结合网上和个人总结,仅供参考。
1、HTML&CSS:
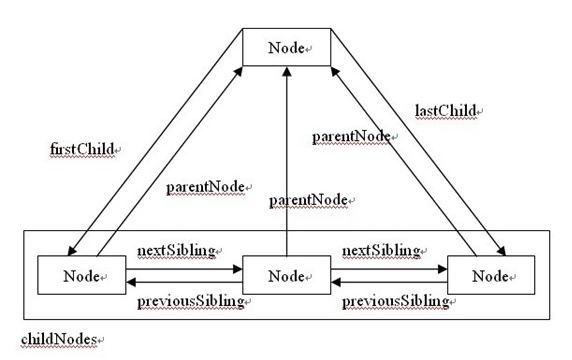
1、DOM结构 —— 两个节点之间可能存在哪些关系以及如何在节点之间任意移动。(通俗易懂的来讲讲DOM、两个节点之间可能存在哪些关系以及如何在节点之间任意移动)
DOM: Document Object Module, 文档对象模型。
节点的关系:父(parent)、子(child)和同胞(sibling)等节点关系;
- 在节点树中,顶端节点被称为根(root)
- 每个节点都有父节点、除了根(它没有父节点)
- 一个节点可拥有任意数量的子
- 同胞是拥有相同父节点的节点
2、DOM操作 —— 如何添加、移除、移动、复制、创建和查找节点等。
查找DOM:document.getElementById()和document.getElementsByTagName(),以及CSS选择器document.getElementsByClassName();querySelector()和querySelectorAll()【低版本的IE<8不支持,8有限支持】。
document.getElementById()可以直接定位唯一的一个DOM节点。document.getElementsByTagName()和document.getElementsByClassName()总是返回一组DOM节点。
创建DOM:document.createElement(newElement);
更新DOM:innerHTML和innerText、textContent;
插入DOM:innerHTML 和 parentNode.appendChild(childNode),parentElement.insertBefore(newElement, referenceElement);
删除DOM:parent.removeChild(childElement);
3、事件 —— 如何使用事件,以及IE和标准DOM事件模型之间存在的差别。
(1)冒泡型事件:事件按照从最特定的事件目标到最不特定的事件目标(document对象)的顺序触发。
IE 5.5: div -> body -> document
IE 6.0: div -> body -> html -> document
Mozilla 1.0: div -> body -> html -> document -> window
(2)捕获型事件(event capturing):事件从最不精确的对象(document 对象)开始触发,然后到最精确(也可以在窗口级别捕获事件,不过必须由开发人员特别指定)。
(3)DOM事件流:同时支持两种事件模型:捕获型事件和冒泡型事件,但是,捕获型事件先发生。两种事件流会触及DOM中的所有对象,从document对象开始,也在document对象结束。
DOM事件模型最独特的性质是,文本节点也触发事件(在IE中不会)。
4、XMLHttpRequest —— 这是什么、怎样完整地执行一次GET请求、怎样检测错误。(老版本IE ajax核心对象为ActiveXObject)
XMLHttpRequest 对象提供了在网页加载后与服务器进行通信的方法。
获取ajax核心对象:
var request = false;
try {
request = new XMLHttpRequest();
} catch (trymicrosoft) {
try {
request = new ActiveXObject("Msxml2.XMLHTTP");
} catch (othermicrosoft) {
try {
request = new ActiveXObject("Microsoft.XMLHTTP");
} catch (failed) {
request = false;
}}}
5、严格模式与混杂模式 —— 如何触发这两种模式,区分它们有何意义。
DOCTYPE(是Document Type文档类型的简写)是一组机器可读的规则,它们指示(X)HTML文档中允许有什么,不允许有什么,DOCTYPE正是用来告诉浏览器使用哪种DTD,三种 DTD 类型分别是严格版本、过渡版本以及基于框架的 HTML 文档。声明位于文档中的最前面的位置,处于标签之前。如果DOCTYPE声明不是页面上的第一个元素,那么IE 6会自动切换到混杂模式。
严格模式是浏览器根据web标准去解析页面,是一种要求严格的DTD,不允许使用任何表现层的语法,如
。混杂模式则是一种向后兼容的解析方法,就是可以实现IE5.5以下版本浏览器的渲染模式。总结:
(1)、 声明位于文档中的最前面,处于标签之前。告知浏览器的解析器,用什么文档类型规范来解析这个文档。
(2)、严格模式的排版和 JS 运作模式是 以该浏览器支持的最高标准运行。
(3)、在混杂模式中,页面以宽松的向后兼容的方式显示。模拟老式浏览器的行为以防止站点无法工作。
(4)、DOCTYPE不存在或格式不正确会导致文档以混杂模式呈现。
6、盒模型 —— 外边距、内边距和边框之间的关系,及IE8以下版本的浏览器中的盒模型
CSS 盒子模型(Box Model)
所有HTML元素可以看作盒子,在CSS中,"box model"这一术语是用来设计和布局时使用。
