Mysql实现数据的不重复写入(insert if not exists)以及新问题:ID自增不连续的解答
本文系作者The_Third_Wave原创!转载请带上此说明。本文地址点击打开链接
本文由@The_Third_Wave原创。不定期更新,有错误请指正。
Sina微博关注:@The_Third_Wave
如果这篇博文对您有帮助,为了好的网络环境,不建议转载,建议收藏!如果您一定要转载,请带上后缀和本文地址。
最近做数据处理时候,遇到一个问题。用一个id自增主键时候,数据表中会插入大量重复数据(除ID不同)。这虽然对最终数据处理结果没有影响,但是有1个问题,如果数据量超大,对处理的速度影响成几何倍数增长!所以必须找到不重复插入的方法。
谷歌之:大量bolg有相关资料,但都是
INSERT INTO users_roles (userid, roleid) SELECT 'userid_x', 'roleid_x' FROM dual WHERE NOT EXISTS (SELECT * FROM users_roles WHERE userid = 'userid_x' AND roleid = 'roleid_x');这样的sql语句,尝试,不能解决问题。sql语法错误!
果断找官方文档,于mysql5.6版本查看到的insert文档如下图:

online help insert文档地址为:http://dev.mysql.com/doc/refman/5.6/en/insert.html
5.6版本的官方文档中没有以上语法了,这有三种插入语句。分别分析。
INSERT [LOW_PRIORITY | DELAYED | HIGH_PRIORITY] [IGNORE]
[INTO] tbl_name
[PARTITION (partition_name,...)]
[(col_name,...)]
{VALUES | VALUE} ({expr | DEFAULT},...),(...),...
[ ON DUPLICATE KEY UPDATE
col_name=expr
[, col_name=expr] ... ]
【With INSERT ... SELECT, you can quickly insert many rows into a table from one or many tables.不能从本表查询插入本表】
Or:
INSERT [LOW_PRIORITY | DELAYED | HIGH_PRIORITY] [IGNORE]
[INTO] tbl_name
[PARTITION (partition_name,...)]
SET col_name={expr | DEFAULT}, ...
[ ON DUPLICATE KEY UPDATE
col_name=expr
[, col_name=expr] ... ]
Or:
INSERT [LOW_PRIORITY | HIGH_PRIORITY] [IGNORE]
[INTO] tbl_name
[PARTITION (partition_name,...)]
[(col_name,...)]
SELECT ...
[ ON DUPLICATE KEY UPDATE
col_name=expr
[, col_name=expr] ... ]
You can use
REPLACE
instead of
INSERT
to overwrite old rows.
REPLACE
is the counterpart to
INSERT IGNORE
in the treatment of new rows that contain unique key values that duplicate old rows: The new rows are used to replace the old rows rather than being discarded.
也就是说REPLACE这条语句就是替代INSERT语句重写以前的数据,也就是更新!当你有一个唯一键UNIQUE KEY时候,需要插入的行中含有这个唯一键值,REPLACE语句是重写表中已有的行,而INSERT IGNORE则是丢弃新数据处理!
关键字使用:
Note:延迟插入即DELAYED在后续版本会丢弃不用,所以不用学了。【原文:As of MySQL 5.6.6, INSERT DELAYED is deprecated, and will be removed in a future release. Use INSERT (without DELAYED) instead.】
一、LOW_PRIORITY:很可能一直不被执行。
二、HIGH_PRIORITY:可能导致并发插入数据不可用。
Note:LOW_PRIORITY and HIGH_PRIORITY affect only storage engines that use only table-level locking (such as MyISAM, MEMORY, and MERGE).
