使用google的web服务实现搜索
Response.Write(Page.IsValid);
string queryStr = HttpUtility.UrlEncode(txtSearch.Text);
Response.Redirect("http://www.google.com/search?q=" + queryStr);
作者:Scott Mitchell
介绍
你知道google提供了一个web服务让你可以使用他的数据库去搜索吗?让你使用他
的数据库去找回已经被收藏的web页面吗?让你使用他的数据库去执行拼写检查吗?使
用google的web服务你可以在你自己的站点轻松的实现像google那样的搜索。下个月我
将写两到三篇的文章去说明如何利用google的web服务,这里我们先来看看如何利用
google的数据库去实现搜索的功能吧!
来自google的许可证
google的web服务接口目前还处在测试阶段,仅供个人使用。为了
限制限制过度的使用这个接口,google需要那些想去使用他的人可以得到
一个唯一的许可(这个许可是免费的).这个许可是为了限制个人使用者每天
的使用量不要超过1000次。请务必要认真的去读这个许可证。
web服务的快速入门
Web服务是一个额外的接口,这个接口由某个网站提供,可以被其他的网站调用。
你可以把web服务想象成一个自我包含的组件,同时带有一种或多种的调用方法。他
可以驻扎在Inetnet的任何地方。通过他所提供的调用方法而被世界任何一个地方的客户
端所调用。例如,google的web服务就提供了三种方法:doGoogleSearch(),
doGetCachedPage(), 和 doSpellingSuggestion().*The doGoogleSearch()这个方法
将返回和你输入的查询字符相符合的结果。然后这个方法返回一个GoogleSearchResult类的实例,这个实例中包含了搜索的结果。
Web服务是建立在开放的协议和标准上的。例如一个想要消费web服务的客户和
Web服务本身的通讯就是通过HTTP这样一个众所周知的开放协议来进行的。而参数和
返回值之间来来回回的传送也是通过SOAP这样一个众所周知的数据引导和排序协议来
进行的。这样一来,web服务就可以完全暴露了,打个比方来说:基于微软的IIS配置的
服务器上的由ASP.net所写的web页就可以被基于Apache培植的服务器上的PHP程序所
消费,甚至可以作为完全的桌面应用程序来使用。
当消费一个web服务的时候,通常都是先建立一个代理,这个代理将保护客户端免
于对web服务的复杂的请求。代理类是一个类,他本身包含了web服务的所有暴露出来
的方法和对象。当一个客户端程序发出请求时,这些方法将控制和引导这些参数进入
SOAP,然后通过HTTP协议传送这些SOAP请求,接着接受来自web服务的响应,再次
的引导和控制这些返回值。代理类允许客户端程序调用web服务就像是在调用自己本地
的组件一样。
如果你不是很熟悉web服务,那么这个入门指导将是一个很好的引导,但是你还是
要抽出一定的时间去读一读建立web服务和建立并消费web服务这两篇文章。
Google web服务的API
Google Web服务的信息你可以在http://www.google.com/apis/找到。在开始使用
Google的web服务之前,你需要先去下载 Google Web API Developer's Kit.这个666K
的文件包含了完整的WSDL文件用以描述这个web服务,还包含一些使用Java,VB.net
和C#开发的例子。下载完了Google的web服务开发工具包以后,你还需要在Google
申请一个帐号。这个帐号可以在
https://www.google.com/accounts/NewAccount?continue=http://api.google.com/createkey&followup=http://api.google.com/createkey这个地址去做。
一旦这个免费帐号被建立,那么你就会被分配给一个唯一的许可号。以后每当Google
web服务被调用的时候,这个帐号都必须 被使用,这个帐号的作用就是限制一个号每天
调用web服务的次数不可以超过1000次。
建立代理类
一旦你拥有了帐号和google接口开发工具包,那么接下来你就需要去建立用来调用
web服务的代理类了。在完成这些以前,我们需要先在WSDL文件中得到帮助,这是
一个XML格式的文件用来去描述google的web服务所提供的服务种类。这个WSDL
文件GoogleSearch.wsdl可以在google接口开发工具包中找到。
如果你使用Visual Studio.NET,那么你可以拷贝这个文件到存放ASP.NET文件的
文件夹中(如:C:/Inetpub/wwwroot/WebApplication1). 然后去项目菜单,选择
Add Web Reference选项。接下来在对话栏里输入WSDL文件的URL即可。就像这样
http://localhost/WebApplication1/GoogleSearch.wsdl。之后再点击
Add Reference按钮就可以完成这整个的过程了。这将建立一个代理类用localhost名字
空间(如果你喜欢,你可以自己改一个名字)。
如果你没有Visual Studio.net那么你可以建立代理类通过一个命令行程序去调用
wsdl.exe。wsdl.exe文件将建立一个C#或者是VB.NET文件,当然你要编译和运行
wsdl.exe文件。在命令行中直接输入如下的即可。
wsdl /protocol:SOAP /namespace:google /out:GoogleProxy.cs
C:/google/GoogleSearch.wsdl
这样将使用google名字空间去建立一个名字为GoogleProxy.cs的C#文件。使用C#
命令行编译器,csc,去编译这个类,如下:
csc /t:library /out:GoogleProxy.dll GoogleProxy.cs
这将建立一个名字叫GoogleProxy.dll的文件。一定要把这个文件拷贝到你的web应用
程序的 /bin 目录下。
关于wsdl.exe的更多的信息
如果没有Visual Studio.NET,那么要建立一个代理类需要更多的
信息,一定要读一下PowerPoint的介绍:从一个ASP.NET 的web页面
去调用web服务。
建立一个ASP.NET的web页面去调用google的web服务
既然已经建立了代理类,那么建立一个ASP.NET去调用web服务就是小事一桩了。
首先在做这件事情之前。我们需要先检查一下web服务需要那些参数。幸运的是,这些
参数都被详细的列在了Google站点的参考部分。在这里我们既然是经由google的
web服务去执行一个搜索,那么就让我们来检查一下doGoogleSearch()方法的参数。
这一方法的十个参数如下:
key:
由google提供的,必须要使用这个键值去访问google的服务,google使用这个键值起到鉴定和*记入日志的作用
q:
(看Query Terms 去查询详细的查询语法)
start:
第一个结果的首指针
maxResults :
每一个想得到的查询结果的数字。每个查询的最大值是10(注:如果你的查询没有多少匹配的话,那么得到的结果可能要少于你的提问)
filter:
激活和未激活的自动过滤,这将隐藏非常相似的结果,而这些结果都来自相同的主机。过滤器的只要作用是想去提高google的最终用户使用google时的体验,但是从你的站点应用考虑,你最好还是放弃使用它(参见Automatic Filtering的详细信息)。
restricts:
限制搜索web站点的网页索引下的子集,比如一个国家像“乌克兰”,或者是一个主题像“linux”。(参见Restricts 的详细信息)
safeSearch :
一个布尔值,在搜索结果中可以过滤掉成人内容。(参见SafeSearch的详细信息)
lr:
语言限制-限制搜索文档中含有一种或多种语言
ie:
输入代码用的,这个参数不常用,所有输入代码都应该使用UTF-8格式(参见input和output代码的详细信息)
oe:
输出代码用的,这个参数不常用,所有输出代码都应该使用UTF-8格式(参见input和output代码的详细信息)
DoGoogleSearch()方法将返回一个GoogleSearchResult对象的实例。这个对象有
一个resultElements属性,他们是一系列ResultElement对象的实例。每一个
ResultElement对象都有一个*数字属性。比如 title,snippet, URL,summary等等。
现在让我们去建立一个简单的ASP.NET web页去显示输入查询字-asp时的前十个
结果。这个使用如下的代码就可以完成。
Font-Name=”Verdana” Font-Size=”10pt”>
<%# Container.DataItem.title %>
<%# Container.DataItem.summary %>
[”>
<%# Container.DataItem.URL %>
]
[查看演示实例]
以上代码的黑体部分是调用google web服务dogooglesearch()方法所必须的。
代码如此的少是由于代理类。搜索结果用DataList来显示,每个结果都将显示标题,
概要和通往这个页面的URL。
上面的演示实例将图示google的web服务如何去执行一个搜索。但是功能确是
非常有限的,因为它仅仅显示预先定义的搜索查询的前十个结果。在接下来的Part2
部分我们将看看如何使用一个ASP.NET去建立一个更加实用的web页去使用google的
web服务。
读Part2
使用google的web服务实现搜索(2)
上一个实例演示图示了如何调用google的web服务去实现一个搜索。但是它的功能
确实是非常有限的,它仅仅可以显示限定的查询字的前十个搜索结果。在第二部分,我们
将看看如何建立一个功能类似google的搜索引擎,可以建立一个页面让用户输入关键字
,再由另一个页面返回搜索结果。
建立一个功能更加强大搜索引擎
为了建立一个通过google提供的搜索接口web服务的功能更加强大的搜索引擎,先
让我们通过ASP.NET来建立一个可以分页并且可以让用户自己输入搜索条件的web页。
完成这个的一种方法就是模仿google自己的方法,这样也就意味着将搜索条件和搜索
的页数同时放在querystring环境变量里。比方说,如果用户想要查询字”ASP”而且希望前
十到二十个记录是可见的,那么这个URL请求将是:
http://www.yourserver.com/Search.aspx?q=ASP&first=10&last=20
其实还有其他的方法可以实现这个功能的。另一个方法就是使用postback方式。
Postback方式传送自己到ASP.NET中,所以它比querystring方式可以传送更多的
东西。然而querystring有一个好处那就是用户可以使用特别的查询(对于postback方式,
它是经由HTTP报头去传送数据的,但是querystring在搜索或者标页的时候是不可以
改变的)。
尽管querystring方式有这种标记的优点,但是我还是决定 去实现这个实例演示用
postback方式。如果你喜欢,你完全可以使用querystring方式。Postback方式的原代码
如下:
[参看实例演示]
以上代码的主要功能子程序是DisplaySearchResults(),它将调用web服务,把结果
绑定到DataList中去,并且它还将显示各色各样的信息,比如估计匹配数,查询要求
运行的时间等等。这个子程序还将决定以前的LinkButton是激活还是不激活。
还有一点要注意的就是,当调用google搜索的web服务时,我们必须规定起始的
索引和在一页中将看见多少结果。那就是说,为了看见一个搜索的前十个记录,我们
应当设定0作为开始标记,而将10作为返回的记录数。为了看见接下来的十个记录,
我们最好将10作为开始标记(让10作为返回的记录数)。需要注意的就是,ViewState
被用来去维持开始页的标记数。每一页要显示的记录数被常数PAGE_SIZE所表示。
考虑到分页,将有两个LinkButton被使用,当点击它们的时候,nextRecs和
prevRecs事件将被触发。这些事件仅仅更新可以看见的开始记录数并且调用
DisplaySearchResults().
结论
在这篇文章中我们探究了如何去调用google搜索的web服务。为了调用这个web
服务,我们首先下载了downloading the Google Web API Developer's Kit,接下来我们
在google站里建立了一个帐号可以得到一个许可证。这些都做完以后,我们建立了一个
基于google web服务WSDL文件(GoogleSearch.wsdl, 被包含在被下载的Developer's Kit
里)的代理类。建立了代理类以后,我们仅仅就需要几行简单的ASP.NET代码就可以去调用这个
web服务了。
编程快乐!!!:)
Scott Mitchell
Searching Google Using the Google Web Service
| [日期:2003-10-06] |
来源:4guysfromrolla 作者:Scott Mitchell |
[字体:大 中 小] |
Introduction
Did you know that Google provides a Web service for searching through Google's database, retrieving cached versions of Web pages, and performing spelling checks? Using Google's Web service you can provide Google's search functionality on your own Web site. Over the next month or so I plan on authoring two to three articles describing how to utilize Google's Web services. In this first article, we'll look at how to use the Web service to search through Google's database.
| Licensing Terms of the Google Web Service |
| The Google Web Service API is currently in Beta testing, and is only available for personal use. To limit excessive use, Google requires that those who wish to use the Google Web service acquire a unique license key (which is free to obtain). This license key is used to limit individuals to no more than 1,000 calls to the Google Web service per day. Please be sure to read the license terms. |
A Quick Primer on Web Services
A Web service is an external interface provided by a Web site that can be called from other Web sites. Think of Web services as a self-contained component with one or more methods. This component can reside anywhere on the Internet, and can have its methods invoked by remote clients. For example, the Google Web service provides three methods: doGoogleSearch(), doGetCachedPage(), and doSpellingSuggestion(). The doGoogleSearch(), which we'll be examining in this article, has a number of input parameters that specify the search query. The method then returns an instance of the GoogleSearchResult object, which has the results of the search.
Web services are built on open protocols and standards. For example, the communication between a client that wishes to consume a Web service, and the Web service itself, happens over HTTP, a well-known, open protocol. The parameters and return values being passed back and forth are packaged using SOAP, a well-known, open protocol for data-marshalling. The relevant point here is that Web services can be exposed on, say, a Microsoft IIS Web server and be consumed by PHP Web pages running on Apache, by ASP.NET Web pages running on IIS 6.0, or even by a desktop application.