CSS盒模型本质上是一个盒子,封装周围的HTML元素,它包括:边距,边框,填充,和实际内容。
盒模型允许我们在其它元素和周围元素边框之间的空间放置元素。
属性:box-sizing;
属性值1: box-sizing: content-box;(默认值) 标准盒子模型 ,元素实际宽度等于width加上元素的内边距padding和边框宽度border-width,元素内容宽度 = width;(IE8以下浏览器的盒模型中定义的元素的宽高不包括内边距和边框)
属性值2: box-sizing:border-box; 元素宽度width包含了元素的内边距padding和边框宽度border-width,元素内容宽度 = width - padding - border;
7、块级元素与行内元素 —— 怎么用CSS控制它们、以及如何合理的使用它们(参考链接)
(1)CSS规范规定,每个元素都有display属性,比如div默认display属性值为“block”,成为“块级”元素,总是独占一行,表现为另起一行开始,而且其后的元素也必须另起一行显示;span默认display属性值为“inline”,是“行内”元素,可以和相邻的内联元素在同一行。
(2)行内元素有:a b span img input select strong···
(3)块级元素有:div ul ol li dl dt dd h1 h2 h3 h4…p
(4)知名的空元素:
![]()
// 鲜为人知的是:
8、浮动元素 —— 怎么使用它们、它们有什么问题以及怎么解决这些问题。(参考链接)
属性:float;
属性值:left:往左浮动;right:往右浮动;
浮动元素引起的问题:
1.父元素的高度无法被撑开,影响与父元素同级的元素;
2.与浮动元素同级的非浮动元素会跟随其后;
3.若非第一个元素浮动,则该元素之前的元素也需要浮动,否则会影响页面显示的结构;
解决方法:
清浮动,使用CSS中的clear:both;属性来清除同级子元素的浮动问题
给父元素添加clearfix样式,解决父元素高度无法撑开问题:
.clearfix:after {content: ""; display: block; clear: both;}
9、HTML与XHTML —— 二者有什么区别,你觉得应该使用哪一个并说出理由。
主要区别:HTML是一种基本的WEB网页设计语言,XHTML是一个基于XML的置标语言;
XHTML元素必须被正确地嵌套;
XHTML元素必须被关闭;
标签名必须用小写字母;
XHTML文档必须拥有根元素。
10、JSON —— 作用、用途、设计结构。
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式。易于人阅读和编写。同时也易于机器解析和生成。
JSON建构于两种结构:“名称/值”对的集合(A collection of name/value pairs)。
不同的语言中,它被理解为对象(object)、纪录(record)、结构(struct)、字典(dictionary)、哈希表(hash table)、有键列表(keyed list)或者关联数组(associative array)、值的有序列表(An ordered list of values)。在大部分语言中,它被理解为数组(array)。
11、link 和@import 的区别。
(1)、link属于XHTML标签,而@import是CSS提供的;
(2)、页面被加载的时,link会同时被加载,而@import引用的CSS会等到页面被加载完再加载;
(3)、import只在IE5以上才能识别,而link是XHTML标签,无兼容问题;
(4)、link方式的样式的权重 高于@import的权重;
12、CSS 选择符有哪些?哪些属性可以继承?优先级算法如何计算? CSS3新增伪类有那些?
* 1.id选择器( # myid)
2.类选择器(.myclassname)
3.标签选择器(div, h1, p)
4.相邻选择器(h1 + p)
5.子选择器(ul < li)
6.后代选择器(li a)
7.通配符选择器( * )
8.属性选择器(a[rel = "external"])
9.伪类选择器(a: hover, li: nth - child)
* 可继承: font-size font-family color, UL LI DL DD DT;
* 不可继承 :border padding margin width height ;
* 优先级就近原则,样式定义最近者为准;
* 载入样式以最后载入的定位为准;
优先级为:
!important > id > class > tag
important 比内联优先级高
CSS3新增伪类举例:
p:first-of-type 选择属于其父元素的首个元素的每个元素。
p:last-of-type 选择属于其父元素的最后元素的每个元素。
p:only-of-type 选择属于其父元素唯一的元素的每个元素。
p:only-child 选择属于其父元素的唯一子元素的每个元素。
p:nth-child(2) 选择属于其父元素的第二个子元素的每个元素。
:enabled、:disabled 控制表单控件的禁用状态。
:checked,单选框或复选框被选中。
13、对浏览器内核的理解?常见的浏览器内核有哪些?
