猫狗分类器--特征提取与微调
猫与狗图像分类
Exercise 3: 特征提取与微调
Estimated completion time: 30 minutes
在练习1中,我们从头开始构建了一个convnet,并且能够达到约70%的准确度。 随着练习2中数据增加和丢失的增加,我们能够将准确度提高到大约80%。 这似乎不错,但20%仍然是错误率太高。 也许我们没有足够的训练数据来妥善解决问题。 我们还可以尝试哪些其他方法?
在本练习中,我们将介绍两种技术,用于重新利用已经在大型数据集上训练的图像模型生成的特征数据,特征提取和微调,并使用它们来改进 我们的猫与狗分类模型的准确性。
使用预训练模型进行特征提取
通常在计算机视觉中完成的一件事是采用在非常大的数据集上训练的模型,在您自己的较小数据集上运行它,并提取模型生成的中间表示(特征)。这些表示通常为您自己的计算机视觉任务提供信息,即使该任务可能与原始模型训练的问题完全不同。这种多功能性和可重复使用性是深度学习中最有趣的方面之一。
在我们的案例中,我们将使用在谷歌开发的[Inception V3模型](https://arxiv.org/abs/1512.00567),并在[ImageNet]上预先培训(http://image-net.org/) ,一个大型的网络图像数据集(1.4M图像和1000个类)。这是一个强大的模型;让我们看看它学到的功能可以为我们的猫与狗问题做些什么。
首先,我们需要选择我们将用于特征提取的Inception V3的中间层。通常的做法是在“Flatten”操作之前使用最后一层的输出,即所谓的“瓶颈层”。这里的理由是,以下完全连接的层对于网络训练的任务而言过于专业化,因此这些层学到的特征对于新任务将不是非常有用。然而,瓶颈特征保持了很多普遍性。
让我们实例化一个预先加载了在ImageNet上训练的权重的Inception V3模型:
import os
from tensorflow.keras import layers
from tensorflow.keras import Model
下载权重:
!wget --no-check-certificate \
https://storage.googleapis.com/mledu-datasets/inception_v3_weights_tf_dim_ordering_tf_kernels_notop.h5 \
-O /tmp/inception_v3_weights_tf_dim_ordering_tf_kernels_notop.h5
from tensorflow.keras.applications.inception_v3 import InceptionV3
local_weights_file = '/tmp/inception_v3_weights_tf_dim_ordering_tf_kernels_notop.h5'
pre_trained_model = InceptionV3(
input_shape=(150, 150, 3), include_top=False, weights=None)
pre_trained_model.load_weights(local_weights_file)
通过指定include_top = False参数,我们加载一个网络,该网络不包括最适合特征提取的分类层。
让我们使模型不可训练,因为我们只会将它用于特征提取; 我们不会在训练期间更新预训练模型的权重。
for layer in pre_trained_model.layers:
layer.trainable = False
我们将在Inception v3中用于特征提取的层称为“mixed7”。 它不是网络的瓶颈,但我们正在使用它来保留足够大的特征映射(在这种情况下为7x7)。 (使用瓶颈层会产生3x3的特征映射,这有点小。)让我们从mixed7获得输出:
last_layer = pre_trained_model.get_layer('mixed7')
print 'last layer output shape:', last_layer.output_shape
last_output = last_layer.output
![]()
现在让我们在last_output之上添加一个完全连接的分类器:
from tensorflow.keras.optimizers import RMSprop
# Flatten the output layer to 1 dimension
x = layers.Flatten()(last_output)
# Add a fully connected layer with 1,024 hidden units and ReLU activation
x = layers.Dense(1024, activation='relu')(x)
# Add a dropout rate of 0.2
x = layers.Dropout(0.2)(x)
# Add a final sigmoid layer for classification
x = layers.Dense(1, activation='sigmoid')(x)
# Configure and compile the model
model = Model(pre_trained_model.input, x)
model.compile(loss='binary_crossentropy',
optimizer=RMSprop(lr=0.0001),
metrics=['acc'])
对于示例和数据预处理,让我们使用与练习2中相同的文件和train_generator。
注意:本练习中使用的2,000张图片摘自Kaggle提供的[“Dogs vs. Cats”数据集](https://www.kaggle.com/c/dogs-vs-cats/data) ,其中包含25,000张图片。 在这里,我们使用完整数据集的子集来减少用于教育目的的培训时间。
!wget --no-check-certificate \
https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip -O \
/tmp/cats_and_dogs_filtered.zip
import os
import zipfile
from tensorflow.keras.preprocessing.image import ImageDataGenerator
local_zip = '/tmp/cats_and_dogs_filtered.zip'
zip_ref = zipfile.ZipFile(local_zip, 'r')
zip_ref.extractall('/tmp')
zip_ref.close()
# Define our example directories and files
base_dir = '/tmp/cats_and_dogs_filtered'
train_dir = os.path.join(base_dir, 'train')
validation_dir = os.path.join(base_dir, 'validation')
# Directory with our training cat pictures
train_cats_dir = os.path.join(train_dir, 'cats')
# Directory with our training dog pictures
train_dogs_dir = os.path.join(train_dir, 'dogs')
# Directory with our validation cat pictures
validation_cats_dir = os.path.join(validation_dir, 'cats')
# Directory with our validation dog pictures
validation_dogs_dir = os.path.join(validation_dir, 'dogs')
train_cat_fnames = os.listdir(train_cats_dir)
train_dog_fnames = os.listdir(train_dogs_dir)
