Java9.0 HashMap源码阅读记录
- 关注点
- 结构
- 继承体系
- 属性
- 构造器
- 结点结构
- 哈希值计算
- 添加元素
- 查找元素
- 删除元素
- 扩容处理
- 红黑树
- 红黑树
- 转化函数
- 示例
- 添加数据
- 删除数据
- 获取数据
- 遍历数据
- 遍历节点(迭代器)
- 遍历节点(foreach)
- 遍历Key(迭代器)
- 遍历value
- 总结
- 相关文章
关注点
| 关注点 | Are |
|---|---|
| HashMap结构 | 数组+链表 或者 数组+红黑树 |
| 是否允许重复数据 | key重复会覆盖,value可以重复 |
| 是否允许null值 | key和value都允许null值 |
| 是否线程安全 | 非线程安全 |
结构
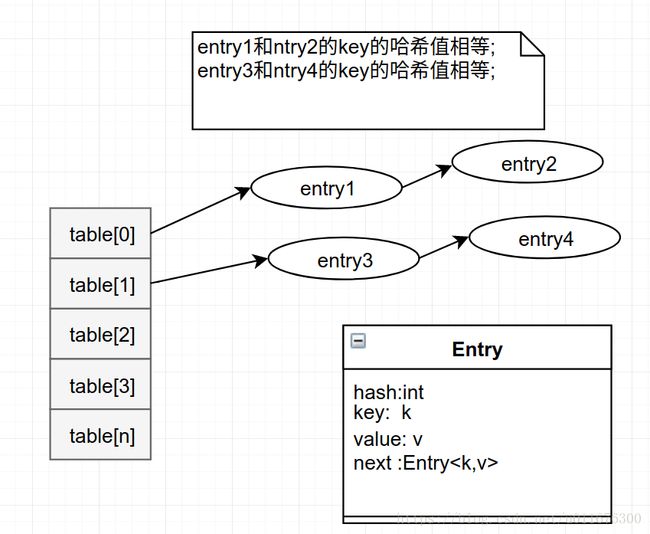
HashMap是一种散列表,通过计算key的哈希值获取其在数组中的索引位置,如果不同key计算的索引位置一样,那么多个键-值节点将会在该索引位置以链表的形式存在,为了提高性能,如果该索引位置的节点数达到8个,那么将会将该索引位置的链表结构转换为红黑树.这将会提高查找插入等性能.
继承体系
public class HashMap<K,V> extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable HashMap继承的是AbstractMap.
属性
//Node为键值对定义的类
//HashMap使用数组保存
transient Node[] table;
transient Set> entrySet;
//实际的键值对数量
transient int size;
//修改的次数,用于判断迭代过程中是否被改变
transient int modCount;
//扩容的阀值threshold = capacity * load factor
int threshold;
//加载因子,会影响性能和空间
final float loadFactor; 官方对loadFactor取值为0.75,该值提供了相对比较好的性能和空间开销.
对于loadFactor个人的理解:
1.如果太小,比如为0.2,初始容量为16;
当容量超过16*0.2=3.2时就会进行扩容,也就是16-3=13的空间没有被利用,浪费了空间,同时过小也会导致频繁地扩容,导致性能下降.
2.如果过大,比如为1.
由于HashMap和Hashtable是以数组+链表的形式存放数据,不同的key可能会出现计算的哈希值一样,而索引位置是通过哈希值与数组长度相与得到(table.length& hash),也就会存在相同的数组索引位置,也就是出现哈希冲突,假如数组容量是16,你保存的16个键值对计算的数组索引值是0,也就是说所有的数据都保存在table[0]处,由于每次变更查找数据都要比较哈希值和key,这就会导致性能下降.
构造器
//指定初始容量和加载因子(0-1)
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
//指定初始容量,默认loadFactor为0.75
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
//无参构造器,默认初始容量为0.默认loadFactor为0.75
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
//由其他Map进行数据初始化
public HashMap(Map m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false);
}
结点结构
可以看出节点是一个链表结构
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node next;
} 哈希值计算
由于一般使用String作为key的类型,String已经重写了hashCode()方法
String再根据不同的字符编码来选择不同的计算方法.
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
hash = h = isLatin1() ? StringLatin1.hashCode(value)//单字节编码
: StringUTF16.hashCode(value);//双字节编码
}
return h;
}
//StringLatin1.hashCode(value) 单字节编码
public static int hashCode(byte[] value) {
int h = 0;
for (byte v : value) {
h = 31 * h + (v & 0xff);
}
return h;
}
//StringUTF16.hashCode(value) 双字节编码
public static int hashCode(byte[] value) {
int h = 0;
int length = value.length >> 1;
for (int i = 0; i < length; i++) {
h = 31 * h + getChar(value, i);
}
return h;
}获取数组索引位置
index = (tab.length - 1) & hash;添加元素
获取哈希值,并调用putVal进行插入
如果链表的长度达到8,则将该链表转化为TreeNode(红黑树结构)
这里有两个疑问就是:
1.