浏览器内核的理解:
主要分成两部分:渲染引擎(layout engineer或Rendering Engine)和JS引擎。
渲染引擎:负责取得网页的内容(HTML、XML、图像等等)、整理讯息(例如加入CSS等),以及计算网页的显示方式,然后会输出至显示器或打印机。浏览器的内核的不同对于网页的语法解释会有不同,所以渲染的效果也不相同。所有网页浏览器、电子邮件客户端以及其它需要编辑、显示网络内容的应用程序都需要内核。
JS引擎则:解析和执行javascript来实现网页的动态效果。
最开始渲染引擎和JS引擎并没有区分的很明确,后来JS引擎越来越独立,内核就倾向于只指渲染引擎。
常见的浏览器内核:
Trident内核:IE,MaxThon,TT,The World,360,搜狗浏览器等。[又称MSHTML]
Gecko内核:Netscape6及以上版本,FF,MozillaSuite/SeaMonkey等
Presto内核:Opera7及以上。 [Opera内核原为:Presto,现为:Blink;]
Webkit内核:Safari,Chrome等。 [ Chrome的:Blink(WebKit的分支)]
16、less、sass、stylus预处理器
17. HTML5:离线存储
参考链接:有趣的HTML5:离线存储
html&&css参考地址:
https://leohxj.gitbooks.io/front-end-database/html-and-css-basic/learn-dom-tree.html
https://www.liaoxuefeng.com/wiki/
2、js基础
0. 面向对象原理;
1)目标:实现封装、继承、多态等面向对象的基本功能。
2)原理:使用prototype、function 、new、this模拟面向对象的类。
JavaScript是面向对象语言,但不使用类(根本不存在类)。JavaScript的面向对象是基于prototype和function的,而不是基于类的。
1. 原型和原型链;(参考链接)
每个对象都有一个私有属性(称之为 [[Prototype]]),它指向它的原型对象(prototype)。该 prototype 对象又具有一个自己的 prototype ,层层向上直到一个对象的原型为 null。根据定义,null 没有原型,并作为这个原型链中的最后一个环节。
当查找一个对象的属性时,JavaScript 会向上遍历原型链,直到找到给定名称的属性为止,到查找到达原型链的顶部 - 也就是 Object.prototype - 但是仍然没有找到指定的属性,就会返回 undefined
2. 闭包;(参考链接)
闭包是代码块和创建该代码块的上下文中数据的结合。
闭包是指有权访问另一个函数作用域中的变量的函数。创建闭包的常见方式,就是在一个函数内部创建另一个函数。(红宝书P178)。
例子1:
[1, 2, 3].sort(function(a, b) {
...// 排序条件
});
[1, 2, 3].map(function (element) {
return element * 2;
}); // [2, 4, 6]
例子2-延迟调用:
var a = 10;
setTimeout(function () {
alert(a); // 10, after one second
}, 1000);
例子3-回调函数:
var x = 10;
xmlHttpRequestObject.onreadystatechange =function() {
// 当数据就绪的时候,才会调用;
// 这里,不论是在哪个上下文中创建
// 此时变量“x”的值已经存在了
alert(x);// 10
};
例子4-隐藏辅助对象:
varfoo = {};
// 初始化
(function(object) {
var x = 10;
object.getX =function_getX() {
return x;
};
})(foo);
alert(foo.getX());// 获得闭包 "x" – 10
3. 类和继承(es5实现方法 + es6实现方法);
继承机制
ES6创建类的基本语法和继承实现原理
ES5和ES6中对于继承的实现方法
4. let、const、var;(参考链接)
5. Promise的使用及原理;(参考链接)
6. 异步处理方法;(参考链接)
1)回调函数:
function fn1 () {
console.log('Function 1')
}
function fn2 (f) {
setTimeout(() => {
console.log('Function 2')
f()
}, 500)
}
function fn3 () {
console.log('Function 3')
}
fn1();
fn2(fn3) ; //可依次执行fn1,fn2,fn3
2)发布/订阅模式;
class AsyncFunArr {
constructor (...arr) {
this.funcArr = [...arr]
}
next () {
const fn = this.funcArr.shift()
if (typeof fn === 'function') fn()
}
run () {
this.next()
}
}
function fn1 () {
console.log('Function 1')
asyncFunArr.next()
}
function fn2 () {
setTimeout(() => {
console.log('Function 2')
asyncFunArr.next()
