iOS字典和数组底层实现原理
### NSMutableArray的底层原理
_used 是计数的意思
_list 是缓冲区指针
_size 是缓冲区的大小
_offset 是在缓冲区里的数组的第一个元素索引
数据结构
正如你会猜测的,__NSArrayM 用了环形缓冲区 (circular buffer)。这个数据结构相当简单,只是比常规数组或缓冲区复杂点。环形缓冲区的内容能在到达任意一端时绕向另一端。
环形缓冲区有一些非常酷的属性。尤其是,除非缓冲区满了,否则在任意一端插入或删除均不会要求移动任何内存。我们来分析这个类如何充分利用环形缓冲区来使得自身比 C 数组强大得多。在任意一端插入或者删除,只是修改offset参数,不需要移动内存,我们访问的时候只是不和普通的数组一样index多少就是多少,这里会计算加上offset之后处理的值取数据,而不是插入头和尾巴的时候,环形结构会根据最少移动内存指针的方式插入,例如要在A和B之间插入,按照C的数组,我们需要把B到E的元素移动内存,但是环形缓冲区的设计,我们只要把A的值向前移动一个单位内存,即可,同时修改offset偏移量,就能保证最小的移动单元来完成中间插入。
& 删除指定位置的元素
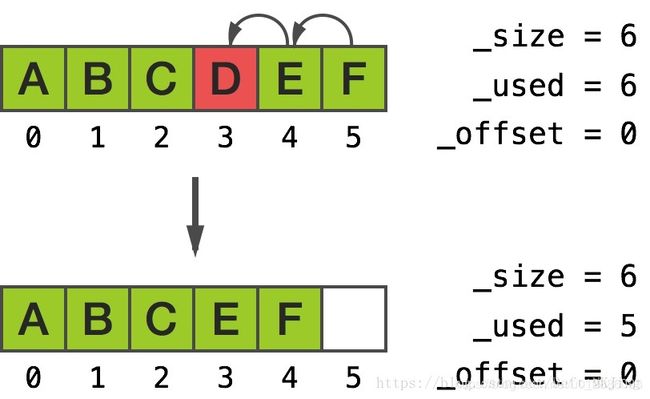
往中部插入对象有非常相似的结果。合理的解释就是,__NSArrayM 试着去最小化内存的移动,因此会移动最少的一边元素。
& 删除头部元素和添加元素

NSMutableArray 是一个高级抽象数组,解决了 C 风格数组对应的缺点。(C数组插入的时候都会移动内存,不是O(1),用到了环形缓冲区数据结构来处理内存移动的损耗)
但是可变数组任意一端插入或删除能有固定时间的性能。而且在中间插入和删除的时候都会试着去移动最小化内存。
环形缓冲区的数据结构如果是连续数组结构,在扩容的时候难免会移动大量内存,因此用链表实现环形缓冲会更好
### 字典的底层实现原理
一:字典原理
NSDictionary(字典)是使用hash表来实现key和value之间的映射和存储的
方法:- (void)setObject:(id)anObject forKey:(id)aKey;
Objective-C中的字典NSDictionary底层其实是一个哈希表
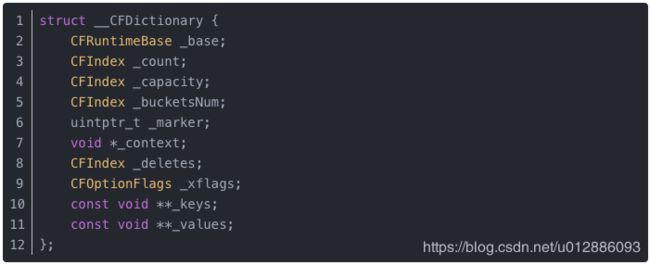
根据数据结构可以发现dictionary内部使用了两个指针数组分别来保存keys和values,先不去讨论这两个数组的元素如何形成对应关系,已知的是dictionary采用的是连续存储的方式存储键值对,因此接下来我们将一步步了解字典是如何完成key-value的匹配过程。我们刚才在CFDictionary的结构体的时候看到了key和values这两个二级指针,可以基本断定为数组结构,由于是两个数组分别存储,因此,key哈希出来的数组下标地址,同样这个地址对应到values数组的下标,就是匹配到的值。因此keys和values这两个数组的长度一致才能保证匹配到数据。内部结构还有个_capacity表示当前通列表的扩充阀域 ,当count数量达到这个长度就扩容
