Sqoop2中Connectors开发方法
Sqoop是Hadoop生态圈中的ETL抽取工具,可以从关系型数据库抽取数据至HDFS、HBase、Hive中,其内在机制利用了MapReduce进行多节点并行抽取,可以有效地提升抽取速度。
1. Sqoop抽取原理
Sqoop抽取的核心思想是对sql语句进行分割,例如对表A进行抽取时,首先要指定一个抽取字段,默认是表的主键,假设为objectId,首先会计算出min(objectId)和max(objectId),假设抽取线程数为N,则每个抽取线程的抽取范围大小为(max(objectId)-min(objectId))/N,最后将每个子抽取提交到Hadoop,利用MapReduce并行抽取,这样可以极大地提升抽取速度。
从Sqoop的抽取原理可以看出,Sqoop是对某个字段进行分割,因此如果选择的字段非常不均匀,则每个抽取线程抽取的数据量相差悬殊,这样会导致某些节点的负载过大,而某些节点的负载不足,从而影响整体抽取速度。
2 Sqoop2的基本架构
Sqoop2与Sqoop1的架构完全不同,Sqoop2采用的主从服务模式,引入了Sqoop Server(采用Jetty),而Sqoop2的核心部分就是Connector,具体来说,Sqoop2对各种数据源都开发了相应的访问接口,包括导入/导出,Sqoop Server对接口进行统一管理,进行数据抽取时,需要创建任务,指定从哪一个数据源抽取到哪一个数据源,提交的Sqoop Server上运行,而任务的分割、调度都都将由Sqoop Server完成。
3 Connector开发方法
目前Sqoop2官网上最新版本是1.99.7,其支持的Connector包括:JDBC、HDFS、FTP、SFTP、Kafka,后续版本中应该会添加对其他数据源的支持,由于项目需求,对Sqoop2的源码进行了分析,并独立开发了支持HBase、Hive、Solr的数据源接口,在此对开发接口一般方法进行分享,希望对从事Sqoop的开发人员起到抛砖引玉的作用,以Hive接口为例:
3.1 整体Connector源码预览:
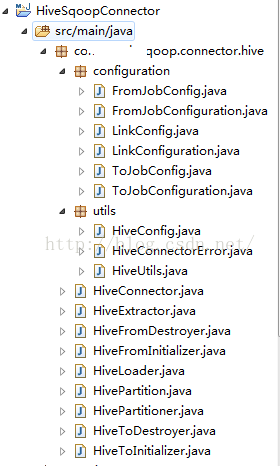
要写的代码还是比较多的,其实主要分为两部分:From和To,下面分这两个部分分别进行阐述:
3.2 From 部分实现
该部分即实现了对某个数据源进行抽取
首先看LinkConfig.java
@ConfigClass(validators = {@Validator(LinkConfig.ConfigValidator.class)})
public class LinkConfig {
/**
* HDFS地址
*/
@Input(size = 255)
public String hdfsURI;
/**
* HiveServer地址
*/
@Input(size = 255)
public String hiveSeverHost;
public LinkConfig(){
}
public static class ConfigValidator extends AbstractValidator{
@Override
public void validate(LinkConfig config) {
if(StringUtils.isEmpty(config.hdfsURI)){
addMessage(Status.ERROR, "Must Specify HDFS URI!");
}
if(StringUtils.isEmpty(config.hiveSeverHost)){
addMessage(Status.ERROR, "Must Specify HiveServer Address!");
}
}
}
} 这部分代码实现了Hive的连接配置,挡在Sqoop Shell中创建link时,需要指定相关配置参数,在本例中,我们需要指定HDFS地址和HiverServer地址,以注解@Input标定。
再看FromJobConfig.java
@ConfigClass(validators = { @Validator(FromJobConfig.FromJobConfigValidator.class)})
public class FromJobConfig {
/**
* 要导出的Hive表名
*/
@Input(size=255)
public String tableName;
public FromJobConfig(){
}
public static class FromJobConfigValidator extends AbstractValidator{
@Override
public void validate(FromJobConfig config) {
if(StringUtils.isEmpty(config.tableName)){
addMessage(Status.ERROR, "Must Specify tableName!");
}
}
}
} 这部分代码指定了需要抽取Hive的哪张表
下面是Sqoop抽取最关键的实现部分:HivePartition.java和HivePartitioner.java ,即实现抽取的分割策略:
首先说明一下对Hive抽取分割策略的基本实现,Hive数据表存储的HDFS路径为/user/hive/warehouse/hive表名,在本例我是以文本文件存储的,因此核心思路是如何对文本文件进行多线程读写。
假设路径下共有M个文本文件,抽取线程为N,在此我们需要对每个文件按行进行分割,即每个文件按行分成N部分,这样每个文件都可以被并行抽取,具体的分割我将在另一篇博客中详细阐述。
HivePartition指定一些分区参数,包括Hive存储路径下各个文件路径集合,每个文件的其实读写点和终止读写点等
下面看下HivePartitioner.java
public class HivePartitioner extends Partitioner{
private static Configuration config = null;
@Override
public List getPartitions(PartitionerContext context,
LinkConfiguration linkConfig, FromJobConfiguration jobConfig) {
assert linkConfig != null;
assert jobConfig != null;
List partitions = new LinkedList();
long numberPartitions = context.getMaxPartitions();
String hdfsUri = linkConfig.linkConfig.hdfsURI;
String tableName = jobConfig.fromJobConfig.tableName;
FileSystem fs = getFileSystem(hdfsUri);
