一文了解 Zookeeper 基本原理与应用场景
Zookeeper 是一个高性能、高可靠的分布式协调系统,是 Google Chubby 的一个开源实现,目前在分布式系统、大数据领域中使用非常广泛。本文将介绍 Zookeeper 集群架构、数据模型、监听机制,以及Zookeeper典型的应用场景等。
1. Zookeeper 集群角色
首先介绍下 Zookeeper 集群,一个 Zookeeper 集群通常由一组机器组成,一般3~5台集群就可以组成一个 Zookeeper 集群。集群拓扑图基本如下:
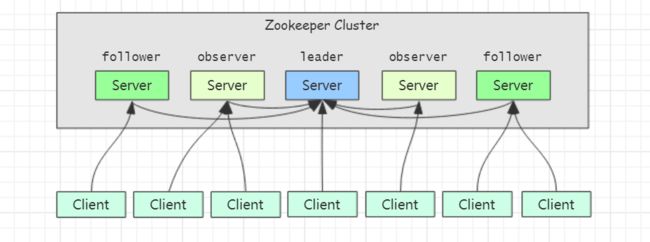
Zookeeper 集群中每一个节点都会在内存中维护当前的节点状态,并且彼此之间保持着通信。这里说明一点,只要集群中存在过半的节点正常工作,整个集群就能够对外提供服务。
如上图,在 Zookeeper 集群中,有 Leader、Follower 和 Observer 三种类型的角色。
Leader
Leader 节点整个 Zookeeper 集群工作机制中的核心,主要工作是处理客户端的读写请求,及集群内部各服务的调度。注意只有 leader 能够处理写请求。
Follower
处理客户端的读请求,将写请求转发给 leader。参与 leader 选举投票等。
Observer
这是自 Zookeeper 3.3.0 版本引入的一个新的角色,主要是为了解决大规模 Server 场景下因 leader 选举投票成本增加导致写性能下降的问题。Observer 的工作原理和 follower 基本一致。处理客户端的读请求,将写请求转发给leader。和 follower 唯一的区别在于,Observer 不参与任何形式的选举,包括 leader 选举。
一般而言,中小型规模的 Zookeeper 集群中只包含 leader 和 follower 两个角色,这容易让我们忽略 observer 角色的存在。配置一个节点为 observer 也很简单,只需如下两步:
# 在observer节点的配置文件中添加如下配置
peerType=observer
# 在每个节点的配置文件中,给observer节点添加:observer标识
# 例如:
server.1:localhost:2181:3181:observer
至此,相信你对 Zookeeper 的集群架构与相关角色有了一定认识。
2. Zookeeper 数据模型
Zookeeper 的数据模型是一棵类似 Unix 文件系统的 ZNode Tree 即 ZNode 树,但是没有引入传统文件系统的目录或者文件等概念,而是使用了称为 “数据节点” 的概念,术语叫做 ZNode。ZNode 是 Zookeeper 存储数据的最小单元,每个 ZNode 可以保存数据,也可以挂载子节点,其中根节点是 /。示意图如下:

使用过 Zookeeper 的同学应该都知道,Zookeeper 主要提供了两个核心功能:
-
管理(存储、读取)客户端提交的数据;
-
为客户端提供数据节点的监听服务;
这里就涉及到 Zookeeper 的两个重要特性,就是它的 ZNode 模型与 Watcher 机制。
ZNode 模型
前面讲到 Zookeeper 是由数据节点 ZNode 构成的,Zookeeper 中的每个数据节点都是有生命周期的,其生命周期的长短取决于 ZNode 的节点类型。ZNode 根据其生命周期和特点可分为 4 类。
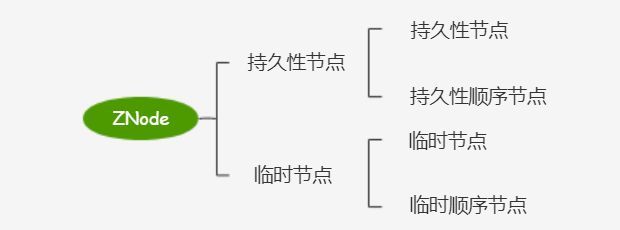
分别是:
-
持久性节点(PERSISTENT):客户端与 Zookeeper 断开会话后,该节点依旧存在,直到执行删除操作才会清除节点。
-
持久性顺序节点(PERSISTENT_SEQUENTIAL):另一种持久节点,Zookeeper 会给该节点名称加上一个数字后缀,进行顺序编号。
-
临时节点(EPHEMERAL):节点的生命周期和客户端的会话绑定在一起,客户端与 Zookeeper 断开会话后,该节点就会被自动删除。各个场景中很多都是利用 Zookeeper 临时节点这个特性的。
-
临时顺序节点(EPHEMERAL_SEQUENTIAL):概念和上面类似,Zookeeper 也会给该节点进行顺序编号。
前面提及了 ZNode 是存储数据的最小单元,除了存储用户数据外,ZNode 还有以下特点:
-
包含 ZNode 修改/访问的时间、事务id(zxid),ACL 权限、版本等状态信息;
-
所有的事务请求在 ZNode 端都是顺序和原子性的;
-
数据主要存储在内存中,磁盘中保存事务日志、快照数据等;
Watcher 机制
Watcher 机制也称监听机制,它是 Zookeeper 的关键特性,是通过 ZooKeeper 实现分布式发布/订阅、分布式锁、集群管理等功能的基础。
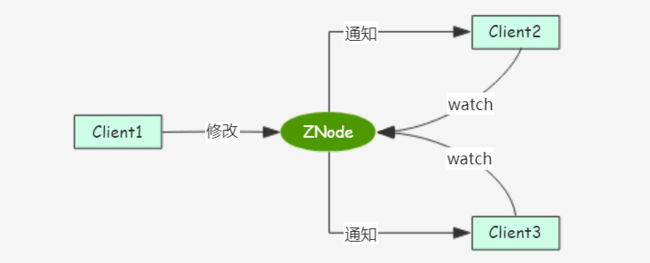
如上图所示,Zookeeper 允许客户端向服务端注册一个 Watcher 监听器,当服务端的一些指定事件触发了该监听,比如节点创建、删除,节点数据变更等事件,Zookeeper 就会向注册了监听器的客户端发送相应的事件通知。
3. 代码演示 Zookeeper 监听器
接下来我们看一下通过 Zookeeper 原生的客户端 API,创建 ZNode 数据节点,然后演示下 Zookeeper 监听器的基本使用。
引入依赖
首先,当前有一个包含3个节点的 Zookeeper 集群,我们根据 Zookeeper 版本引入了相应依赖,如下
org.apache.zookeeper
zookeeper
3.4.5
演示代码
-
创建 ZNode
private final String ZK_ADDRS = "server01:2181,server02:2181,server03:2181";
private final int SESSION_TIMEOUT = 5000;
private String znodePath = "/my_node";
@Test
public void createZNode() throws IOException, KeeperException, InterruptedException {
//创建zookeeper客户端
ZooKeeper zkClient = new ZooKeeper(ZK_ADDRS, SESSION_TIMEOUT, watchedEvent -> {});
//判断节点是否存在
Stat exist = zkClient.exists(znodePath, false);
if (exist == null){
//创建一个持久节点并写入数据,完全放开acl权限
zkClient.create(znodePath, "123".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
}
//关闭zookeeper连接
zkClient.close();
}(可左右滑动)
执行完这个单元测试后,我们通过命令行在服务端查看一下该数据节点:
[zk: localhost:2181(CONNECTED) 48] get /my_node
123
cZxid = 0xdb6439ef2
ctime = Fri Feb 27 21:08:09 CST 2020
mZxid = 0xdb6439ef2
mtime = Fri Feb 27 21:08:09 CST 2020
pZxid = 0xdb6439ef2
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 3
numChildren = 0-
删除 ZNode 节点,并监听该节点的删除动作
@Test
public void TestWatcher() throws IOException, KeeperException, InterruptedException {
//创建zookeeper客户端,并注册一个监听器
ZooKeeper zkClient = new ZooKeeper(ZK_ADDRS, SESSION_TIMEOUT, new Watcher() {
@Override
public void process(WatchedEvent watchedEvent) {
//监听指定节点删除事件
if (watchedEvent.getType() == Event.EventType.NodeDeleted &&
watchedEvent.getPath().equals(znodePath)){
log.info(String.format("注意:ZNode '%s' is deleted !", znodePath));
}
}
});
//判断节点是否存在,同时注册了一个 watcher
Stat exist = zkClient.exists(znodePath, true);
if (exist != null){
//删除节点
zkClient.delete(znodePath, -1);
}
//关闭zookeeper连接
zkClient.close();
}(可左右滑动)
代码执行后,可以看到控制台打印出了我们的日志:
21:41:07.870 [main-EventThread] INFO xxx - 注意:ZNode '/my_node' is deleted !
服务端查看该节点也已经不存在了:
[zk: localhost:2181(CONNECTED) 50] get /my_node
Node does not exist: /my_node这里我们简单演示了下 Zookeeper 原始 API、监听器的使用,希望通过这个简单的demo,我们能对 Zookeeper 监听器有一个比较直观的认识。
4. Zookeeper 应用场景
Zookeeper 在分布式系统、大数据领域里应用广泛,这里总结了 8 个典型的应用场景:
数据发布/订阅
即所谓的配置管理或配置中心,拓扑图如下:

通常在分布式系统或集群中,所以节点的配置应该一致,比如Hadoop集群,要求对配置的修改,能够快速同步到各个节点中,可以通过 Zookeeper 实现:
-
将配置信息写入 ZooKeeper 的一个 ZNode 中;
-
各个节点在启动阶段从 Zookeeper 中获取配置,并注册一个数据变更的 Watcher 监听器;
-
当 ZNode 中的数据被修改,ZooKeeper 将通知各个客户端节点,节点收到通知后进行配置更新;
负载均衡
负载均衡通常是一种动态的服务配置,拓扑图:
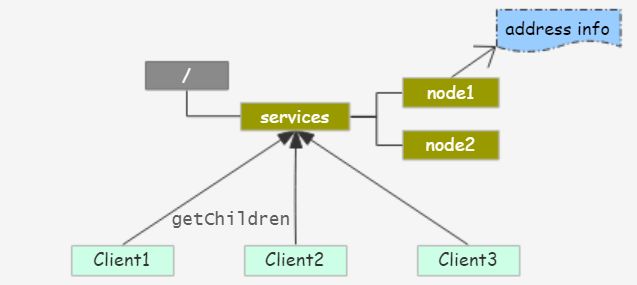
通常包含两部分:
-
服务注册,服务提供者启动时会在某一个根 ZNode 节点下创建属于自己的子节点,并写入一些服务信息 比如IP:Port信息;
-
服务解析,服务使用者在请求服务时会先获取根 ZNode 节点的子节点列表,即服务列表,然后通过一定的负载均衡算法 比如hash选取一个服务访问;
命名服务
又称 nameservice,这是比较常见的场景,Zookeeper 的命令服务主要有两个方向的应用:
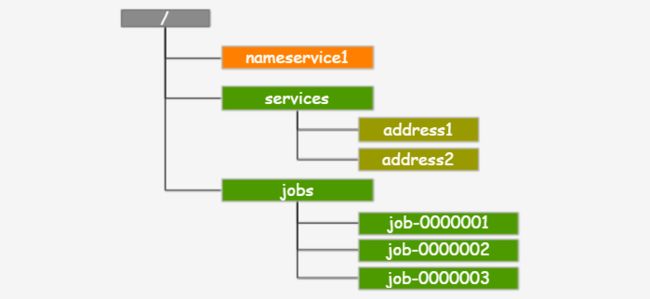
-
提供类似 JNDI 的功能:就是把各种服务的名称,地址及其他信息放到 Zookeeper 中,使用时去读取,实现资源的定位和使用;
-
利用 Zookeeper 顺序节点的特性,生成分布式的全局唯一 ID;
分布式协调/通知
主要是利用了 Zookeeper Watcher 的注册与异步通知机制,通常的做法是不同客户端都对 Zookeeper 的一个数据节点进行 Watcher 注册,监听数据的变化,当数据节点发生变化时,所有订阅的客户端都能接到通知并做相应处理。常见场景比如:
-
Master 节点定期检测 Slave 节点的状态,类似于心跳检测机制;
-
信息推送,相当于一个发布订阅系统,和第一个场景类似;
集群管理

主要包括两部分功能
-
记录当前集群中有多少个节点在工作,以及节点的运行状态;
-
对集群中的节点进行上下线方面的操作;
Master 选举
Master 选举是一个分布式系统中非常常见的场景,这里是利用 Zookeeper 的强一致性,保证只有一个客户端能够创建节点成功。

分布式锁
不同节点上的服务,可能需要同时访问一个资源,这事可能需要一把分布式锁。使用 Zookeeper 实现分布式锁主要基于以下特性:
-
ZooKeeper 的强一致性,保证只有一个客户端能够创建锁成功。
-
锁的独占性,创建 ZNode 成功的客户端才能得到锁,其他客户端只能等待,当客户端用完释放锁时,其他客户端再次尝试创建 ZNode,获取分布式锁。
分布式队列
利用 Zookeeper 主要能够实现两种分布式队列:
-
当一个队列的成员都聚齐时,这个队列才可用,否则一直等待所有成员到达,这种是同步队列。 比如一个 job 由多个 task 组成,只有所有 task 完成后,job 才运行完成,可为 job 创建一个 /job 目录,然后在该目录下,为每个完成的 task 创建一个临时的 ZNode,一旦临时节点数目达到 task 总数,则表明 job 运行完成。
-
利用 Zookeeper 的临时顺序节点特性,实现 FIFO 即先进先出的队列。
5. 总结
本文介绍了 Zookeeper 的集群架构,ZNode 数据模型,Watcher 监听机制,以及 Zookeeper 的典型应用场景。Zookeeper 在分布式系统应用非常广泛,主流的大数据组件比如HDFS、HBase、Kafka等也依靠 Zookeeper 做协调服务。通过本文的介绍,相信我们对 Zookeeper 有了进一步的掌握。
往期文章精选:
1、如何快速全面掌握Kafka?5000字吐血整理
2、一文读懂 HBase 核心原理与应用场景
3、京东JDHBase异地多活实践
4、美团点评基于 Flink 的实时数仓平台实践

如果您喜欢这篇文章,点【在看】与转发都是一种鼓励,期待得到您的认可 ❥(^_-)