When consuming a Web service, typically a proxy class is created to shield the client from the complexity involved in invoking the Web service. A proxy class is a class that itself contains all of the methods and objects that the Web service exposes. These methods, when called from the client program, handle the marshalling of the parameters into SOAP, sending the SOAP request over HTTP, receiving the response from the Web service, and unmarshalling the return value. The proxy class allows the client program to call a Web service as if the Web service was a local component.
If you are unfamiliar with Web services, this primer serves as a good introduction, but you should definitely take the time to read Creating a Web Service and then Creating and Consuming a Web Service.
The Google Web Service API
The Google Web Service information can be found online at http://www.google.com/apis/. To start using the Google Web Service you will first need to download the Google Web API Developer's Kit. This 666K file includes the WSDL (Web Service Description Language) file that fully describes the Web service, and examples of accessing the Google Web Service in both Java and VB.NET/C#.
After downloading the Google Web API Developer's Kit, you will need to create an account with Google. This can be done at: https://www.google.com/accounts/NewAccount?continue=http://api.google.com/createkey. Once you create one of these free accounts, you will be assigned a unique license number. This license number must be used whenever a Google Web service method is called. The purpose of this license is to limit the number of calls to the Google Web service to 1,000 invocations per license key per day.
Creating the Proxy Class
Once you have a license key and the Google API Developer's Kit, the next step is to create the proxy class that we'll use to call the Web service. To accomplish this, we first need to get our hands on the WSDL file, which is an XML-formatted file that describes the services provided by the Google Web service. This WSDL file, GoogleSearch.wsdl is located in the Google Web API Developer's Kit.
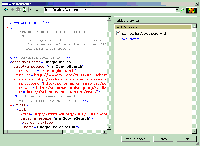 If you are using Visual Studio .NET, copy this file to the ASP.NET Web directory (like
If you are using Visual Studio .NET, copy this file to the ASP.NET Web directory (like C:/Inetpub/wwwroot/WebApplication1). Then, in Visual Studio .NET, go to the Project menu and select the Add Web Reference option. Then, in the dialog box, enter the URL to the WSDL file, which will look like: http://localhost/WebApplication1/GoogleSearch.wsdl (see the screenshot to the right). To complete the process, click the Add Reference button. This will create the proxy class using the namespace localhost (which you can change if you like).
If you do not have Visual Studio .NET, you can create the proxy class through a command-line program called wsdl.exe. Wsdl.exe will create a C# or VB.NET file, which you'll then need to compile. To run wsdl.exe, drop to the command-line and enter:
wsdl /protocol:SOAP /namespace:google /out:GoogleProxy.cs C:/google/GoogleSearch.wsdl
This will create a C# file named GoogleProxy.cs with the namespace google. To compile this class, use the C# command-line compiler, csc, like so:
csc /t:library /out:GoogleProxy.dll GoogleProxy.cs
This will create a file named GoogleProxy.dll. Be sure to copy this file to your Web application's /bin directory!
For More Information on Wsdl.exe |
| For more information on creating a proxy class without using Visual Studio .NET, be sure to read the PowerPoint presentation: Calling a Web Service from an ASP.NET Web Page. |
Creating an ASP.NET Web Page that Calls the Google Web Service
Now that we have created the proxy class, calling the Google Web Service through an ASP.NET Web page is a breeze. Before we examine how, precisely, to do this, we need to first examine what parameters the Web service methods expect. Fortunately, these methods and their input parameters are detailed in the reference section on Google's Web site. Since, in this article, we'll focus on simply performing a search via the Google Web services, let's examine the parameters for the doGoogleSearch() method.
This method takes in 10 parameters:
|
Name
|
Description
|
|
key
|
Provided by Google, this is required for you to access the Google service. Google uses the key for authentication and logging. |
|
q
|
(See Query Terms section for details on query syntax.) |
|
start
|
Zero-based index of the first desired result. |
|
maxResults
|
Number of results desired per query. The maximum value per query is 10. Note: If you do a query that doesn't have many matches, the actual number of results you get may be smaller than what you request. |
|
filter
|
Activates or deactivates automatic results filtering, which hides very similar results and results that all come from the same Web host. Filtering tends to improve the end user experience on Google, but for your application you may prefer to turn it off. (See Automatic Filtering section for more details.) |
|
restricts
|
Restricts the search to a subset of the Google Web index, such as a country like "Ukraine" or a topic like "Linux." (See Restricts for more details.) |
|
safeSearch
|
A Boolean value which enables filtering of adult content in the search results. See SafeSearch for more details. |
|
lr
|
Language Restrict - Restricts the search to documents within one or more languages. |
|
ie
|
Input Encoding - this parameter has been deprecated and is ignored. All requests to the APIs should be made with UTF-8 encoding. (See Input and Output Encodings section for details.) |
|
oe
|
Output Encoding - this parameter has been deprecated and is ignored. All requests to the APIs should be made with UTF-8 encoding. (See Input and Output Encodings for details.) |
The doGoogleSearch() method returns an instance of the GoogleSearchResult object. This object has a resultElements property, which is an array of ResultElement objects. Each ResultElement object has a number of properties, such as title, snippet, URL, summary, and so on.
Now, let's create a simple ASP.NET Web page that will display the first 10 search results for the search query ASP. This can be accomplished using the following code:
[ View a Live Demo!]
The bolded text shows the code necessary to call the Google Web service's doGoogleSearch() method. Such little code is needed thanks to the proxy class. The search results are displayed in a DataList, with each result displaying the title, summary, and the URL to access the page.
While the previous live demo illustrates how to call the Google Web service to perform a search, it is fairly limited in that it only displays the first 10 records of a predefined search query. In Part 2 we'll see how to create a more useful ASP.NET Web page that employs the Google search Web service.
While the previous live demo illustrates how to call the Google Web service to perform a search, it is fairly limited in that it only displays the first 10 records of a predefined search query. In this second part we'll examine how to build a "pseudo Google" search engine, by creating a page that the user can enter a search query for and page through the search results.
Building a More Functional Search Engine
In order to create a more functional search through Google's Web service search API, let's create an ASP.NET Web page that allows the user to input the search term and provides pagination through the data. One way to accomplish this would be to mimic Google's own approach, meaning that search terms and page numbers would be placed in the querystring. That is, if the user searched for "ASP" and was viewing records 10 through 20, the URL requested might be:
http://www.yourserver.com/Search.aspx?q=ASP&first=10&last=20
Or something to that effect. Another option is to use postback forms. The postback approach lends itself to ASP.NET moreso than the querystring approach. However, the querystring approach has the benefit that a user can bookmark a particular search query (note that with the postback form, the postback occurs via the HTTP POST headers, meaning the actual querystring does not change when searching or paging through the search results).
Despite the querystring approach's bookmarking advantage, I decided to implement this live demo using the postback approach. You are encouraged to implement the querystring approach if you so wish. The source code for the postback approach can be seen below:
[ View a Live Demo!]
The main workhorse subroutine in the above code listing is DisplaySearchResults(), which makes the Web service call, binds the results to the DataList, and displays miscellaneous information, such as the estimated number of matches found, the time to run the query, etc. This subroutine also determines whether or not the Prev. LinkButton should be enabled or not.
Realize that when calling the Google search Web service, we must specify the starting result index and how many results we want to see in the page. That is, to view the first 10 records of a search, we would pass in 0 as the starting index and 10 as the number of records to return. To view the next 10 records, we'd simply pass in 10 as the starting index (leaving 10 as the number of records to return). Notice that the ViewState is used to maintain what the starting index number. The number of records to display per page is denoted by the constant PAGE_SIZE.
To allow for pagination, two LinkButtons are used, which, when clicked, cause the nextRecs and prevRecs event handlers to fire. These event handlers simply update the starting record number to view and then call DisplaySearchResults().
Conclusion
In this article we saw how to call the Google search Web service. To use the Google Web services, we started by downloading the Google Web API Developer's Kit and then creating an account to obtain a license key. Following that, we created a proxy class based on the Google Web service's WSDL file (GoogleSearch.wsdl, which is included in the Developer's Kit download). Armed with this proxy class, we could then access the Web service with just a few lines of code from our ASP.NET Web page.
Happy Programming!
As of December 5, 2006, we are no longer issuing new API keys for the SOAP Search API. Developers with existing SOAP Search API keys will not be affected.
Google SOAP Search API ReferenceOverview
1.
1.1 Search Requests
1.2 Cache Requests
1.3 Spelling Requests
2. Search Request Format
2.1 Search Parameters
2.2 Query Terms
2.3 Automatic Filtering
2.4 Restricts
2.5 Input and Output Encoding
2.6 SafeSearch
2.7 Limitations
3. Search Results Format
3.1 Search Response
3.2 Result Element
3.3 Directory Category
This document explains in detail the semantics of the function calls you can make using the Google SOAP Search API service. In this document, you will learn:
- How Google's query syntax works. How to restrict your queries to portions of Google's index, such as a particular language or country.
- How to interpret the search results information sent back by the Google SOAP Search API service.
You may also find the following files from the Google SOAP Search API developer kit to be helpful:
- GoogleSearch.wsdl - WSDL description for Google SOAP Search API SOAP interface. soap-samples/ - example SOAP messages and responses.
- javadoc/index.html - javadoc for the example Java libraries.
For comments or questions, please use the Google SOAP Search API discussion group.
| 1.1 Search Requests |
Back to top |
Search requests submit a query string and a set of parameters to the Google SOAP Search API service and receive in return a set of search results. Search results are derived from Google's index of billions of web pages.
The details of the interactions involved with search requests are covered in the Search Request Format and Search Results Format sections of this document.
| 1.2 Cache Requests |
Back to top |
Cache requests submit a URL to the Google SOAP Search API service and receive in return the contents of the URL when Google's crawlers last visited the page (if available).
Please note that Google is not affiliated with the authors of cached pages nor responsible for their content.
The return type for cached pages is base64 encoded text.
| 1.3 Spelling Requests |
Back to top |
Spelling requests submit a query to the Google SOAP Search API service and receive in return a suggested spell correction for the query (if available). Spell corrections mimic the same behavior as found on Google's Web site.
Spelling requests are subject to the same query string limitations as any other search request. (The input string is limited to 2048 bytes and 10 individual words.)
The return type for spelling requests is a text string.
![]() |
| 2. Search Request Format |
Back to top |
| 2.1 Search Parameters |
Back to top |
This table lists all the valid name-value pairs that can be used in a search request and describes how these parameters will modify the search results.
|
Name
|
Description
|
|
key
|
Provided by Google, this is required for you to access the Google service. Google uses the key for authentication and logging. |
|
q
|
(See Query Terms section for details on query syntax.) |
|
start
|
Zero-based index of the first desired result. |
|
maxResults
|
Number of results desired per query. The maximum value per query is 10. Note: If you do a query that doesn't have many matches, the actual number of results you get may be smaller than what you request. |
|
filter
|
Activates or deactivates automatic results filtering, which hides very similar results and results that all come from the same Web host. Filtering tends to improve the end user experience on Google, but for your application you may prefer to turn it off. (See Automatic Filtering section for more details.) |
|
restricts
|
Restricts the search to a subset of the Google Web index, such as a country like "Ukraine" or a topic like "Linux." (See Restricts for more details.) |
|
safeSearch
|
A Boolean value which enables filtering of adult content in the search results. See SafeSearch for more details. |
|
lr
|
Language Restrict - Restricts the search to documents within one or more languages. |
|
ie
|
Input Encoding - this parameter has been deprecated and is ignored. All requests to the API should be made with UTF-8 encoding. (See Input and Output Encodings section for details.) |
|
oe
|
Output Encoding - this parameter has been deprecated and is ignored. All requests to the API should be made with UTF-8 encoding. (See Input and Output Encodings for details.) |
| 2.2 Query Terms - |
Back to top |
Default Search
By default, Google searches for all of your search terms, as well as for relevant variations of the terms you've entered. There is no need to include "AND" between terms. Keep in mind that the order of the terms in the query will affect the search results.
Stop Words
Google ignores common words and characters such as "where" and "how," as well as certain single digits and single letters. Common words that are ignored are known as stop words. However, you can prevent Google from ignoring stop words by enclosing them in quotes, such as in the phrase "to be or not to be".
Special Characters
By default, all non-alphanumeric characters that are included in a search query are treated as word separators. The only exceptions are the following: double quote mark ( " ), plus sign ( + ), minus sign or hyphen ( - ), and ampersand ( & ). The ampersand character ( & ) is treated as another character in the query term in which it is included, while the remaining exception characters correspond to search features listed in the section below.