Hashtable 获取index = hash % tab.length
HashMap获取index = hash & (tab.length-1)
从效率上来讲并不差多少,但是HashMap的方式会导致出现哈希冲突概率增大,导致整体性能降低.不知道官方为什么这么写.
2.既然HashMap不会允许重复key存在,为什么在进行判断时不只是判断key,还要判断key的hash值,毕竟数组的索引位置已经定了.
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node[] tab; Node p; int n, i;
//如果数组为null或者容量为0,则进行扩容
if ((tab = table) == null || (n = tab.length) == 0)
//扩容处理,
n = (tab = resize()).length;
//n为扩容后的容量
//哈希值与(长度-1)相与,确保得到的索引在数组的索引范围内.
if ((p = tab[i = (n - 1) & hash]) == null)
//如果当前索引位置还没有任何对象加入,添加
tab[i] = newNode(hash, key, value, null);
else {
Node e; K k;
//此时p是当前索引位的第一个node引用
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
//为什么不能直接比较key??????????????
//如果是第一个节点的key,获取该引用,后面再赋值
e = p;
else if (p instanceof TreeNode)
//如果是TreeNode(红黑树)类型,则通过putTreeVal添加元素
e = ((TreeNode)p).putTreeVal(this, tab, hash, key, value);
else {
//寻找相同的key,如果不存在相同的key,就在链表尾插入数据
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
//如果未找到相同的key,则插入新的节点
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
//如果链表的长度达到8,则将该链表转化为TreeNode(红黑树结构)
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
//如果找到相同的key,退出循环,后面再进行赋值
break;
p = e;
}
}
//进行赋值处理
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
//空函数,貌似没什么用
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
//如果链表的数据长度超过阀值,则进行扩容处理
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
} 查找元素
1.通过(tab.length - 1) & hash获取索引位置;
2 . 再通过查询链表定位
public V get(Object key) {
Node e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node getNode(int hash, Object key) {
Node[] tab; Node first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
//定位
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
//如果是第一个节点
return first;
//不是第一个节点
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
删除元素
public V remove(Object key) {
Node e;
return (e = removeNode(hash(key), key, null, false, true)) == null ?
null : e.value;
}
final Node removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node[] tab; Node p; int n, index;
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
Node node = null, e; K k; V v;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
node = p;
else if ((e = p.next) != null) {
if (p instanceof TreeNode)
node = ((TreeNode)p).getTreeNode(hash, key);
else {
do {
if (e.hash == hash &&
((k = e.key) == key ||
(key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
if (node != null && (!matchValue || (v = node.value) == value ||
(value != null && value.equals(v)))) {
if (node instanceof TreeNode)
((TreeNode)node).removeTreeNode(this, tab, movable);
else if (node == p)
tab[index] = node.next;
else
p.next = node.next;
++modCount;
--size;
afterNodeRemoval(node);
return node;
}
}
return null;
} 扩容处理
1.新的容量是旧容量的两倍,新的扩容阀值是旧的扩容阀值两倍.
2.将旧table上的各个节点数据搬到新的table
final Node[] resize() {
Node[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
//两倍扩容
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node[] newTab = (Node[])new Node[newCap];
table = newTab;
if (oldTab != null) {
//扩容处理
for (int j = 0; j < oldCap; ++j) {
Node e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode)e).split(this, newTab, j, oldCap);
else { // preserve order
Node loHead = null, loTail = null;
Node hiHead = null, hiTail = null;
Node next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
红黑树
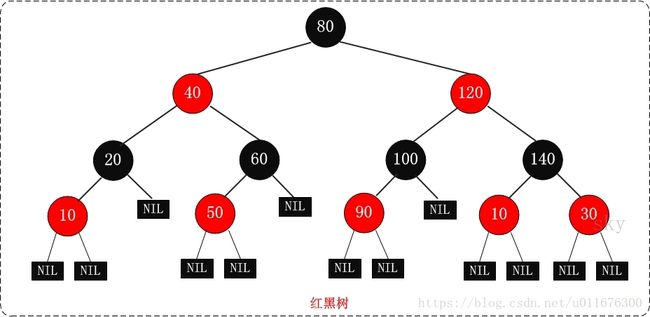
