时序数据库应用场景与设计
- 数据特点
时序数据是基于时间的一系列的数据。在有时间的坐标中将这些数据点连成线,往过去看可以做成多纬度报表,揭示其趋势性、规律性、异常性;往未来看可以做大数据分析,机器学习,实现预测和预警。比如工业上的设备状态监控,无人驾驶汽车各个设备监控。
时序数据库就是存放时序数据的数据库,并且需要支持时序数据的快速写入、持久化、多纬度的聚合查询等基本功能。对比传统数据库仅仅记录了数据的当前值,时序数据库则记录了所有的历史数据。同时时序数据的查询也总是会带上时间作为过滤条件
- 概念定义
| 指标 |
说明 |
| metric |
度量,相当于关系型数据库中的table,用来表示待测定对象 |
| data point |
数据点,相当于关系型数据库中的row,也就是一条一条的记录 |
| timestamp |
时间戳,采集数据的时间 |
| field |
度量下的不同字段。比如位置这个度量具有经度和纬度两个field,风有风速和风向两个属性。一般情况下存放的是会随着时间戳的变化而变化的数据 |
| Tag |
标签,或者附加信息。一般存放的是并不随着时间戳变化的属性信息。timestamp加上所有的tags可以认为是table的primary key |
举个例子:
- 应用场景
所有有时序数据产生,并且需要展现其历史趋势、周期规律、异常性的,进一步对未来做出预测分析的,都是时序数据库适合的场景。
在工业物联网环境监控方向,百度天工的客户就遇到了这么一个难题,由于工业上面的要求,需要将工况数据存储起来。客户每个厂区具有20000个监测点,500毫秒一个采集周期,一共20个厂区。这样算起来一年将产生惊人的26万亿个数据点。假设每个点50Byte,数据总量将达1P(如果每台服务器10T的硬盘,那么总共需要100多台服务器)。这些数据不只是要实时生成,写入存储;还要支持快速查询,做可视化的展示,帮助管理者分析决策;并且也能够用来做大数据分析,发现深层次的问题,帮助企业节能减排,增加效益。最终客户采用了百度天工的时序数据库方案,帮助他解决了难题。
在互联网场景中,也有大量的时序数据产生。百度内部有大量服务使用天工物联网平台的时序数据库。举个例子,百度内部服务为了保障用户的使用体验,将用户的每次网络卡顿、网络延迟都会记录到百度天工的时序数据库。由时序数据库直接生成报表以供技术产品做分析,尽早的发现、解决问题,保证用户的使用体验。
- 需要解决的问题
- 高并发写入
如何支持每秒钟上千万数据点的写入
- 秒级聚合
如何支持在秒级对上亿数据的分组聚合运算
- 成本敏感
如何降低海量数据存储的成本
- 存储设计
数据的存储可以分为两个问题,单机上存储和分布式存储。
- 单机存储
如果只是存储起来,直接写成日志就行。但因为后续还要快速的查询,所以需要考虑存储的结构,合理的进行索引的设计。
传统数据库存储采用的都是Btree(参考链接https://www.cnblogs.com/coder2012/p/5309197.html),这是由于其在查询和顺序插入时有利于减少寻道次数的组织形式(顺序插入指的是索引key的顺序插入,当索引key是顺序的时候,能够充分利用filesystemcache,减少磁盘寻道次数)。我们知道磁盘寻道时间是非常慢的,一般在10ms左右。磁盘的随机读写慢就慢在寻道上面。对于随机写入B tree会消耗大量的时间在磁盘寻道上,导致速度很慢。我们知道SSD具有更快的寻道时间,但并没有从根本上解决这个问题。而在时序数据中,field字段往往是随机变化的,所以对于90%以上场景都是写入的时序数据库,B tree很明显是不合适的。
业界主流都是采用LSM tree(参考链接https://cloud.tencent.com/developer/news/340271)替换B tree,比如Hbase, Cassandra等nosql中。LSM tree操作流程如下:
- 数据写入和更新时首先写入位于内存里的数据结构。为了避免数据丢失也会先写到WAL文件中。
- 内存里的数据结构会定时或者达到固定大小会刷到磁盘。这些磁盘上的文件不会被修改。