Special Query Terms
Google supports the use of several special query terms that allow the user or search administrator to access additional capabilities of the Google search engine.ign in front of it.
|
Special Query Capability
|
Example Query
|
Description
|
| Include Query Term |
Star Wars Episode +I |
If a common word is essential to getting the results you want, you can include it by putting a "+" sign in front of it. |
| Exclude Query Term |
bass -music |
You can exclude a word from your search by putting a minus sign ("-") immediately in front of the term you want to exclude from the search results. |
| Phrase Search |
"yellow pages" |
Search for complete phrases by enclosing them in quotation marks or connecting them with hyphens. Words marked in this way will appear together in all results exactly as entered. Note: You may need to use a "+" to force inclusion of common words in a phrase. |
| Boolean OR Search |
vacation london OR paris |
Google search supports the Boolean I operator. To retrieve pages that include either word A or word B, use an uppercase OR between terms. |
| Site Restricted Search |
admission site:www.stanford.edu |
If you know the specific web site you want to search but aren't sure where the information is located within that site, you can use Google to search only within a specific web site. Do this by entering your query followed by the string "site:" followed by the host name. Note: The exclusion operator ("-") can be applied to this query term to remove a web site from consideration in the search. Note: Only one site: term per query is supported. |
| Date Restricted Search |
Star Wars daterange:2452122-2452234 |
If you want to limit your results to documents that were published within a specific date range, then you can use the "daterange:" query term to accomplish this. The "daterange:" query term must be in the following format:
daterange:-
where
= Julian date indicating the start of the date range
= Julian date indicating the end of the date range
The Julian date is calculated by the number of days since January 1, 4713 BC. For example, the Julian date for August 1, 2001 is 2452122. |
| Title Search (term) |
intitle:Google search |
If you prepend "intitle:" to a query term, Google search restricts the results to documents containing that word in the title. Note there can be no space between the "intitle:" and the following word. Note: Putting "intitle:" in front of every word in your query is equivalent to putting "allintitle:" at the front of your query. |
| Title Search (all) |
allintitle: Google search |
Starting a query with the term "allintitle:" restricts the results to those with all of the query words in the title. |
| URL Search (term) |
inurl:Google search |
If you prepend "inurl:" to a query term, Google search restricts the results to documents containing that word in the result URL. Note there can be no space between the "inurl:" and the following word. Note: "inurl:" works only on words , not URL components. In particular, it ignores punctuation and uses only the first word following the "inurl:" operator. To find multiple words in a result URL, use the "inurl:" operator for each word. Note: Putting "inurl:" in front of every word in your query is equivalent to putting "allinurl:" at the front of your query. |
| URL Search (all) |
allinurl: Google search |
Starting a query with the term "allinurl:" restricts the results to those with all of the query words in the result URL. Note: "allinurl:" works only on words, not URL components. In particular, it ignores punctuation. Thus, "allinurl: foo/bar" restricts the results to pages with the words "foo" and "bar"" in the URL, but does not require that they be separated by a slash within that URL, that they be adjacent, or that they be in that particular word order. There is currently no way to enforce these constraints. |
| Text Only Search (all) |
allintext: Google search |
Starting a query with the term "allintext:" restricts the results to those with all of the query words in only the body text, ignoring link, URL, and title matches. |
| Links Only Search (all) |
allinlinks: Google search |
Starting a query with the term "allinlinks:" restricts the results to those with all of the query words in the URL links on the page. |
| File Type Filtering |
Google filetype:doc OR filetype:pdf |
The query prefix "filetype:" filters the results returned to include only documents with the extension specified immediately after. Note there can be no space between "filetype:"; and the specified extension. Note: Multiple file types can be included in a filtered search by adding more "filetype:" terms to the search query. |
| File Type Exclusion |
Google -filetype:doc -filetype:pdf |
The query prefix "-filetype:" filters the results to exclude documents with the extension specified immediately after. Note there can be no space between "-filetype:" and the specified extension. Note: Multiple file types can be excluded in a filtered search by adding more "-filetype:" terms to the search query. |
| Web Document Info |
info:www.google.com |
The query prefix "info:" returns a single result for the specified URL if it exists in the index. Note: No other query terms can be specified when using this special query term. |
| Back Links |
link:www.google.com |
The query prefix "link:" lists web pages that have links to the specified web page. Note there can be no space between "link:" and the web page URL. Note: No other query terms can be specified when using this special query term. |
| Related Links |
related:www.google.com |
The query prefix "related:" lists web pages that are similar to the specified web page. Note there can be no space between "related:" and the web page URL. Note: No other query terms can be specified when using this special query term. |
| Cached Results Page |
cache:www.google.com web |
The query prefix "cache:" returns the cached HTML version of the specified web document that the Google search crawled. Note there can be no space between "cache:" and the web page URL. If you include other words in the query, Google will highlight those words within the cached document. |
| 2.3 Automatic Filtering - |
Back to top |
The parameter causes Google to filter out some of the results for a given search. This is done to enhance the user experience on Google.com, but for your application, you may prefer to turn filtering off in order to get the full set of search results.
When enabled, filtering takes the following actions:
- Near-Duplicate Content Filter = If multiple search results contain identical titles and snippets, then only one of the documents is returned.
- Host Crowding = If multiple results come from the same Web host, then only the first two are returned.
| 2.4 Restricts - |
Back to top |
Google provides the ability to search a predefined subset of Google's web index. This is enabled by using the lr and restrict parameters.
- language restrict
To search for documents within a particular language, use the parameter, using one of the values in the table below.
|
Language
|
value
|
| Arabic |
lang_ar |
| Chinese (S) |
lang_zh-CN |
| Chinese (T) |
lang_zh-TW |
| Czech |
lang_cs |
| Danish |
lang_da |
| Dutch |
lang_nl |
| English |
lang_en |
| Estonian |
lang_et |
| Finnish |
lang_fi |
| French |
lang_fr |
| German |
lang_de |
| Greek |
lang_el |
| Hebrew |
lang_iw |
| Hungarian |
lang_hu |
|
|
Language
|
value
|
| Icelandic |
lang_is |
| Italian |
lang_it |
| Japanese |
lang_ja |
| Korean |
lang_ko |
| Latvian |
lang_lv |
| Lithuanian |
lang_lt |
| Norwegian |
lang_no |
| Portuguese |
lang_pt |
| Polish |
lang_pl |
| Romanian |
lang_ro |
| Russian |
lang_ru |
| Spanish |
lang_es |
| Swedish |
lang_sv |
| Turkish |
lang_tr |
|
- Country and Topic Restricts
Google allows you to search for Web information within one or more countries, using an algorithm that considers the top level domain name of the server and the geographic location of the server IP address.
The automatic country sub-collections currently supported are listed below:
|
Country
|
value
AD-CL
|
| Andorra |
countryAD |
| United Arab Emirates |
countryAE |
| Afghanistan |
countryAF |
| Antigua and Barbuda |
countryAG |
| Anguilla |
countryAI |
| Albania |
countryAL |
| Armenia |
countryAM |
| Netherlands Antilles |
countryAN |
| Angola |
countryAO |
| Antarctica |
countryAQ |
| Argentina |
countryAR |
| American Samoa |
countryAS |
| Austria |
countryAT |
| Australia |
countryAU |
| Aruba |
countryAW |
| Azerbaijan |
countryAZ |
| Bosnia and Herzegowina |
countryBA |
| Barbados |
countryBB |
| Bangladesh |
countryBD |
| Belgium |
countryBE |
| Burkina Faso |
countryBF |
| Bulgaria |
countryBG |
| Bahrain |
countryBH |
| Burundi |
countryBI |
| Benin |
countryBJ |
| Bermuda |
countryBM |
| Brunei Darussalam |
countryBN |
| Bolivia |
countryBO |
| Brazil |
countryBR |
| Bahamas |
countryBS |
| Bhutan |
countryBT |
| Bouvet Island |
countryBV |
| Botswana |
countryBW |
| Belarus |
countryBY |
| Belize |
countryBZ |
| Canada |
countryCA |
| Cocos (Keeling) Islands |
countryCC |
| Congo, The Democratic Republic of the |
countryCD |
| Central African Republic |
countryCF |
| Congo |
countryCG |
| Burundi |
countryBI |
| Benin |
countryBJ |
| Bermuda |
countryBM |
| Brunei Darussalam |
countryBN |
| Bolivia |
countryBO |
| Brazil |
countryBR |
| Bahamas |
countryBS |
| Bhutan |
countryBT |
| Bouvet Island |
countryBV |
| Botswana |
countryBW |
| Belarus |
countryBY |
| Belize |
countryBZ |
| Canada |
countryCA |
| Cocos (Keeling) Islands |
countryCC |
| Congo, The Democratic Republic of the |
countryCD |
| Central African Republic |
countryCF |
| Congo |
countryCG |
| Switzerland |
countryCH |
| Cote D'ivoire |
countryCI |
| Cook Islands |
countryCK |
| Chile |
countryCL |
|
|
Country
|
value
CM-JO
|
| Cameroon |
countryCM |
| China |
countryCN |
| Colombia |
countryCO |
| Costa Rica |
countryCR |
| Cuba |
countryCU |
| Cape Verde |
countryCV |
| Christmas Island |
countryCX |
| Cyprus |
countryCY |
| Czech Republic |
countryCZ |
| Germany |
countryDE |
| Djibouti |
countryDJ |
| Denmark |
countryDK |
| Dominica |
countryDM |
| Dominican Republic |
countryDO |
| Algeria |
countryDZ |
| Ecuador |
countryEC |
| Estonia |
countryEE |
| Egypt |
countryEG |
| Western Sahara |
countryEH |
| Eritrea |
countryER |
| Spain |
countryES |
| Ethiopia |
countryET |
| European Union |
countryEU |
| Finland |
countryFI |
| Fiji |
countryFJ |
| Falkland Islands (Malvinas) |
countryFK |
| Micronesia, Federated States of |
countryFM |
| Faroe Islands |
countryFO |
| France |
countryFR |
| France, Metropolitan |
countryFX |
| Gabon |
countryGA |
| United Kingdom |
countryUK |
| Grenada |
countryGD |
| Georgia |
countryGE |
| French Quiana |
countryGF |
| Ghana |
countryGH |
| Gibraltar |
countryGI |
| Greenland |
countryGL |
| Gambia |
countryGM |
| Guinea |
countryGN |
| Guadeloupe |
countryGP |
| Equatorial Guinea |
countryGQ |
| Greece |
countryGR |
| South Georgia and the South Sandwich Islands |
countryGS |
| Guatemala |
countryGT |
| Guam |
countryGU |
| Guinea-Bissau |
countryGW |
| Guyana |
countryGY |
| Hong Kong |
countryHK |
| Heard and Mc Donald Islands |
countryHM |
| Honduras |
countryHN |
| Croatia (local name: Hrvatska) |
countryHR |
| Haiti |
countryHT |
| Hungary |
countryHU |
| Indonesia |
countryID |
| Ireland |
countryIE |
| Israel |
countryIL |
| India |
countryIN |
| British Indian Ocean Territory |
countryIO |
| Iraq |
countryIQ |
| Iran (Islamic Republic of) |
countryIR |
| Iceland |
countryIS |
| Italy |
countryIT |
| Jamaica |
countryJM |
| Jordan |
countryJO |
|
|
Country
|
value
JP-PS
|
| Japan |
countryJP |
| Kenya |
countryKE |
| Kyrgyzstan |
countryKG |
| Cambodia |
countryKH |
| Kiribati |
countryKI |
| Comoros |
countryKM |
| Saint Kitts and Nevis |
countryKN |
| Korea, Democratic People's Republic of |
countryKP |
| Korea, Republic of |
countryKR |
| Kuwait |
countryKW |
| Cayman Islands |
countryKY |
| Kazakhstan |
countryKZ |
| Lao People's Democratic Republic |
countryLA |
| Lebanon |
countryLB |
| Saint Lucia |
countryLC |
| Liechtenstein |
countryLI |
| Sri Lanka |
countryLK |
| Liberia |
countryLR |
| Lesotho |
countryLS |
| Lithuania |
countryLT |
| Luxembourg |
countryLU |
| Latvia |
countryLV |
| Libyan Arab Jamahiriya |
countryLY |
| Morocco |
countryMA |
| Monaco |
countryMC |
| Moldova |
countryMD |
| Madagascar |
countryMG |
| Marshall Islands |
countryMH |
| Macedonia, The Former Yugoslav Republic of |
countryMK |
| Mali |
countryML |
| Myanmar |
countryMM |
| Mongolia |
countryMN |
| Macau |
countryMO |
| Northern Mariana Islands |
countryMP |
| Martinique |
countryMQ |
| Mauritania |
countryMR |
| Montserrat |
countryMS |
| Malta |
countryMT |
| Mauritius |
countryMU |
| Maldives |
countryMV |
| Malawi |
countryMW |
| Mexico |
countryMX |
| Malaysia |
countryMY |
| Mozambique |
countryMZ |
| Namibia |
countryNA |
| New Caledonia |
countryNC |
| Niger |
countryNE |
| Norfolk Island |
countryNF |
| Nigeria |
countryNG |
| Nicaragua |
countryNI |
| Netherlands |
countryNL |
| Norway |
countryNO |
| Nepal |
countryNP |
| Nauru |
countryNR |
| Niue |
countryNU |
| New Zealand |
countryNZ |
| Oman |
countryOM |
| Panama |
countryPA |
| Peru |
countryPE |
| French Polynesia |
countryPF |
| Papua New Guinea |
countryPG |
| Philippines |
countryPH |
| Pakistan |
countryPK |
| Poland |
countryPL |
| St. Pierre and Miquelon |
countryPM |
| Pitcairn |
countryPN |
| Puerto Rico |
countryPR |
| Palestine |
countryPS |
|
|
Country
|
value
PT-ZR
|
| Portugal |
countryPT |
| Palau |
countryPW |
| Paraguay |
countryPY |
| Qatar |
countryQA |
| Reunion |
countryRE |
| Romania |
countryRO |
| Russian Federation |
countryRU |
| Rwanda |
countryRW |
| Saudi Arabia |
countrySA |
| Solomon Islands |
countrySB |
| Seychelles |
countrySC |
| Sudan |
countrySD |
| Sweden |
countrySE |
| Singapore |
countrySG |
| St. Helena |
countrySH |
| Slovenia |
countrySI |
| Svalbard and Jan Mayen Islands |
countrySJ |
| Slovakia (Slovak Republic) |
countrySK |
| Sierra Leone |
countrySL |
| San Marino |
countrySM |
| Senegal |
countrySN |
| Somalia |
countrySO |
| Suriname |
countrySR |
| Sao Tome and Principe |
countryST |
| El Salvador |
countrySV |
| Syria |
countrySY |
| Swaziland |
countrySZ |
| Turks and Caicos Islands |
countryTC |
| Chad |
countryTD |
| French Southern Territories |
countryTF |
| Togo |
countryTG |
| Thailand |
countryTH |
| Tajikistan |
countryTJ |
| Tokelau |
countryTK |
| Turkmenistan |
countryTM |
| Tunisia |
countryTN |
| Tonga |
countryTO |
| East Timor |
countryTP |
| Turkey |
countryTR |
| Trinidad and Tobago |
countryTT |
| Tuvalu |
countryTV |
| Taiwan |
countryTW |
| Tanzania |
countryTZ |
| Ukraine |
countryUA |
| Uganda |
countryUG |
| United States Minor Outlying Islands |
countryUM |
| United States |
countryUS |
| Uruguay |
countryUY |
| Uzbekistan |
countryUZ |
| Holy See (Vatican City State) |
countryVA |
| Saint Vincent and the Grenadines |
countryVC |
| Venezuela |
countryVE |
| Virgin Islands (British) |
countryVG |
| Virgin Islands (U.S.) |
countryVI |
| Vietnam |
countryVN |
| Vanuatu |
countryVU |
| Wallis and Futuna Islands |
countryWF |
| Samoa |
countryWS |
| Yemen |
countryYE |
| Mayotte |
countryYT |
| Yugoslavia |
countryYU |
| South Africa |
countryZA |
| Zambia |
countryZM |
| Zaire |
countryZR |
|
Google also has four topic restricts:
|
Topic
|
value
|
| US. Government |
unclesam |
| Linux |
linux |
| Macintosh |
mac |
| FreeBSD |
bsd |
|
Combining the and parameters: Search requests which use the lr and restrict parameters support the Boolean operators identified in the table below (in order of precedence).
