这篇文章介绍了如何利用Apache Flink的内置指标系统以及如何使用Prometheus来高效地监控流式应用程序。

为什么选择Prometheus?
随着深入地了解Prometheus,你会发现一些非常好的功能:
- 服务发现使配置更加容易。Prometheus支持consul,etcd,kubernetes以及各家公有云厂商自动发现。对于监控目标动态发现,这点特别契合Cloud时代,应用动态扩缩的特点。我们无法想象,在Cloud时代,需要运维不断更改配置。
- 开源社区建立了数百个exporter。基本上涵盖了所有基础设施和主流中间件。
- 工具库可从您的应用程序获取自定义指标。基本上主流开发语言都有对应的工具库。
- 它是CNCF旗下的OSS,是继Kubernetes之后的第二个毕业项目。Kubernetes已经与Promethues深度结合,并在其所有服务中公开了Prometheus指标。
- Pushgateway,Alermanager等组件,基本上涵盖了一个完整的监控生命周期。
Flink官方已经提供了对接Prometheus的jar包,很方便就可以集成。由于本系列文章重点在Flink on Kubernetes, 因此我们所有的操作都是基于这点展开。
部署Prometheus
对k8s不熟悉的同学,可以查阅k8s相关文档。由于部署不是本博客的重点,所以我们直接贴出yaml文件:
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: monitor
namespace: kube-system
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: monitor
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
rules:
- apiGroups:
- ""
resources:
- pods
verbs:
- get
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: monitor
labels:
kubernetes.io/cluster-service: "true"
addonmanager.kubernetes.io/mode: Reconcile
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: monitor
subjects:
- kind: ServiceAccount
name: monitor
namespace: kube-system
---
apiVersion: v1
kind: ConfigMap
metadata:
labels:
app: monitor
name: monitor
namespace: kube-system
data:
prometheus.yml: |-
global:
scrape_interval: 10s
evaluation_interval: 10s
scrape_configs:
- job_name: kubernetes-pods
kubernetes_sd_configs:
- role: pod
relabel_configs:
- action: keep
regex: true
source_labels:
- __meta_kubernetes_pod_annotation_prometheus_io_scrape
- action: replace
regex: (.+)
source_labels:
- __meta_kubernetes_pod_annotation_prometheus_io_path
target_label: __metrics_path__
- action: replace
regex: ([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2
source_labels:
- __address__
- __meta_kubernetes_pod_annotation_prometheus_io_port
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- action: replace
source_labels:
- __meta_kubernetes_namespace
target_label: kubernetes_namespace
- action: replace
source_labels:
- __meta_kubernetes_pod_name
target_label: kubernetes_pod_name
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
labels:
app: monitor
name: monitor
namespace: kube-system
spec:
serviceName: monitor
selector:
matchLabels:
app: monitor
replicas: 1
template:
metadata:
labels:
app: monitor
spec:
containers:
- args:
- --config.file=/etc/prometheus/prometheus.yml
- --storage.tsdb.path=/data/prometheus
- --storage.tsdb.retention.time=10d
image: prom/prometheus:v2.19.0
imagePullPolicy: IfNotPresent
name: prometheus
ports:
- containerPort: 9090
protocol: TCP
readinessProbe:
httpGet:
path: /-/ready
port: 9090
initialDelaySeconds: 30
timeoutSeconds: 30
livenessProbe:
httpGet:
path: /-/healthy
port: 9090
initialDelaySeconds: 30
timeoutSeconds: 30
resources:
limits:
cpu: 1000m
memory: 2018Mi
requests:
cpu: 1000m
memory: 2018Mi
volumeMounts:
- mountPath: /etc/prometheus
name: config-volume
- mountPath: /data
name: monitor-persistent-storage
restartPolicy: Always
priorityClassName: system-cluster-critical
serviceAccountName: monitor
initContainers:
- name: "init-chown-data"
image: "busybox:latest"
imagePullPolicy: "IfNotPresent"
command: ["chown", "-R", "65534:65534", "/data"]
volumeMounts:
- name: monitor-persistent-storage
mountPath: /data
subPath: ""
volumes:
- configMap:
defaultMode: 420
name: monitor
name: config-volume
volumeClaimTemplates:
- metadata:
name: monitor-persistent-storage
namespace: kube-system
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 20Gi
storageClassName: gp2
---
apiVersion: v1
kind: Service
metadata:
annotations:
service.beta.kubernetes.io/aws-load-balancer-type: nlb
labels:
app: monitor
name: monitor
namespace: kube-system
spec:
ports:
- name: http
port: 9090
protocol: TCP
targetPort: 9090
selector:
app: monitor
type: LoadBalancer这里我们简单说下,由于我们想利用Prometheus的Kubernetes的服务发现的方式,所以需要RBAC授权,授权prometheus 实例对集群中的pod有一些读取权限。
为什么我们要使用自动发现的方式那?