可以看到,NSDictionary设置的key和value,key值会根据特定的hash函数算出建立的空桶数组,keys和values同样多,然后存储数据的时候,根据hash函数算出来的值,找到对应的index下标,如果下标已有数据,开放定址法后移动插入,如果空桶数组到达数据阀值,这个时候就会把空桶数组扩容,然后重新哈希插入。这样把一些不连续的key-value值插入到了能建立起关系的hash表中,当我们查找的时候,key根据哈希值算出来,然后根据索引,直接index访问hash表keys和hash表values,这样查询速度就可以和连续线性存储的数据一样接近O(1)了,只是占用空间有点大,性能就很强悍。如果删除的时候,也会根据_maker标记逻辑上的删除,除非NSDictionary(NSDictionary本体的hash值就是count)内存被移除。我们也会根据dictionary之所以采用这种设计,其一出于查询性能的考虑;其二dictionary在使用过程中总是会很快的被释放,不会长期占用内存。
### 哈希原理
散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
给定表M,存在函数f(key),对任意给定的关键字值key,代入函数后若能得到包含该关键字的记录在表中的地址,则称表M为哈希(Hash)表,函数f(key)为哈希(Hash) 函数。
哈希概念:哈希表的本质是一个数组,数组中每一个元素称为一个箱子(bin),箱子中存放的是键值对。
三:哈希存储过程
1.根据 key 计算出它的哈希值 h。
2.假设箱子的个数为 n,那么这个键值对应该放在第 (h % n) 个箱子中。
3.如果该箱子中已经有了键值对,就使用开放寻址法或者拉链法解决冲突。
在使用拉链法解决哈希冲突时,每个箱子其实是一个链表,属于同一个箱子的所有键值对都会排列在链表中。
哈希表还有一个重要的属性: 负载因子(load factor),它用来衡量哈希表的空/满程度,一定程度上也可以体现查询的效率,计算公式为:
负载因子 = 总键值对数 / 箱子个数
负载因子越大,意味着哈希表越满,越容易导致冲突,性能也就越低。因此,一般来说,当负载因子大于某个常数(可能是 1,或者 0.75 等)时,哈希表将自动扩容。
哈希表在自动扩容时,一般会创建两倍于原来个数的箱子,因此即使 key 的哈希值不变,对箱子个数取余的结果也会发生改变,因此所有键值对的存放位置都有可能发生改变,这个过程也称为重哈希(rehash)。
哈希表的扩容并不总是能够有效解决负载因子过大的问题。假设所有 key 的哈希值都一样,那么即使扩容以后他们的位置也不会变化。虽然负载因子会降低,但实际存储在每个箱子中的链表长度并不发生改变,因此也就不能提高哈希表的查询性能。
### 自动释放池的实现原理
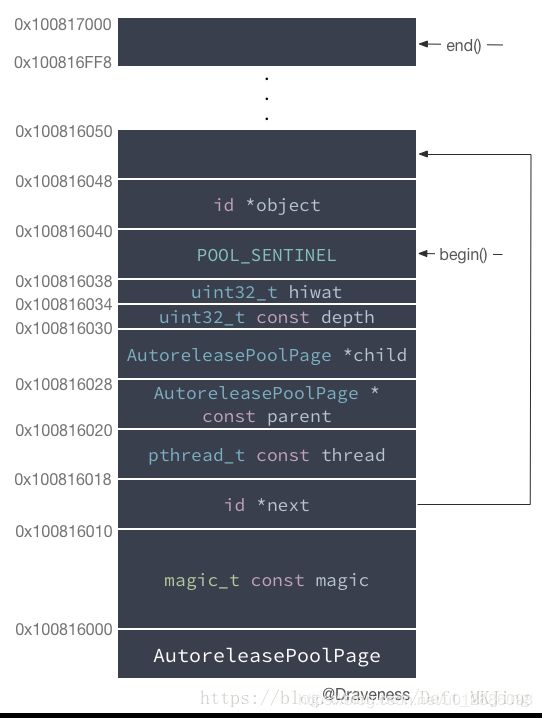
magic 用来校验 AutoreleasePoolPage 的结构是否完整;
next 指向最新添加的 autoreleased 对象的下一个位置,初始化时指向 begin() ;
thread 指向当前线程;
parent 指向父结点,第一个结点的 parent 值为 nil ;双向链表上一个节点
child 指向子结点,最后一个结点的 child 值为 nil ;双向链表下一个节点
depth 代表深度,从 0 开始,往后递增 1;
hiwat 代表 high water mark 。
每一个自动释放池都是由一系列的 AutoreleasePoolPage 组成的,并且每一个 AutoreleasePoolPage 的大小都是 4096 字节(16 进制 0x1000)
