: NULL
rows: 10
Extra: Using where
1 row in set (0.00 sec)key 为NULL,没有命中索引,所以这里也验证了刚才的说法,为什么mysql的索引会有这个优化的策略呢
首先mysql innodb的索引原理图如下
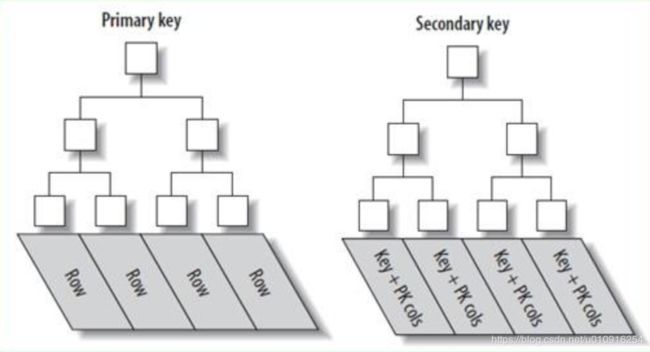
我们这里的主键索引是 id, 二级索引是 create_time ,根据create_time 去扫描数据,如果走索引,则是从二级索引查询到id值,再去主键索引中根据id值取到目标数据,所以会有一次 回表 的过程,如果我们要检索的create_time 数据区间很大,目标数据查过20% ,则这20%的数据在 二级索引 查询后还需查询 主键索引,索引mysql 对此进行优化,对检索超过20%数据的sql不走二级索引,直接 扫描全表,这样效率会比过两次索引,最终取到目标数据更高。
三、总结
1.mysql innodb的timestamp字段使用索引时,查询条件必须为 yyyy-MM-dd HH:mm:ss 格式,索引才能生效
2.mysql innodb 的 任何二级索引查询,目标数据量过大(一般是超过20%),mysql优化器会选择不走索引,扫描全表