大数据-一站式内容画像数据处理(pyodps+odps)
文章目录
- 背景
- 数据流
- 原理
- 实战演示
- 数据集成
- 数据开发(odps sql)
- 数据开发(pyodps)
- pyodps实战演示
- 在dataworks中使用
- 在本机使用
- 在dsw的hello world
- 在dsw中进行埋点分析(时间序列分析)
- 工程选择
- 工程中存在以下问题
- 工程选择
- 评价
背景
公司的pro环境并没有搭建自己存储环境,而是直接使用阿里云的rds,那么数仓的建设也就直接使用了阿里云的dataworks(也就是原odps,也有maxcompute)。
数据存储的限制,需要使用pyodps的sdk才能进行更好的管理、分析、处理(机器学习、深度学习模型训练等)。
本wiki将阐述使用pyodps的优势。
数据流

概念解析:
- 内容源
- 爬虫系统,scrapy实现,爬取文章、音视频、标签、评论舆情信息、商品信息等
- 大v后台,大v发布文章等
- 运营后台,运行标签系统
- 用户行为埋点,收集用户操作app的行为日志,通过sls进行日志收集,在数仓进行处理,生成埋点数据表
- 数据集成,也可以被简单的理解为数据同步,阿里云使用datax实现
- 数仓,也就是odps(阿里云参考hive实现)
- 数据处理
- 分词,jieba分词
- word2vec,文本向量化,也可以称之为词嵌入(embedding)
- 主题聚类,lda、kmeans等聚类
- 特征抽取,知识图谱、关键词提取等
- tfidf、textrank,一些非监督的文本向量化手段
- 模式分类,即给定一定的样本后,训练相应的分类模型,进行训练和预测
- rds,阿里云的数据库;nosql,包括redis、hbase、MongoDB、elasticsearch等
- 脚本同步,python、go、java实现的一些简单的同步脚本
- 数据应用,数据被整合和处理完毕之后,可以提供给不同的业务系统进行使用
- 推荐系统,包括内容信息流、电商推荐、广告推荐
- 其他业务
- 数据挖掘,优质文章挖掘、人群关注的关键词挖掘、舆情挖掘等
可以看到,数据最终是通过数仓进行数据集成的,那么数据并不在本地,需要通过pyodps的sdk进行操作。
原理
以下为简易说明图
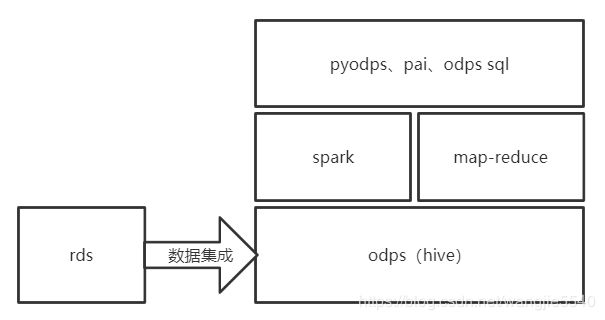
阿里云的odps,和hadoop的hive如出一辙,生成的hive表可以直接使用hive sql进行操作,最终的原理就是map reduce的过程,把生成的一个个任务分发到了不同的集群机器上执行(具体原理可以研习一下hadoop的map reduce)。
odps的map reduce应该是完全类似于hive的,spark是另外一种map reduce的框架,只不过是把硬盘上的操作挪移到了内容,加快了运算速度。
pyodps、pai、odps sql等都是对map reduce和spark进行了一次封装,其中sql适合于表关联的查询统计等,而pyodps则掺杂了python操作,把表转换成了类似于pandas中的DataFrame,可以完成复杂的编程类操作。机器学习pai,也可以在pyodps中进行调用,从何进行机器学习的相关功能。
实战演示
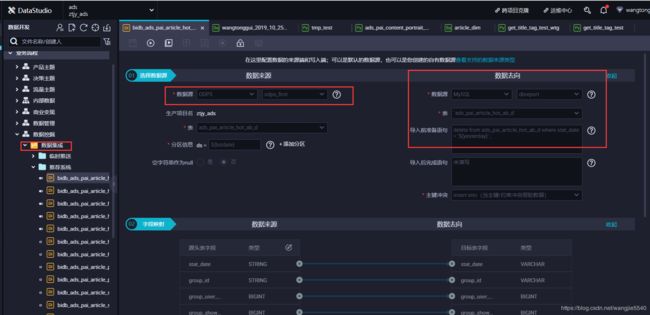
数据集成
又名抽数。直接在dataworks中进行配置即可,这里不加以赘述。
数据开发(odps sql)