}, 500)
}
function fn3 () {
console.log('Function 3')
asyncFunArr.next()
}
3)Promise:
function fn1 () {
console.log('Function 1')
}
function fn2 () {
return new Promise((resolve, reject) => {
setTimeout(() => {
console.log('Function 2')
resolve()
}, 500) })
}
function fn3 () {
console.log('Function 3')
}
fn1();
fn2().then(() => { fn3() });
4)generator:(参考链接)
7. 遍历所有文档树所有节点(考察递归)的方法;
(参考链接:https://blog.csdn.net/jjaze3344/article/details/7280321
https://blog.csdn.net/sinat_27346451/article/details/77073938)
8. sort排序相关(注意ASCII这个坑)(参考链接)
默认情况下,sort函数是按照ASCII字符排序。在ASCII字符排序中,是对应位相比较。18和5相比,实际上就是1和5相比,因为5只有一位数,所以只比较第一位。因为1<5,所以就会出现错误的答案。
错误如:
var a = [5,41,7,18]
a.sort();
alert(a); //18,41,5,7
解决方案:
如果省略参数,将默认为ASCII字符排序,简而言之,就是有了参数,就不是默认为ASCII字符排序了。
即:
var a=[5,41,7,18];
a.sort(function (m, n){
return m-n;
});
alert(a); //5,7,18,41
9. 数组和对象的深浅拷贝;(参考链接)
10. String + Array的一些基本操作;(参考链接)
11. 数组去重的方法;(参考链接)
推荐的两种方法:
1、先将原数组进行排序,使重复元素在相邻位置,创建新数组,并赋值元数组的第一项,检查原数组中的第i个元素与新数组中的最后一个元素是否相同,如果不相同,则将该元素存入新数组中
function unique(arr){
arr.sort(); //先排序 ,这里不需要参数
var res = [arr[0]];
for (var i = 1; i < arr.length; i++) {
if (arr[i] !== res[res.length - 1]) {
res.push(this[i]);
}
}
return res;
}
2、创建一个空对象和一个空数组,将数组的数值以对象属性的形式保存,并赋值1,push到新数组中,后续遍历数组时通过数组的值以属性的方式访问对象,从而达到验证重复的目的。(较推荐)
function unique(arr) {
var res = [];
var hash = {};
for (var i = 0; i < arr.length; i++) {
if (!hash[arr[i]]) {
res.push(arr[i]);
hash[arr[i]] = 1;
}
}
return res;
}
12. 冒泡和捕获;(参考链接)
13. 事件代理;(参考链接)
14. cookies,sessionStorage 和 localStorage 的区别?(参考链接)
cookie是网站为了标示用户身份而储存在用户本地终端(Client Side)上的数据(通常经过加密)。cookie数据始终在同源的http请求中携带(即使不需要),即会在浏览器和服务器间来回传递。
sessionStorage和localStorage仅在客户端(即浏览器)中保存,不参与和服务器的通信;sessionStorage保存在当前会话窗口;localStorage保存在本浏览器数据缓存区。
共同点:都是保存在浏览器端、仅同源可用的存储方式。
存储大小:cookie数据大小不能超过4k;sessionStorage和localStorage 虽然也有存储大小的限制,但比cookie大得多,可以达到5M或更大。
存储格式:cookie只能以字符串格式保存;webStorage以key-value格式保存,更便于存取(sessionStorage.setItem("key","value"),sessionStorage.getItem("key"));
保存时间:localStorage 存储持久数据,浏览器关闭后数据不丢失除非主动删除数据;sessionStorage 数据在当前浏览器窗口关闭后自动删除;cookie 设置的cookie过期时间之前一直有效,即使窗口或浏览器关闭。
Cookie的作用是与服务器进行交互,作为HTTP规范的一部分而存在 ,而Web Storage仅仅是为了在本地“存储”数据而生。
15. jsonp和跨域,为什么浏览器会禁止跨域(参考链接: 跨 域、 jsonp)
16. 变量提升;(参考链接)
17. 高阶函数;(参考链接)
18. 动画;(参考链接)
19. setTimeout、setInterval和requestAnimationFrame;(参考链接)(requestAnimationFrame参考链接)
基本用法与区别
setTimeout(code, millseconds) 用于延时执行参数指定的代码,如果在指定的延迟时间之前,你想取消这个执行,那么直接用clearTimeout(timeoutId)来清除任务,timeoutID 是 setTimeout 时返回的;