三、IGNORE:使用此关键词插入数据时,写入数据error也会被ignore。【原文:1.If you use the IGNORE keyword, errors that occur while executing the INSERT statement are ignored. For example, without IGNORE, a row that duplicates an existing UNIQUE index or PRIMARY KEY value in the table causes a duplicate-key error and the statement is aborted. With IGNORE, the row still is not inserted, but no error occurs. Ignored errors may generate warnings instead, although duplicate-key errors do not.2.IGNORE has a similar effect on inserts into partitioned tables where no partition matching a given value is found. Without IGNORE, such INSERT statements are aborted with an error; however, when INSERT IGNORE is used, the insert operation fails silently for the row containing the unmatched value, but any rows that are matched are inserted. 】
1.也就是说当有唯一键或者主键时候,新数据和唯一键值,主键值有重复,新数据不会被写入,也不会报错。
2.当给的value list数据类型等与表的结构不一致时候,也会ignore,不会报错。
3.使用ignore关键字时,无效的value会根据表中对应字段的数据类型自动调整为最接近的value,也就是说value会改变。
四、 ON DUPLICATE KEY UPDATE:
If you specify ON DUPLICATE KEY UPDATE, and a row is inserted that would cause a duplicate value in aUNIQUE index or PRIMARY KEY, an UPDATE of the old row is performed. The affected-rows value per row is 1 if the row is inserted as a new row, 2 if an existing row is updated, and 0 if an existing row is set to its current values. If you specify the CLIENT_FOUND_ROWS flag to mysql_real_connect() when connecting to mysqld, the affected-rows value is 1 (not 0) if an existing row is set to its current values.
那么到此,我们已经找到三种方法实现写不重复数据!
方法1:指定一个或多个UNIQUE KEY,使用insert ignore into 指令,即遇到唯一键值相同时,丢弃新数据,这考虑到了一般都会有自增ID(必须为主键);或者用 col_name=expr...去更新新数据到表(需要注意唯一键值不能变,否则可能出错)。
方法2:不用自增ID,用复合主键!写数据方法同上!
方法3:指定UNIQUE KEY or PRIMARY KEY用REPLACE语句。
为什么不用自增ID呢?答:实践发现,复合主键是组合多列为1个主键,主键还是一个,所有列的值合为一个主键。用了自增ID再用复合主键等于没设复合主键。
新问题:是可以插入了,但是ID会变的不连续。问题具体为:当有一条重复数据插入时候,使用INSERT IGNORE INTO 语句执行完毕后,重复数据没有插入但是ID自增还是运行了一次,这就导致ID出现不连续的情况。这些不连续的ID值也就是出现重复的时候。使用ON DUPLICATE KEY UPDATE时也会出现此问题。REPLACE则是删除旧记录,新纪录卸载表后面,ID还是不连续。
原因是什么呢?官方文档原文为:http://dev.mysql.com/doc/refman/5.6/en/insert-on-duplicate.html
If you specify ON DUPLICATE KEY UPDATE, and a row is inserted that would cause a duplicate value in a UNIQUE index or PRIMARY KEY,MySQL performs an UPDATE of the old row. For example, if column a is declared as UNIQUE and contains the value 1, the following two statements have similar effect:
INSERT INTO table (a,b,c) VALUES (1,2,3) ON DUPLICATE KEY UPDATE c=c+1; UPDATE table SET c=c+1 WHERE a=1;
(The effects are not identical for an InnoDB table where a is an auto-increment column.With an auto-increment column, an INSERT statement increases the auto-increment value but UPDATE does not.)
With ON DUPLICATE KEY UPDATE, the affected-rows value per row is1 if the row is inserted as a new row,2 if an existing row is updated, and0 if an existing row is set to its current values. If you specify the CLIENT_FOUND_ROWSflag to mysql_real_connect() when connecting to mysqld, the affected-rows value is 1 (not 0) if an existing row is set to its current values.
