2018年4月05日 RANDALL THOMSON
以下是 LogicMonitor 的资深技术操作工程师兰德尔. 汤姆森的博客。你会发现如果他没有梦想着下一次滑雪探险,那他一定忙于敲击键盘以保持 LogicMonitor SaaS 平台处于最佳状态。
构建我们的高可用性平台
LogicMonitor是一个基于 SaaS 的企业组织监控平台, 每天从5.5万多个用户收集超过200亿种指标。毫无疑问,我们需要24/7全天候提供服务。为了确保这种能力, LogicMonitor TechOps 团队使用 HashiCorpPacker、 Terraform和Consul,以可靠和可持续的方式动态地构建灾难恢复基础设施。
LogicMonitor SaaS 平台是基于蜂窝的体系结构。运行 LogicMonitor 所需的所有资源 (web 和数据库服务器、DNS 记录、消息队列、ElasticSearch 群集等) 都称为 pod。至关重要的是, 每个资源都要始终如一地调配而不会遗漏任何内容。为了实现这一级别的细节, 我们在公共云中提供的任何资源都必须通过 Terraform 来完成。过去18月来, 我们作出了很大努力, 不仅使用 Terraform 提供新的基础设施, 而且还要回填 (导入并/或重新创建) 现有资源。就这样发生了, 以一种偶然的方式, 我们的DR计划诞生了。我们不再需要一种方法来提供我们的生产基础设施而选择另一种方法来提供我们的 DR 计划。因为在Terraform的帮助下, 它们基本上是相同的情况。
即使有了这个万无一失的计划, DR 计划实施过程中仍然难免存在着出于良好的意图,但易错的人为失误。您可能有数百台 web 服务器并行运转, 但如果他们需要手动干预才能为客户提供服务, 那么这些任务必须经过串行处理。更糟的是, 一旦自动化停止恢复时间目标 (RTO)就会迅速增加。从基于并行的自动化运行切换到基于串行的手动进行不仅减慢了处理速度, 而且会立即增加压力负担。
我们的团队讨论了以前的 DR 实践的结果, 并制定了两个目标: 加快速度,删除手动步骤。应用这些 HashiCorp 产品 (Packer, Terraform 和Consul) 帮助我们实现了这两个目标。所以下面我将解释我们是如何克服各种绊脚石。
搭建Blocks
我们使用Packer来生成各种预焙的服务器模板。使用此方法而不是从一般映像开始, 提供了许多优点: 可以标记模板 (这有助于将有意义的上下文添加到它们所使用的内容), 服务器会启动所有安装的应用程序 (预应用配置管理)以及生成映像的方式被记录下来并置于版本控制之下。我们还将Packer集成到我们的软件构建和部署服务中, 以提供更好的可见性和一致性。
==> amazon-ebs: Creating AMI tags
amazon-ebs: Adding tag: "name": "santaba-centos7.4"
amazon-ebs: Adding tag: "approved": "true"
amazon-ebs: Adding tag: "prebaked": "true"
amazon-ebs: Adding tag: "LM_app": "santaba"
amazon-ebs: Adding tag: "packer_build": "1522690645"
amazon-ebs: Adding tag: "buildresultsurl": "https://build.logicmonitor.com/PACK"
==> amazon-ebs: Creating snapshot tags
==> amazon-ebs: Terminating the source AWS instance...
==> amazon-ebs: Cleaning up any extra volumes...
==> amazon-ebs: Destroying volume (vol-0134567890abcdef)...
==> amazon-ebs: Deleting temporary keypair...
Build 'amazon-ebs' finished.
