此文已由作者温正湖授权网易云社区发布。
欢迎访问网易云社区,了解更多网易技术产品运营经验。
最近阅读了TiDB源码的说明文档,跟MongoDB的分片集群做了下简单对比。
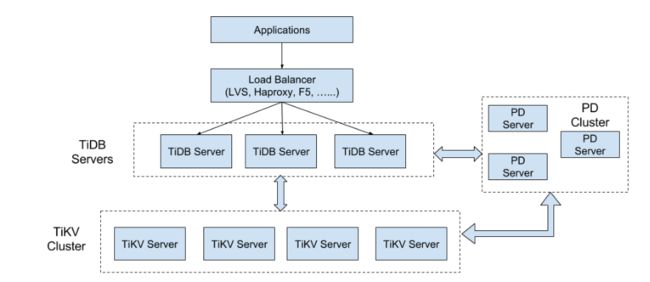
首先展示TiDB的整体架构
MongoDB分片集群架构如下:
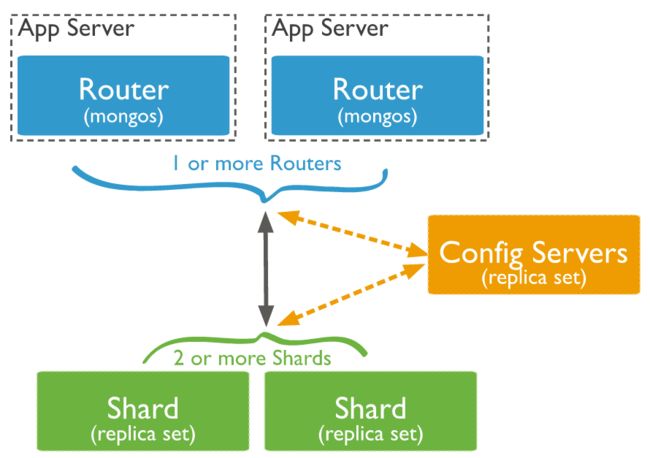
更加具体点如下:
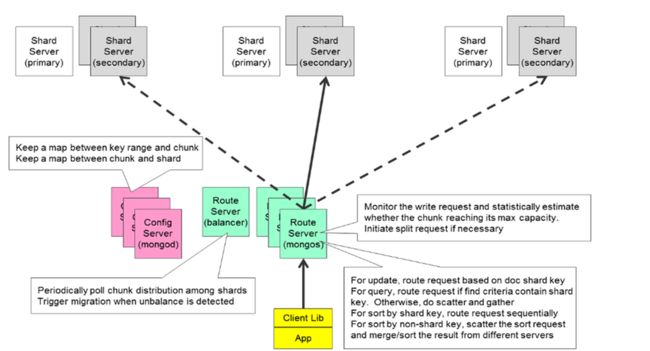
下面从介绍TiDB组件的角度切入,将其跟MongoDB分片集群做对比。
TiDB 集群主要分为三个组件:
TiDB Server
TiDB Server 负责接收 SQL 请求,处理 SQL 相关的逻辑,并通过 PD 找到存储计算所需数据的 TiKV 地址,与 TiKV 交互获取数据,最终返回结果。 TiDB Server 是无状态的,其本身并不存储数据,只负责计算,可以无限水平扩展,可以通过负载均衡组件(如LVS、HAProxy 或 F5)对外提供统一的接入地址。
// 类比MongoDB分片集群中的mongos或者叫router server
PD Server
Placement Driver (简称 PD) 是整个集群的管理模块,其主要工作有三个: 一是存储集群的元信息(某个 Key 存储在哪个 TiKV 节点);二是对 TiKV 集群进行调度和负载均衡(如数据的迁移、Raft group leader 的迁移等);三是分配全局唯一且递增的事务 ID。
PD 是一个集群,需要部署奇数个节点,一般线上推荐至少部署 3 个节点。
//类比MongoDB分片集群中的config server
TiKV Server
TiKV Server 负责存储数据,从外部看 TiKV 是一个分布式的提供事务的 Key-Value 存储引擎。存储数据的基本单位是 Region,每个 Region 负责存储一个 Key Range (从 StartKey 到 EndKey 的左闭右开区间)的数据,每个 TiKV 节点会负责多个 Region 。TiKV 使用 Raft 协议做复制,保持数据的一致性和容灾。副本以 Region 为单位进行管理,不同节点上的多个 Region 构成一个 Raft Group,互为副本。数据在多个 TiKV 之间的负载均衡由 PD 调度,这里也是以 Region 为单位进行调度。
//类比MongoDB分片集群中的replica set
// Region概念类似MongoDB分片中的chunk,但又有些不一样。chunk是个逻辑概念,数据存储并不是以chunk为单位。而Region是正式在TIKV上的数据单位。两种都是数据迁移的最小单位。默认也是64MB
核心特性
水平扩展
无限水平扩展是 TiDB 的一大特点,这里说的水平扩展包括两方面:计算能力和存储能力。TiDB Server 负责处理 SQL 请求,随着业务的增长,可以简单的添加 TiDB Server 节点,提高整体的处理能力,提供更高的吞吐。TiKV 负责存储数据,随着数据量的增长,可以部署更多的 TiKV Server 节点解决数据 Scale 的问题。PD 会在 TiKV 节点之间以 Region 为单位做调度,将部分数据迁移到新加的节点上。所以在业务的早期,可以只部署少量的服务实例(推荐至少部署 3 个 TiKV, 3 个 PD,2 个 TiDB),随着业务量的增长,按照需求添加 TiKV 或者 TiDB 实例。