相比配置文件的方式,自动发现更加灵活。尤其是当你使用的是flink on native kubernetes,整个job manager 和task manager 是根据作业的提交自动创建的,这种动态性,显然是配置文件无法满足的。
由于我们的集群在eks上,所以大家在使用其他云的时候,需要略做调整。
定制镜像
这里我们基本上使用上一篇文章介绍的demo上,增加监控相关,所以Dockerfile如下:
FROM flink
COPY /plugins/metrics-prometheus/flink-metrics-prometheus-1.11.0.jar /opt/flink/lib
RUN mkdir -p $FLINK_HOME/usrlib
COPY ./examples/streaming/WordCount.jar $FLINK_HOME/usrlib/my-flink-job.jarFlink 的 Classpath 位于/opt/flink/lib,所以插件的jar包需要放到该目录下
作业提交
由于我们的Pod必须增加一定的标识,从而让Prometheus实例可以发现。所以提交命令稍作更改,如下:
./bin/flink run-application -p 8 -t kubernetes-application \
-Dkubernetes.cluster-id=my-first-cluster \
-Dtaskmanager.memory.process.size=2048m \
-Dkubernetes.taskmanager.cpu=2 \
-Dtaskmanager.numberOfTaskSlots=4 \
-Dkubernetes.container.image=iyacontrol/flink-world-count:v0.0.2 \
-Dkubernetes.container.image.pull-policy=Always \
-Dkubernetes.namespace=stream \
-Dkubernetes.jobmanager.service-account=flink \
-Dkubernetes.rest-service.exposed.type=LoadBalancer \
-Dkubernetes.rest-service.annotations=service.beta.kubernetes.io/aws-load-balancer-type:nlb,service.beta.kubernetes.io/aws-load-balancer-internal:true \
-Dkubernetes.jobmanager.annotations=prometheus.io/scrape:true,prometheus.io/port:9249 \
-Dkubernetes.taskmanager.annotations=prometheus.io/scrape:true,prometheus.io/port:9249 \
-Dmetrics.reporters=prom \
-Dmetrics.reporter.prom.class=org.apache.flink.metrics.prometheus.PrometheusReporter \
local:///opt/flink/usrlib/my-flink-job.jar- 给 jobmanager 和 taskmanager 增加了annotations
- 增加了metrcis相关的配置,指定使用prometheus reporter
关于prometheus reporter:
参数:
-
port- 可选, Prometheus导出器监听的端口,默认为9249。为了能够在一台主机上运行报告程序的多个实例(例如,当一个TaskManager与JobManager并置时),建议使用这样的端口范围 9250-9260。 -
filterLabelValueCharacters- 可选, 指定是否过滤标签值字符。如果启用,则将删除所有不匹配[a-zA-Z0-9:_]的字符,否则将不删除任何字符。禁用此选项之前,请确保您的标签值符合Prometheus要求。
效果
提交任务后,我们看下实际效果。
首先查看Prometheus 是否发现了我们的Pod。

然后查看具体的metrics,是否被准确抓取。
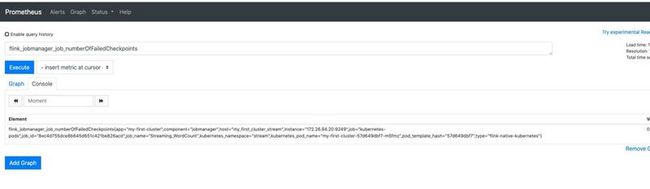
指标已经收集,后续大家就可以选择grafana绘图了。或是增加相应的报警规则。例如:
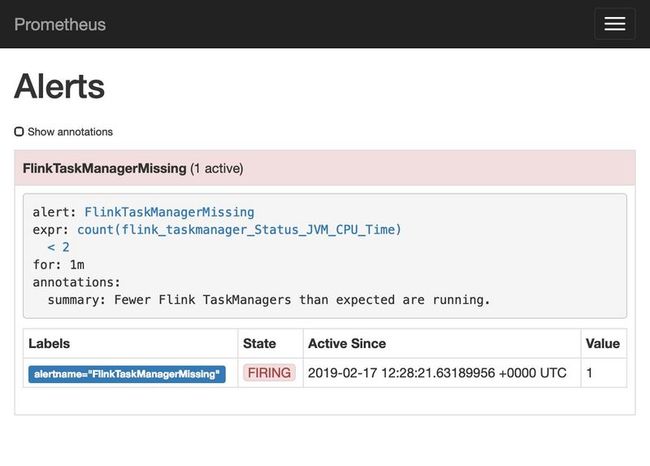
总结
当然除了Prometheus主动发现Pod,然后定期抓取metrcis的方式,flink 也支持向PushGateway 主动push metrcis。
Flink 通过 Reporter 来向外部系统提供metrcis。通过在conf/flink-conf.yaml中配置一个或多个Reporter ,可以将metrcis公开给外部系统。这些Reporter在启动时将在每个作业和任务管理器上实例化。
所有Reporter都必须至少具有class或factory.class属性。可以/应该使用哪个属性取决于Reporter的实现。有关更多信息,请参见各个Reporter 配置部分。一些Reporter允许指定报告间隔。
指定多个Reporter 的示例配置:
metrics.reporters: my_jmx_reporter,my_other_reporter
metrics.reporter.my_jmx_reporter.factory.class: org.apache.flink.metrics.jmx.JMXReporterFactory
metrics.reporter.my_jmx_reporter.port: 9020-9040
metrics.reporter.my_jmx_reporter.scope.variables.excludes:job_id;task_attempt_num
metrics.reporter.my_other_reporter.class: org.apache.flink.metrics.graphite.GraphiteReporter
metrics.reporter.my_other_reporter.host: 192.168.1.1
metrics.reporter.my_other_reporter.port: 10000启动Flink时,必须可以访问包含reporter的jar。支持factory.class属性的reporter可以作为插件加载。否则,必须将jar放在/lib文件夹中。你可以通过实现org.apache.flink.metrics.reporter.MetricReporter接口来编写自己的Reporter。如果 reporter定期发送报告,则还必须实现Scheduled接口。通过额外实现MetricReporterFactory,你的reporter也可以作为插件加载。