【Paper】UCI-HAR:Human Activity Recognition on Smartphones using a Multiclass Hardware-Friendly SVM
论文原文:点击此处
论文下载:点击此处
论文被引:605
论文年份:2012
Human Activity Recognition on Smartphones using a Multiclass Hardware-Friendly Support Vector Machine
Abstract
基于活动的计算[1]旨在通过利用异构传感器来捕获用户及其环境的状态,以适应外部计算资源。 当这些传感器连接到受试者的身体上时,它们可以连续监视大量生理信号。 这在医疗保健应用中具有吸引人的用途,例如在老年人的日常活动监控中利用环境智能(AmI)。 在本文中,我们介绍了使用智能手机惯性传感器进行人体身体活动识别(AR)的系统。 由于这些手机的能源和计算能力有限,因此我们提出了一种新颖的,硬件友好的方法来进行多类别分类。 此方法适用于标准支持向量机(SVM),并利用定点算法来降低计算成本。 与传统SVM的比较表明,在保持相似准确性的同时,在计算成本方面有了显着改善,这可以为开发AmI的可持续性系统做出贡献。
Keywords: Activity Recognition, SVM, Smartphones, Hardware-Friendly
1 Introduction
自从1979年第一台商用手持式手机问世以来,已经观察到手机市场的加速增长,到2011年已达到世界人口的80%[2]。 这表明,在很短的时间内,几乎每个人都可以轻松访问移动设备。 智能手机是新一代的手机,除了基本的电话技术外,现在还具有许多其他功能,例如多任务处理和各种传感器的部署。 当前尝试在保持相似的电池寿命和设备尺寸的同时合并所有这些功能。
这些移动设备在我们日常生活中的集成正在迅速增长。 可以预见,这样的设备将无缝地跟踪我们的活动,向他们学习,并随后帮助我们对未来的行动做出更好的决策[3]。 这是AmI所依赖的一个关键概念。 在本文中,我们将智能手机用于人类活动识别,并将其潜在地应用于辅助生活技术中。我们考虑到当前的硬件限制,并提出了一种新的AR替代方案,该方案需要较少的计算资源即可进行操作。
AR旨在通过对自己和周围环境的一系列观察来识别一个人所采取的行动。 例如,可以通过利用从惯性传感器(如加速度计)[4]中检索到的信息来实现识别。 在某些智能手机中,这些传感器默认情况下是嵌入式的,我们由此受益于通过有监督的机器学习(ML)方法,处理人体惯性信号,来对一组身体活动(站立,行走,放置,行走,上楼,下楼)进行分类。
本文的结构如下:第2节描述了有关先前工作的最新技术。第3节介绍了所采用方法的描述。在那里,为捕获数据而进行的实验性设置以及对数据的数学描述。在那里,解释了用于捕获数据的实验装置以及所提出的 Multiclass Hardware Friendly Support Vector Machine (MC-HF-SVM) 的数学描述。
2 Related Work
使用智能手机开发的AR应用程序具有多个优点,例如,无需其他固定设备即可轻松实现设备便携性,以及由于不显眼的感应给用户带来的舒适感。 这与使用特定硬件设备(例如[5]或传感器主体网络[6])的其他已建立的AR方法形成对比。 尽管使用大量传感器可以提高识别算法的性能,但是由于困难和佩戴时间的原因,期望公众在日常活动中使用它们是不现实的。 基于智能手机的方法的一个缺点是,手机上的能源和服务与其他应用程序共享,这在资源有限的设备中变得至关重要。
先前已被用于识别的ML方法包括朴素贝叶斯,支持向量机,基于阈值和马尔可夫链[6]。 特别是,我们将支持向量机用于分类,因为在[7]和[8]中也使用了SVM。 尽管尚不清楚哪种方法对AR效果更好,但SVM已在包括异类识别(例如手写字符[9]和语音[10])在内的多个领域确认了成功的应用。
在机器学习中,定点算法模型最初已经被研究[11,12],这是因为带有点点单元的设备不可用或价格昂贵。如今,对于需要低成本设备或降低多任务移动设备负载的AmI系统采用这些方法的可能性已变得特别具有吸引力。 Anguita等。 在[13]中介绍了**硬件友好型SVM(HF-SVM)**的概念。 此方法在SVM分类器的前馈阶段中采用定点算法,以便允许在硬件受限的设备中使用此算法。 在本文中,我们将此模型扩展为多类分类。