Note: If both lr and restrict parameters are used in a search request, the sub-collection strings will be combined together using "AND" logic.
|
Boolean Operator
|
Sample Usage
|
Description
|
| Boolean NOT [ - ] |
-lang_fr |
Removes all results which are defined as part of the sub-collection immediately following the "-" operator. The example restrict value would remove all results in French. |
| Boolean AND [ . ] |
linux.countryFR |
Returns results which are in the intersection of the results returned by the sub-collection to either side of the "." operator. The example restrict value would return all results which are from both the "linux" subtopic and identified as being located in France. |
| Boolean OR [ | ] |
lang_en|lang_fr |
Returns results which are in either of the results returned by the sub-collection to either side of the "|" operator. The example restrict value would return all results matching the query that are in either the French or English sub-collections. |
| Parentheses [ ( ) ] |
(linux).(-(conutryUK|countryUS)) |
All terms within the innermost set of parentheses in a sub-collection string will be evaluated before terms outside the parentheses are evaluated. Use parentheses to adjust the order of term evaluation. The example restrict value would return all results in the "linux" custom sub-collection that are not in either the United States or United Kingdom sub-collections. |
Note: Spaces are not valid characters in the restrict parameter.
| 2.5 Input and Output Encodings - , |
Back to top |
In order to support searching documents in multiple languages and character encodings the Google SOAP Search API performs all requests and responses in the UTF-8 encoding. The parameters and are required in client requests but their values are ignored. Clients should encode all request data in UTF-8 and should expect results to be in UTF-8.
| 2.6 SafeSearch - |
Back to top |
Many Google users prefer not to have adult sites included in their search results. Google's SafeSearch feature screens for sites that contain this type of information and eliminates them from search results. While no filter is 100% accurate, Google's filter uses advanced proprietary technology that checks keywords and phrases, URLs, and Open Directory categories. If you have SafeSearch activated and still find websites containing offensive content in your results, please contact us and we'll investigate it.
| 2.7 Limitations |
Back to top |
There are some important limitations you should be aware of. Some of these are because Google's infrastructure is currently optimized for end users. However, in the future we hope to vastly increase the limits for Google SOAP Search API developers.
|
Component
|
Limit
|
| Search request |
length 2048 bytes |
| Maximum number of words in the query |
10 |
| Maximum number of site: terms in the query |
1 (per search request) |
| Maximum number of results per query |
10 |
| Maximum value of + |
1000 |
|
![]() |
| 3. Search Results Format |
Back to top |
| 3.1 Search Response |
Back to top |
Each time you issue a search request to the Google service, a response is returned back to you. This section describes the meanings of the values returned to you.
- A Boolean value indicating whether filtering was performed on the search results. This will be "true" only if (a) you requested filtering and (b) filtering actually occurred.
- A text string intended for display to an end user. One of the most common messages found here is a note that "stop words" were removed from the search automatically. (This happens for very common words such as "and" and "as.")
- The estimated total number of results that exist for the query. Note: The estimated number may be either higher or lower than the actual number of results that exist.
- A Boolean value indicating that the estimate is actually the exact value.
- An array of items. This corresponds to the actual list of search results.
- This is the value of for the search request.
- Indicates the index (1-based) of the first search result in .
- Indicates the index (1-based) of the last search result in .
- A text string intended for display to the end user. It provides instructive suggestions on how to use Google.
- An array of items. This corresponds to the ODP directory matches for this search.
- Text, floating-point number indicating the total server time to return the search results, measured in seconds.
| 3.2 Result Element |
Back to top |
- If the search result has a listing in the ODP directory, the ODP summary appears here as a text string.
- The URL of the search result, returned as text, with an absolute URL path.
- A text excerpt from the results page that shows the query in context as it appears on the matching results page. This is formatted HTML and usually includes tags within it. Query terms will be highlighted in bold in the results, and line breaks will be included for proper text wrapping. If Google searched for stemmed variants of the query terms using its proprietary technology, those terms will also be highlighted in bold in the snippet. Note that the query term does not always appear in the snippet. </strong> - The title of the search result, returned as HTML.</font></p>
<p><font size="-1"><strong><cachedSize></strong> - Text (Integer + "k"). Indicates that a cached version of the <URL> is available; size is indicated in kilobytes.</font></p>
<p><font size="-1"><strong><relatedInformationPresent></strong> - Boolean indicating that the "related:" query term is supported for this URL.</font></p>
<p><font size="-1"><strong><hostName></strong> - When filtering occurs, a maximum of two results from any given host is returned. When this occurs, the second resultElement that comes from that host contains the host name in this parameter.</font></p>
<p><font size="-1"><strong><directoryCategory></strong> - See below.</font></p>
<p><font size="-1"><strong><directoryTitle></strong> - If the URL for this resultElement is contained in the ODP directory, the title that appears in the directory appears here as a text string. Note that the directoryTitle may be different from the URL's <title>.</font></p>
<p></p>
<p> </p>
<table width="100%" border="0">
<tbody>
<tr>
<td width="80%"><strong>3.3 Directory Category</strong></td>
<td width="20%"><font size="-1"><font color="#551a8b">Back to top</font> </font></td>
</tr>
</tbody>
</table>
<p><font size="-1"><strong><fullViewableName></strong> - Text, containing the ODP directory name for the current ODP category.</font></p>
<p><font size="-1"><strong><specialEncoding></strong> - Specifies the encoding scheme of the directory information.</font></p>
</blockquote>
</div>
</div>
</div>
</div>
</div>
<!--PC和WAP自适应版-->
<div id="SOHUCS" sid="1288015524403392512"></div>
<script type="text/javascript" src="/views/front/js/chanyan.js"></script>
<!-- 文章页-底部 动态广告位 -->
<div class="youdao-fixed-ad" id="detail_ad_bottom"></div>
</div>
<div class="col-md-3">
<div class="row" id="ad">
<!-- 文章页-右侧1 动态广告位 -->
<div id="right-1" class="col-lg-12 col-md-12 col-sm-4 col-xs-4 ad">
<div class="youdao-fixed-ad" id="detail_ad_1"> </div>
</div>
<!-- 文章页-右侧2 动态广告位 -->
<div id="right-2" class="col-lg-12 col-md-12 col-sm-4 col-xs-4 ad">
<div class="youdao-fixed-ad" id="detail_ad_2"></div>
</div>
<!-- 文章页-右侧3 动态广告位 -->
<div id="right-3" class="col-lg-12 col-md-12 col-sm-4 col-xs-4 ad">
<div class="youdao-fixed-ad" id="detail_ad_3"></div>
</div>
</div>
</div>
</div>
</div>
</div>
<div class="container">
<h4 class="pt20 mb15 mt0 border-top">你可能感兴趣的:(googlec查询调用)</h4>
<div id="paradigm-article-related">
<div class="recommend-post mb30">
<ul class="widget-links">
<li><a href="/article/1835511911769272320.htm"
title="C语言如何定义宏函数?" target="_blank">C语言如何定义宏函数?</a>
<span class="text-muted">小九格物</span>
<a class="tag" taget="_blank" href="/search/c%E8%AF%AD%E8%A8%80/1.htm">c语言</a>
<div>在C语言中,宏函数是通过预处理器定义的,它在编译之前替换代码中的宏调用。宏函数可以模拟函数的行为,但它们不是真正的函数,因为它们在编译时不会进行类型检查,也不会分配存储空间。宏函数的定义通常使用#define指令,后面跟着宏的名称和参数列表,以及宏展开后的代码。宏函数的定义方式:1.基本宏函数:这是最简单的宏函数形式,它直接定义一个表达式。#defineSQUARE(x)((x)*(x))2.带参</div>