'''
==> Builds finished. The artifacts of successful builds are:
--> amazon-ebs: AMIs were created:
eu-west-1: ami-1234567876
us-east-1: ami-9101112131
us-west-1: ami-4151617181
随着这个新流程的实施, Packer提供的一个最重要的改进就是节省时间。我们从需要45分钟+的启动时间到仅需5分钟便可使单个组件能够提供服务。
精心策划的扩建
过去, 如果我们想复制现有服务器的构建方式, 我们必须查找文档 (交叉手指表示祈祷), 然后评估是否进行了手动更改 (甚至可能没有同事的. bash_history给予梳理) 或假设有黑色魔法的存在。这导致了应该完全相同的环境的不一致。一次性的, 手动的方法对于必须进行逆向工程去构建一个新pod的工程师来说也是一个很大的时间陷阱。通常还需要多种不同的资源调配技术。
当我们将所有的生产基础结构移动到 Terraform 中时, 我们意识到我们可以使用相同的代码来进行灾难恢复。我们将有能力以可重复的方式测试我们的 DR 计划, 而不会产生很多压力。Terraform 可以像构建基础结构那样轻松地拆除基础结构。它需要120多个不同的资源来创建一个 pod-这是一个很大的量去进行记忆或删除。
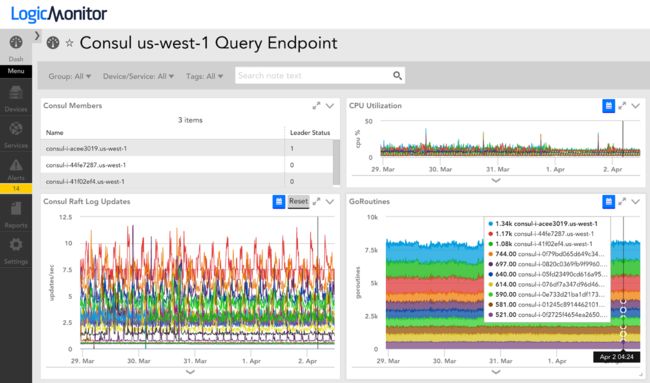
通过开发我们自己的Terraform Providers, 解决了在 DR 过程中需要手动干预的一些情况。我们创建了两个独立的providers, 每个都实现一个独特的任务。由于我们的团队使用 LogicMonitor 作为停机的真相来源, 我们需要一种方法来加载 Terraform 创建的资源到我们的 LogicMonitor 帐户中。然后, 我们可以根据需求监控这些资源, 并知道它们何时需要服务。如果Consul健康检查失败 (在下一节中对此有更多的了解), 我们希望马上得到通知。
下一个要填充的gaps是应用程序配置管理。我们开发了一个内部使用的 Terraform provider来自动从资源输出中填充配置信息。目前, 每个 pod 都需要130个单独的配置项目, 这给错误留下了很大的发生概率。使用 Terraform 提供程序不仅节约了更多的时间, 而且还省略了复制和粘贴的需求, 最小化错误 发生的可能性(曾经尝试加载一个 URL, 把其中的 ". com"写成了 "om" )。
那玩意又跑哪去了?
在Consul中登记服务给我们带来了一些好处。我们已经可以通过监控自动确定服务的健康状况, 但是我们不能以有意义的方式将这些信息应用到我们的pod的组件中。在Consul中使用 HTTP 和 DNS 接口意味着较少的手动或静态配置, 以便服务知道其他服务的位置。到目前为止, 我们在每个pod中有17种不同的服务。我们甚至注册了我们的Zookeeper群集, 包括标记领导者, 使我们有一个一致 (和方便) 的方式, 以了解是否和在哪里服务。例如, 管理员客户端可以使用 zookeeper.service.consul 作为 FQDN 通过Consul DNS。
下面是一个示例Consul健康检查以确定给定的Zookeeper成员是否是群集中的当前负责人:
{
"name": "zookeeper",
"id": "zookeeper-leader",
"tags": [ "leader"],
"port": 2181,
"checks": [
{
"script": "timeout -s KILL 10s echo stat | nc 127.0.0.1 2181 | grep leader; if [ $? -eq 0 ]; then exit 0; else exit 2; fi",
"interval": "30s"
}
]
}
您可以利用您认为的服务变得更具创造性, 例如客户帐户的实例。我们的proxies和负载平衡器使用从consul模板自动写入其路由配置文件。这导致错误的机会减少, 并提供了可伸缩的模型, 因此我们可以继续管理更复杂的系统。这些proxies实际上配置自己, 管理数以百计或数以千计的后台, 从来不需要人类干预。当然, proxies本身也在Consul注册。
当灾难降临
那一天到来了。您的数据中心失去了电源。现在是 5am, 你和你的孩子已经醒着有半个夜晚了。你想做多少思考?你还能做多少思考?可能很少。
Cue Terraform plan; Terraform apply。复制项目文件并重复 (并希望您的 VPN 工作正常, 并且在目标区域中具有最新的服务器模板以及足够的实例限制...).