Path directory = new Path("/user/hive/warehouse/"+tableName);
try {
//获取hive表目录下的所有文件
FileStatus[] files = fs.listStatus(directory);
//目录下的文件数量
int numFiles = files.length;
Path[] filePaths = new Path[numFiles];
List> filePartitions = new ArrayList>();
for(int i=0; i filePartition = getLocations(hdfsUri, files[i].getPath(), numberPartitions);
filePartitions.add(filePartition);
}
for(int i=0; i filePartition : filePartitions){
starts[s++] = filePartition.get(i);
ends[t++] = filePartition.get(i+1);
}
HivePartition partition = new HivePartition(numFiles, filePaths, starts, ends);
partitions.add(partition);
}
} catch (Exception e) {
throw new SqoopException(HiveConnectorError.HIVE_CONNECTOR_0002, e.getMessage());
}
return partitions;
}
} HivePartitioner需要实现getPartitions方法,即根据抽取线程数量生成多个HivePartition
HiveExtractor即抽取部分的实现:
public class HiveExtractor extends Extractor{
private static final Logger logger = Logger.getLogger(HiveExtractor.class);
private long rowsRead = 0L;
@Override
public void extract(ExtractorContext context, LinkConfiguration linkConfig,
FromJobConfiguration jobConfig, HivePartition partition) {
String hdfsUri = linkConfig.linkConfig.hdfsURI;
String tableName = jobConfig.fromJobConfig.tableName;
Schema schema = context.getSchema();
DataWriter writer = context.getDataWriter();
int numFiles = partition.getNumFiles();
Path[] filePaths = partition.getPaths();
Long[] starts = partition.getStarts();
Long[] ends = partition.getEnds();
Configuration config = new Configuration();
config.set("fs.default.name", hdfsUri);
try {
FileSystem fs = FileSystem.get(config);
Text text = new Text();
for(int i=0; i HiveExtractor需要实现extract函数,其中的参数partition即之前生成的HivePartition,context.getDataWriter()可以获取上下文的输出流,在此我们对源文件进行按行读取,并写到输出流中。
HiveFromInitializer和HiveFromDestroyer即实现抽取的初始化与清理工作,包括连接HDFS和HiveServer,断开与HDFS、HiveServer的连接等
3.3 To 部分的实现:
包括ToJobConfig.java、HiveToInitializer.java、HiveToDestroy.java、HiveLoader.java等,其中的配置、初始化、清理与From相同,在此看下HiveLoader.java:
public class HiveLoader extends Loader{
private static final Logger logger = Logger.getLogger(HiveLoader.class);
private long rowsWritten = 0;
@Override
public void load(LoaderContext context, LinkConfiguration linkConfig,
ToJobConfiguration toJobConfig) throws Exception {
String hdfsURI = linkConfig.linkConfig.hdfsURI;
String hiveServer = linkConfig.linkConfig.hiveSeverHost;
String tableName = toJobConfig.toJobConfig.tableName;
String fileName = "/user/hive/warehouse/"+tableName+"/"+UUID.randomUUID()+".txt";
Path filepath = new Path(fileName);
logger.info("准备导入HDFS文件:"+fileName);
Schema schema = context.getSchema();
Column[] columns = schema.getColumnsArray();
DataReader reader = context.getDataReader();
logger.info("输入的字段列表:"+Arrays.toString(columns));
Configuration config = new Configuration();
config.set("fs.default.name", hdfsURI);
/**
* 创建HDFS读写流
*/
FileSystem fs = filepath.getFileSystem(config);
DataOutputStream filestream = fs.create(filepath, false);
BufferedWriter filewriter = new BufferedWriter(new OutputStreamWriter(filestream, "UTF-8"));
Object[] record;
