CornerNet网络结构超详细解读
这两天看了一下CornerNet,一开始没太搞懂这个结构,作者的代码也没注释,网上查了一下都没什么详细讲解网络结构的博客和帖子。看了我一天,根据论文和代码搞懂了,写一篇博客记录一下。
论文链接:https://eccv2018.org/openaccess/content_ECCV_2018/papers/Hei_Law_CornerNet_Detecting_Objects_ECCV_2018_paper.pdf
代码链接:https://github.com/princeton-vl/CornerNet 有一说一,作者的代码写的是真的难看。
首先上整体结构图
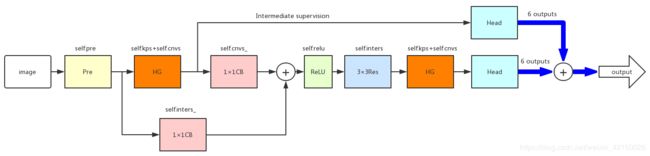
然后根据论文和代码逐步解释各个部分
主要结构的代码都在CornerNet-master\models\py_utils\kp.py 中,其中 _train(self,*xs) 函数详细说明了整个流程
(1)图像预处理
首先论文中说图像先经过了预处理:

这对应了结构图中的Pre模块
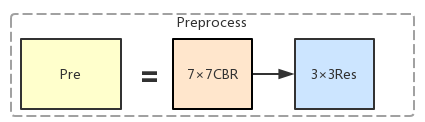
其中的CBR代表Convolution+BatchNormalization+ReLU, CBR模块对应的程序的 class convolution, 路径在\CornerNet-master\models\py_utils\utils.py 中

之后的Res代表Residual模块。上述同一个utils.py钟的 class residual 中
具体结构为:

其中CB模块代表Convolution+BatchNormalization, 没有ReLU,即

以上就是图像的预处理,并且同时介绍了CBR和Res两个模块
(2)Hourglass模块与Intermediate supervision
HourglassNet的论文链接:
https://arxiv.org/pdf/1603.06937.pdf
根据CornerNet的程序,CornerNet中的Hourglass模块为:

它由\CornerNet-master\models\py_utils\kp.py中的self.kps和self.cnvs组成。3×3CBR就是self.cnvs,
self.kps是Hourglass的主体部分。详细结构见程序中的kp_module部分。这里不展开讲了。
CornerNet中作者仿照HourglassNet中那样,采用了Intermediate supervision。
CornerNet的作者在文章中说用了2个Hourglass模块。

Intermediate supervision就是要在两个Hourglass模块中间引出一个支路来和后面的加在一起计算loss。
其中关于Intermediate supervision, 在HourglassNet的文章中作者是这样说的:

文中说了The key to this approach is the prediction of intermediate heatmaps upon which we
can apply a loss. 就是说,这个方法的关键是the prediction of intermediate heatmaps 能够被计算loss。
那么在CornerNet中,要使得Hourglass模块的输出能够被计算loss,能够被和最后的输出加在一起的话,就要给中间的Hourglass的输出加上一个Head。Head的结构作者在文章中有详细给出:
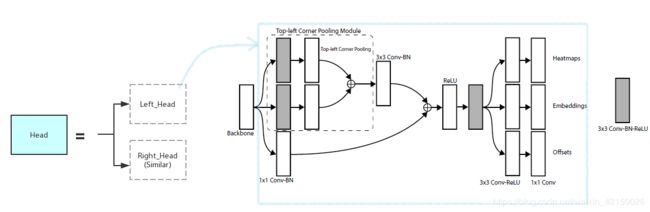
因此,作者用了2个Hourglass模块的话,整个CornerNet网络是有2个Head模块的,这一点,作者在论文中没有详细指出来,这是使得这整个CornerNet结构很迷,使得代码很难理解的关键。
关于两个Hourglass模块之间怎么连接,作者倒是讲的很详细

