SpringBoot 的类的加载过程和循环依赖详细过程
Springboot 的类的加载过程和循环依赖问题
1)首先加载.class的文件,spring会将这个类里面的所有属性拆分。
会走refresh()这个方法 这里,如果是用xml的形式配置的

<bean id="xxx"/>
这种形式,会在obtainFreshBeanFactory(返回值是一个beanFactory)去将这个类的ID ,属性fileds这些放入beanDefinitionMap中(这里面会放入beanClass文件,是否懒加载之类的,dependsOn这些),ID放入一个有序ArrayList中;
如果是基于注解@Component去加载,那么就会在
invokeBeanFactoryPostProcessors(beanFacotry);这个方法去进行假如Map和list的操作
之后会进入创建对象的核心方法:
finishBeanFactoryIniialization(beanFactory)

在这个方法中会去调用一个**preInstantiateSingletons()**的方法;是个接口
注意这里是创建单例模式下的对象,spring在创建模型和单例的时候是不一样的。在单例模式下,是先创建对象,然后通过set方法去注入属性;比如A B循环依赖,那么会先将A B 不管三七二十一都先创建出来,再set;然后在多例模式下,会先检查当前对象是否有依赖,有依赖就会先不创建,先去创建依赖对象,就会形成死循环
在**preInstantiateSingletons()**这个实现中,会进行遍历。
protected void finishBeanFactoryInitialization(ConfigurableListableBeanFactory beanFactory) {
if (beanFactory.containsBean("conversionService") && beanFactory.isTypeMatch("conversionService", ConversionService.class)) {
beanFactory.setConversionService((ConversionService)beanFactory.getBean("conversionService", ConversionService.class));
}
if (!beanFactory.hasEmbeddedValueResolver()) {
beanFactory.addEmbeddedValueResolver((strVal) -> {
return this.getEnvironment().resolvePlaceholders(strVal);
});
}
String[] weaverAwareNames = beanFactory.getBeanNamesForType(LoadTimeWeaverAware.class, false, false);
String[] var3 = weaverAwareNames;
int var4 = weaverAwareNames.length;
for(int var5 = 0; var5 < var4; ++var5) {
String weaverAwareName = var3[var5];
this.getBean(weaverAwareName);
}
beanFactory.setTempClassLoader((ClassLoader)null);
beanFactory.freezeConfiguration();
//此处核心方法
beanFactory.preInstantiateSingletons();
}
2 )、再此之前,会进行判断,spring会判断这个类是否有扩展,这个扩展就相当于,你自己创建了一个类去实现了spring的后置处理器,也就是BeanFactoryPostProcessor这个接口。比如可以在这个里面修改,比如把创建的A类换成B类这种操作。然后将修改完的就放入到了beanDefinitionMap中,然后Spring再拿beanDefinitionMap去创建对象的时候就会根据你的自已的扩展去创建了。
3)、在遍历中,会进行判断,诸如,当前类是否是抽象,是否是单例,是否是懒加载,是否是一个工厂bean,如果不是,则就会调用**getBean(beanName)**这个方法
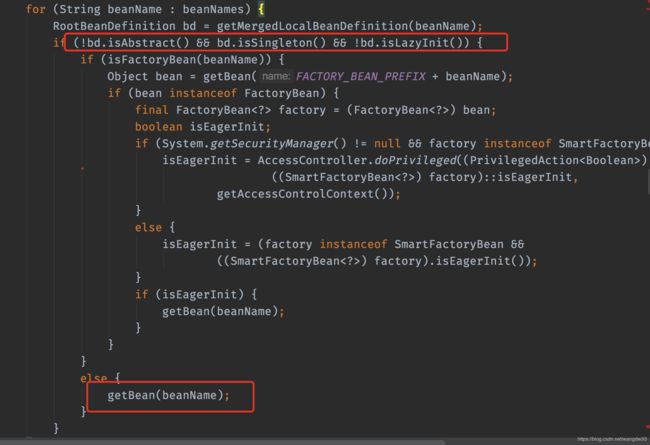
4)、然后就会调用**doGetBean(beanName)**这个方法
--1 首先会**transFormedBeanName(beanName)**判断当前ID(或者说别名,不允许重复,如果重复会覆盖)是不是合法的。
--2 判断完之后会去首先调用一下getSingleton()这个方法,在这个方法中会去SingletonObjects()中获取,其实就是从Spring容器(也是一个Map)的单例池获取。
--3 如果是第一次创建,肯定是没有的为null,
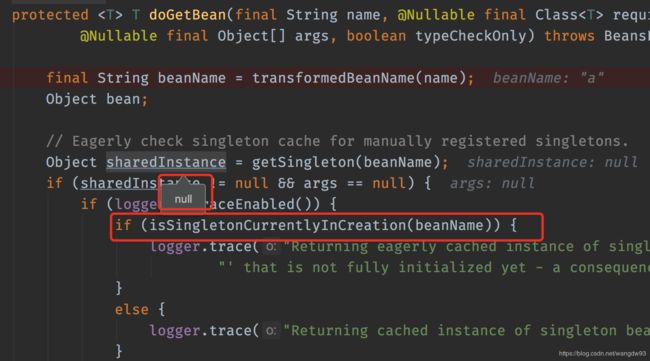
注意此处:在getSingleton()方法中,会将当前需要创建的对象A通过singletonFactories这个对象给创建并加入到earlySingletonObjects这个Map中代码如下:
@Nullable
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
//1、先从容器单例池获取
Object singletonObject = this.singletonObjects.get(beanName);