也可以认为是hive sql(即hql),和普通的sql区别并不大,其中多了表分区的概念,同时也减少了一些概念(比如说索引等)。这时候产生了一个问题:“这个和mysql没啥区别呀”。
然而并非如此,业务系统使用的是操作型数据库,例如mysql;而odps(hive)数据分析型数据库,只做数据分析(最好是t+1的数据)。
数据开发(pyodps)
类似的开源产品有pyhive(但是据说有坑)。使用sql进行联表的统计无疑是最佳选择,但如果需要对数据进行jieba分词呢?或者需要对已有数据进行lda主题模型分析、相似度分析、设置是做更多的复杂逻辑,使用sql来操作就显得捉襟见肘了。
而python则不同,可以直接使用jieba模块进行分词,sklearn中同时也存在丰富的机器学习、nlp、数据处理的方法,另外还可以进行直接使用tensorflow进行深度学习,一切都显得那么美好。
pyodps实战演示
参考文档:
https://pyodps.readthedocs.io/zh_CN/latest/
https://help.aliyun.com/document_detail/121718.html?spm=a2c4g.11186623.6.783.5eeb153a3mGCDM
https://help.aliyun.com/document_detail/137514.html?spm=5176.10695662.1996646101.searchclickresult.52c4438fy1aKdO
在dataworks中使用
直接在对应的目录,右键就可以直接创建pyodps脚本,下面简单进行一下hello world
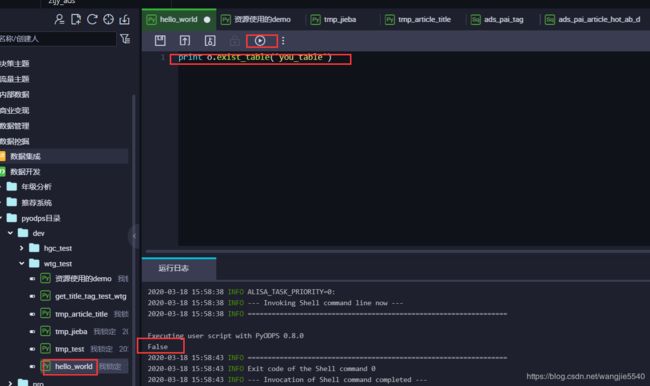
下面我们来实现一个jieba分词的脚本
from odps import ODPS, options
from odps.df import DataFrame
from odps.df import output
import pandas as pd
import datetime
# 设置了这个标志,在print的时候就直接打印结果
options.interactive = True
# 导入jieba的包
options.df.libraries = ['jieba-master.zip']
# 实现jieba分词函数
@output(['content_id', 'content_type', 'title', 'title_seg'], ['string', 'int', 'string', 'string'])
def seg(resources):
stop_words = set([r[0] for r in resources[0]])
def func(row):
import jieba
import sys
import re
pattern = u"^[a-zA-Z0-9\u4e00-\u9fa5]{0,}$"
reload(sys)
sys.setdefaultencoding('utf-8')
word_list = jieba.lcut(row.title)
word_list = [word.encode('utf-8') for word in word_list if word.encode('utf-8') not in stop_words and re.match(pattern=pattern, string=word)]
return row.article_id, 1, row.title, ' '.join(word_list)
return func
# 获取停用词(博主的资源下载里面有停用词的txt文件)
def get_stop_words():
resource = o.get_resource('stop_words.txt')
stop_words = list()
with resource.open('r') as fp:
lines = fp.readlines()
for line in lines:
stop_words.append(line.strip().encode('utf-8'))
stop_words = DataFrame(pd.DataFrame({'stop_words': stop_words}))
return stop_words
# 计算当天时间
today = datetime.date.today()
oneday = datetime.timedelta(days=1)
yesterday = today - oneday
# 获取源数据表
t = o.get_table('ztjy_dim.dim_flow_article_a').get_partition('ds={}'.format(str(yesterday)))
# 转成df,这里也可以直接调用to_df
article_df = DataFrame(t)
df = article_df[['article_id','title','is_online','is_delete']]
# 过滤上线的和未删除的
df = df.filter(df.is_online == 1, df.is_delete == 0)
# 分发给集群执行
df = df.apply(seg, axis=1, resources=[get_stop_words()])
# print df.execute()
# 对表进行持久化
df = df.persist('ads_pai_content_portrait_title_seg_d', partition='ds={}'.format(str(yesterday)) , drop_partition=True, create_partition=True)
在本机使用
通过使用阿里云的ak sk,在本机也可以进行相关调试。其他的都类似,只不过在创建odps实例的时候,需要添加手动添加ak sk。
from odps import ODPS
o = ODPS('**your-access-id**', '**your-secret-access-key**', '**your-default-project**',
endpoint='**your-end-point**')
本机操作有一点是非常不方便的,数据进行调试的时候,要进行长时间的下载。数据本身是在阿里云上,而数据在展示的时候,必然需要进行大量的数据下载,导致调试极为不便,一个网络不好,就会断了。。
在dsw的hello world
通过机器学习pai的dsw notebook环境进行pyodps开发。此环境说白了就是一台阿里云的ecs机器,但是有良好的封装(anaconda)和可视化。
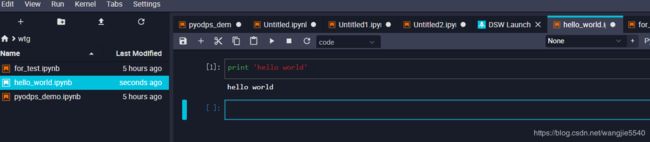
是不是感觉亲切很多,这其实就是python的jupyter notebook。
来查看一下之前的分词表