就是对应图中的这部分:
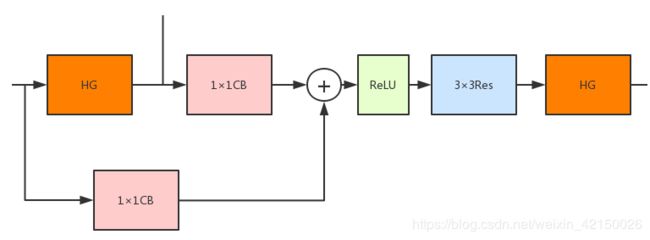
在第一个Hourglass模块的前后加了1×1的卷积,然后element-wise add,然后通过ReLU和Residual模块,再送入第二个Hourglass模块。
程序中对于这个Intermediate supervision的结构,是采用for循环的方式写的。乍一看会有点懵逼。
下面给出代码的具体解读(注释):
class kp(nn.Module):
def __init__(
self, n, nstack, dims, modules, out_dim, pre=None, cnv_dim=256,
make_tl_layer=make_tl_layer, make_br_layer=make_br_layer,
make_cnv_layer=make_cnv_layer, make_heat_layer=make_kp_layer,
make_tag_layer=make_kp_layer, make_regr_layer=make_kp_layer,
make_up_layer=make_layer, make_low_layer=make_layer,
make_hg_layer=make_layer, make_hg_layer_revr=make_layer_revr,
make_pool_layer=make_pool_layer, make_unpool_layer=make_unpool_layer,
make_merge_layer=make_merge_layer, make_inter_layer=make_inter_layer,
kp_layer=residual
):
super(kp, self).__init__()
self.nstack = nstack # 指定了Hourglass模块的个数,文章中用了2个
self._decode = _decode
# decode就是网络输出了heatmap,embedding,offset后如何进行点匹配以及最终选择哪些点对作为结果的函数
curr_dim = dims[0]
self.pre = nn.Sequential(
convolution(7, 3, 128, stride=2), # 3 is input_channels
# 此时输出shape == (N,128,256,256), N==batch_size, 128==channels
residual(3, 128, 256, stride=2) # 此时输出shape==(N,256,128,128), 128×128,channels==256
) if pre is None else pre
# self.pre定义的是网络的头部,网络先接了一个kernel size 7x7的conv以及一个residual结构
# convolution的定义:def __init__(self, k, inp_dim, out_dim, stride=1, with_bn=True):
self.kps = nn.ModuleList([
kp_module(
n, dims, modules, layer=kp_layer,
make_up_layer=make_up_layer,
make_low_layer=make_low_layer,
make_hg_layer=make_hg_layer,
make_hg_layer_revr=make_hg_layer_revr,
make_pool_layer=make_pool_layer,
make_unpool_layer=make_unpool_layer,
make_merge_layer=make_merge_layer
) for _ in range(nstack)
])
# CornerNet的主干结构是hourglasses,上面是就是其主干结构,make_xx_layer都是定义
# 在kp_utils.py文件中的,感兴趣可以看一下,这里不详细介绍了,知道其实hourglasses主干结构就可以了。
# 并且注意,这里的定义都使用了for循环 for _ in range(nstack),
# 就是作者文中说的CornerNet的backbone用了两个Hourglass模块
# 两个模块之间通过前面提到的中继监督(intermediate supervision)连接到一起。
# 注释来自https://blog.csdn.net/Chunfengyanyulove/article/details/94646724
self.cnvs = nn.ModuleList([
make_cnv_layer(curr_dim, cnv_dim) for _ in range(nstack)
])
# hourglasses输出后,接一个卷积层,
# def make_cnv_layer(inp_dim, out_dim):
# return convolution(3, inp_dim, out_dim)
# kernel_size == (3,3), strides 缺省,为 1,BN缺省,为True
self.tl_cnvs = nn.ModuleList([
make_tl_layer(cnv_dim) for _ in range(nstack)
])
# def make_tl_layer(dim):
# return None
self.br_cnvs = nn.ModuleList([
make_br_layer(cnv_dim) for _ in range(nstack)
])
## keypoint heatmaps
self.tl_heats = nn.ModuleList([
make_heat_layer(cnv_dim, curr_dim, out_dim) for _ in range(nstack)
])
self.br_heats = nn.ModuleList([
make_heat_layer(cnv_dim, curr_dim, out_dim) for _ in range(nstack)
])