</li>
<li><a href="/article/1835509391361667072.htm"
title="Linux下QT开发的动态库界面弹出操作(SDL2)" target="_blank">Linux下QT开发的动态库界面弹出操作(SDL2)</a>
<span class="text-muted">13jjyao</span>
<a class="tag" taget="_blank" href="/search/QT%E7%B1%BB/1.htm">QT类</a><a class="tag" taget="_blank" href="/search/qt/1.htm">qt</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a><a class="tag" taget="_blank" href="/search/sdl2/1.htm">sdl2</a><a class="tag" taget="_blank" href="/search/linux/1.htm">linux</a>
<div>需求:操作系统为linux,开发框架为qt,做成需带界面的qt动态库,调用方为java等非qt程序难点:调用方为java等非qt程序,也就是说调用方肯定不带QApplication::exec(),缺少了这个,QTimer等事件和QT创建的窗口将不能弹出(包括opencv也是不能弹出);这与qt调用本身qt库是有本质的区别的思路:1.调用方缺QApplication::exec(),那么我们在接口</div>
</li>
<li><a href="/article/1835504217729626112.htm"
title="Python教程:一文了解使用Python处理XPath" target="_blank">Python教程:一文了解使用Python处理XPath</a>
<span class="text-muted">旦莫</span>
<a class="tag" taget="_blank" href="/search/Python%E8%BF%9B%E9%98%B6/1.htm">Python进阶</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a>
<div>目录1.环境准备1.1安装lxml1.2验证安装2.XPath基础2.1什么是XPath?2.2XPath语法2.3示例XML文档3.使用lxml解析XML3.1解析XML文档3.2查看解析结果4.XPath查询4.1基本路径查询4.2使用属性查询4.3查询多个节点5.XPath的高级用法5.1使用逻辑运算符5.2使用函数6.实战案例6.1从网页抓取数据6.1.1安装Requests库6.1.2代</div>
</li>
<li><a href="/article/1835502704827396096.htm"
title="将cmd中命令输出保存为txt文本文件" target="_blank">将cmd中命令输出保存为txt文本文件</a>
<span class="text-muted">落难Coder</span>
<a class="tag" taget="_blank" href="/search/Windows/1.htm">Windows</a><a class="tag" taget="_blank" href="/search/cmd/1.htm">cmd</a><a class="tag" taget="_blank" href="/search/window/1.htm">window</a>
<div>最近深度学习本地的训练中我们常常要在命令行中运行自己的代码,无可厚非,我们有必要保存我们的炼丹结果,但是复制命令行输出到txt是非常麻烦的,其实Windows下的命令行为我们提供了相应的操作。其基本的调用格式就是:运行指令>输出到的文件名称或者具体保存路径测试下,我打开cmd并且ping一下百度:pingwww.baidu.com>./data.txt看下相同目录下data.txt的输出:如果你再</div>
</li>
<li><a href="/article/1835499681732456448.htm"
title="SQL Server_查询某一数据库中的所有表的内容" target="_blank">SQL Server_查询某一数据库中的所有表的内容</a>
<span class="text-muted">qq_42772833</span>
<a class="tag" taget="_blank" href="/search/SQL/1.htm">SQL</a><a class="tag" taget="_blank" href="/search/Server/1.htm">Server</a><a class="tag" taget="_blank" href="/search/%E6%95%B0%E6%8D%AE%E5%BA%93/1.htm">数据库</a><a class="tag" taget="_blank" href="/search/sqlserver/1.htm">sqlserver</a>
<div>1.查看所有表的表名要列出CrabFarmDB数据库中的所有表(名),可以使用以下SQL语句:USECrabFarmDB;--切换到目标数据库GOSELECTTABLE_NAMEFROMINFORMATION_SCHEMA.TABLESWHERETABLE_TYPE='BASETABLE';对这段SQL脚本的解释:SELECTTABLE_NAME:这个语句的作用是从查询结果中选择TABLE_NAM</div>
</li>
<li><a href="/article/1835497411179540480.htm"
title="深入理解 MultiQueryRetriever:提升向量数据库检索效果的强大工具" target="_blank">深入理解 MultiQueryRetriever:提升向量数据库检索效果的强大工具</a>
<span class="text-muted">nseejrukjhad</span>
<a class="tag" taget="_blank" href="/search/%E6%95%B0%E6%8D%AE%E5%BA%93/1.htm">数据库</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a>
<div>深入理解MultiQueryRetriever:提升向量数据库检索效果的强大工具引言在人工智能和自然语言处理领域,高效准确的信息检索一直是一个关键挑战。传统的基于距离的向量数据库检索方法虽然广泛应用,但仍存在一些局限性。本文将介绍一种创新的解决方案:MultiQueryRetriever,它通过自动生成多个查询视角来增强检索效果,提高结果的相关性和多样性。MultiQueryRetriever的工</div>
</li>
<li><a href="/article/1835495770502033408.htm"
title="Day17笔记-高阶函数" target="_blank">Day17笔记-高阶函数</a>
<span class="text-muted">~在杰难逃~</span>
<a class="tag" taget="_blank" href="/search/Python/1.htm">Python</a><a class="tag" taget="_blank" href="/search/%E7%AC%94%E8%AE%B0/1.htm">笔记</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a><a class="tag" taget="_blank" href="/search/pycharm/1.htm">pycharm</a><a class="tag" taget="_blank" href="/search/%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90/1.htm">数据分析</a>
<div>高阶函数【重点掌握】函数的本质:函数是一个变量,函数名是一个变量名,一个函数可以作为另一个函数的参数或返回值使用如果A函数作为B函数的参数,B函数调用完成之后,会得到一个结果,则B函数被称为高阶函数常用的高阶函数:map(),reduce(),filter(),sorted()1.map()map(func,iterable),返回值是一个iterator【容器,迭代器】func:函数iterab</div>
</li>
<li><a href="/article/1835489207716507648.htm"
title="基于CODESYS的多轴运动控制程序框架:逻辑与运动控制分离,快速开发灵活操作" target="_blank">基于CODESYS的多轴运动控制程序框架:逻辑与运动控制分离,快速开发灵活操作</a>
<span class="text-muted">GPJnCrbBdl</span>
<a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a>
<div>基于codesys开发的多轴运动控制程序框架,将逻辑与运动控制分离,将单轴控制封装成功能块,对该功能块的操作包含了所有的单轴控制(归零、点动、相对定位、绝对定位、设置当前位置、伺服模式切换等等)。程序框架由主程序按照状态调用分归零模式、手动模式、自动模式、故障模式,程序状态的跳转都已完成,只需要根据不同的工艺要求完成所需的动作即可。变量的声明、地址的规划都严格按照C++的标准定义,能帮助开发者快速</div>
</li>
<li><a href="/article/1835488702881689600.htm"
title="Faiss:高效相似性搜索与聚类的利器" target="_blank">Faiss:高效相似性搜索与聚类的利器</a>
<span class="text-muted">网络·魚</span>
<a class="tag" taget="_blank" href="/search/%E5%A4%A7%E6%95%B0%E6%8D%AE/1.htm">大数据</a><a class="tag" taget="_blank" href="/search/faiss/1.htm">faiss</a>
<div>Faiss是一个针对大规模向量集合的相似性搜索库,由FacebookAIResearch开发。它提供了一系列高效的算法和数据结构,用于加速向量之间的相似性搜索,特别是在大规模数据集上。本文将介绍Faiss的原理、核心功能以及如何在实际项目中使用它。Faiss原理:近似最近邻搜索:Faiss的核心功能之一是近似最近邻搜索,它能够高效地在大规模数据集中找到与给定查询向量最相似的向量。这种搜索是近似的,</div>
</li>
<li><a href="/article/1835479758033481728.htm"
title="SpringBlade dict-biz/list 接口 SQL 注入漏洞" target="_blank">SpringBlade dict-biz/list 接口 SQL 注入漏洞</a>
<span class="text-muted">文章永久免费只为良心</span>
<a class="tag" taget="_blank" href="/search/oracle/1.htm">oracle</a><a class="tag" taget="_blank" href="/search/%E6%95%B0%E6%8D%AE%E5%BA%93/1.htm">数据库</a>
<div>SpringBladedict-biz/list接口SQL注入漏洞POC:构造请求包查看返回包你的网址/api/blade-system/dict-biz/list?updatexml(1,concat(0x7e,md5(1),0x7e),1)=1漏洞概述在SpringBlade框架中,如果dict-biz/list接口的后台处理逻辑没有正确地对用户输入进行过滤或参数化查询(PreparedSta</div>
</li>
<li><a href="/article/1835463622344667136.htm"
title="基于Python给出的PDF文档转Markdown文档的方法" target="_blank">基于Python给出的PDF文档转Markdown文档的方法</a>
<span class="text-muted">程序媛了了</span>
<a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/pdf/1.htm">pdf</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a>
<div>注:网上有很多将Markdown文档转为PDF文档的方法,但是却很少有将PDF文档转为Markdown文档的方法。就算有,比如某些网站声称可以将PDF文档转为Markdown文档,尝试过,不太符合自己的要求,而且无法保证文档没有泄露风险。于是本人为了解决这个问题,借助GPT(能使用GPT镜像或者有条件直接使用GPT的,反正能调用GPT接口就行)生成Python代码来完成这个功能。笔记、代码难免存在</div>
</li>
<li><a href="/article/1835460658280361984.htm"
title="无题" target="_blank">无题</a>
<span class="text-muted">琴韵无声</span>
<div>问了几家门诊部都没有科兴疫苗,突然自我感觉这种品牌的疫苗是不是少一些,于是又无端滋生焦虑感,可别一拖再拖影响孩子上学,学校要求下学期开学得接种完新冠疫苗。我在这种自制的焦虑的驱使下,立马上网查询看哪里能打到北京科兴的疫苗,终于找到了,大喜。与珊宝一起打车过去(路比较远,早想借此机会让她徒步拉练一下的计划泡汤了)。到达目的地,一看到医院大门前一条长龙似的队伍就知道那里应该是打疫苗的地方。迅速过去排队</div>
</li>
<li><a href="/article/1835452402178813952.htm"
title="Linux查看服务器日志" target="_blank">Linux查看服务器日志</a>
<span class="text-muted">TPBoreas</span>
<a class="tag" taget="_blank" href="/search/%E8%BF%90%E7%BB%B4/1.htm">运维</a><a class="tag" taget="_blank" href="/search/linux/1.htm">linux</a><a class="tag" taget="_blank" href="/search/%E8%BF%90%E7%BB%B4/1.htm">运维</a>
<div>一、tail这个是我最常用的一种查看方式用法如下:tail-n10test.log查询日志尾部最后10行的日志;tail-n+10test.log查询10行之后的所有日志;tail-fn10test.log循环实时查看最后1000行记录(最常用的)一般还会配合着grep用,(实时抓包)例如:tail-fn1000test.log|grep'关键字'(动态抓包)tail-fn1000test.log</div>
</li>
<li><a href="/article/1835443696431099904.htm"
title="笋丁网页自动回复机器人V3.0.0免授权版源码" target="_blank">笋丁网页自动回复机器人V3.0.0免授权版源码</a>
<span class="text-muted">希希分享</span>
<a class="tag" taget="_blank" href="/search/%E8%BD%AF%E5%B8%8C%E7%BD%9158soho_cn/1.htm">软希网58soho_cn</a><a class="tag" taget="_blank" href="/search/%E6%BA%90%E7%A0%81%E8%B5%84%E6%BA%90/1.htm">源码资源</a><a class="tag" taget="_blank" href="/search/%E7%AC%8B%E4%B8%81%E7%BD%91%E9%A1%B5%E8%87%AA%E5%8A%A8%E5%9B%9E%E5%A4%8D%E6%9C%BA%E5%99%A8%E4%BA%BA/1.htm">笋丁网页自动回复机器人</a>
<div>笋丁网页机器人一款可设置自动回复,默认消息,调用自定义api接口的网页机器人。此程序后端语言使用Golang,内存占用最高不超过30MB,1H1G服务器流畅运行。仅支持Linux服务器部署,不支持虚拟主机,请悉知!使用自定义api功能需要有一定的建站基础。源码下载:https://download.csdn.net/download/m0_66047725/89754250更多资源下载:关注我。安</div>
</li>
<li><a href="/article/1835443013749403648.htm"
title="入门MySQL——查询语法练习" target="_blank">入门MySQL——查询语法练习</a>
<span class="text-muted">K_un</span>
<div>前言:前面几篇文章为大家介绍了DML以及DDL语句的使用方法,本篇文章将主要讲述常用的查询语法。其实MySQL官网给出了多个示例数据库供大家实用查询,下面我们以最常用的员工示例数据库为准,详细介绍各自常用的查询语法。1.员工示例数据库导入官方文档员工示例数据库介绍及下载链接:https://dev.mysql.com/doc/employee/en/employees-installation.h</div>
</li>
<li><a href="/article/1835435758844997632.htm"
title="【2022 CCF 非专业级别软件能力认证第一轮(CSP-J1)入门级 C++语言试题及解析】" target="_blank">【2022 CCF 非专业级别软件能力认证第一轮(CSP-J1)入门级 C++语言试题及解析】</a>