在JDK1.8之前,Java仅采用链表解决散列冲突,因此,在最坏情况下,假定所有节点关键字的hash值都相等,则所有节点插入同一槽位,导致HashMap退化为该槽位的链表,查找节点的时间复杂度为O(n)。JDK1.8在解决散列冲突时引入了红黑树,在某槽位的链表长度超过限额(8)之后,则将链表转换为红黑树。通过上一节的描述,我们知道红黑树能够保证最坏情况的操作时间复杂度为O(Log(n)),因此,使得HashMap在散列冲突时的性能有较大程度的提升
红黑树
红黑树原理
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
//父节点
TreeNode parent; // red-black tree links
//左节点
TreeNode left;
//右节点
TreeNode right;
TreeNode prev; // needed to unlink next upon deletion
//节点颜色
boolean red;
} 几个重要的参数
一个索引位置的树化阈值
当该位置链表中元素个数超过这个值时,需要使用红黑树节点替换链表节点
这个值必须为 8,要不然频繁转换效率也不高
static final int TREEIFY_THRESHOLD = 8;一个树的链表还原阈值
当扩容时,桶中元素个数小于这个值,就会把树形的元素 还原(切分)为链表结构
这个值应该比上面那个小,至少为 6,避免频繁转换
static final int UNTREEIFY_THRESHOLD = 6;哈希表的最小树形化容量
当哈希表中的容量大于这个值时,表中的桶才能进行树形化
否则桶内元素太多时会扩容,而不是树形化
为了避免进行扩容、树形化选择的冲突,这个值不能小于 4 * TREEIFY_THRESHOLD
static final int MIN_TREEIFY_CAPACITY = 64;转化函数
当每个索引位置链表节点达到8个时就会将链表转化为红黑树
1.根据哈希表中元素个数确定是扩容还是树形化
2.如果是树形化,遍历桶中的元素,创建相同个数的树形节点,复制内容,建立起联系,然后让桶第一个元素指向新建的树头结点,替换桶的链表内容为树形内容
3.之前的操作并没有设置红黑树的颜色值,现在得到的只能算是个二叉树。在 最后调用树形节点 hd.treeify(tab) 方法进行塑造红黑树
final void treeifyBin(Node[] tab, int hash) {
int n, index; Node e;
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
else if ((e = tab[index = (n - 1) & hash]) != null) {
TreeNode hd = null, tl = null;
do {
TreeNode p = replacementTreeNode(e, null);
if (tl == null)
hd = p;
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
if ((tab[index] = hd) != null)
hd.treeify(tab);
}
} 塑造红黑树
final void treeify(Node[] tab) {
TreeNode root = null;
for (TreeNode x = this, next; x != null; x = next) {
next = (TreeNode)x.next;
x.left = x.right = null;
if (root == null) {
x.parent = null;
x.red = false;
root = x;
}
else {
K k = x.key;
int h = x.hash;
Class kc = null;
for (TreeNode p = root;;) {
int dir, ph;
K pk = p.key;
if ((ph = p.hash) > h)
dir = -1;
else if (ph < h)
dir = 1;
else if ((kc == null &&
(kc = comparableClassFor(k)) == null) ||
(dir = compareComparables(kc, k, pk)) == 0)
dir = tieBreakOrder(k, pk);
TreeNode xp = p;
if ((p = (dir <= 0) ? p.left : p.right) == null) {
x.parent = xp;
if (dir <= 0)
xp.left = x;
else
xp.right = x;
root = balanceInsertion(root, x);
break;
}
}
}
}
moveRootToFront(tab, root);
} 示例
添加数据
HashMap<String,Integer> hashMap = new HashMap<String,Integer>();
hashMap.put("aa",11);
hashMap.put("bb",22);
hashMap.put("cc",33);
hashMap.put(null,44);删除数据
hashMap.remove("cc");获取数据
Integer value = hashMap.get("aa");遍历数据
遍历节点(迭代器)
Iterator iteratorForentrySet = hashMap.entrySet().iterator();
while(iteratorForentrySet.hasNext()){
Map.Entry e = (Map.Entry) iteratorForentrySet.next();
System.out.println(e.getKey() + "--" + e.getValue());
}遍历节点(foreach)
for(Map.Entry entry:hashMap.entrySet()) {
System.out.println(entry.getKey() + "--" + entry.getValue());
} 遍历Key(迭代器)
Iterator IteratorForkeySet = hashMap.keySet().iterator();
while(IteratorForkeySet.hasNext()){
String key = (String)IteratorForkeySet.next();
System.out.println("key = " + key);
}遍历value
ArrayList arrayLList = new ArrayList(hashMap.values());
for(Integer val:arrayLList) {
System.out.println("val= " + val);
} 总结
1.HashMap的key不能为null值,但是value可以为null值,
Hashtable的key不能为null值,但是value也不可以为null值,
2.HashMap结构是数组加链表形式.
3.Hashtable 获取index = hash % tab.length
HashMap获取index = hash & (tab.length-1)
从效率上来讲并不差多少,但是HashMap的方式会导致出现哈希冲突概率增大,导致整体性能降低.不知道官方为什么这么写.
4.HashMap是非线程安全的,在多线程环境中使用可能会存在问题.
相关文章
JDK9.0 ArrayList源码阅读记录
JDK9.0 LinkedList源码阅读记录
ArrayList和LinkedList性能比较
JDK9.0 Vector源码阅读记录
JDK9.0 Hashtable源码阅读记录
Java9.0 HashMap源码阅读记录
JDK9.0 HashSet源码阅读记录