MySQL数据库索引的原理(B-Tree)
我就不画图了, 首先, 先试想一下, 有个图书馆, 里面有10万本书, 有一本书叫"金瓶梅",有一天小明去图书馆想借一本书,就是金瓶梅,如果直接去找, 从10万本书里找, 一本本找过去, 估计也要个几年, 几年后估计小明也不想看金瓶梅了吧.
当然现实中图书馆肯定不能这么找书了, 一般图书馆会分类, 例如:
科学类: 物理书, 化学书.....
武侠类: 天龙八部, 射雕英雄传....
成人类: 金瓶梅(第2排,第3列...).....
分完类,每本书都要有一个小卡片作为,它位置的标识, 像上面说的金瓶梅(第2排,第3列),这样找书是不是很快
但是呢!维护很麻烦,假如这回图书馆要加一本书<肉蒲团>,新书加进去, 如果不添加小卡片,我们就不知道他加进去了,也不知道去哪找他了, 更新的时候也是, 要重新整理小卡片, 所以下面总结:
1. 索引(index)可以加快查询速度, 但是是以牺牲删除,修改,添加为代价(dml语句会有影响)
2.索引(index)信息是存放在空间里...*.myi(小卡片占地方)
---------------------------------------- 上面只是说了一个例子 --------------------------------------------
那真正这个索引怎么让我们的检索速度变快呢? 这边就要进入主题了 MySQL索引的原理
MySQL索引的原理
MySQL索引是用一种叫做聚簇索引的数据结构实现的,下面我们就来看一下什么是聚簇索引。
聚簇索引是一种数据存储方式,它实际上是在同一个结构中保存了B+树索引和数据行,InnoDB表是按照聚簇索引组织的(类似于Oracle的索引组织表)。
注:
B+ 树是一种树数据结构,是一个n叉排序树,每个节点通常有多个孩子,一棵B+树包含根节点、内部节点和叶子节点。根节点可能是一个叶子节点,也可能是一个包含两个或两个以上孩子节点的节点。
B+ 树通常用于数据库和操作系统的文件系统中。NTFS, ReiserFS, NSS, XFS, JFS, ReFS 和BFS等文件系统都在使用B+树作为元数据索引。B+ 树的特点是能够保持数据稳定有序,其插入与修改拥有较稳定的对数时间复杂度。B+ 树元素自底向上插入。
InnoDB通过主键聚簇数据,如果没有定义主键,会选择一个唯一的非空索引代替,如果没有这样的索引,会隐式定义个主键作为聚簇索引。
虽然InnoDB也使用B+Tree作为索引结构,但具体实现方式却与MyISAM截然不同。
第一个重大区别是InnoDB的数据文件本身就是索引文件。从上文知道,MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。而在InnoDB中,表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶结点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。
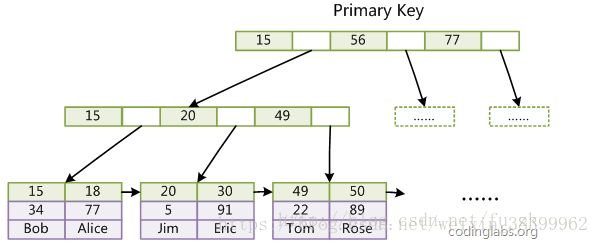