# make_heat_layer 被赋值为 make_kp_layer,
# def make_kp_layer(cnv_dim, curr_dim, out_dim):
# return nn.Sequential(
# convolution(3, cnv_dim, curr_dim, with_bn=False), # kernel_size == (3,3) strides 缺省,为1
# nn.Conv2d(curr_dim, out_dim, (1, 1)), # kernel_size == (1,1) ,strides 缺省,为1
# )
## tags, 即文章中说的embedding
self.tl_tags = nn.ModuleList([
make_tag_layer(cnv_dim, curr_dim, 1) for _ in range(nstack)
])
self.br_tags = nn.ModuleList([
make_tag_layer(cnv_dim, curr_dim, 1) for _ in range(nstack)
])
# make_tag_layer 被赋值为 make_kp_layer,
# def make_kp_layer(cnv_dim, curr_dim, out_dim):
# return nn.Sequential(
# convolution(3, cnv_dim, curr_dim, with_bn=False), # kernel_size == (3,3) strides 缺省,为1
# nn.Conv2d(curr_dim, out_dim, (1, 1)), # kernel_size == (1,1) ,strides 缺省,为1
# )
for tl_heat, br_heat in zip(self.tl_heats, self.br_heats):
tl_heat[-1].bias.data.fill_(-2.19)
br_heat[-1].bias.data.fill_(-2.19)
## 下面这3个是中继结构,即将输出再接入下一个输入,后面的train以及test函数中会用到。
self.inters = nn.ModuleList([
make_inter_layer(curr_dim) for _ in range(nstack - 1)
])
# def make_inter_layer(dim):
# return residual(3, dim, dim) kernel_size == (3,3)
# class residual 的构造函数为def __init__(self, k, inp_dim, out_dim, stride=1, with_bn=True):
#
self.inters_ = nn.ModuleList([
nn.Sequential(
nn.Conv2d(curr_dim, curr_dim, (1, 1), bias=False), #kernel_size == (1,1), strides缺省,默认为1
nn.BatchNorm2d(curr_dim)
) for _ in range(nstack - 1)
])
self.cnvs_ = nn.ModuleList([
nn.Sequential(
nn.Conv2d(cnv_dim, curr_dim, (1, 1), bias=False),
nn.BatchNorm2d(curr_dim)
) for _ in range(nstack - 1)
])
### 下面2个定义的是输出的回归坐标 : 2 * 256 * 256
self.tl_regrs = nn.ModuleList([
make_regr_layer(cnv_dim, curr_dim, 2) for _ in range(nstack)
])
self.br_regrs = nn.ModuleList([
make_regr_layer(cnv_dim, curr_dim, 2) for _ in range(nstack)
])
# make_regr_layer 被赋值为 make_kp_layer,
# def make_kp_layer(cnv_dim, curr_dim, out_dim):
# return nn.Sequential(
# convolution(3, cnv_dim, curr_dim, with_bn=False), # kernel_size == (3,3) strides 缺省,为1
# nn.Conv2d(curr_dim, out_dim, (1, 1)), # kernel_size == (1,1) ,strides 缺省,为1
# )
self.relu = nn.ReLU(inplace=True)
def _train(self, *xs): # 输入参数写为*xs, 表示xs可以接受不定长的tuple输入
image = xs[0]
tl_inds = xs[1]
br_inds = xs[2]
inter = self.pre(image) # pre是对图像的预处理(经过了卷积和residual模块)
outs = []
layers = zip(
self.kps, self.cnvs,
self.tl_cnvs, self.br_cnvs,
self.tl_heats, self.br_heats,
self.tl_tags, self.br_tags,
self.tl_regrs, self.br_regrs
) # zip 返回的是一个的列表,列表中的元素是tuple,列表的长度和被打包的东西中最短的那个长度相同
# 由几个对象被打包,每个tuple 就有几个元素,i.e.,第0个tuple包含各对象的第0个元素,
for ind, layer in enumerate(layers): # 但其实,在此处layers中的两个layer是一样的
kp_, cnv_ = layer[0:2]
tl_cnv_, br_cnv_ = layer[2:4]
tl_heat_, br_heat_ = layer[4:6]
tl_tag_, br_tag_ = layer[6:8]
tl_regr_, br_regr_ = layer[8:10]
kp = kp_(inter) # kp 是沙漏部分
cnv = cnv_(kp)
tl_cnv = tl_cnv_(cnv)
br_cnv = br_cnv_(cnv)
