目录
一、数据库系统架构
二、数据存储与访问
1.数据库与文件系统对比总结
2.存储单位
2.1 硬盘
2.2 文件系统
2.3 RDSBM
3.访问策略
3.1 顺序访问
3.2 Indexing
3.3 Buffer Pool
3.4 join运算三种Query Plan
(本文是中科院陈世敏老师课程学习笔记)
--------------------------------------------
一、数据库系统架构
DBMS-Database Management System 数据库管理系统
RDBSM -关系型数据库系统
主流商用系统:Oracle 、Microsoft SQL、IBM DB2
开源:PostgreSQL、MySQL、sqlite
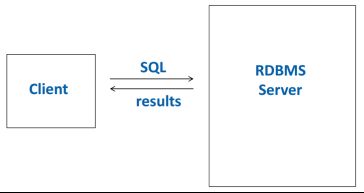

Parser:语法解析、语法检查、表名、列名、类型检查
Optimizer:产生可行query plan -> 估计运行时间和空间代价 -> 选择最佳query plan;
优化内容包括访问方式、实现的算法、多个连接的次序等等
Execution Engine:根据query plan -> SQL语句 完成运算和操作
Buffer pool:内存中缓存
Data Storage and Indexing:数据存储策略与高效访问策略
Transaction management:事务管理,保证ACID,进行logging、locking保证事务之间的正确性
ACID:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)ACID见关系型数据管理系统三
二、数据存储与访问
1.先一张wondeful的对比总结:

可以看出数据库的接口应该是在文件系统提供的基本编程接口上实现的
2.存储单位
2.1硬盘:扇区 512B
2.2文件系统:4KB
2.3RDSMS:database page size 4KB,8KB,16KB...(文件系统的整数倍),一个Page占一段一维的地址空间

slot用指针记录着每个记录,之所以这么做是因为每个记录都是不定长的,不能用size*第n页+起始->推出每条记录的首地址。
记录前面存储定长,后面存储变长,len=定长+变长


3.访问策略
3.1顺利访问
select Name,GPA from Student where Major='计算机';
顺序读取student每个page
对每个page顺序访问每个tuple
检查条件是否成立
对于成立的读取Name和GPA
这对一些情况来说效率会很低,经常要把所有数据遍历一遍。
3.2 Index建立索引
Tree based:有序,支持点查询和范围查询
Hash based:无序,只支持点查询
3.2.1 Hash Indexing

bucket = page
当链过长时候需要进行renew hash
3.2.2B+ Tree Indexing
3.2.2.1 结构


内部节点:
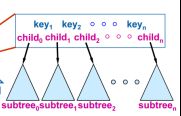
叶子节点:
key1
subtree0
大体流程:查询某个键值-> 进入为该键建立的索引B+树->内部节点->叶子节点(可包含多个值)->找到键值对应的指针,得到page Id和In- page tuple slot ID->page管理结构->page header->page slot->tuple,获取记录信息
3.2.2.2 四种操作
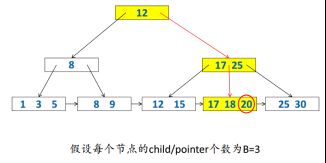
(1)Search
共有N个Key,树高O(logBN) = 总I/O数
每个节点内部二分查找O(log2B)总比较次数=O(log2B)*O(logBN) =O(log2N)
eg.search 20
(2)Insert
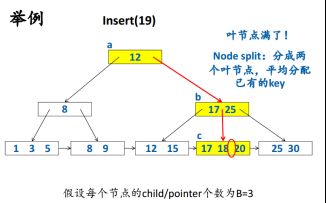


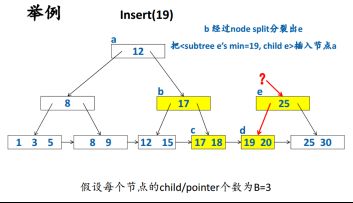
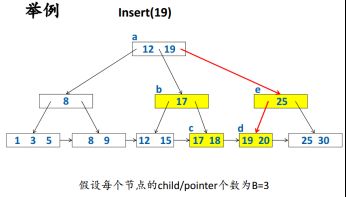
注意:在插入满格需要分裂时候,要向上一级呈递自己最小key,且内部节点不再保留该key,叶子节点需要保留。
(3)Delete
search到之后delete,删除后节点为空,进行node merge操作,或者完全不进行merge.
(4)Range Scan
先由内部节点找到起始叶节点,通过child sibling pointer沿着叶往下读,一直到范围终止。
3.3 Buffer Pool

-目的
减少I/O,提高性能
-原理
(1)Temporal Locality 时间局部性
同一数据可能在一段时间内被访问多次
(2)Spatial Locality 空间局部性
位置相同的数据可能会被在一起访问
-访问过程
检查page 是否在buffer pool中
(1)hit:找到,直接访问
(2)miss:在buffer中找到一个可用的frame ,从硬盘中读取,放入frame
-替换策略
buffer满了,需要替换frame
(1)random 随机替换
(2) FIFO 先进先出
(3)LRU 最近最少使用
-LRU详解
用次数作为标记,按次数排成链表,需要替换时候标记数最小首当其冲,代价O(1)
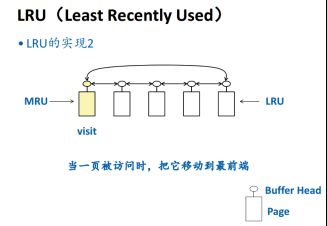
-clock算法
LRU队列遇到多线程共享队头,等待临界区浪费很多时间。所以把一个共享变量,变成一圈。


开始,frame空白,R为空
frame读入数据,R=1
R全为1,所有frame都有数据了
顺时针转圈,没访问的修改R=0,中间被访问了R会被设置为1
再来一圈,R=0的,上一圈没被访问过,选为victim被替换
3.4 join运算实现详解
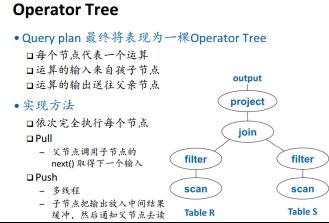
-join的三种实现思路
(1)loop
两层循环,时间代价二次,两个改进版本


(2) hash
比内存大的时候进行hash分块,,代价线性,读2MR+2MS

(3)sorting
通常是两边数据都是排好序的才这么用。