hadoop-2.7.4完全分布式集群部署 外加测试例子mapreduce
更改系统时区(将时间同步更改为北京时间)
xiaolei@hadoop1:~$ date
Wed Oct 26 02:42:08 PDT 2017
xiaolei@hadoop1:~$ sudo tzselect
根据提示选择Asia China Beijing Time yes
最后将Asia/Shanghai shell scripts 复制到/etc/localtime
xiaolei@hadoop1:~$ sudo cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
xiaolei@ubuntu:~$ date
Wed Oct 26 17:45:30 CST 2017
修改Ubuntu主机名
1、 输入:sudo vi /etc/hostname 把名字改为所需要的名字
2、 输入: sudo hostname 名字
3、 输入: exit 重启来使得配置生效
让其他主机来访问到你这个主机
1、 输入:sudo vi /etc/hosts
192.168.15.128 master
192.168.15.129 slave1
192.168.15.130 slave2
2、 重启生效
让Ubuntu开机时直接进入命令行模式
1. 输入:sudo vi /etc/X11/default-display-manager
2. 改为如下:
# /usr/sbin/gdm
false
安装jdk
1. mkdir /usr/local/java --新建文件夹
2. 将本地jdk安装包上传到服务器(使用lrzsz工具,当然也可以使用filezilla,还可以使用 alt+p 快捷键直接命令行传送 例如:put C:文件名
输入:sudo rz 然后选择文件
2. tar -zxvf jdk-7u75-linux-x64.tar.gz -C /usr/local/java --解压并复制文件夹到新建目录
-------------------------------------------------------------------------
3.这时候就可以进入根目录了。
解压完成后,进入到:
[root@localhost~]# cd /etc
[root@localhost etc]# vi profile
在profile文件的末尾加入如下命令:
在文件最后添加
export JAVA_HOME=/usr/java/jdk1.8.0_11
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
4.编辑profile文档立即生效 source /etc/profile
安装hadoop
配置 hadoop-env.sh (修改java_home) --环境
配置 core-site.xml --参数
配置 hdfs-site.xml
配置 yarn-site.xml
1. 将本地jdk安装包上传到服务器(使用lrzsz工具,当然也可以使用filezilla,还可以使用alt+p 快捷键直接命令行传送 例如:put C:文件名
2. tar -zxvf 上传的hadoop的压缩包 -C /usr/local/hadoop
在Hadoop1,2,3 中配置Hadoop环境变量
进入到 hadoop根目录,然后输入:cd /etc/hadoop (忘记JAVA_HOME的路径可以,使用命令 echo &JAVA_HOME 进行查找)
1.修改hadoop-env.sh文件
添加:
export JAVA_HOME=/usr/local/java/jdk1.8.0_11
2.配置core-site.xml 文件
输入:sudo vi core-site.xml
在configure中加入如下:
fs.defaultFS
hdfs://master:9000
hadoop.tmp.dir
/usr/local/hadoop/data
3.配置hdfs-site.xml
输入:sudo vi hdfs.site.xml
在configure中加入如下
dfs.replication
2
dfs.namenode.dir
/usr/local/hadoop/hadoop-2.7.4/name/
dfs.datanode.dir
/usr/local/hadoop/hadoop-2.7.4/data/
4.配置mapred-site.xml
首先改名字:sudo mv mapred-site.xml.template
然后,sudo vi mapred-site.xml
修改配置文件如下:
mapreduce.framework.name
yarn
5.配置yarn-site.xml
输入:sudo vi yarn-site.xml
yarn.resourcemanager.hostname
master
yarn.nodemanager.aux-services
mapreduce_shuffle
6.关闭Linux防火墙(因为hadoop运行与内网不需要连接外网,所以可以关闭防火墙)
sudo service iptables status (查看防火墙状态)
sudo service iptables stop (这个知识暂时的关闭,开机还是会自动启动)
sudo chkconfig iptables --list (查看各个级别防火墙状态)
sudo chkconfig iptables off (关闭防火墙 ,开机不会启动)
每台机器都要关闭防火墙
Ubuntu 17.4 的关闭防火墙命令: sudo ufw disable
--------------------------------------------------------------------------------
一台主机master的hadoop配置完成,然后需要将hadoop文件夹拷贝到其他两台,所以更加急需要无密码的ssh:
怎么ssh无密码登录
1、 输入ssh-keygen -t rsa
2. 后面出来的读直接默认 (全按回车)
3. 把公钥复制到各自主机下 scp id_rsa.pub slave1:/home/hadoop/.ssh/
4. 把它加入到授权文件里面(authorized_keys)cat id_rsa.pub >>authorized_keys(如果没有这个文件则用touch authorized_keys创建,然后修改为权限为:-rw------- 1 hadoop hadoop 0 Aug 30 15:37 authorized_keys,则输入:sudo chmod 600 authorized_keys)
5. 把自己的id_rsa.pub公钥追加到自己的authorized_keys (输入:cat id_rsa.pub>>authorized_keys)
--------------------------------------------------------------------------------
配置完无密码的ssh,拷贝hadoop:(就如有多台服务器,采用这个方式更加方便)
在master的主机上:输入:scp -r /usr/local/hadoop/hadoop-2.7.4 slave1:/usr/local/hadoop
再继续拷贝到第二台:输入:scp -r /usr/local/hadoop/hadoop-2.7.4 slave2:/usr/local/hadoop
7.格式化hadoop
为了能让hadoop在任意位置执行,配置环境变量:sudo vi /etc/profile
在里面增加 HADOOP_HOME,如下:
export JAVA_HOME=/usr/local/java/jdk1.8.0_11
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.7.4
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
输入:hadoop namenode -format 格式化hadoop
常见报错:
ERROR namenode.NameNode: java.io.IOException: Cannot create directory /export/home/dfs/name/current
ERROR namenode.NameNode: java.io.IOException: Cannot remove current directory: /usr/local/hadoop/hdfsconf/name/current
原因是 没有设置 /usr/hadoop/tmp 的权限没有设置, 将之改为:
sudo chown –R hadoop:hadoop /usr/local/hadoop/
sudo chmod -R a+w /usr/local/hadoop
8.启动hadoop
输入: cd /usr/local/hadoop/hadoop-2.7.4/sbin/ 进入这个文件夹
接着输入:start-dfs.sh
输入:jps (查看进程)
结果如下:
3058 NameNode
3219 DataNode
3414 SecondaryNameNode
3527 Jps
9.配置slaves文件