<span class="text-muted">汉子萌萌哒</span>
<a class="tag" taget="_blank" href="/search/CCF/1.htm">CCF</a><a class="tag" taget="_blank" href="/search/noi/1.htm">noi</a><a class="tag" taget="_blank" href="/search/%E7%AE%97%E6%B3%95/1.htm">算法</a><a class="tag" taget="_blank" href="/search/%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84/1.htm">数据结构</a><a class="tag" taget="_blank" href="/search/c%2B%2B/1.htm">c++</a>
<div>一、单项选择题(共15题,每题2分,共计30分;每题有且仅有一个正确选项)1.以下哪种功能没有涉及C++语言的面向对象特性支持:()。A.C++中调用printf函数B.C++中调用用户定义的类成员函数C.C++中构造一个class或structD.C++中构造来源于同一基类的多个派生类题目解析【解析】正确答案:AC++基础知识,面向对象和类有关,类又涉及父类、子类、继承、派生等关系,printf</div>
</li>
<li><a href="/article/1835425043241332736.htm"
title="windows下python opencv ffmpeg读取摄像头实现rtsp推流 拉流" target="_blank">windows下python opencv ffmpeg读取摄像头实现rtsp推流 拉流</a>
<span class="text-muted">图像处理大大大大大牛啊</span>
<a class="tag" taget="_blank" href="/search/opencv%E5%AE%9E%E6%88%98%E4%BB%A3%E7%A0%81%E8%AE%B2%E8%A7%A3/1.htm">opencv实战代码讲解</a><a class="tag" taget="_blank" href="/search/%E8%A7%86%E8%A7%89%E5%9B%BE%E5%83%8F%E9%A1%B9%E7%9B%AE/1.htm">视觉图像项目</a><a class="tag" taget="_blank" href="/search/windows/1.htm">windows</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/opencv/1.htm">opencv</a>
<div>windows下pythonopencvffmpeg读取摄像头实现rtsp推流拉流整体流程1.下载所需文件1.1下载rtsp推流服务器1.2下载ffmpeg2.开启RTSP服务器3.opencv读取摄像头并调用ffmpeg进行推流4.opencv进行拉流5.opencv异步拉流整体流程1.下载所需文件1.1下载rtsp推流服务器下载RTSP服务器下载页面https://github.com/blu</div>
</li>
<li><a href="/article/1835420753252675584.htm"
title="微信小程序开发注意事项" target="_blank">微信小程序开发注意事项</a>
<span class="text-muted">jun778895</span>
<a class="tag" taget="_blank" href="/search/%E5%BE%AE%E4%BF%A1%E5%B0%8F%E7%A8%8B%E5%BA%8F/1.htm">微信小程序</a><a class="tag" taget="_blank" href="/search/%E5%B0%8F%E7%A8%8B%E5%BA%8F/1.htm">小程序</a>
<div>微信小程序开发是一个融合了前端开发、用户体验设计、后端服务(可选)以及微信小程序平台特性的综合性项目。这里,我将详细介绍一个典型的小程序开发项目的全过程,包括项目规划、设计、开发、测试及部署上线等各个环节,并尽量使内容达到或超过2000字的要求。一、项目规划1.1项目背景与目标假设我们要开发一个名为“智慧校园助手”的微信小程序,旨在为学生提供一站式校园生活服务,包括课程表查询、图书馆座位预约、食堂</div>
</li>
<li><a href="/article/1835414575906910208.htm"
title="Python编程 - 初识面向对象" target="_blank">Python编程 - 初识面向对象</a>
<span class="text-muted">易辰君</span>
<a class="tag" taget="_blank" href="/search/Python%E6%A0%B8%E5%BF%83%E7%BC%96%E7%A8%8B/1.htm">Python核心编程</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a>
<div>目录前言一、面向对象二、类和对象(一)类简介定义类(二)对象简介创建对象(三)总结三、实例属性和实例方法(一)实例属性创建的基本语法使用示例(二)实例方法定义实例方法的基本语法调用示例方法的示例(三)总结四、类中的self(一)基本概念(二)作用访问实例属性调用其他实例方法在构造函数中初始化对象(三)总结五、__init__方法(一)__init__方法的特点(二)基本语法(三)示例(四)总结前言</div>
</li>
<li><a href="/article/1835403761783238656.htm"
title="3.增删改查--连接查询" target="_blank">3.增删改查--连接查询</a>
<span class="text-muted">问女何所忆</span>
<div>关系型数据库的一个特点就是,多张表之间存在关系,以致于我们可以连接多张表进行查询操作,所以连接查询会是关系型数据库中最常见的操作。连接查询主要分为三种,交叉连接、内连接和外连接,我们一个个说。1、交叉连接交叉连接其实连接查询的第一个阶段,它简单表现为两张表的笛卡尔积形式,具体例子:如果你没学过数学中的笛卡尔积概念,你可以这样简单的理解这里的交叉连接:两张表的交叉连接就是一个连接合并的过程,T1表中</div>
</li>
<li><a href="/article/1835400084305571840.htm"
title="python老是报参数未定义_Python函数默认参数常见问题及解决方案" target="_blank">python老是报参数未定义_Python函数默认参数常见问题及解决方案</a>
<span class="text-muted">weixin_39935571</span>
<a class="tag" taget="_blank" href="/search/python%E8%80%81%E6%98%AF%E6%8A%A5%E5%8F%82%E6%95%B0%E6%9C%AA%E5%AE%9A%E4%B9%89/1.htm">python老是报参数未定义</a>
<div>一、默认参数python为了简化函数的调用,提供了默认参数机制:这样在调用pow函数时,就可以省略最后一个参数不写:在定义有默认参数的函数时,需要注意以下:必选参数必须在前面,默认参数在后;设置何种参数为默认参数?一般来说,将参数值变化小的设置为默认参数。python标准库实践python内建函数:函数签名可以看出,使用print('hellopython')这样的简单调用的打印语句,实际上传入了</div>
</li>
<li><a href="/article/1835397685104963584.htm"
title="Redis:缓存击穿" target="_blank">Redis:缓存击穿</a>
<span class="text-muted">我的程序快快跑啊</span>
<a class="tag" taget="_blank" href="/search/%E7%BC%93%E5%AD%98/1.htm">缓存</a><a class="tag" taget="_blank" href="/search/redis/1.htm">redis</a><a class="tag" taget="_blank" href="/search/java/1.htm">java</a>
<div>缓存击穿(热点key):部分key(被高并发访问且缓存重建业务复杂的)失效,无数请求会直接到数据库,造成巨大压力1.互斥锁:可以保证强一致性线程一:未命中之后,获取互斥锁,再查询数据库重建缓存,写入缓存,释放锁线程二:查询未命中,未获得锁(已由线程一获得),等待一会,缓存命中互斥锁实现方式:redis中setnxkeyvalue:改变对应key的value,仅当value不存在时执行,以此来实现互</div>
</li>
<li><a href="/article/1835397685729914880.htm"
title="【高阶数据结构】并查集" target="_blank">【高阶数据结构】并查集</a>
<span class="text-muted">椿融雪</span>
<a class="tag" taget="_blank" href="/search/%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84%E4%B8%8E%E7%AE%97%E6%B3%95/1.htm">数据结构与算法</a><a class="tag" taget="_blank" href="/search/%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84/1.htm">数据结构</a><a class="tag" taget="_blank" href="/search/%E5%B9%B6%E6%9F%A5%E9%9B%86/1.htm">并查集</a>
<div>文章目录一、并查集原理二、并查集实现三、并查集应用一、并查集原理在一些应用问题中,需要将n个不同的元素划分成一些不相交的集合。开始时,每个元素自成一个单元素集合,然后按一定的规律将归于同一组元素的集合合并。在此过程中要反复用到查询某一个元素归属于那个集合的运算。适合于描述这类问题的抽象数据类型称为并查集(union-findset)。比如:某公司今年校招全国总共招生10人,西安招4人,成都招3人,</div>
</li>
<li><a href="/article/1835396299915096064.htm"
title="mysql学习教程,从入门到精通,TOP 和MySQL LIMIT 子句(15)" target="_blank">mysql学习教程,从入门到精通,TOP 和MySQL LIMIT 子句(15)</a>
<span class="text-muted">知识分享小能手</span>
<a class="tag" taget="_blank" href="/search/%E5%A4%A7%E6%95%B0%E6%8D%AE/1.htm">大数据</a><a class="tag" taget="_blank" href="/search/%E6%95%B0%E6%8D%AE%E5%BA%93/1.htm">数据库</a><a class="tag" taget="_blank" href="/search/MySQL/1.htm">MySQL</a><a class="tag" taget="_blank" href="/search/mysql/1.htm">mysql</a><a class="tag" taget="_blank" href="/search/%E5%AD%A6%E4%B9%A0/1.htm">学习</a><a class="tag" taget="_blank" href="/search/oracle/1.htm">oracle</a><a class="tag" taget="_blank" href="/search/%E6%95%B0%E6%8D%AE%E5%BA%93/1.htm">数据库</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a><a class="tag" taget="_blank" href="/search/adb/1.htm">adb</a><a class="tag" taget="_blank" href="/search/%E5%A4%A7%E6%95%B0%E6%8D%AE/1.htm">大数据</a>
<div>1、TOP和MySQLLIMIT子句内容在SQL中,不同的数据库系统对于限制查询结果的数量有不同的实现方式。TOP关键字主要用于SQLServer和Access数据库中,而LIMIT子句则主要用于MySQL、PostgreSQL(通过LIMIT/OFFSET语法)、SQLite等数据库中。下面将分别详细介绍这两个功能的语法、语句以及案例。1.1、TOP子句(SQLServer和Access)1.1</div>
</li>
<li><a href="/article/1835394030880518144.htm"
title="HarmonyOS Next鸿蒙扫一扫功能实现" target="_blank">HarmonyOS Next鸿蒙扫一扫功能实现</a>
<span class="text-muted">JohnLiu_</span>
<a class="tag" taget="_blank" href="/search/HarmonyOS/1.htm">HarmonyOS</a><a class="tag" taget="_blank" href="/search/Next/1.htm">Next</a><a class="tag" taget="_blank" href="/search/harmonyos/1.htm">harmonyos</a><a class="tag" taget="_blank" href="/search/%E5%8D%8E%E4%B8%BA/1.htm">华为</a><a class="tag" taget="_blank" href="/search/%E6%89%AB%E4%B8%80%E6%89%AB/1.htm">扫一扫</a><a class="tag" taget="_blank" href="/search/%E9%B8%BF%E8%92%99/1.htm">鸿蒙</a>
<div>直接使用的是华为官方提供的api,封装成一个工具类方便调用。import{common}from'@kit.AbilityKit';import{scanBarcode,scanCore}from'@kit.ScanKit';exportnamespaceScanUtil{exportasyncfunctionstartScan(context:common.Context):Promise{if</div>
</li>
<li><a href="/article/1835392391662628864.htm"
title="metaRTC5.0 API编程指南(一)" target="_blank">metaRTC5.0 API编程指南(一)</a>
<span class="text-muted">metaRTC</span>
<a class="tag" taget="_blank" href="/search/metaRTC/1.htm">metaRTC</a><a class="tag" taget="_blank" href="/search/c%2B%2B/1.htm">c++</a><a class="tag" taget="_blank" href="/search/c%E8%AF%AD%E8%A8%80/1.htm">c语言</a><a class="tag" taget="_blank" href="/search/webrtc/1.htm">webrtc</a>
<div>概述metaRTC5.0版本API进行了重构,本篇文章将介绍webrtc传输调用流程和例子。metaRTC5.0版本提供了C++和纯C两种接口。纯C接口YangPeerConnection头文件:include/yangrtc/YangPeerConnection.htypedefstruct{void*conn;YangAVInfo*avinfo;YangStreamConfigstreamco</div>
</li>
<li><a href="/article/1835392013772615680.htm"
title="leetcode刷题day19|二叉树Part07(235. 二叉搜索树的最近公共祖先、701.二叉搜索树中的插入操作、450.删除二叉搜索树中的节点)" target="_blank">leetcode刷题day19|二叉树Part07(235. 二叉搜索树的最近公共祖先、701.二叉搜索树中的插入操作、450.删除二叉搜索树中的节点)</a>
<span class="text-muted">小冉在学习</span>
<a class="tag" taget="_blank" href="/search/leetcode/1.htm">leetcode</a><a class="tag" taget="_blank" href="/search/%E7%AE%97%E6%B3%95/1.htm">算法</a><a class="tag" taget="_blank" href="/search/%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84/1.htm">数据结构</a>
<div>235.二叉搜索树的最近公共祖先思路:二叉搜索树首先考虑中序遍历。根据二叉搜索树的特性,如果p,q分别在中间节点的左右两边,该中间节点一定是最近公共祖先,如果在同一侧,则递归这一侧即可。递归三部曲:1、传入参数:根节点,p,q,返回节点。2、终止条件:因为p,q一定存在,所以不会遍历到树的最底层,因此可以不写终止条件3、递归逻辑:如果p,q均小于root的值,递归调用左子树;如果p,q均大于roo</div>
