RDD应用API---parallelize、Array、reduce、distinct、filter
图片来源:梁洪亮老师的课件
代码来源:Spark MLlib机器学习实践 王晓华
parallelize
def parallelize[T: ClassTag](seq:Seq[T], numSlices:Int=defaultParallelism):RDD[T]第一个参数是数据,默认参数为1,表示将数据值分布在多少个数据节点中存放
import org.apache.spark.{SparkConf, SparkContext}
object WordCount
{
def main(args: Array[String])
{
//SparkContext 的初始化需要一个 SparkConf 对象, SparkConf 包含了Spark集群配置的各种参数(比如主节点的URL)
val sc = new SparkContext("local", "testRDD") //Spark 程序的编写都是从 SparkContext 开始的。
//将内存数据读入Spark系统中,作为一个整体数据集
var str = sc.parallelize(Array("One", "Two", "Three", "Four", "Five")) //创建数据集
str.foreach(println)
}
}
运行结果:
![]()
import org.apache.spark.{SparkConf, SparkContext}
object WordCount
{
def main(args: Array[String])
{
//SparkContext 的初始化需要一个 SparkConf 对象, SparkConf 包含了Spark集群配置的各种参数(比如主节点的URL)
val sc = new SparkContext("local", "testRDD") //Spark 程序的编写都是从 SparkContext 开始的。
//parallelize将内存数据读入Spark系统中,作为一个整体数据集
var str = sc.parallelize(Array("One", "Two", "Three", "Four", "Five"), 2) //创建数据集
str.foreach(println)
}
}运行结果:

reduce

import org.apache.spark.{SparkConf, SparkContext}
object WordCount
{
def main(args: Array[String])
{
//SparkContext 的初始化需要一个 SparkConf 对象, SparkConf 包含了Spark集群配置的各种参数(比如主节点的URL)
val sc = new SparkContext("local", "testRDD"); //Spark 程序的编写都是从 SparkContext 开始的。
//parallelize将内存数据读入Spark系统中,作为一个整体数据集
var str = sc.parallelize(Array("One", "two", "three", "four", "five")) //创建数据集
var result = str.reduce(_+_) //对传入的数据进行合并处理
result.foreach(print) //打印数据结果
}
}
运行结果:
Onetwothreefourfiveimport org.apache.spark.{SparkConf, SparkContext}
object WordCount
{
def main(args: Array[String])
{
//SparkContext 的初始化需要一个 SparkConf 对象, SparkConf 包含了Spark集群配置的各种参数(比如主节点的URL)
val sc = new SparkContext("local", "testRDD"); //Spark 程序的编写都是从 SparkContext 开始的。
//parallelize将内存数据读入Spark系统中,作为一个整体数据集
var str = sc.parallelize(Array("One", "two", "three", "four", "five")) //创建数据集
var result = str.reduce(myFun) //对传入的数据按照指定函数处理
result.foreach(print) //打印数据结果
}
//返回最长的字符串
def myFun(str1:String, str2:String):String =
{
var str = str1
if(str2.size >= str.size)
{
str = str2
}
return str
}
}
运行结果:
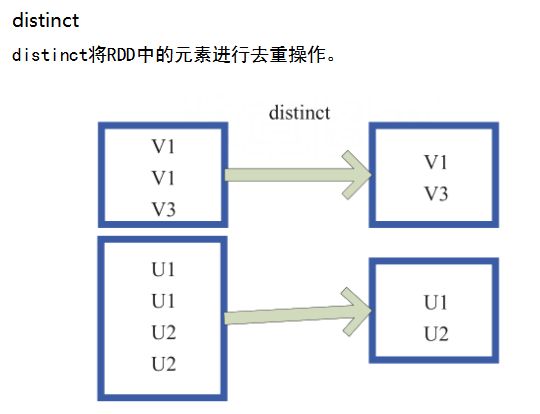
threedistinct
输出分区为输入分区的子集
import org.apache.spark.{SparkConf, SparkContext}
object WordCount
{
def main(args: Array[String])
{
//SparkContext 的初始化需要一个 SparkConf 对象, SparkConf 包含了Spark集群配置的各种参数(比如主节点的URL)
val sc = new SparkContext("local", "testRDD") //Spark 程序的编写都是从 SparkContext 开始的。
var str = sc.parallelize(Array("One", "Two", "Three", "One", "One")) //创建数据集
var result = str.distinct() //对传入的数据按照指定函数处理
result.foreach(println) //打印数据结果
}
}
filter
输出分区为输入分区的子集

import org.apache.spark.{SparkConf, SparkContext}
object WordCount
{
def main(args: Array[String])
{
//SparkContext 的初始化需要一个 SparkConf 对象, SparkConf 包含了Spark集群配置的各种参数(比如主节点的URL)
val sc = new SparkContext("local", "testRDD") //Spark 程序的编写都是从 SparkContext 开始的。
var str = sc.parallelize(Array("One", "Two", "Three", "Four", "Five")) //创建数据集
val result = str.filter(_.size > 3) //筛选
result.foreach(println)
}
}
运行结果:
![]()