还可以进行数据分析
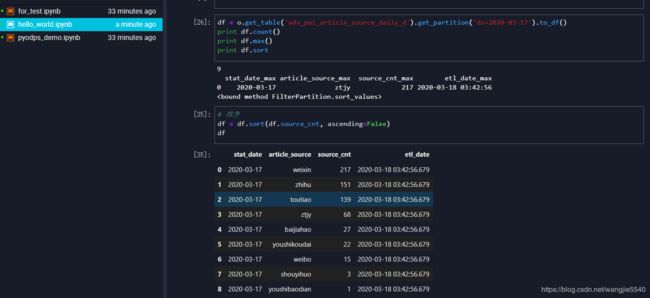
数据可视化
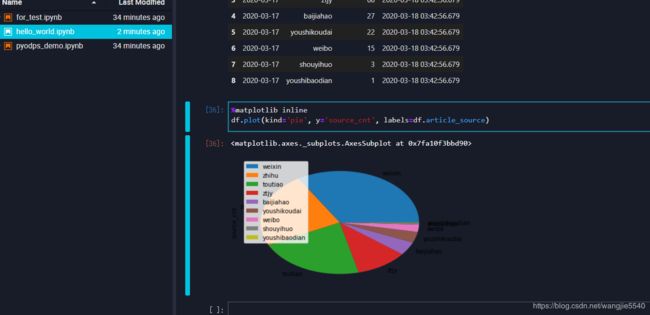
可见在dsw上进行开发,方便快捷的多,开发完毕之后,可以直接把代码上上到dataworks上进行调度;也可以把代码上到自己的ecs,通过xxljob进行调度。
在dsw中进行埋点分析(时间序列分析)
加载表,然后看一下埋点上报类型的分布
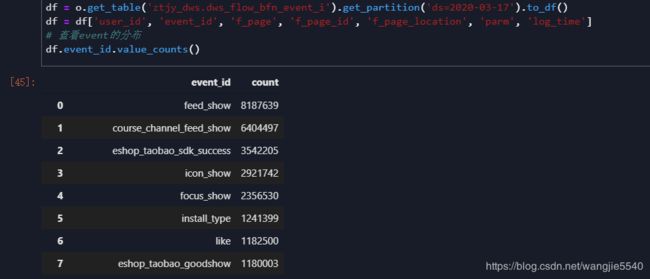
使用barh图查看一下比例

过滤feed_show(需要的事件类型)

使用data_range进行时间序列分割,然后进行value_count,查看每个时间段的数量。通过时间段的数据,可以反映出,用户在发现信息流中的行为时间段

工程选择
工程中存在以下问题
- dsw用于做pyodps开发,进行DataFrame的运算是没问题的,但如果进行本地运算,本地资源就会成为瓶颈
- 模型的运算大多需要在本地实现(特别是sklearn提供的模型),例如tfidf、lda等,只有在进行预测的时候,才需要在odps的资源组中进行(也就是在map reduce的集群中)
- pyodps在dataworks中的调度,不能在本地运算模型,同样存在资源限制的问题
工程选择
- 最好是阿里云ecs,作为pyodps的载体
- 在ecs上安装jupyterhub,方便开发人员合作开发
- 通过xxl调度的方式,每天生成模型文件,并且进行模型文件上传
评价
- 在dsw中,同时也可以创建pytoch、tensorflow的开发环境,所以odps+深度学习的模式是完全可以搞
- 另外,大的训练集可以直接放到oss上,在进行训练的时候也可以方便使用
- 数据完全集中在odps,不用再去访问业务库,数据的安全性得到了保障,初步达到了一站式的开发