setInterval(code, millseconds)用于每隔一段时间执行指定的代码,永无停歇,除非你反悔了,想清除它,可以使用 clearInterval(intervalId),这样从调用 clearInterval 开始,就不会在有重复执行的任务,intervalId 是 setInterval 时返回的;
requestAnimationFrame(code),一般用于动画,与 setTimeout 方法类似,区别是 setTimeout 是用户指定的,而 requestAnimationFrame 是浏览器刷新频率决定的,一般遵循 W3C 标准,它在浏览器每次刷新页面之前执行。
20. 模块化开发;
参考链接:模块化入门-知乎
UMD
21. 引起内存泄漏的原因;(参考链接)
1)全局变量引起的内存泄漏
function leaks(){ leak = 'xxxxxx';//leak 成为一个全局变量,不会被回收}
2)闭包引起的内存泄漏
var leaks = (function(){
var leak = 'xxxxxx';// 被闭包所引用,不会被回收
return function(){
console.log(leak);
}
})()
3)dom清空或删除时,事件未清除导致的内存泄漏
$('#container').bind('click', function(){
console.log('click');
}).remove();
// zepto 和原生 js下,#container dom 元素,还在内存里jquery 的 empty和 remove会帮助开发者避免这个问题
$('#container').bind('click', function(){
console.log('click');
}).off('click').remove();
//把事件清除了,即可从内存中移除
4) 被遗忘的计时器或回调函数
var someResource = getData();
setInterval(function() {
var node = document.getElementById('Node');
if(node) { // 处理 node 和 someResource
node.innerHTML = JSON.stringify(someResource));
}}, 1000);
修改:
var element = document.getElementById('button');
function onClick(event) {
element.innerHTML = 'text';
}
element.addEventListener('click', onClick);
22. ajax;
(参考链接: http://www.runoob.com/ajax/ajax-tutorial.html
http://3ms.huawei.com/km/blogs/details/5434911)
23. map、filter、reduce相关;
(参考链接:https://atendesigngroup.com/blog/array-map-filter-and-reduce-js
http://zerosoul.github.io/2016/12/06/array-filter-map-reduce-in-js/)
24. Map和Set;(参考链接)
Map是一组键值对的结构,具有极快的查找速度。
例:var m =new Map([['Michael',95], ['Bob',75], ['Tracy',85]]);
m.get('Michael');// 95
Set和Map类似,也是一组key的集合,但不存储value。由于key不能重复,所以,在Set中,没有重复的key。
要创建一个Set,需要提供一个Array作为输入,或者直接创建一个空Set:
var s1 = new Set(); // 空Set
var s2 = new Set([1, 2, 3]); // 含1, 2, 3
25. this相关(注意箭头函数的this指向问题);(参考链接)
1)ES6中箭头函数的this问题:
ES6 允许使用“箭头”(=>)定义函数,函数体内的this对象,就是定义时所在的对象,而不是使用时所在的对象。this对象的指向是可变的,但是在箭头函数中,它是固定的,箭头函数根本没有自己的this,导致内部的this就是外层代码块的this。所以箭头函数不能做构造函数, 也不能用call()、apply()、bind()这些方法去改变this的指向。
26. call、apply、bind;(参考链接)
27. 移动端开发相关;
(参考链接:https://juejin.im/post/5a77d6086fb9a0634417bfd3
http://www.restran.net/2015/05/14/mobile-web-front-end-collections/)
3、框架和工具相关
vue数据绑定原理;
定义:vue的数据双向绑定是基于Object.defineProperty方法,通过定义data属性的get和set函数来监听数据对象的变化,一旦变化,vue利用发布订阅模式,通知订阅者执行回调函数,更新dom。
参考链接:vue数据绑定原理
vue父子组件和兄弟组件的通信问题;
1)父子组件通信:
1、父组件使用 props 把数据传给子组件。
2、子组件使用 $emit 触发父组件的自定义事件。
2)兄弟组件通信:
创建一个事件中心,相当于中转站,可以用它来传递事件和接收事件。