输入:cd /usr/local/hadoop/hadoop-2.7.4/etc/hadoop
再输入:sudo vi slaves
把localhost 修改为如下:
当master不仅作为namenode而且还要作为datanode时,三个都加上
master
slave1
slave2
10.启动yarn用于跑程序
在sbin目录下输入:start-yarn.sh
11.浏览hdfs状态
打开浏览器在地址输入:192.168.15.128:50070(即为:master的ip地址:50070)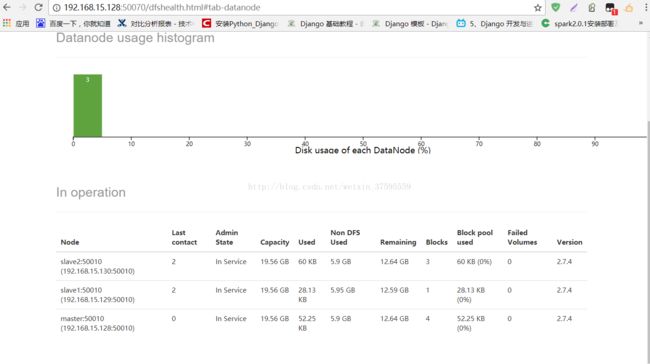
测试:上传文件到hdfs 小例子
首先在hdfs中新建data文件夹:输入:hadoop fs -mkdir /data
输入:hadoop fs -put 文件名 /data
然后进入到192.168.15.128:50070地址,点击Utilities ——> Browse the file system 进行查看
测试:mapreduce 小例子
1.计算圆周率
输入:cd /usr/local/hadoop/hadoop-2.7.4/sahre/hadoop/mapreduce 直接运行自带的例子
输入: hadoop jar hadoop-mapreduce-examples-2.7.4.jar pi 5 5
如下:
hadoop@master:/usr/local/hadoop/hadoop-2.7.4/share/hadoop/mapreduce$ hadoop jar hadoop-mapreduce-examples-2.7.4.jar pi 5 5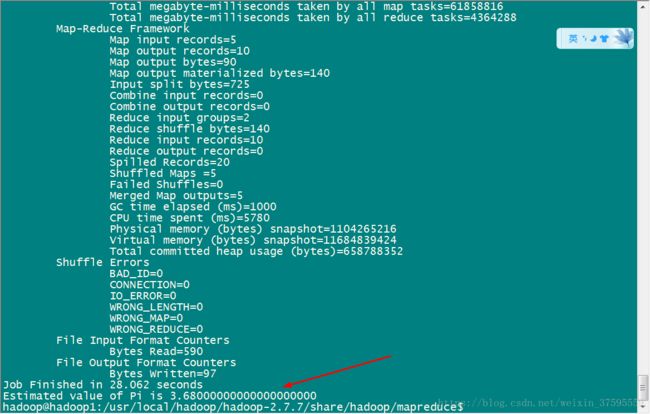
2.运行wordcount 程序
输入如下:新建一个wordcount文件夹,再在wordcount文件夹下新建一个input文件夹
hadoop@master:~$ hadoop fs -mkdir /data/wordcount
hadoop@master:~$ hadoop fs -mkdir /data/wordcount/input
hadoop@master:~$ hadoop fs -put wordcount.txt /data/wordcount/input
输入:sudo vi wordcount.txt
在里面输入如下内容:
hello liu
hello tom
hello kitty
hello jianghesong
hello wangzhe
hello flue
将wordcount.txt 文件上传到hdfs的input的文件夹下:
输入:hadoop fs -put wordcount.txt /data/wordcount/input
//这wordcount 带两个参数,一个是输入路径 另一个是结果的输出路径
进入到/usr/local/hadoop/hadoop-2.7.4/share/hadoop/mapreduce路径下:
运行程序:输入:hadoop jar hadoop-mapreduce-examples-2.7.4.jar wordcount /data/wordcount/input/wordcount.txt /data/wordcount/output
查看结果:可以通过网页浏览查看,也可以同过命令行直接查看:
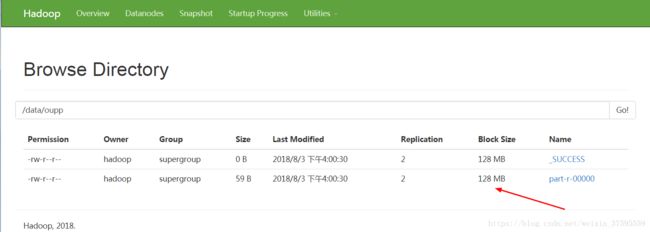
输入:hadoop fs -ls /data/wordcount/output
再输入:hadoop fs -cat /wordcount/output/part-r-00000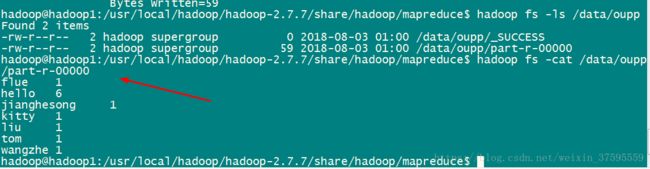
常见报错:hadoop datanode没有启动
若HDFS一直没有启动,读者可以查询日志,并通过日志进行分析,以上提示信息显示了NameNode和DataNode的namespaceID不一致。
这个问题一般是由于两次或两次以上的格式化NameNode造成的,
有两种方法可以解决,第一种方法是删除DataNode的所有资料(及将集群中每个datanode的/hdfs/data/current中的VERSION删掉,
然后执行hadoop namenode -format重启集群,错误消失。<推荐>);
第二种方法是修改每个DataNode的namespaceID(位于/hdfs/data/current/VERSION文件中)
<优先>或修改NameNode的namespaceID(位于/hdfs/name/current/VERSION文件中),使其一致。