- 随着磁盘上积累的文件越来越多,会定时的进行合并操作,消除冗余数据,减少文件数量。
LSM tree核心思想就是通过内存写和后续磁盘的顺序写入获得更高的写入性能,避免了随机写入。但同时也牺牲了读取性能
- 分布式存储
时序数据库面向的是海量数据的写入存储读取,单机是无法解决问题的。所以需要采用多机存储,也就是分布式存储。分布式存储首先要考虑的是如何将数据分布到多台机器上面,也就是 分片(sharding)问题。下面我们就时序数据库分片问题展开介绍。分片问题由分片方法的选择和分片的设计组成。时序数据库的分片方法和其他分布式系统是相通的。
- 哈希分片(参考链接:https://blog.csdn.net/wang7807564/article/details/80232580):这种方法实现简单,均衡性较好,但是集群不易扩展。
- 一致性哈希(参考链接:https://www.jianshu.com/p/e968c081f563):这种方案均衡性好,集群扩展容易,只是实现复杂。代表有Amazon的DynamoDB和开源的Cassandra。
- 范围划分(参考链接:https://www.jianshu.com/p/e76f08cdf547):按照key的范围进行划分,比如(0,100],(100,200]划分成两块,通常配合全局有序,复杂度在于合并和分裂。代表有Hbase。
分片设计简单来说就是以什么做分片,这是非常有技巧的,会直接影响写入读取的性能。结合时序数据库的特点,根据metric+tags分片是比较好的一种方式,因为往往会按照一个时间范围查询,这样相同metric和tags的数据会分配到一台机器上连续存放,顺序的磁盘读取是很快的。再结合上面讲到的单机存储内容,可以做到快速查询。
进一步我们考虑时序数据时间范围很长的情况,需要根据时间范围再将分成几段,分别存储到不同的机器上,这样对于大范围时序数据就可以支持并发查询,优化查询速度。
如下图,第一行和第三行都是同样的tag(sensor=95D8-7913;city=上海),所以分配到同样的分片,而第五行虽然也是同样的tag,但是根据时间范围再分段,被分到了不同的分片。第二、四、六行属于同样的tag(sensor=F3CC-20F3;city=北京)也是一样的道理。
- 业界案例
下面我以一批开源时序数据库作为说明。
InfluxDB:
非常优秀的时序数据库,但只有单机版是免费开源的,集群版本是要收费的。从单机版本中可以一窥其存储方案:在单机上InfluxDB采取类似于LSM tree的存储结构TSM;而分片的方案InfluxDB先通过
这里timestamp默认情况下是7天对齐,也就是说7天的时序数据会在一个Shard中。
p6-Influxdb TSM结构图(注2)
Kairosdb:
底层使用Cassandra作为分布式存储引擎,如上文提到单机上采用的是LSM tree。
Cassandra有两级索引:partition key和clustering key。其中partition key是其分片ID,使用的是一致性哈希;而clustering key在一个partition key中保证有序。
Kairosdb利用Cassandra的特性,将
partition key中的timestamp是3周对齐的,也就是说21天的时序数据会在一个clustering key下。3周的毫秒数是18亿正好小于Cassandra每行列数20亿的限制。
OpenTsdb:
底层使用Hbase作为其分布式存储引擎,采用的也是LSM tree。
Hbase采用范围划分的分片方式。使用row key做分片,保证其全局有序。每个row key下可以有多个column family。每个column family下可以有多个column。
上图是OpenTsdb的row key组织方式。不同于别的时序数据库,由于Hbase的row key全局有序,所以增加了可选的salt以达到更好的数据分布,避免热点产生。再由与timestamp间的偏移和数据类型组成column qualifier。