# Add our data-augmentation parameters to ImageDataGenerator
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
# Note that the validation data should not be augmented!
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
train_dir, # This is the source directory for training images
target_size=(150, 150), # All images will be resized to 150x150
batch_size=20,
# Since we use binary_crossentropy loss, we need binary labels
class_mode='binary')
# Flow validation images in batches of 20 using test_datagen generator
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')
最后,让我们使用我们提取的特征训练模型。 我们将对所有2000个可用图像进行训练,包括2个时期,并对所有1,000个测试图像进行验证。
history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=2,
validation_data=validation_generator,
validation_steps=50,
verbose=2)

您可以看到我们很快就达到了88-90%的验证准确度。这比我们从头开始训练的小型模型要好得多。
通过微调进一步提高精度
在我们的特征提取实验中,我们只尝试在Inception V3层之上添加两个分类层。训练期间未更新预训练网络的权重。进一步提高性能的一种方法是在训练顶级分类器的同时“微调”预训练模型的顶层的权重。关于微调的几个重要说明:
- 只有在训练了顶级分类器并将预训练模型设置为不可训练之后,才应尝试进行微调。如果在预训练模型上添加随机初始化分类器并尝试联合训练所有图层,则渐变更新的幅度将太大(由于分类器的随机权重),并且您的预训练模型将忘记一切它已经学会了。
- 另外,我们只调整预训练模型的顶层而不是预训练模型的所有层,因为在一个预测中,层越高,它就越专业化。回旋网中的前几层学习非常简单和通用的功能,这些功能可以推广到几乎所有类型的图像。但随着您越来越高,这些功能越来越特定于模型所训练的数据集。微调的目标是使这些专用功能适应新数据集。
我们需要做的就是实现微调,就是将Inception V3的顶层设置为可训练,重新编译模型(这些更改生效所必需的),然后恢复训练。让我们解冻属于mixed7模块的所有层 - 即,在mixed6之后找到的所有层 - 并重新编译模型:
from tensorflow.keras.optimizers import SGD
unfreeze = False
# Unfreeze all models after "mixed6"
for layer in pre_trained_model.layers:
if unfreeze:
layer.trainable = True
if layer.name == 'mixed6':
unfreeze = True
# As an optimizer, here we will use SGD
# with a very low learning rate (0.00001)
model.compile(loss='binary_crossentropy',
optimizer=SGD(
lr=0.00001,
momentum=0.9),
metrics=['acc'])
现在让我们重新训练模型。 我们将对所有2000个可用图像进行训练,包括50个时期,并对所有1,000个测试图像进行验证。 (这可能需要15-20分钟才能运行。)
history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=50,
validation_data=validation_generator,
validation_steps=50,
verbose=2)

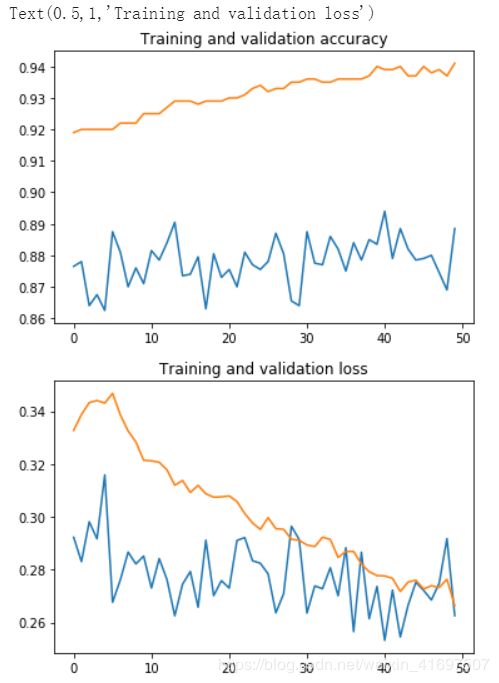
我们看到了一个很好的改进,验证损失从1.7下降到1.2,准确度从88%上升到92%。 这相对准确度提高了4.5%。
让我们绘制培训和验证损失和准确性,以最终显示:
%matplotlib inline
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
# Retrieve a list of accuracy results on training and test data
# sets for each training epoch
acc = history.history['acc']
val_acc = history.history['val_acc']
# Retrieve a list of list results on training and test data
# sets for each training epoch
loss = history.history['loss']
val_loss = history.history['val_loss']
# Get number of epochs
epochs = range(len(acc))
# Plot training and validation accuracy per epoch
plt.plot(epochs, acc)
plt.plot(epochs, val_acc)
plt.title('Training and validation accuracy')
plt.figure()
# Plot training and validation loss per epoch
plt.plot(epochs, loss)
plt.plot(epochs, val_loss)
plt.title('Training and validation loss')
祝贺! 使用特征提取和微调,您已经构建了一个图像分类模型,可以识别图像中的猫与狗,准确率超过90%。
清理
运行以下单元格以终止内核并释放内存资源:
import os, signal
os.kill(os.getpid(), signal.SIGKILL)、