SVM算法最初仅针对二进制分类问题提出,但已针对不同类别的问题(例如,在[9]中)使用不同的方案进行了调整。 特别是,我们选择了“单对所有”(OVA)方法,因为它的准确性与Rifkin和Klautau在[14]中证明的其他分类方法相当,并且因为它的学习模型与例如 一对一(OVO)方法。 当在有限资源的硬件设备中使用时,这是有利的。
3 Methodology
3.1 Experimental Setup
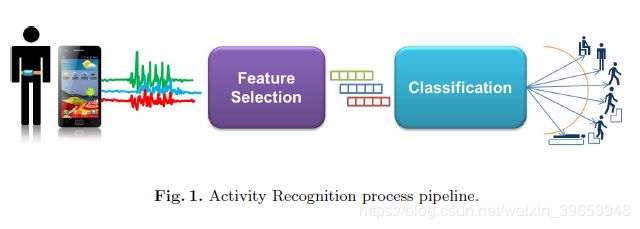
实验是由一组30名志愿者组成的,年龄在19-48岁之间。 每个人都将智能手机放在腰上进行了前面提到的六项活动。 实验已被录像,以方便数据标记。 **所获得的数据库已随机分为两组,其中70%的模式已用于训练目的,30%的模式用作测试数据:然后将训练集用于训练多类SVM分类器,**这将在以下部分中介绍 。 实验中使用了三星Galaxy S2智能手机,因为它包含一个加速度计和一个陀螺仪,分别以50Hz的恒定速率测量3轴线性加速度和角速度,足以捕获人体运动。
出于增强现实的目的,我们开发了基于Google Android操作系统的智能手机应用程序。 识别过程始于传感器信号的采集,随后通过应用噪声滤波器对该传感器信号进行预处理,然后在2.56秒和50%重叠的固定宽度滑动窗口中进行采样。 通过在时域和频域中从加速度计信号中计算变量(例如,平均值,标准差,信号幅度区域,熵,信号对相关性等),可以从每个窗口中获得17个特征的向量。 快速傅立叶变换用于发现信号频率分量。 最后,这些模式用作受过训练的SVM分类员的输入,以识别活动。 整个AR处理流程如图1所示。
3.2 The Multiclass HF-SVM model
考虑一个由 l 个模式组成的数据集,其中每个模式都是一对(xi, yi)所有i 都在区间 [1, … l]内,xi 属于 R ^m,并且yi = ±1。 通过解决凸约束二次规划(CCQP)最小化问题可以学习标准的二进制SVM,该问题由以下公式表示[13]:




4 Experimental results
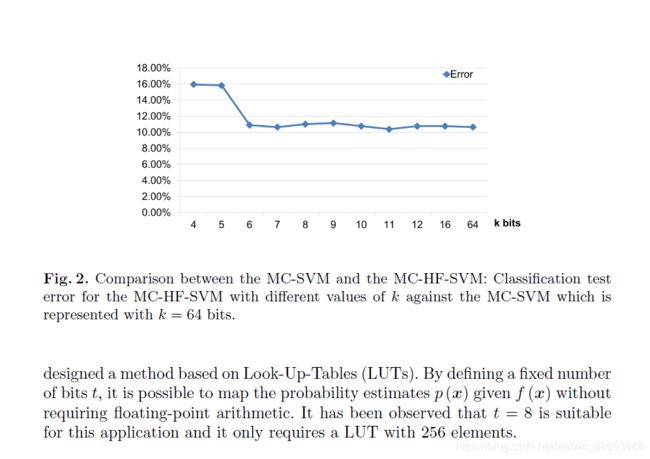
为了评估MC-HF-SVM的性能,使用本文描述的AR数据集进行了一组实验。 它们包括学习具有不同位数k的SVM模型以进行估计,然后将它们在测试数据错误方面的性能与标准的O点多类SVM(MC-SVM)进行比较。 比较结果如图2所示。
实验表明,对于该数据集,k = 6位足以达到与使用64位点算法的MC-SVM方法相当的性能。 对于64到6位的k值,测试误差保持稳定(大约1%的变化),但是当达到5位时,测试误差会明显增加到15%。 此外,从图中还可以看出,与使用MC-SVM获得的k值相比,一些k值产生的误差较小。 此发现与[18]和[19]中的发现一致。 因此,表明这些方法可以表现出较低的泛化误差。 我们认为,模型参数的截断可能会产生正则化效应。
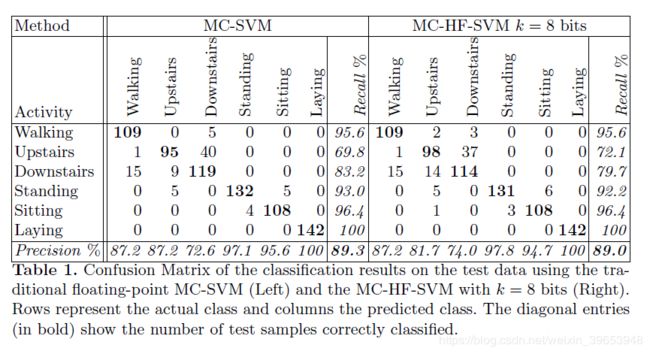
通过表1中的混淆矩阵来描述测试数据的k = 8位的MC-SVM和MC-HF-SVM的分类结果,其中还给出了总体准确性,召回率和精度的估计值 。 每个类别评估了789个测试样本,样本数量大致相等。 两种混淆矩阵都显示相似的输出,但走下楼和走上楼的活动的分类精度略有不同。 他们还暴露了一些主要在动态活动中的错误预测。 相反,静态活动的性能更好,特别是laying活动的精度为100%。
5 Conclusions
在本文中,我们提出了一种使用整数参数构建多类SVM的新方法。 MC-HF-SVM是用于医疗应用程序的AmI系统中的一种有吸引力的方法,例如智能手机上的活动监视。 这种采用定点计算的方法可以用于AR,因为它需要更少的内存,处理器时间和功耗。而且,它提供的精度水平可与传统方法(例如使用点算法的MC-SVM)相媲美。
实验结果证明,即使减少了等于6的位来表示学习到的MC-HF-SVM模型参数,也可以替代标准MC-SVM。 这一结果为智能手机带来了积极的影响,因为它可以帮助释放系统资源并减少能耗。 未来的工作将展示一个可公开获得的AR数据集,以允许其他研究人员测试和比较不同的学习模型。
**Acknowledgments.**这项工作得到了Erasmus Mundus互动和认知环境联合博士学位的部分支持,该博士学位由欧洲委员会EACEA机构根据EMJD ICE FPA n 2010-0012资助。