原因正是我的表中ID是一个自增量!【原文:If a table contains an AUTO_INCREMENT column and INSERT ... ON DUPLICATE KEY UPDATE inserts or updates a row, the LAST_INSERT_ID() function returns the AUTO_INCREMENT value.】
如果不是自增量,ID处理会更麻烦。。。
于是,我想,既然是AUTO_INCREMENT 的原因,那么我们能不能改这个值呢?答案是可以的!相关python代码为:
def get_auto(self, table_name):
conn, cursor = self.loginlocal()
cursor.execute("show table status like "'"'+self.table_name+'"'"")
conn.commit()
auto_inscrment = cursor.fetchall()[0]
return auto_inscrment[10]当然这是我自己写的库,但是应该可以看得懂的。我们可以得到当前的auto_increment值,接下来验证能不能修改,截图如下:
命令为:alter table table_name AUTO_INCREMENT = X
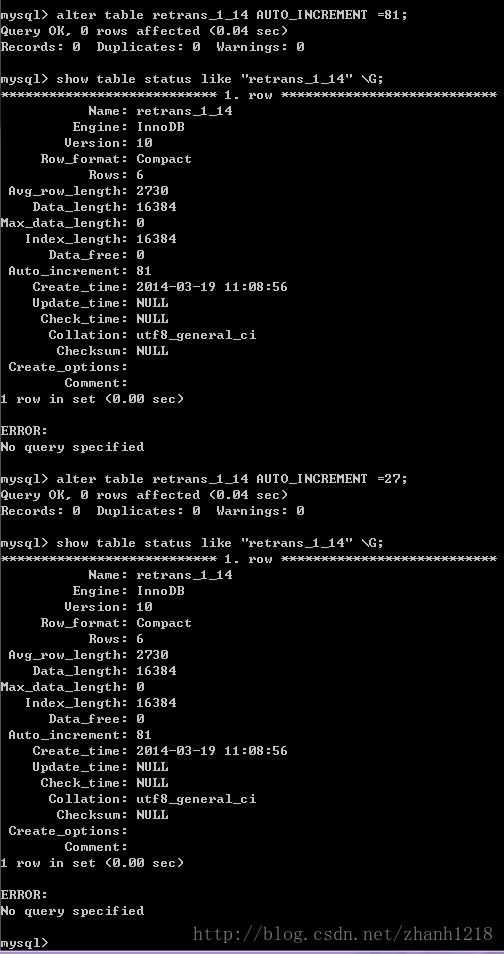
结果发现AUTO_INCREMENT 这个值只能向上修改,也就是说改到当前自增量后面的值。。。看来这个行不通了!
继续搜索论坛,发现以下说法:
- 可使用复合索引在同一个数据表里创建多个相互独立的自增序列,具体做法是这样的:为数据表创建一个由多个数据列组成的PRIMARY KEY OR UNIQUE索引,并把AUTO_INCREMENT数据列包括在这个索引里作为它的最后一个数据列。这样,这个复合索引里,前面的那些数据列每构成一种独一无二的组合,最末尾的AUTO_INCREMENT数据列就会生成一个与该组合相对应的序列编号。
好了,今天发现一篇文章详细说了下:点击打开链接
没有验证,看博主态度应该是正确的,我使用的表决定了AUTO_INCREMENT不可重复使用。
Note:1. 尽量避免用ON DUPLICATE KEY UPDATE去更新多UNIQUE KEY的表,有时候会出乎意料!2. The DELAYED option is ignored when you use ON DUPLICATE KEY UPDATE.3. Thus, in MySQL 5.6.4 and later, INSERT ... SELECT ON DUPLICATE KEY UPDATE statements are flagged as unsafe for statement-based replication.复合主键或者多个唯一键时不安全。。。
Prior to MySQL 5.6.6, an INSERT that affected a partitioned table using a storage engine such as MyISAMthat employs table-level locks locked all partitions of the table. This was true even for INSERT ... PARTITION statements. (This did not and does not occur with storage engines such as InnoDB that employ row-level locking.) In MySQL 5.6.6 and later, MySQL uses partition lock pruning, so that only partitions into which rows are inserted are actually locked. For more information, see Section 18.6.4, “Partitioning and Locking”.
本文由@The_Third_Wave原创。不定期更新,有错误请指正。
Sina微博关注:@The_Third_Wave
如果这篇博文对您有帮助,为了好的网络环境,不建议转载,建议收藏!如果您一定要转载,请带上后缀和本文地址。