let Hub = new Vue(); //创建事件中心
组件1触发:
methods: {
eve() { Hub.$emit('change','hehe'); } //Hub触发事件
}
组件2接收:
created() {
Hub.$on('change', () => { //Hub接收事件
this.msg = 'hehe';
});
}
vuex的原理;
参考链接:到底vuex是什么
vuex的action和mutation的异步操作和同步操作问题;
参考链接:vuex2.0 基本使用(2) --- mutation 和 action
vue的事件监听;
参考链接:事件监听
vue-router获取自定义参数;
传值:
this.$router.push(name:"test",params:{data:"test"});
this.$router.push(path:"/test",query:{data:"test"});
取值(与传值一一对应):
$route.params 类型: Object
一个 key/value 对象,包含了动态片段和全匹配片段,如果没有路由参数,就是一个空对象。
this.$route.params.data //"test"
$route.query 类型: Object
一个 key/value 对象,表示 URL 查询参数。例如,对于路径 /foo?user=1,则有 $route.query.user == 1,如果没有查询参数,则是个空对象。
this.$route.query.data //"test"
query和params使用区别
vue-router 路由模式(url中#号的解析);
参考链接:vueRouter - mode API
1)Hash模式:使用 URL hash 值来作路由。支持所有浏览器,包括不支持 HTML5 History Api 的浏览器。(URL中带有#号):
http://localhost:8080/#/
2)History模式:依赖HTML5 History API 和服务器配置。HTML5 History模式,(URL中不带有#号):
export default new Router ({
mode: 'history',
routes: [ {
path: '/',
name: '/',
component: main
} ]
})
3)Abstract模式:支持所有javascript运行模式,如 Node.js 服务器端。如果发现没有浏览器的API,路由会自动强制进入这个模式。
vue-router的go相关;
router.go(n):类似 window.history.go(n),在 history 记录中向前或后退n步(n为int类型)
router.push(location):导航到不同的 URL,则使用 router.push 方法。这个方法会向 history 栈添加一个新的记录,所以,当用户点击浏览器后退按钮时,则回到之前的 URL。
router.replace(location):跟 router.push 很像,唯一的不同就是,它不会向 history 添加新记录,而是跟它的方法名一样 —— 替换掉当前的 history 记录。
vue组件设计相关;
1)用一些功能单一的小模块来组织应用,较小的模块更容易看懂、维护、复用和调试 (每个组件应该保持单一、独立、可复用、可测试);
2)组件命名应该遵从以下几点原则:
有意义: 名字不要太详细,也不要太抽象。
短: 名字最好是2-3个单词。
可读的:容易让人能读出来以便我们可以更容易的讨论它。
vue组件也应该遵循以下原则:
遵从元素命名规范,包括连字符,不要使用保留字
为了在其他项目中复用,应该以某个模块名字作为命名空间。
3)把复杂的语法移动到methods或者计算属性中,避免使用行内表达式;
4)保证组件的props简单,保证接口简单,便于开发理解维护,同时进行props限制,比如检查是否存在,设置默认值,设置类型校验等;
参考链接:vue组件最佳实践
模块化的工具;
参考链接:常用模块化方案
webpack打包优化;
参考链接:webpack打包体积优化
设计一个自己的打包工具需要设计哪些主要功能;
参考链接:前端打包工具
babel相关;
参考链接:Babel 从入门到插件开发
Babel
mvvm的好处;
参考链接:MVVM的优点和缺点
MVVM架构的优缺点
jquery的一些基本用法;
参考链接:jquery的一些基本用法
jQuery的详细解析以及用法
lodash相关;
参考链接:官方文档
vue和react的对比;
参考链接:Vue.js与React的全面对比
vue和jquery的对比;
jQuery是使用选择器($)选取DOM对象,对其进行赋值、取值、事件绑定等操作,其实和原生的HTML的区别只在于可以更方便的选取和操作DOM对象,而数据和界面是在一起的。比如需要获取label标签的内容:$("lable").val();,它还是依赖DOM元素的值。
Vue则是通过Vue对象将数据和View完全分离开来了。对数据进行操作不再需要引用相应的DOM对象,可以说数据和View是分离的,他们通过Vue对象这个vm实现相互的绑定。这就是传说中的MVVM。
vue适用的场景:复杂数据操作的后台页面,表单填写页面;
jquery适用的场景:比如说一些html5的动画页面,一些需要js来操作页面样式的页面;
然而二者也是可以结合起来一起使用的,vue侧重数据绑定,jquery侧重样式操作,动画效果等,则会更加高效率的完成业务需求。
webGL:
参考链接:webGL—MDN