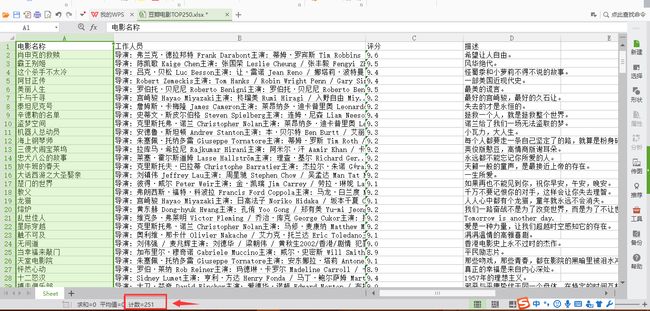
爬虫项目:requests爬取豆瓣电影TOP250存入excel中
这次爬取是爬取250部电影的相关内容,分别用了requests请求url,正则表达式re与BeautifulSoup作为内容过滤
openpyxl作为excel的操作模块,本人为才学不久的新手,代码编写有点无脑和啰嗦,希望有大神能多提建议
首先,代码清单如下:
import requests
import re
from bs4 import BeautifulSoup
import openpyxl
def get_movie_top250_name(soup):
targets = soup.find_all('span',class_="title") #用BeautifulSoup找寻一个内容为一个列表
targets_name = re.findall(r'.*?title">(.*?)<\/span',str(targets)) #用正则表达式去掉标签
for each in targets_name: #剔除targets_name当中的别名
if '\xa0' in each:
targets_name.remove(each)
return targets_name
def get_movie_top250_workers(soup):
targets = soup.find_all('p',class_="")
targets_workers = []
for each in targets:
targets_workers.append(each.text.replace('','').replace('\n ','').replace('\xa0','').replace('\n ',''))
return targets_workers
def get_movie_top250_star(soup):
targets = soup.find_all('div', class_="star")
targets_star = re.findall(r'
其实一开始,有想过是不是直接用正则表达式找就行了,不用BeautifulSoup。然后完全是因为自己想多熟悉一下两个的用法,所以都用到了,自认为两个一起用能更准确些。首先谈一谈最重要的是码代码时候遇到的一些问题:
1.抓取电影的名字:
def get_movie_top250_name(soup):
targets = soup.find_all('span',class_="title") #用BeautifulSoup找寻一个内容为一个列表
targets_name = re.findall(r'.*?title">(.*?)<\/span',str(targets)) #用正则表达式去掉标签
for each in targets_name: #剔除targets_name当中的别名
if '\xa0' in each:
targets_name.remove(each)
return targets_name
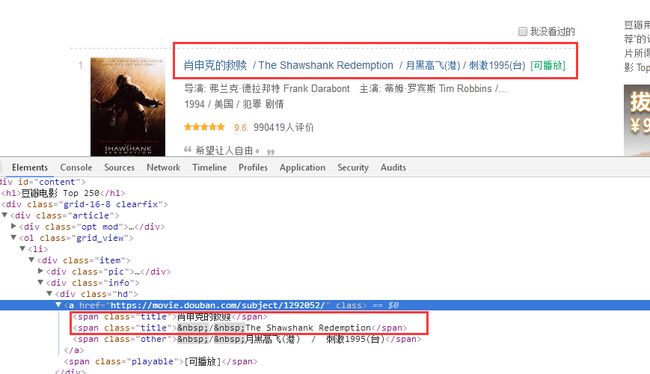
可以看出,每一个电影的class ='title'有两个,这就不好分辨了。由于本人刚学不久,所以在筛选电影的名字的时候,就花了我半天时间。其实回想很简单,如果把所有的名字print出来,就会发现别名前面都会有字符'\xa0',所以只要做一个if判断的过滤就可以解决(当时if判断也想了半天,结果问人才写出来的,基础不好,要补基础)。
2.爬取工作人员的内容,其中也包括电影的性质归属了,两个一起抓了,其实我就是懒,没有分开:
def get_movie_top250_workers(soup):
targets = soup.find_all('p',class_="")
targets_workers = []
for each in targets:
targets_workers.append(each.text.replace('','').replace('\n ','').replace('\xa0','').replace('\n ',''))
return targets_workers
这里的抓取只用到了BeautifulSoup,然后做一个replace的过滤,将多余的部分全部过滤(节点、空格之类的),比较简单
3.抓取评分、描述(一句很骚的话描述了整个电影),都跟第二点差不多,略过
下一步计划开始学习Scrapy框架抓取。。