华为云FusionInsight MRS融合大数据平台进阶之路
【摘要】
FusionInsight 8.0 MRS新版本由华为研发团队精心打磨,是产品演进的重要转折点,通过对CarbonData、HetuEngine及众多社区组件的升级和加强,实现了融合分析的一站式所见即所得大数据平台。
【导读】
大数据诞生之初聚焦在海量数据的批分析,实际使用场景基本都是海量数据T+1的跑批业务,随着用户业务的不断发展,对数据使用维度的复杂性和T+0时效性要求也在不断增加,而且每个需求上都有细粒度甚至苛刻的定义。为此,华为研发队伍不断的加大MRS研发力度,FusionInsight 8.0 MRS版本是产品演进过程中一个较大的转折点,产品在保障跑批及跑批性能的同时,考虑到用户对T+0数据时效的贴源分析场景,引入了更高性能的交互式查询引擎,实现企业全量数据分析从T+0贴源分析,到全量数据融合分析,再到结果的交互式探索分析,解决了过去数据共享难、使用效率低、跨系统链路复杂等难题,实现了统一分析的一站式所见即所得平台。
除此之外,新版本对Spark、Hive等组件进行了增强,使得原有业务应用的性能得到大幅提升,在MRS平台上构建海量数据融合批、流、交互式的一站式分析平台。
FusionInsight 8.0 MRS的版本已正式发布,本文意在结合融合大数据场景重点介绍新版本的核心产品能力。
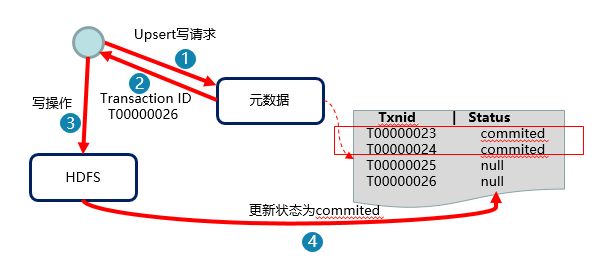
支持事务ACID,实现全量数据T+0入湖,一站式融合分析,消除数据孤岛
事务以及事务的ACID是数据处理中永恒的话题,原本是经典的数据库设计理论,现在已经逐渐衍生到各种数据平台产品中,MRS也不例外,目的是为了解决在Hadoop生态中数据时效达到T+0贴源分析。
实际上在MRS早期版本中已经沿用并增强了Hive本身对事务的支持,但实际场景中使用效果并不理想,既要兼顾列式引擎的极致查询性能,又要兼顾传统MPP基于事务能力的行式存储,这给研发人员提出了很大的挑战。FusionInsight 8.0 MRS的版本里,由华为贡献的顶级项目CarbonData升级到 2.0版本,在保证列式存储天然的优势外,极大的提升了ACID能力,同时也提升了Upsert操作的性能,使得T+0贴源分析的数据应用场景的业务需求得到充分满足,让用户得到同OLAP几乎一致的体验感。
除此之外,FusionInsight 8.0 MRS还支持Merge操作,极大的丰富了SQL的语法且能保证一致的性能。
 传统大数据平台中T+1流水线示例
传统大数据平台中T+1流水线示例
 传统大数据平台中T+0流水线示例
传统大数据平台中T+0流水线示例
在业务场景上,受Lambda/Kappa架构思想的影响,过去用户往往会建立两条流水线作业,一条是T+1从Source->PDM->SUM->MARK的分层结构的批处理模型,另一条是基于Flink/Kafka的流式处理引擎实现实时数据的消费,遗憾的是,仅T+0的数据无法满足业务需求,还是要依赖T+1的方式来实现。