while((record=reader.readArrayRecord())!=null){
String line = SqoopIDFUtils.toCSV(record, schema);
filewriter.write(line+"\n");
rowsWritten++;
}
filewriter.close();
filestream.close();
fs.close();
Statement stmt = HiveConfig.getStatement(hiveServer);
HiveUtils.loadDataFromDfs(stmt, fileName, tableName);
}
@Override
public long getRowsWritten() {
return rowsWritten;
}
}
3.4 Connector的部署
完成From与To部分的实现之后,最后需要实现HiveConnector对From与To进行整合,该类继承自SqoopConnector,需要实现的方法包括:
public class HiveConnector extends SqoopConnector{
private static final From FROM = new From(HiveFromInitializer.class,
HivePartitioner.class,
HivePartition.class,
HiveExtractor.class,
HiveFromDestroyer.class);
private static final To TO = new To(HiveToInitializer.class,
HiveLoader.class,
HiveToDestroyer.class);
@Override
public List getSupportedDirections(){
return Arrays.asList(Direction.FROM, Direction.TO);
}
@Override
public ResourceBundle getBundle(Locale locale) {
return ResourceBundle.getBundle("hive-connector-config", locale);
}
@Override
public ConnectorConfigurableUpgrader getConfigurableUpgrader(String arg0) {
return null;
}
@Override
public From getFrom() {
return FROM;
}
@Override
public Class getJobConfigurationClass(Direction jobType) {
switch(jobType){
case FROM:
return FromJobConfiguration.class;
case TO:
return ToJobConfiguration.class;
}
throw new SqoopException(HiveConnectorError.HIVE_CONNECTOR_0004, jobType.name());
}
@Override
public Class getLinkConfigurationClass() {
return LinkConfiguration.class;
}
@Override
public To getTo() {
return TO;
}
@Override
public String getVersion() {
return VersionInfo.getBuildVersion();
}
} HiveConnector中的FROM和TO对导出与导入部分进行了封装,getBundle方法返回一个配置文件hive-connector-config.properties,在该文件的配置信息指定了Sqoop Shell命令中看到的Connector配置信息:
connector.name = Hive Connector
linkConfig.label = Hive Link
linkConfig.help = Configuration options describing Hive Link.
linkConfig.hdfsURI.label = HDFS URI
linkConfig.hdfsURI.example = hdfs://192.168.47.136:9000
linkConfig.hiveSeverHost.label = HiveServer Address
linkConfig.hiveSeverHost.example = jdbc:hive2://192.168.47.136:10000
fromJobConfig.label = Hive Input Configuration
fromJobConfig.help = Configuration necessary when extracting data from Hive.
fromJobConfig.tableName.label = Hive TableName
fromJobConfig.tableName.help = The Hive Table to Extrat
toJobConfig.label = Hive Output Configuration
toJobConfig.help = Configuration necessary when writing data to Hive.
toJobConfig.tableName.label = Hive Table Name
toJobConfig.tableName.help = The Hive Table to Load
最后还需要一个配置文件sqoopconnector.properties:
# Hive Connector Properties
org.apache.sqoop.connector.class = org.apache.sqoop.connector.hive.HiveConnector
org.apache.sqoop.connector.name = hive-connector该配置文件指定了Connector的实现类与名称,该文件是必须存在,因为Sqoop Server会扫描首先Jar包的该文件,再对Connector进行初始化。
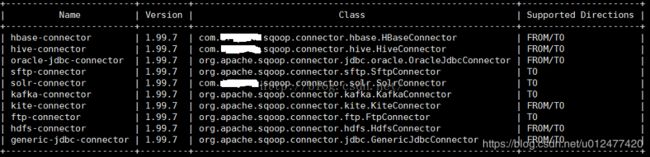
编写好所有的类后,将Java工程打包成jar包,需要注意的是需要将该工程依赖的jar包放在lib文件夹下,并将lib文件夹打进jar包中。将打好的jar复制到sqoop2安装目录中server/lib目录中,重启Sqoop2,Sqoop2会自动对添加的Connector进行注册。
在Sqoop Shell中输入命令 show connector后,即可显示已注册的Connector,由图可见,编写的HBase、Hive、Solr已被成功注册至Server。