//isSingletonCurrentlyInCreation(beanName)判断是否是已经在创建
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
synchronized (this.singletonObjects) {
//2、从earlySingletonObjects中获取
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null && allowEarlyReference) {
//3、通过singletonFactories创建
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
singletonObject = singletonFactory.getObject();
//4、放入earlySingletonObjects中
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
}
}
}
}
return singletonObject;
}
接下来再判断**isSingletonCurrentlyInCreation(beanName)**是否正在创建(其实是从一个Map中去获取,第一次进来肯定也是没有的,所有第一次创建的时候是返回为false)
之后此时会给当前要创建的bean加一个标记,标识已经创建了
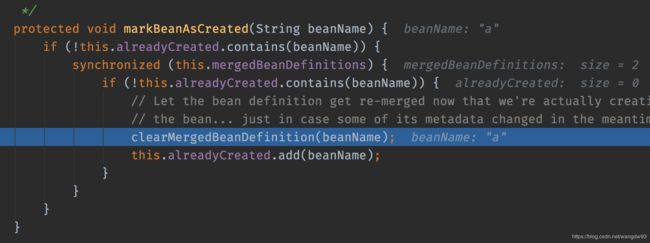
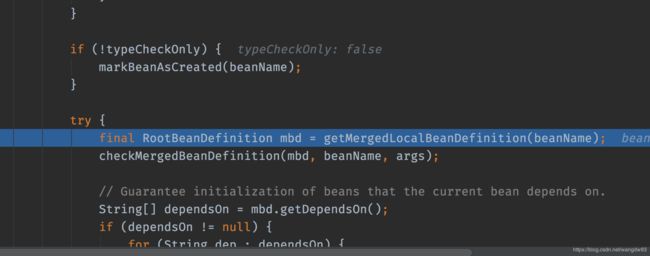
--4 接着,会判断是否DepensOn()这些是否有别的强依赖。如果有,则会先去创建依赖的对象,流程也是和上面一样。如果没有那么就会调用getSingleton方法:
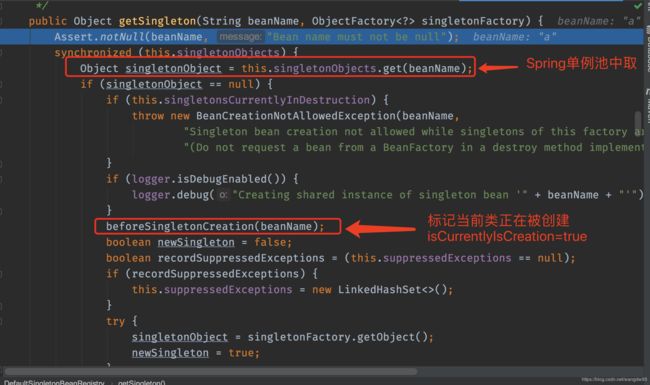
((上图写错了)修改isCurrentlyInCreation=true其实是往singletonsCurrentlyInCreation这个Map中添加了这个类:)
protected void beforeSingletonCreation(String beanName) {
if (!this.inCreationCheckExclusions.contains(beanName) && !this.singletonsCurrentlyInCreation.add(beanName)) {
throw new BeanCurrentlyInCreationException(beanName);
}
}
r然后调用createBean()(用了lamed表达式)
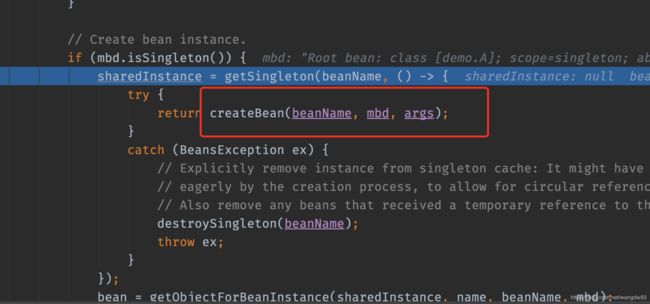
--5 在createBean调用中进行一系列判断,会调用doCreateBean()方法。
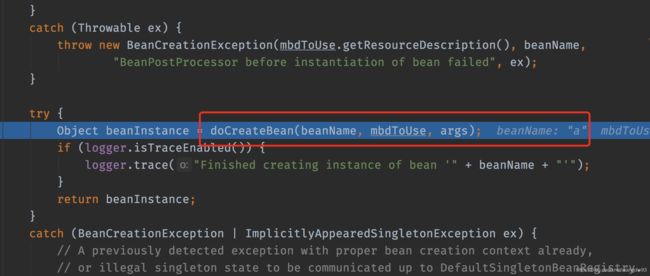
--6 在doCreateBean中会去创建对象。createBeanInstance()此时其实只是创建了对象,并没有进行set属性的注入
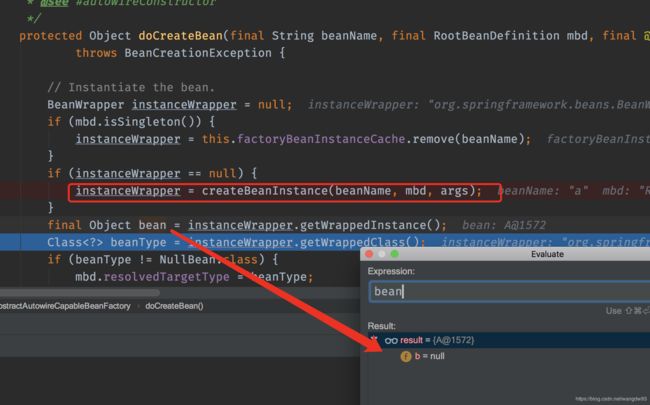
--7 当创建完对象后,Spring又进行了一个判断
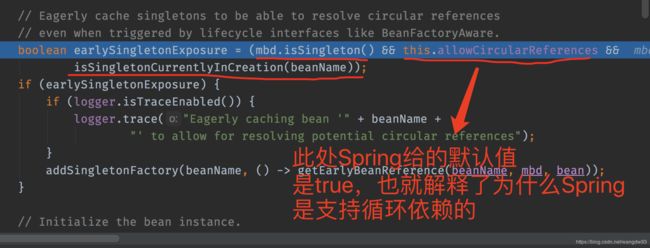
this.allowCircularReferences 是默认为true
此处也解决了,如何关闭Spring的循环依赖问题,在创建对象之前,将Spring的allowCircularReferences值设置为false,然后再从头开始调用refresh()方法
·而**isSingletonCurrentlyInCreation()**方法是对之前的Map(singletonsCurrentlyInCreation)进行的判断是否进行了已经在创建的判断:
public boolean isSingletonCurrentlyInCreation(String beanName) {
return this.singletonsCurrentlyInCreation.contains(beanName);
}
判断完成返回结果为true就执行了**addSingletonFactory()**这个方法
protected void addSingletonFactory(String beanName, ObjectFactory<?> singletonFactory) {
Assert.notNull(singletonFactory, "Singleton factory must not be null");
synchronized (this.singletonObjects) {
//1、判断Spring的单例容器是否有
if (!this.singletonObjects.containsKey(beanName)) {
//也就是把A的创建工厂放入
this.singletonFactories.put(beanName, singletonFactory);
//将A对象从三级缓存中移除
this.earlySingletonObjects.remove(beanName);
this.registeredSingletons.add(beanName);
}
}
}
--8 方法执行完之后,就相当于spring的三级缓存中存在了A这个当前创建的对象,但是此时A对象的B的这个属性还没有赋值,依然为null;接着就走:

populateBean()这个方法,这个方法就是给类的属性赋值,也就是说就在这里面会创建B对象,相当于重新走B这个类的上述的doCreateBean方法。

当然也会走addSingletonFactory中的三级缓存中

当B对象完成创建之中,此时B对象当需要走populateBean()这个方法是,就会从三级缓存中找到A对象有已经创建了,就会给B对象的A属性赋值上。
此时当B执行完,回到A的属性赋值中,此时,B也被放到了三级缓存中,那么A也可以相同方式完成B属性的赋值。
这也是Spring完成循环依赖的实现过程。
简单来说:
第一次创建A对象的时候,它会从Spring容器中先去查找,如果没找到,就从三级缓存中去寻找,此时没有,就会放进去。此时再给A对象赋值的时候就会创建B对象,这时,就会创建B对象,然后同理就会把B放到三级缓存,而B对象赋值的时候,可以从三级缓存中寻找到A对象,就可以完成赋值,当B执行完;A此时也能从三级缓存中找到B那么也就可以完成A的属性赋值了。
而Spring初始化对象的过程也可以总结一下就是:
1.加载xml文件和注解扫描
2.解析xml文件和注解
3.调用扩展(自己写的Spring后置处理器 beanFactoryPostProcessor)实现自定义
4.放入Spring单例池,完成对象创建。
完整的过程如下流程
- 实例化Spring容器-------创建存储的空间,可以简单理解为创建那些Map
- 扫描类
- 解析类
- 实例化BeanDefinition,也就是把类信息拆分放入这个类(每个类都会有一个这个对象)
- 然后将实例化的对象放入:BeanDefinitionMap.put(BeanDefinition)
- 调用beanFactory的后置处理器
- 验证相关属性(单例,懒加载之类)
- 反射创建对象:doCreateBean()—createBeanInstance()
- 合并相关信息属性
- 暴露创建对象的工厂也就是singletonFactories
- 完成属性注入(没有就创建)
- 调用一些Spring的后置处理器完成bean的相关生命周期的回调方法
- 完成代理AOP-----不清楚
- 放入Spring的单例池