论文笔记(三):Multi-Label Balancing with Selective Learning for Attribute Prediction
AAAI2018的一篇文章,基于Multi-task的人脸属性识别,解决不平衡样本问题。
论文下载:
https://github.com/JackwithWilshere/Facial_Attributes_Papers/blob/master/07_AAAI2018_SelectiveLearning.pdf

1.Motivation
(1)只有一个大规模数据集,即CelebA
(2)数据集中大部分是名人图片
(3)因为(2),很难泛化
(4)普通的解决数据不平衡的方法在MTL中不适用
2.Contribution
针对1-(1),贡献了UMD-AED(University of Maryland Attribute EvaluationDataset)
针对1-(2)~(4),提出了AttCNN网络和Selective Learning 方法
3.Model---AttCNN

4.Method
(1)Selective Learning(选择学习)
处理不平衡数据
Saparate model(单模型):Sample the data(Pytorch里有取样的实现)
解释一下就是,比如一个batch有100个样本,保证每次正负样本各取50个即可。
Multi-task model(多任务学习模型):上述方法无效,比如第一个属性(比如性别)你满足上面各取五十个了(即男女各五十个),但是第二个属性(比如涂口红)并不一定各有50个,对应到celebA的40个属性就更难以平衡了。
所以作者提出了Selective Learning的方法。Selective Learning是在每个batch中,根据每个属性标签的目标分布,自适应的平衡每个标签。
(2)Batch Balancing(批平衡)
1)Three cases(三种情况)
a) the batch distribution is equal to the target distribution(批分布和目标分别相同)
b) the label is over-represented(标签过表示,即正样本过多)
c) the label is under-represented(标签欠表示,即负样本过多)
2)解决方案:利用SL(Selective Learning)把原来不平衡的batch 构建为新的平衡的SL batch
a) Equal(批分布和目标分别相同)
什么都不做,SL batch和标签最初的batch相同
b) over-represented(标签过表示,即正样本过多,负样本过少)
SL batch 包含正样本的子集和加权的负样本
具体来说,对于一个batch的正样本,根据目标分布随机取正样本的子集,添加它们到SL batch里,忽略其余的正样本。
对于负样本,加权负样本,以匹配目标分布。
举个例子,batch size=100,对于某个batch,某个label,正样本=70,负样本=30,我们随机选取70个正样本的50个作为新的SL batch的正样本,忽略另外20个正样本;然后30个负样本,乘以权重系数5/3,作为SL batch的负样本,那么SL batch 就是该label的一个平衡的batch。
c) under-represented(标签欠表示,即正样本过少,负样本过多)
和b)类似,SL batch 包含负样本的子集和加权的正样本
(3)可视化SL
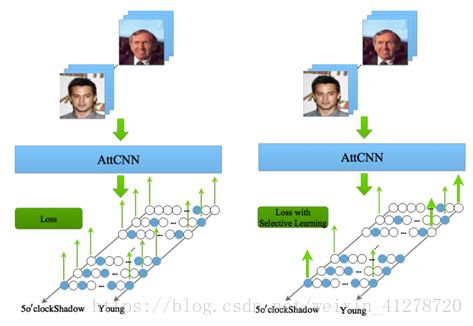
其中,
蓝色结点:正样本
白色结点:负样本
蓝色箭头:BP error
5.Datasets

(1)CelebA Dataset
40 different attributes
200,000 images
160,000 for training
20,000 for validation
20,000 for testing.
mostly frontal , posed images ofcelebrities.
(2)LFWA Dataset
40 different attributes
13,143 images
6,263 for training
6,880 for testing.
images of celebrities
(3)UMD-AED
2800 face images,
each labeled with a subset of the 40attributes
each attribute has the same number ofpositive and negative samples
every attribute has 50 positive and 50negative samples
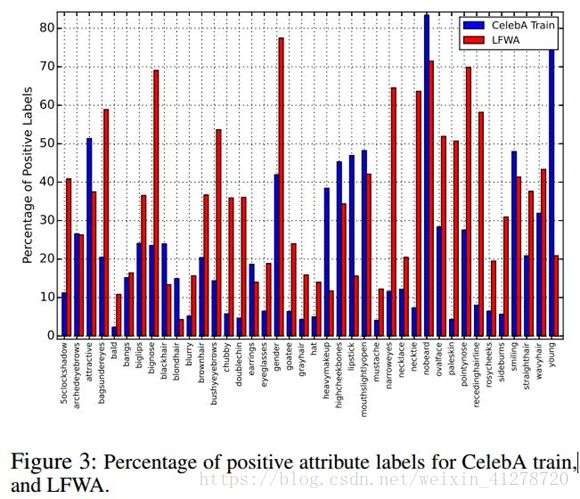
CelebA和LFWA的不平衡效果
6. Experiments
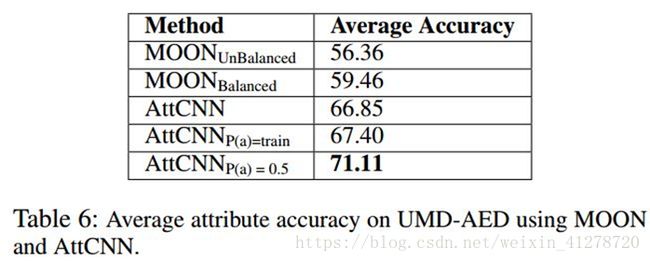
(1)AttCNN的有效性

无预训练
随机初始化
不到600万的参数
而MOON的参数1.38亿
(2) SL的有效性
a) MOON效果稍好,作者认为是CelebA 数据的不平衡对MOON有加成,因为MOON参数多和预训练,并没有因为Balanced而完全移除这一效果
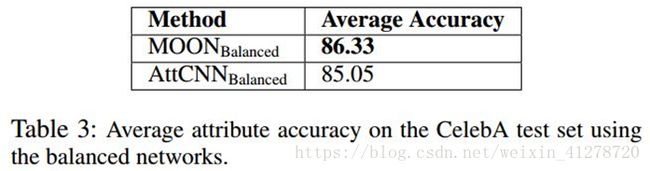
b) 效果的提升显示了batch 标签平衡的重要性,分布变化一点,效果就有很大的变化。
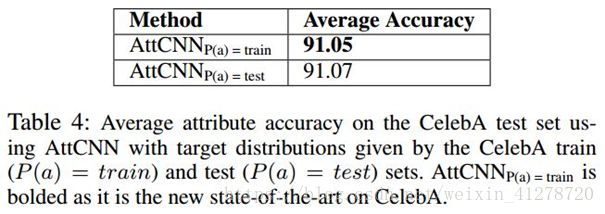
也可以得出CelebA数据从训练集、验证集到测试集都不平衡。
c) 同a)相似,作者认为LFWA 数据的不平衡对MOON有副作用


d)平衡的数据集可以获得真实世界图片的更好表达,SL可以处理多标签数据不平衡的问题

7.Conclusion
问题:不平衡数据
目标:让深度网络学习数据的真实表示,而不是训练集的偏差表示
模型:AttCNN
方法:Selective Learning
新数据集:UMD-AED
SL根据目标分布,调整每个属性的每个batch,以获得平衡的SL batch。