</li>
<li><a href="/article/1835390122640633856.htm"
title="使用selenium调用firefox提示Profile Missing的问题解决" target="_blank">使用selenium调用firefox提示Profile Missing的问题解决</a>
<span class="text-muted">歪歪的酒壶</span>
<a class="tag" taget="_blank" href="/search/selenium/1.htm">selenium</a><a class="tag" taget="_blank" href="/search/%E6%B5%8B%E8%AF%95%E5%B7%A5%E5%85%B7/1.htm">测试工具</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a>
<div>在Ubuntu22.04环境中,使用python3运行selenium提示ProfileMissing,具体信息为:YourFirefoxprofilecannotbeloaded.Itmaybemissingorinaccessible在这个问题的环境中firefox浏览器工作正常。排查中,手动在命令行执行firefox可以打开浏览器,但是出现如下提示Gtk-Message:15:32:09.9</div>
</li>
<li><a href="/article/1835390120858054656.htm"
title="Redis 有哪些危险命令?如何防范?" target="_blank">Redis 有哪些危险命令?如何防范?</a>
<span class="text-muted">花小疯</span>
<a class="tag" taget="_blank" href="/search/redis/1.htm">redis</a><a class="tag" taget="_blank" href="/search/%E7%BC%93%E5%AD%98/1.htm">缓存</a><a class="tag" taget="_blank" href="/search/%E6%95%B0%E6%8D%AE%E5%BA%93/1.htm">数据库</a><a class="tag" taget="_blank" href="/search/%E5%8D%B1%E9%99%A9%E5%91%BD%E4%BB%A4/1.htm">危险命令</a><a class="tag" taget="_blank" href="/search/%E5%A4%A7%E6%95%B0%E6%8D%AE/1.htm">大数据</a>
<div>Redis有哪些危险命令?Redis的危险命令主要有以下几个:1.keys客户端可查询出所有存在的键。2.flushdb删除Redis中当前所在数据库中的所有记录,并且此命令从不会执行失败。3.flushall删除Redis中所有数据库中的所有记录,不止是当前所在数据库,并且此命令从不会执行失败。4.config客户端可修改Redis配置。怎么禁用和重命名危险命令?看下redis.conf默认配置</div>
</li>
<li><a href="/article/1835386717784338432.htm"
title="自定义分区" target="_blank">自定义分区</a>
<span class="text-muted">我的K8409</span>
<a class="tag" taget="_blank" href="/search/Hadoop/1.htm">Hadoop</a><a class="tag" taget="_blank" href="/search/hdfs/1.htm">hdfs</a><a class="tag" taget="_blank" href="/search/hadoop/1.htm">hadoop</a><a class="tag" taget="_blank" href="/search/%E5%A4%A7%E6%95%B0%E6%8D%AE/1.htm">大数据</a>
<div>通过简单例子了解partition分区类的重写方法分区是在MR的过程中进行的,属于Shuffle阶段但是在Job端不要忘记进行调用:job.setPartitionerClass(xxx.class)按照年龄分区:classAgePartitionerextendsPartitioner{@OverridepublicintgetPartition(MyComparablekey,NullWrit</div>
</li>
<li><a href="/article/46.htm"
title="Maven" target="_blank">Maven</a>
<span class="text-muted">Array_06</span>
<a class="tag" taget="_blank" href="/search/eclipse/1.htm">eclipse</a><a class="tag" taget="_blank" href="/search/jdk/1.htm">jdk</a><a class="tag" taget="_blank" href="/search/maven/1.htm">maven</a>
<div>Maven
Maven是基于项目对象模型(POM), 信息来管理项目的构建,报告和文档的软件项目管理工具。
Maven 除了以程序构建能力为特色之外,还提供高级项目管理工具。由于 Maven 的缺省构建规则有较高的可重用性,所以常常用两三行 Maven 构建脚本就可以构建简单的项目。由于 Maven 的面向项目的方法,许多 Apache Jakarta 项目发文时使用 Maven,而且公司</div>
</li>
<li><a href="/article/173.htm"
title="ibatis的queyrForList和queryForMap区别" target="_blank">ibatis的queyrForList和queryForMap区别</a>
<span class="text-muted">bijian1013</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/ibatis/1.htm">ibatis</a>
<div>一.说明
iBatis的返回值参数类型也有种:resultMap与resultClass,这两种类型的选择可以用两句话说明之:
1.当结果集列名和类的属性名完全相对应的时候,则可直接用resultClass直接指定查询结果类</div>
</li>
<li><a href="/article/300.htm"
title="LeetCode[位运算] - #191 计算汉明权重" target="_blank">LeetCode[位运算] - #191 计算汉明权重</a>
<span class="text-muted">Cwind</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/%E4%BD%8D%E8%BF%90%E7%AE%97/1.htm">位运算</a><a class="tag" taget="_blank" href="/search/LeetCode/1.htm">LeetCode</a><a class="tag" taget="_blank" href="/search/Algorithm/1.htm">Algorithm</a><a class="tag" taget="_blank" href="/search/%E9%A2%98%E8%A7%A3/1.htm">题解</a>
<div>原题链接:#191 Number of 1 Bits
要求:
写一个函数,以一个无符号整数为参数,返回其汉明权重。例如,‘11’的二进制表示为'00000000000000000000000000001011', 故函数应当返回3。
汉明权重:指一个字符串中非零字符的个数;对于二进制串,即其中‘1’的个数。
难度:简单
分析:
将十进制参数转换为二进制,然后计算其中1的个数即可。
“</div>
</li>
<li><a href="/article/427.htm"
title="浅谈java类与对象" target="_blank">浅谈java类与对象</a>
<span class="text-muted">15700786134</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a>
<div> java是一门面向对象的编程语言,类与对象是其最基本的概念。所谓对象,就是一个个具体的物体,一个人,一台电脑,都是对象。而类,就是对象的一种抽象,是多个对象具有的共性的一种集合,其中包含了属性与方法,就是属于该类的对象所具有的共性。当一个类创建了对象,这个对象就拥有了该类全部的属性,方法。相比于结构化的编程思路,面向对象更适用于人的思维</div>
</li>
<li><a href="/article/554.htm"
title="linux下双网卡同一个IP" target="_blank">linux下双网卡同一个IP</a>
<span class="text-muted">被触发</span>
<a class="tag" taget="_blank" href="/search/linux/1.htm">linux</a>
<div>转自:
http://q2482696735.blog.163.com/blog/static/250606077201569029441/
由于需要一台机器有两个网卡,开始时设置在同一个网段的IP,发现数据总是从一个网卡发出,而另一个网卡上没有数据流动。网上找了下,发现相同的问题不少:
一、
关于双网卡设置同一网段IP然后连接交换机的时候出现的奇怪现象。当时没有怎么思考、以为是生成树</div>
</li>
<li><a href="/article/681.htm"
title="安卓按主页键隐藏程序之后无法再次打开" target="_blank">安卓按主页键隐藏程序之后无法再次打开</a>
<span class="text-muted">肆无忌惮_</span>
<a class="tag" taget="_blank" href="/search/%E5%AE%89%E5%8D%93/1.htm">安卓</a>
<div>遇到一个奇怪的问题,当SplashActivity跳转到MainActivity之后,按主页键,再去打开程序,程序没法再打开(闪一下),结束任务再开也是这样,只能卸载了再重装。而且每次在Log里都打印了这句话"进入主程序"。后来发现是必须跳转之后再finish掉SplashActivity
本来代码:
// 销毁这个Activity
fin</div>
</li>
<li><a href="/article/808.htm"
title="通过cookie保存并读取用户登录信息实例" target="_blank">通过cookie保存并读取用户登录信息实例</a>
<span class="text-muted">知了ing</span>
<a class="tag" taget="_blank" href="/search/JavaScript/1.htm">JavaScript</a><a class="tag" taget="_blank" href="/search/html/1.htm">html</a>
<div>通过cookie的getCookies()方法可获取所有cookie对象的集合;通过getName()方法可以获取指定的名称的cookie;通过getValue()方法获取到cookie对象的值。另外,将一个cookie对象发送到客户端,使用response对象的addCookie()方法。
下面通过cookie保存并读取用户登录信息的例子加深一下理解。
(1)创建index.jsp文件。在改</div>
</li>
<li><a href="/article/935.htm"
title="JAVA 对象池" target="_blank">JAVA 对象池</a>
<span class="text-muted">矮蛋蛋</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/ObjectPool/1.htm">ObjectPool</a>
<div>原文地址:
http://www.blogjava.net/baoyaer/articles/218460.html
Jakarta对象池
☆为什么使用对象池
恰当地使用对象池化技术,可以有效地减少对象生成和初始化时的消耗,提高系统的运行效率。Jakarta Commons Pool组件提供了一整套用于实现对象池化</div>
</li>
<li><a href="/article/1062.htm"
title="ArrayList根据条件+for循环批量删除的方法" target="_blank">ArrayList根据条件+for循环批量删除的方法</a>
<span class="text-muted">alleni123</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a>
<div>场景如下:
ArrayList<Obj> list
Obj-> createTime, sid.
现在要根据obj的createTime来进行定期清理。(释放内存)
-------------------------
首先想到的方法就是
for(Obj o:list){
if(o.createTime-currentT>xxx){
</div>
</li>
<li><a href="/article/1189.htm"
title="阿里巴巴“耕地宝”大战各种宝" target="_blank">阿里巴巴“耕地宝”大战各种宝</a>
<span class="text-muted">百合不是茶</span>
<a class="tag" taget="_blank" href="/search/%E5%B9%B3%E5%8F%B0%E6%88%98%E7%95%A5/1.htm">平台战略</a>
<div>“耕地保”平台是阿里巴巴和安徽农民共同推出的一个 “首个互联网定制私人农场”,“耕地宝”由阿里巴巴投入一亿 ,主要是用来进行农业方面,将农民手中的散地集中起来 不仅加大农民集体在土地上面的话语权,还增加了土地的流通与 利用率,提高了土地的产量,有利于大规模的产业化的高科技农业的 发展,阿里在农业上的探索将会引起新一轮的产业调整,但是集体化之后农民的个体的话语权 将更少,国家应出台相应的法律法规保护</div>
</li>
<li><a href="/article/1316.htm"
title="Spring注入有继承关系的类(1)" target="_blank">Spring注入有继承关系的类(1)</a>
<span class="text-muted">bijian1013</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/spring/1.htm">spring</a>
<div>一个类一个类的注入
1.AClass类
package com.bijian.spring.test2;
public class AClass {
String a;
String b;
public String getA() {
return a;
}
public void setA(Strin</div>
</li>
<li><a href="/article/1443.htm"
title="30岁转型期你能否成为成功人士" target="_blank">30岁转型期你能否成为成功人士</a>
<span class="text-muted">bijian1013</span>
<a class="tag" taget="_blank" href="/search/%E6%88%90%E5%8A%9F/1.htm">成功</a>
<div> 很多人由于年轻时走了弯路,到了30岁一事无成,这样的例子大有人在。但同样也有一些人,整个职业生涯都发展得很优秀,到了30岁已经成为职场的精英阶层。由于做猎头的原因,我们接触很多30岁左右的经理人,发现他们在职业发展道路上往往有很多致命的问题。在30岁之前,他们的职业生涯表现很优秀,但从30岁到40岁这一段,很多人</div>
</li>
<li><a href="/article/1570.htm"
title="[Velocity三]基于Servlet+Velocity的web应用" target="_blank">[Velocity三]基于Servlet+Velocity的web应用</a>
<span class="text-muted">bit1129</span>
<a class="tag" taget="_blank" href="/search/velocity/1.htm">velocity</a>
<div>什么是VelocityViewServlet
使用org.apache.velocity.tools.view.VelocityViewServlet可以将Velocity集成到基于Servlet的web应用中,以Servlet+Velocity的方式实现web应用
Servlet + Velocity的一般步骤
1.自定义Servlet,实现VelocityViewServl</div>
</li>
<li><a href="/article/1697.htm"
title="【Kafka十二】关于Kafka是一个Commit Log Service" target="_blank">【Kafka十二】关于Kafka是一个Commit Log Service</a>
<span class="text-muted">bit1129</span>
<a class="tag" taget="_blank" href="/search/service/1.htm">service</a>
<div>Kafka is a distributed, partitioned, replicated commit log service.这里的commit log如何理解?