// TIDB相比MongoDB分片,优势在于其具有更强的业务负载均衡的能力,TIDB是每个region作为一个raft group,会根据raft group leader所在TIKV节点的负载来调整leader节点,从而实现业务负载均衡。
高可用
高可用是 TiDB 的另一大特点,TiDB/TiKV/PD 这三个组件都能容忍部分实例失效,不影响整个集群的可用性。下面分别说明这三个组件的可用性、单个实例失效后的后果以及如何恢复。
-
TiDB
TiDB 是无状态的,推荐至少部署两个实例,前端通过负载均衡组件对外提供服务。当单个实例失效时,会影响正在这个实例上进行的 Session,从应用的角度看,会出现单次请求失败的情况,重新连接后即可继续获得服务。单个实例失效后,可以重启这个实例或者部署一个新的实例。
// MongoDB分片集群通过Driver就可以实现负载均衡,不需要单独部署负载均衡组件。 Driver同时连接多个mongos实现负载均衡。
-
PD
PD 是一个集群,通过 Raft 协议保持数据的一致性,单个实例失效时,如果这个实例不是 Raft 的 leader,那么服务完全不受影响;如果这个实例是 Raft 的 leader,会重新选出新的 Raft leader,自动恢复服务。PD 在选举的过程中无法对外提供服务,这个时间大约是3秒钟。推荐至少部署三个 PD 实例,单个实例失效后,重启这个实例或者添加新的实例。
// 跟config server的高可用一样,但config server心跳超时需要10s,选出主一般需要30s时间。由于mongos缓存了cs上的元数据,所以cs选主期间,业务正常的读写均不受影响。很好奇,选主如何在3s之内搞定。
-
TiKV
TiKV 是一个集群,通过 Raft 协议保持数据的一致性(副本数量可配置,默认保存三副本),并通过 PD 做负载均衡调度。单个节点失效时,会影响这个节点上存储的所有 Region。对于 Region 中的 Leader 结点,会中断服务,等待重新选举;对于 Region 中的 Follower 节点,不会影响服务。当某个 TiKV 节点失效,并且在一段时间内(默认 10 分钟)无法恢复,PD 会将其上的数据迁移到其他的 TiKV 节点上。
// 这是TiDB相比MongoDB分片的不同的地方,PD在某个TiKV节点失效超时后,将其上原有的数据副本迁移到其他存活的TiKV节点实现数据副本完整性。而MongoDB分片集群的数据高可用依赖shard的配置,如果shard是单一的mongod进程,那么该shard故障后,其上的数据都不可用或丢失,如果shard是复制集,则数据是安全的,但副本数会减少,需要人工处理故障节点。所以,分片集群中shard一定要配置为复制集的形式
网易云免费体验馆,0成本体验20+款云产品!
更多网易技术、产品、运营经验分享请点击。
相关文章:
【推荐】 BigData – Join中竟然也有谓词下推!?