另外,当 next == begin() 时,表示 AutoreleasePoolPage 为空;当 next == end() 时,表示 AutoreleasePoolPage 已满。
总结:
1.@autorelease展开来其实就是objc_autoreleasePoolPush和objc_autoreleasePoolPop,但是这两个函数也是封装的一个底层对象AutoreleasePoolPage,实际对应的是AutoreleasePoolPage::push和AutoreleasePoolPage::pop
2.autoreleasepool本身并没有内部结构,而是一种通过AutoreleasePoolPage为节点的双向链表结构
3.根据AutoreleasePoolPage双向链表的结构,可以看到当调用objc_autoreleasePoolPush的时候实际上除了初始化poolpage对象属性之外,还会插入一个POOL_SENTINEL哨兵,用来区分不同autoreleasepool之间包裹的对象。
4.当对象调用 autorelease 方法时,会将实际对象插入 AutoreleasePoolPage 的栈中,通过next指针移动。
5.autoreleasePoolPage的结构字段上面有介绍,其中每个双向链表的node节点也就是poolpage对象内存大小为4096,除了基础属性之外,外插一个POOL_SENTINEL,每出现一个@autorelease就会有一个哨兵,剩下的通过begin和end来标识是否存储满,满了就会重新创建一个poolpage来链接链表,按照这个套路,出现一个PoolPush就创建一个哨兵,出现一个对象的autorelease,就增加一个实际的对象,满了就创建新的链表节点这样衍生下去
6.AutoreleasePoolPage::pop那么当调用pop的时候,会传入需要drain的哨兵节点,遍历该内存地址上方所有对象,直到遇到对应的哨兵,然后释放栈中遍历到的对象,每删除一页就修正双向链表的指针,最后两张图很容易理解
7.ARC下,直接调用上面的方法,整个线程都被自动释放池双向链表管理,Push创建的时候插入哨兵对象,当我们在内部写代码的时候,会自动添加Autorelease,对象会加入到在哨兵节点之间,加入到next指针上,一个个往后移,满了4096就换下一个poolPage对象节点来存储,出了释放池,会调用pop,传入自动释放池的哨兵给pop,然后遍历哨兵内存地址之后的所有对象执行release,最后吧next指针移到目标哨兵
8.Runloop这里就不介绍了,可以翻看另外写的博客,App启动的时候会在主Runloop里面注册两个观察者和一个回调函数,第一个Observe观察到entry即将进入loop的时候,会调用_objc_autoreleasePoolPush()创建自动释放池,优先级最高,保证在所有回调方法之前。第二个Observe观察到即将进入休眠或者退出的时候,当监听到Beforewaiting的时候,调用_objc_autoreleasePoolPop() 和 _objc_autoreleasePoolPush() 释放旧的创建新的,当监听到Exit的时候调用_objc_autoreleasePoolPop释放pool,这里的Observe优先级最低,发生在所有回调函数之后。