A message is considered "committed" when all in sync replicas for that partition have applied i</div>
</li>
<li><a href="/article/1824.htm"
title="NGINX + LUA实现复杂的控制" target="_blank">NGINX + LUA实现复杂的控制</a>
<span class="text-muted">ronin47</span>
<a class="tag" taget="_blank" href="/search/lua+nginx+%E6%8E%A7%E5%88%B6/1.htm">lua nginx 控制</a>
<div>安装lua_nginx_module 模块
lua_nginx_module 可以一步步的安装,也可以直接用淘宝的OpenResty
Centos和debian的安装就简单了。。
这里说下freebsd的安装:
fetch http://www.lua.org/ftp/lua-5.1.4.tar.gz
tar zxvf lua-5.1.4.tar.gz
cd lua-5.1.4
ma</div>
</li>
<li><a href="/article/1951.htm"
title="java-14.输入一个已经按升序排序过的数组和一个数字, 在数组中查找两个数,使得它们的和正好是输入的那个数字" target="_blank">java-14.输入一个已经按升序排序过的数组和一个数字, 在数组中查找两个数,使得它们的和正好是输入的那个数字</a>
<span class="text-muted">bylijinnan</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a>
<div>
public class TwoElementEqualSum {
/**
* 第 14 题:
题目:输入一个已经按升序排序过的数组和一个数字,
在数组中查找两个数,使得它们的和正好是输入的那个数字。
要求时间复杂度是 O(n) 。如果有多对数字的和等于输入的数字,输出任意一对即可。
例如输入数组 1 、 2 、 4 、 7 、 11 、 15 和数字 15 。由于 </div>
</li>
<li><a href="/article/2078.htm"
title="Netty源码学习-HttpChunkAggregator-HttpRequestEncoder-HttpResponseDecoder" target="_blank">Netty源码学习-HttpChunkAggregator-HttpRequestEncoder-HttpResponseDecoder</a>
<span class="text-muted">bylijinnan</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/netty/1.htm">netty</a>
<div>今天看Netty如何实现一个Http Server
org.jboss.netty.example.http.file.HttpStaticFileServerPipelineFactory:
pipeline.addLast("decoder", new HttpRequestDecoder());
pipeline.addLast(&quo</div>
</li>
<li><a href="/article/2205.htm"
title="java敏感词过虑-基于多叉树原理" target="_blank">java敏感词过虑-基于多叉树原理</a>
<span class="text-muted">cngolon</span>
<a class="tag" taget="_blank" href="/search/%E8%BF%9D%E7%A6%81%E8%AF%8D%E8%BF%87%E8%99%91/1.htm">违禁词过虑</a><a class="tag" taget="_blank" href="/search/%E6%9B%BF%E6%8D%A2%E8%BF%9D%E7%A6%81%E8%AF%8D/1.htm">替换违禁词</a><a class="tag" taget="_blank" href="/search/%E6%95%8F%E6%84%9F%E8%AF%8D%E8%BF%87%E8%99%91/1.htm">敏感词过虑</a><a class="tag" taget="_blank" href="/search/%E5%A4%9A%E5%8F%89%E6%A0%91/1.htm">多叉树</a>
<div>基于多叉树的敏感词、关键词过滤的工具包,用于java中的敏感词过滤
1、工具包自带敏感词词库,第一次调用时读入词库,故第一次调用时间可能较长,在类加载后普通pc机上html过滤5000字在80毫秒左右,纯文本35毫秒左右。
2、如需自定义词库,将jar包考入WEB-INF工程的lib目录,在WEB-INF/classes目录下建一个
utf-8的words.dict文本文件,</div>
</li>
<li><a href="/article/2332.htm"
title="多线程知识" target="_blank">多线程知识</a>
<span class="text-muted">cuishikuan</span>
<a class="tag" taget="_blank" href="/search/%E5%A4%9A%E7%BA%BF%E7%A8%8B/1.htm">多线程</a>
<div>
T1,T2,T3三个线程工作顺序,按照T1,T2,T3依次进行
public class T1 implements Runnable{
@Override
</div>
</li>
<li><a href="/article/2459.htm"
title="spring整合activemq" target="_blank">spring整合activemq</a>
<span class="text-muted">dalan_123</span>
<a class="tag" taget="_blank" href="/search/java+spring+jms/1.htm">java spring jms</a>
<div>整合spring和activemq需要搞清楚如下的东东1、ConnectionFactory分: a、spring管理连接到activemq服务器的管理ConnectionFactory也即是所谓产生到jms服务器的链接 b、真正产生到JMS服务器链接的ConnectionFactory还得</div>
</li>
<li><a href="/article/2586.htm"
title="MySQL时间字段究竟使用INT还是DateTime?" target="_blank">MySQL时间字段究竟使用INT还是DateTime?</a>
<span class="text-muted">dcj3sjt126com</span>
<a class="tag" taget="_blank" href="/search/mysql/1.htm">mysql</a>
<div>
环境:Windows XPPHP Version 5.2.9MySQL Server 5.1
第一步、创建一个表date_test(非定长、int时间)
CREATE TABLE `test`.`date_test` (`id` INT NOT NULL AUTO_INCREMENT ,`start_time` INT NOT NULL ,`some_content`</div>
</li>
<li><a href="/article/2713.htm"
title="Parcel: unable to marshal value" target="_blank">Parcel: unable to marshal value</a>
<span class="text-muted">dcj3sjt126com</span>
<a class="tag" taget="_blank" href="/search/marshal/1.htm">marshal</a>
<div>在两个activity直接传递List<xxInfo>时,出现Parcel: unable to marshal value异常。 在MainActivity页面(MainActivity页面向NextActivity页面传递一个List<xxInfo>): Intent intent = new Intent(this, Next</div>
</li>
<li><a href="/article/2840.htm"
title="linux进程的查看上(ps)" target="_blank">linux进程的查看上(ps)</a>
<span class="text-muted">eksliang</span>
<a class="tag" taget="_blank" href="/search/linux+ps/1.htm">linux ps</a><a class="tag" taget="_blank" href="/search/linux+ps+-l/1.htm">linux ps -l</a><a class="tag" taget="_blank" href="/search/linux+ps+aux/1.htm">linux ps aux</a>
<div>ps:将某个时间点的进程运行情况选取下来
转载请出自出处:http://eksliang.iteye.com/admin/blogs/2119469
http://eksliang.iteye.com
ps 这个命令的man page 不是很好查阅,因为很多不同的Unix都使用这儿ps来查阅进程的状态,为了要符合不同版本的需求,所以这个</div>
</li>
<li><a href="/article/2967.htm"
title="为什么第三方应用能早于System的app启动" target="_blank">为什么第三方应用能早于System的app启动</a>
<span class="text-muted">gqdy365</span>
<a class="tag" taget="_blank" href="/search/System/1.htm">System</a>
<div>Android应用的启动顺序网上有一大堆资料可以查阅了,这里就不细述了,这里不阐述ROM启动还有bootloader,软件启动的大致流程应该是启动kernel -> 运行servicemanager 把一些native的服务用命令启动起来(包括wifi, power, rild, surfaceflinger, mediaserver等等)-> 启动Dalivk中的第一个进程Zygot</div>
</li>
<li><a href="/article/3094.htm"
title="App Framework发送JSONP请求(3)" target="_blank">App Framework发送JSONP请求(3)</a>
<span class="text-muted">hw1287789687</span>
<a class="tag" taget="_blank" href="/search/jsonp/1.htm">jsonp</a><a class="tag" taget="_blank" href="/search/%E8%B7%A8%E5%9F%9F%E8%AF%B7%E6%B1%82/1.htm">跨域请求</a><a class="tag" taget="_blank" href="/search/%E5%8F%91%E9%80%81jsonp/1.htm">发送jsonp</a><a class="tag" taget="_blank" href="/search/ajax%E8%AF%B7%E6%B1%82/1.htm">ajax请求</a><a class="tag" taget="_blank" href="/search/%E8%B6%8A%E7%8B%B1%E8%AF%B7%E6%B1%82/1.htm">越狱请求</a>
<div>App Framework 中如何发送JSONP请求呢?
使用jsonp,详情请参考:http://json-p.org/
如何发送Ajax请求呢?
(1)登录
/***
* 会员登录
* @param username
* @param password
*/
var user_login=function(username,password){
// aler</div>
</li>
<li><a href="/article/3221.htm"
title="发福利,整理了一份关于“资源汇总”的汇总" target="_blank">发福利,整理了一份关于“资源汇总”的汇总</a>
<span class="text-muted">justjavac</span>
<a class="tag" taget="_blank" href="/search/%E8%B5%84%E6%BA%90/1.htm">资源</a>
<div>觉得有用的话,可以去github关注:https://github.com/justjavac/awesome-awesomeness-zh_CN 通用
free-programming-books-zh_CN 免费的计算机编程类中文书籍
精彩博客集合 hacke2/hacke2.github.io#2
ResumeSample 程序员简历</div>
</li>
<li><a href="/article/3348.htm"
title="用 Java 技术创建 RESTful Web 服务" target="_blank">用 Java 技术创建 RESTful Web 服务</a>
<span class="text-muted">macroli</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/%E7%BC%96%E7%A8%8B/1.htm">编程</a><a class="tag" taget="_blank" href="/search/Web/1.htm">Web</a><a class="tag" taget="_blank" href="/search/REST/1.htm">REST</a>
<div>转载:http://www.ibm.com/developerworks/cn/web/wa-jaxrs/
JAX-RS (JSR-311) 【 Java API for RESTful Web Services 】是一种 Java™ API,可使 Java Restful 服务的开发变得迅速而轻松。这个 API 提供了一种基于注释的模型来描述分布式资源。注释被用来提供资源的位</div>
</li>
<li><a href="/article/3475.htm"
title="CentOS6.5-x86_64位下oracle11g的安装详细步骤及注意事项" target="_blank">CentOS6.5-x86_64位下oracle11g的安装详细步骤及注意事项</a>
<span class="text-muted">超声波</span>
<a class="tag" taget="_blank" href="/search/oracle/1.htm">oracle</a><a class="tag" taget="_blank" href="/search/linux/1.htm">linux</a>
<div>前言:
这两天项目要上线了,由我负责往服务器部署整个项目,因此首先要往服务器安装oracle,服务器本身是CentOS6.5的64位系统,安装的数据库版本是11g,在整个的安装过程中碰到很多的坑,不过最后还是通过各种途径解决并成功装上了。转别写篇博客来记录完整的安装过程以及在整个过程中的注意事项。希望对以后那些刚刚接触的菜鸟们能起到一定的帮助作用。
安装过程中可能遇到的问题(注</div>
</li>
<li><a href="/article/3602.htm"
title="HttpClient 4.3 设置keeplive 和 timeout 的方法" target="_blank">HttpClient 4.3 设置keeplive 和 timeout 的方法</a>
<span class="text-muted">supben</span>
<a class="tag" taget="_blank" href="/search/httpclient/1.htm">httpclient</a>
<div>ConnectionKeepAliveStrategy kaStrategy = new DefaultConnectionKeepAliveStrategy() {
@Override
public long getKeepAliveDuration(HttpResponse response, HttpContext context) {
long keepAlive</div>
</li>
<li><a href="/article/3729.htm"
title="Spring 4.2新特性-@Import注解的升级" target="_blank">Spring 4.2新特性-@Import注解的升级</a>
<span class="text-muted">wiselyman</span>
<a class="tag" taget="_blank" href="/search/spring+4/1.htm">spring 4</a>
<div>3.1 @Import
@Import注解在4.2之前只支持导入配置类
在4.2,@Import注解支持导入普通的java类,并将其声明成一个bean
3.2 示例
演示java类
package com.wisely.spring4_2.imp;
public class DemoService {
public void doSomethin</div>
</li>
</ul>
</div>
</div>
</div>
<div>
<div class="container">
<div class="indexes">
<strong>按字母分类:</strong>
<a href="/tags/A/1.htm" target="_blank">A</a><a href="/tags/B/1.htm" target="_blank">B</a><a href="/tags/C/1.htm" target="_blank">C</a><a
href="/tags/D/1.htm" target="_blank">D</a><a href="/tags/E/1.htm" target="_blank">E</a><a href="/tags/F/1.htm" target="_blank">F</a><a
href="/tags/G/1.htm" target="_blank">G</a><a href="/tags/H/1.htm" target="_blank">H</a><a href="/tags/I/1.htm" target="_blank">I</a><a
href="/tags/J/1.htm" target="_blank">J</a><a href="/tags/K/1.htm" target="_blank">K</a><a href="/tags/L/1.htm" target="_blank">L</a><a
href="/tags/M/1.htm" target="_blank">M</a><a href="/tags/N/1.htm" target="_blank">N</a><a href="/tags/O/1.htm" target="_blank">O</a><a
href="/tags/P/1.htm" target="_blank">P</a><a href="/tags/Q/1.htm" target="_blank">Q</a><a href="/tags/R/1.htm" target="_blank">R</a><a
href="/tags/S/1.htm" target="_blank">S</a><a href="/tags/T/1.htm" target="_blank">T</a><a href="/tags/U/1.htm" target="_blank">U</a><a
href="/tags/V/1.htm" target="_blank">V</a><a href="/tags/W/1.htm" target="_blank">W</a><a href="/tags/X/1.htm" target="_blank">X</a><a
href="/tags/Y/1.htm" target="_blank">Y</a><a href="/tags/Z/1.htm" target="_blank">Z</a><a href="/tags/0/1.htm" target="_blank">其他</a>
</div>
</div>
</div>
<footer id="footer" class="mb30 mt30">
<div class="container">
<div class="footBglm">
<a target="_blank" href="/">首页</a> -
<a target="_blank" href="/custom/about.htm">关于我们</a> -
<a target="_blank" href="/search/Java/1.htm">站内搜索</a> -
<a target="_blank" href="/sitemap.txt">Sitemap</a> -
<a target="_blank" href="/custom/delete.htm">侵权投诉</a>
</div>
<div class="copyright">版权所有 IT知识库 CopyRight © 2000-2050 E-COM-NET.COM , All Rights Reserved.
<!-- <a href="https://beian.miit.gov.cn/" rel="nofollow" target="_blank">京ICP备09083238号</a><br>-->
</div>
</div>
</footer>
<!-- 代码高亮 -->
<script type="text/javascript" src="/static/syntaxhighlighter/scripts/shCore.js"></script>
<script type="text/javascript" src="/static/syntaxhighlighter/scripts/shLegacy.js"></script>
<script type="text/javascript" src="/static/syntaxhighlighter/scripts/shAutoloader.js"></script>
<link type="text/css" rel="stylesheet" href="/static/syntaxhighlighter/styles/shCoreDefault.css"/>
<script type="text/javascript" src="/static/syntaxhighlighter/src/my_start_1.js"></script>
</body>
</html>