执行 HashiCorp Packer、Terraform 和Consul之间的协调已经代替了手动配置的需要, 并提供了一个弹性的 DR 过程。通过使用 LogicMonitor Provider,我们可以在迭代改进时快速验证测试结果。锻炼我们的灾难恢复肌肉已经把我们过去害怕的流程变成了无需过多思考的任务。
如果您有兴趣了解有关这些产品的更多信息, 请访问 [Terraform] 的 HashiCorp 产品页面 (https://www.hashicorp.com/Terraform) 和 [Consul] (https://www.hashicorp.com/consul)。
你是否有兴趣告诉别人你的 HashiCorp 故事, 或者 HashiCorp 的产品是如何帮助你制造出的惊人的东西的?让我们知道。把你的故事或想法发电子邮件给[email protected] guestblogs@hashicorp. com.
【原文】LogicMonitor Uses Terraform, Packer & Consul for Disaster Recovery Environments
APR 05 2018 RANDALL THOMSON
The following is a guest blog from Randall Thomson, Senior Technical Operations Engineer at LogicMonitor. When he's not daydreaming about his next snowboarding adventure, you will find him busily typing to keep the LogicMonitor SaaS platform in tip-top shape.
Building our Platform for High Availability
LogicMonitor is a SaaS-based monitoring platform for Enterprise organizations and collects over 20 billion metrics each day from over 55,000 users. Our service needs to be available 24/7, without question. In order to ensure this happens, the LogicMonitor TechOps team uses HashiCorp Packer, Terraform, and Consul to dynamically build infrastructure for disaster recovery (DR) in a reliable and sustainable way.
The LogicMonitor SaaS platform is a cellular based architecture. All of the resources (web and database servers, DNS records, message queues, ElasticSearch clusters, etc.) required to run LogicMonitor are referred to as a pod. It is critical that every resource be consistently provisioned and that you aren’t missing anything. To implement this level of detail, any resource we provision in the Public Cloud must be done via Terraform. We made a strong effort over the past 18 months to not only provision new infrastructure using Terraform, but also to backfill (import and/or re-create) existing resources. As it so happened, in a serendipitous way, our DR plan was born. We no longer needed one way to provision our production infrastructure and a different method for our DR plan. With Terraform, it’s basically the same in either case.
Even with this foolproof plan, there were still gaps in the DR process bound to us well intentioned, yet error-prone humans. You may have several hundred web servers being spun up in parallel, but if they need manual intervention before being able to provide service for your customers, then those tasks must be serially processed. Worse, as soon as the automation stops the recovery time objective (RTO) increases rapidly. The switch from actions being automatically instrumented in parallel to serial-based manual tasks not only slows the process down to a crawl, it instantly increases the stress burden.
Our team discussed the results from previous DR exercises and developed two goals: make it faster; remove manual steps. Implementing these HashiCorp products (Packer, Terraform, and Consul) helped satisfy both goals. So let's continue forward and address how we overcame a variety of stumbling blocks.
Building Blocks
We use Packer to generate a variety of pre-baked server templates. Using this approach instead of starting from a generic image offers many advantages: templates can be tagged (which helps add meaningful context to what they are used for), servers boot up with all applications installed (configuration management pre-applied, check!) and the way in which the image was built is documented and placed under version control. We also integrated Packer into our software build and deployment service to provide better visibility and consistency.
==> amazon-ebs: Creating AMI tags
amazon-ebs: Adding tag: "name": "santaba-centos7.4"
amazon-ebs: Adding tag: "approved": "true"
amazon-ebs: Adding tag: "prebaked": "true"
amazon-ebs: Adding tag: "LM_app": "santaba"
amazon-ebs: Adding tag: "packer_build": "1522690645"
amazon-ebs: Adding tag: "buildresultsurl": "https://build.logicmonitor.com/PACK"
==> amazon-ebs: Creating snapshot tags
==> amazon-ebs: Terminating the source AWS instance...
==> amazon-ebs: Cleaning up any extra volumes...
==> amazon-ebs: Destroying volume (vol-0134567890abcdef)...
==> amazon-ebs: Deleting temporary keypair...
Build 'amazon-ebs' finished.
'''
==> Builds finished. The artifacts of successful builds are:
--> amazon-ebs: AMIs were created:
eu-west-1: ami-1234567876
us-east-1: ami-9101112131
us-west-1: ami-4151617181
With this new process in place, one of the most significant improvements Packer provided was time savings. We went from often taking 45+ minutes from boot-up to only 5 minutes for an individual component to be capable of providing service.