上是InnoDB主索引(同时也是数据文件)的示意图,可以看到叶结点包含了完整的数据记录。这种索引叫做聚集索引。因为InnoDB的数据文件本身要按主键聚集,所以InnoDB要求表必须有主键(MyISAM可以没有),如果没有显式指定,则MySQL系统会自动选择一个可以唯一标识数据记录的列作为主键,如果不存在这种列,则MySQL自动为InnoDB表生成一个隐含字段作为主键,这个字段长度为6个字节,类型为长整形。
第二个与MyISAM索引的不同是InnoDB的辅助索引data域存储相应记录主键的值而不是地址。换句话说,InnoDB的所有辅助索引都引用主键作为data域。例如,图11为定义在Col3上的一个辅助索引:
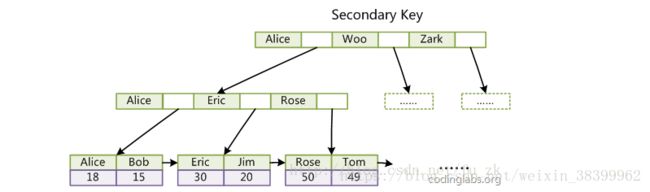
(图示: InnoDB索引)
MyISAM索引实现
MyISAM引擎使用B+Tree作为索引结构,叶结点的data域存放的是数据记录的地址。下面是MyISAM索引的原理图:
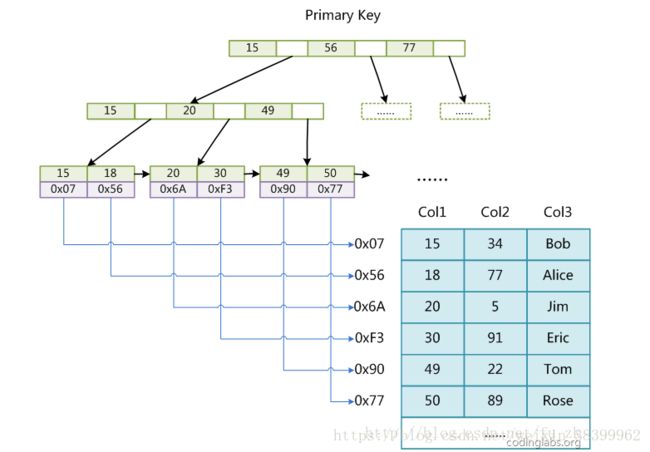
这里设表一共有三列,假设我们以Col1为主键,则图8是一个MyISAM表的主索引(Primary key)示意。可以看出MyISAM的索引文件仅仅保存数据记录的地址。在MyISAM中,主索引和辅助索引(Secondary key)在结构上没有任何区别,只是主索引要求key是唯一的,而辅助索引的key可以重复。如果我们在Col2上建立一个辅助索引,则此索引的结构如下图所示:
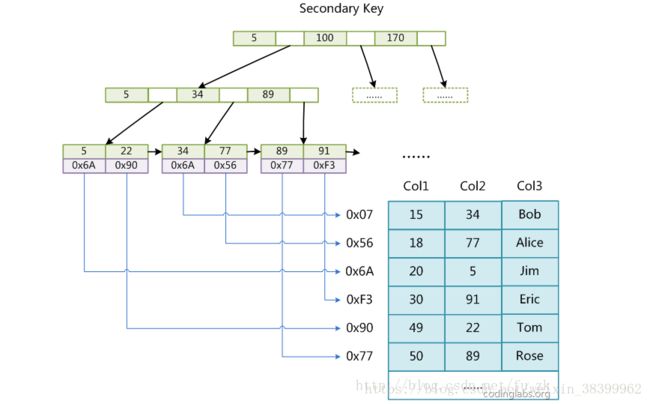
(图示 MyISAM索引)
同样也是一颗B+Tree,data域保存数据记录的地址。因此,MyISAM中索引检索的算法为首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其data域的值,然后以data域的值为地址,读取相应数据记录。
MyISAM的索引方式也叫做“非聚集”的,之所以这么称呼是为了与InnoDB的聚集索引区分。
聚簇索引表最大限度地提高了I/O密集型应用的性能,但它也有以下几个限制:
1)插入速度严重依赖于插入顺序,按照主键的顺序插入是最快的方式,否则将会出现页分裂,严重影响性能。因此,对于InnoDB表,我们一般都会定义一个自增的ID列为主键。
2)更新主键的代价很高,因为将会导致被更新的行移动。因此,对于InnoDB表,我们一般定义主键为不可更新。
3)二级索引访问需要两次索引查找,第一次找到主键值,第二次根据主键值找到行数据。
二级索引的叶节点存储的是主键值,而不是行指针,这是为了减少当出现行移动或数据页分裂时二级索引的维护工作,但会让二级索引占用更多的空间。
在什么列上添加索引比较合适:
1. 较频繁的作为查询条件字段应该创建索引,例如身份证号
2. 唯一性太差的字段不适合单独建立索引,例如男,女(可以理解成字段的相同值太多,不适合做为索引)
3. 更新非常频繁的字段不适合加索引.
explain用法
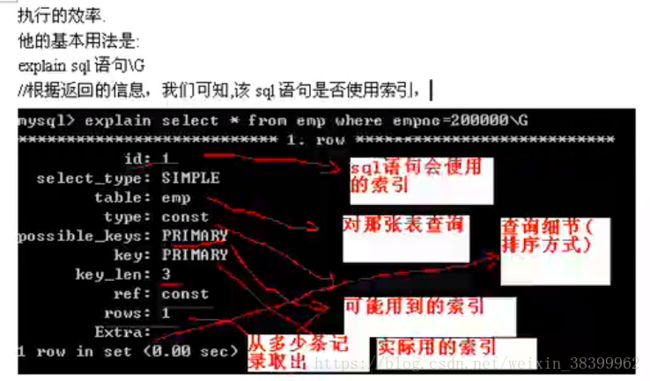
当然: 有些查询动作是无法利用索引完成排序, order by Group by