他的timestamp是小时对齐的,也就是说一个row key下最多存储一个小时的数据。并且需要将构成row key的metric和tags都转成对应的uid来减少存储空间,避免Hfile索引太大。下图是真实的row key示例。
- 查询设计
用户对时序数据的查询场景多种多样,总的来说时序数据的查询分为两种:原始数据的查询和时序数据聚合运算的查询。对于时序数据来说,最主要的难点在于如何解决好海量数据下的聚合查询问题。为了解决该问题,数据库在查询设计上一般从以下两方面入手。
- 分布式查询
分布式聚合查询通过并发使用多个节点并行查询和计算来提高性能,减少了分片查询以及聚合运算的时间,保证了时序数据分析结果秒级返回。
- 预处理
数据预处理则是通过空间换时间的思路,将数据根据查询规则预先计算,查询时直接返回少量的聚合运算结果来保证更低的查询延时。
预处理根据实时性可以分为二种:批处理和流式处理。批处理的优点是支持对历史时序数据的处理,实现简单。但是批处理具有查询数据量大,非实时的缺点。流式处理的优点是数据实时计算,无需查询原始数据,但是灵活性欠缺,需要根据应用场景判断是否适合流式处理。
批处理是使用pull的方式查询时序原始数据,预先进行聚合运算获取数据结果写入时序数据库,当进行聚合查询时直接返回预处理后数据结果。时序数据库定期轮询规则,根据采样窗口创建预处理任务,任务根据规则信息形成多个任务队列。队列内任务顺序执行,队列间任务并发执行,多任务队列保证了多租户对计算资源共享。
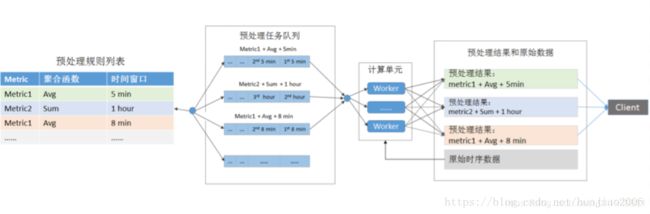
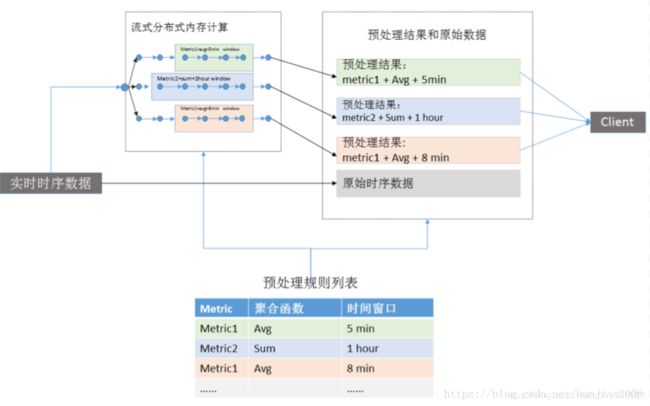
流式处理框架同样能够支持对数据流做聚合运算,不同于批处理方式,时序数据需要路由到流式处理框架例如Spark,Flink等,当数据时间戳到达采样窗口时,在内存中实时计算,写入时序数据库。
- 关键技术
- 字典编码
一种通用数据压缩算法,用《偏移量、长度、下一个字符》的三元组代替一串字符,在编码中仅仅把字符串看成是一个号码,而不去管它来表示什么意义,1977年由两位以色列教授发明,1985年美国Wekch对该算法进行了改进。
参考链接:https://cloud.tencent.com/developer/article/1380632
- 位图索引
位图索引是一种使用位图的特殊数据库索引,位置编码中的每一位表示键值对应的数据行的有无。使用场景:主要针对取值范围较小的列而创建(例如:性别、类别,操作员,部门ID,库房ID等),索
引列的取值区间不适合频繁的更改。相对于B树索引,占用的空间非常小,创建和使用非常快。B树索引更适合于取值范围较大的列建立索引。
参考链接:https://www.cnblogs.com/LBSer/p/3322630.html
- 列式存储
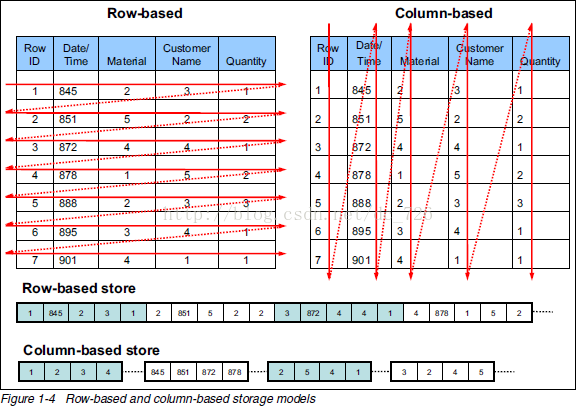
列式存储(Columnar or column-based)是相对于传统关系型数据库的行式存储(Row-basedstorage)来说的。行式存储意味着同一行数据存放在一起,列式存储意味着同一列的数据存放在一起。
|
|
行式存储 |
列式存储 |
| 优点 |
数据被保存在一起; INSERT/UPDATE容易; |
查询时只有涉及到的列会被读取,特别适合大数据场景,减少磁盘IO;任何列都能作为索引;相同列属性一致,适合做压缩,节省存储空间; |
| 缺点 |
选择(Selection)时即使只涉及某几列,所有数据也都会被读取; |
选择完成时,被选择的列要重新组装; INSERT/UPDATE比较麻烦; |
存储过程如下图:
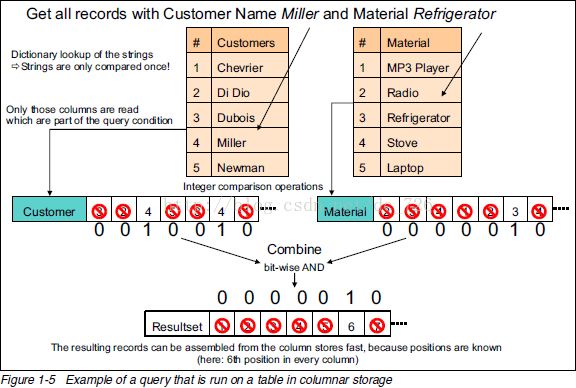
查询过程如下,有点像位图索引的检索过程:
- 后续
前面部分对时序数据库场景、设计中的存储和查询问题做了分析,后续会针对常用的时序数据库进行全方位的比较。
参考链接:https://blog.csdn.net/huojiao2006/article/details/81203830