Orchestrated Buildout
In the past, if we wanted to replicate how an existing server was built, we would have to lookup the documentation (cross your fingers) and then assess if any manual changes were made (there may not even be a co-worker’s .bash_history to comb through) or assume black magic. This led to inconsistencies for environments that should be exactly the same. The one-off, manual based approach was also a big time sink for whomever had to go reverse engineer a pod in order to build a new one. Often there were also a variety of different provisioning techniques needed.
As we moved all of our production infrastructure into Terraform, we realized we could use the same code for Disaster Recovery. We would have the ability to test our DR plan in a repeatable manner without a lot of stress. Terraform can tear down infrastructure just as easily as building it. It takes over 120 different resources to create a pod - which is a lot to remember to remove.
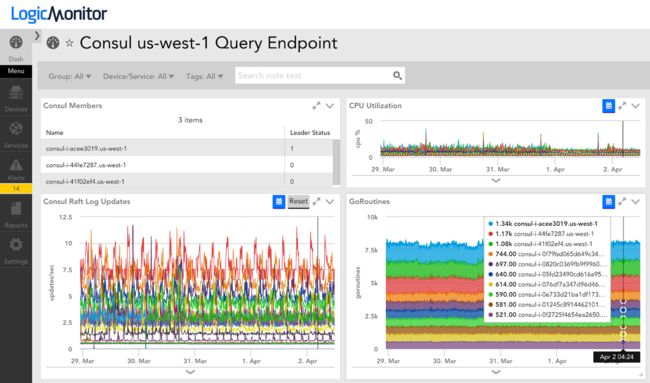
Some of the gaps requiring manual intervention in our DR process were resolved by developing our own Terraform Providers. We created two separate providers, each to achieve a unique task. Since our team uses LogicMonitor as the source of truth for outages, we needed a way to load resources created by Terraform into our LogicMonitor account. We could then monitor those resources on demand and know when they required service. If Consul health checks were failing (more about this in the next section) we wanted to be alerted right away.
The next gap to fill was application configuration management. We developed an internal-use Terraform provider to automatically populate configuration information from the resource outputs. Currently, each pod requires 130 individual configuration items which left a lot of room for mistakes. Using a Terraform provider not only led to more time savings but also depleted the need to copy and paste, minimizing errors (ever try loading a URL with the 'om' missing from ‘.com’?).
Where is That Thing Running Again?
Registering services in Consul provided us with several benefits. We could already automatically determine the health of services with monitoring but we could not apply that information in a meaningful way to components in our pods. Using the HTTP and DNS interfaces in Consul meant less manual or static configuration in order for services to know where other services are. So far we have 17 different services registered in each pod. We even register our Zookeeper clusters, including tagging the leader, so that we have a consistent (and convenient) way to know if and where services are up. For example, a Zookeeper client can use zookeeper.service.consul as the FQDN via Consul DNS.
Here is an example Consul health check to determine if a given Zookeeper member is the current leader in the cluster:
{
"name": "zookeeper",
"id": "zookeeper-leader",
"tags": [ "leader"],
"port": 2181,
"checks": [
{
"script": "timeout -s KILL 10s echo stat | nc 127.0.0.1 2181 | grep leader; if [ $? -eq 0 ]; then exit 0; else exit 2; fi",
"interval": "30s"
}
]
}
You can get creative with what you consider a service, such as an instance of a customer account. Our proxies and load balancers use consul-template to automatically write their routing configuration files. This has resulted in less chance for error and provided a scalable model so we can continue to manage more complex systems. The proxies literally configure themselves, managing hundreds or thousands of backends and never need human intervention. And of course the proxy itself is registered in Consul as well.
When Disaster Strikes
The day has come. Your datacenter lost power. It’s 5am and you’ve been up half the night with your toddler. How much thinking do you want to have to do? How much thinking will you even be capable of? Likely very little.
Cue Terraform plan; Terraform apply. Copy the project file and repeat (and hope your VPN works, and that you have up-to-date server templates in the target regions along with enough instance limits...).
The coordinated efforts between implementing HashiCorp Packer, Terraform and Consul have depleted the need for manual configuration and provided a resilient DR process. And by using the LogicMonitor Provider, enables us to rapidly validate the results of our tests as we iterate through improvements. Exercising our disaster recovery muscles has turned processes we used to fear into near thoughtless tasks.
If you are interested in learning more about these products, please visit the HashiCorp Product pages for Terraform and Consul.
Are you interested in telling others your HashiCorp story or perhaps how HashiCorp products helped with that amazing thing you built? Let us know. Email your story or idea to [email protected].