FusionInsight 8.0 MRS新版本中的统一分析新方案
FusionInsight 8.0 MRS中,Carondata引入事务机制,将两条作业流水线完美融合,流式引擎可以以实时或者准实时的方式处理后存储在Carbondata中,直接以T+0的方式进行贴源数据的加工和分析。给用户提供了一种完整的贴源Source->PDM->SUM->MARK统一分析新方案。
Carbondata提供丰富的索引和物化视图,提升Spark/Hive性能
索引的多样性是Carbondata的一大特色,这给开发者更多的优化手段和极大的优化空间,让SQL解析的过程向数据库优化器功能更进一步。在FusionInsight 8.0 MRS版本中,引入了二级索引、时序索引、空间索引、Segment级别MINMAX索引、倒排索引和分桶索引。
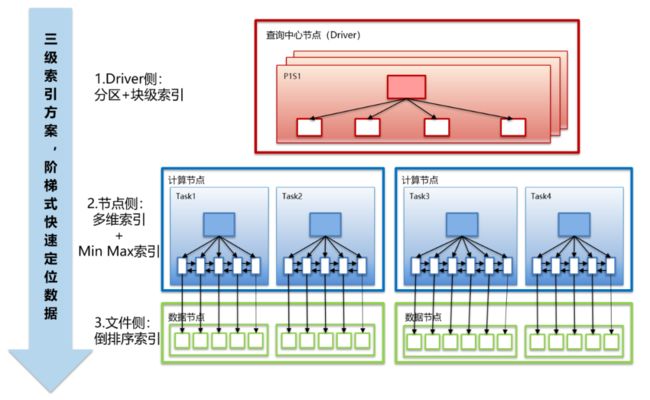
FusionInsight 8.0 MRS的三级索引方案
其中,一级索引在Driver端利用分区和块级索引实现粗粒度的分区剪裁;二级索引在节点内使用块内索引实现细粒度数据过滤;三级索引在文件内实现倒排索引快速定位到明细数据。三层索引按序使用,对于非主键的精确查询秒级响应,极大的提升了OLAP分析性能。
Carbondata实现了数据库的物化视图能力,不仅支持很多场景下数据的动态实时更新,还支持物化视图中对Join、Group By、Order By等SQL能力,实现了基于物化视图的复杂查询秒级响应。
HetuEngine 提供高性能交互式查询
HetuEngine是一个高性能的交互式查询工具,可以直接查询Hive数据,无需将数据从Hive中迁移到其它数据库,通过一个引擎可以访问所有格式的数据,且兼容SQL2003标准。HetuEngine 的核心架构采用管道式多线程任务,CPU资源可以充分利用,相比较Hive+MR的机制,大大提升响应能力;数据处理在内存中完成,内存块之间的数据交换避免了磁盘的IO开销,极大的提升了性能。
与此同时,HetuEngine将计算资源统一交给Yarn进行资源管理,无需像Impala一样规划单独的节点部署,同时还充分享受到了YARN的多租户资源隔离机制,可实现计算资源的弹性伸缩。实现了真正的数据共享、计算隔离、弹性伸缩。满足了企业越来越多的高并发即席分析场景,大集群的扩展能力,灵活的租户分配机制,通过横向扩展能力可轻松实现10000+并发的即席分析。

HetuEngine
HetuEngine对跨源、跨域的数据融合也做到了极强的支撑,通过公共的连接插件层整合了多种数据源的连接插件,对于异构平台的HBase/Hive/ElasticSearch,以及高斯DWS,都能实现融合关联分析。
“一份数据 + 一个引擎”支持数据湖全场景使用
以HBase、MongoDB或者ElasticSearch为代表的Nosql数据库,虽然可以支持实时查询类业务,但是均不支持存算分离的部署架构,为了满足PB级别存储的需求,需要启动更多的计算节点,消耗更多的CPU和存储成本,同时还要付出更多的运维成本,计算和存储的紧密耦合也意味着更低的计算和存储利用率。
以Spark on Parquet、Hive on ORC为代表的Hadoop生态数据仓库解决方案,支持将数据放在对象存储服务上,但是没有对数据构建高效的索引,使得明细数据查询或者复杂查询都很慢。
为了实现“又方便又快又便宜”的任性,FusionInsight 8.0 MRS引入了HetuEngine 和Carbondata 2.0,对接并完全发挥了Carbondata的优势,能够像关系型数据库一样高效执行复杂交互式的SQL查询,又可以兼备NoSQL的索引性能优势,还能和Spark/Hive一样享受文件存储成本优势和高度可扩展性的数据并行处理。
异构融合,平滑演进
对于计算引擎来说,基于Carbondata 2.0,原先已经投产的Flink、Hive、Hetu等计算引擎怎么办?FusionInsight 8.0 MRS支持异构引擎无缝接入,不会因为新组件的引入造成原组件无法使用或性能降低。
对存储引擎来说,在引入了Carbondata之后,之前基于Parquet或者ORC格式存储的文件怎么办?是否需要迁移?HetuEngine 支持对Parquet、ORC、CarbonData数据进行统一访问,无需迁移即可实现全域数据的统一管理和使用。如果想全部用CarbonData存储格式实现统一的数据管理和非异构的数据关联,Carbondata 2.0支持PB级别Parquet数据平滑导入,完全不必担心新组件引入带来的迁移障碍。
基于FusionInsight MRS新版本的企业大数据参考架构
在典型的基于Hadoop生态的企业架构中,数据仓库基于Hive构建,如下图所示,跑批业务从文件交换区读取当天的数据增量开始,以T+1的方式顺次加工处理并整合到各个逻辑存储层,如下红色箭头代表了T+1时效的数据流向。实时业务在没有Carbondata之前,仅仅通过Kafka/Flink引擎将数据采集并存储到贴源区,供用户直接使用。由于不支持事务ACID,实时数据无法保证数据一致性,密集的交易数据无法通过数据处理逻辑(贴源->ODS->PDM->SUM->MARK)而保证业务的上的数据准确。引入Carbondata和HetuEngine 之后,T+0的数据完全可以保证事务ACID机制,从而实时数据经过业务逻辑层次按序加工后,保证准确性和一致性。

FusionInsight 8.0 MRS新版本的企业大数据参考架构
【结束语】
FusionInsight 8.0 MRS基于CarbonData 2.0和HetuEngine 以及其它社区组件的升级与增强,提供了一种全新的企业级的融合大数据平台解决方案,基于事务的增强,用户可以完全实现T+0时效的数据消费和贴源分析,一份数据同时支持多种应用场景,一个引擎支持多种数据存储模式,充分利用资源,消除数据孤岛。支持的数据规模达到EB级,ACID能力增强,查询性能秒级响应,多索引优化,高性能交互式查询以及异构融合。使用一套生态体系完成全部业务场景的愿景得以实现。