tl_heat, br_heat = tl_heat_(tl_cnv), br_heat_(br_cnv)
tl_tag, br_tag = tl_tag_(tl_cnv), br_tag_(br_cnv)
tl_regr, br_regr = tl_regr_(tl_cnv), br_regr_(br_cnv)
tl_tag = _tranpose_and_gather_feat(tl_tag, tl_inds)
br_tag = _tranpose_and_gather_feat(br_tag, br_inds)
tl_regr = _tranpose_and_gather_feat(tl_regr, tl_inds)
br_regr = _tranpose_and_gather_feat(br_regr, br_inds)
outs += [tl_heat, br_heat, tl_tag, br_tag, tl_regr, br_regr]
if ind < self.nstack - 1:
inter = self.inters_[ind](inter) + self.cnvs_[ind](cnv)
inter = self.relu(inter)
inter = self.inters[ind](inter)
##当nstack==2时,上面if中的部分只执行一次,就是论文中情形
# 程序中为了扩展到多个Hourglass模块,所以用循环来写。
# 其实self.inters_与self.cnvs_的结构是一样的,都是卷积层
return outs
如上,采用for循环是因为程序为了能够扩展到多个Hourglass模块的情况,然后作者在代码中把head的结构也复制了n份,这是因为在CornerNet的intermediate supervision中,要从中间的Hourglass引出loss,需要给他套上一个head,这一点是关键,在前文已经说明过。
(3) Head 结构
对于Head结构中的最后三个分支输出部分,对照结构图和代码,其中tl_heat,应该是指heat map; tl_tag应该是指embedding部分,tl_regr应该是指offset部分,这个命名很奇怪,为什么会用regression的缩写regr ???。这三部分对应的网络结构很好找,都被赋值为了 make_kp_layer,定义见\CornerNet-master\models\py_utils\kp_utils.py 中:
def make_kp_layer(cnv_dim, curr_dim, out_dim):
return nn.Sequential(
convolution(3, cnv_dim, curr_dim, with_bn=False),
nn.Conv2d(curr_dim, out_dim, (1, 1))
)上面的这部分对应了Head结构图中的最后三个分支输出(以left top为例)。对于Head的前面部分,在程序中可以看到是make_tl_layer,但是在kp_utils.py 中去找make_tl_layer的定义,却发现返回的是None。并没有详细讲Head的前面部分的结构。这是因为,在class kp 的构造函数__ini__中,首先给了一堆参数的缺省值,这些缺省值是通过from .kp.utils import 进来的。kp_utils.py中def make_tl_layer return None。这说明make_tl_layer的缺省值是None. 真正在用class kp的时候,对__ini__传进去的是哪些参数,是要在\CornerNet-master\models\CornerNet.py中看,在此处有对make_tl_layer的定义,再逐步跟进。具体程序为:
def make_tl_layer(dim):
return tl_pool(dim)class tl_pool(pool):
def __init__(self, dim):
super(tl_pool, self).__init__(dim, TopPool, LeftPool)class pool(nn.Module):
def __init__(self, dim, pool1, pool2):
super(pool, self).__init__()
self.p1_conv1 = convolution(3, dim, 128) # 自带BN和ReLU
self.p2_conv1 = convolution(3, dim, 128)
self.p_conv1 = nn.Conv2d(128, dim, (3, 3), padding=(1, 1), bias=False)
self.p_bn1 = nn.BatchNorm2d(dim)
self.conv1 = nn.Conv2d(dim, dim, (1, 1), bias=False)
self.bn1 = nn.BatchNorm2d(dim)
self.relu1 = nn.ReLU(inplace=True)
self.conv2 = convolution(3, dim, dim)
self.pool1 = pool1()
self.pool2 = pool2()
def forward(self, x):
# pool 1
p1_conv1 = self.p1_conv1(x) # 3×3conv + BN + ReLu
pool1 = self.pool1(p1_conv1) # pool1
# pool 2
p2_conv1 = self.p2_conv1(x) # 3×3conv + BN + ReLu
pool2 = self.pool2(p2_conv1)
# pool 1 + pool 2
p_conv1 = self.p_conv1(pool1 + pool2) # 3×3 conv
p_bn1 = self.p_bn1(p_conv1) # BN
conv1 = self.conv1(x) # 1×1conv
bn1 = self.bn1(conv1) # BN
relu1 = self.relu1(p_bn1 + bn1) # add + ReLU
conv2 = self.conv2(relu1) # 3×3conv + BN + ReLU
return conv2
以上这部分程序,和论文中对Head的描述,对应关系是这样的:
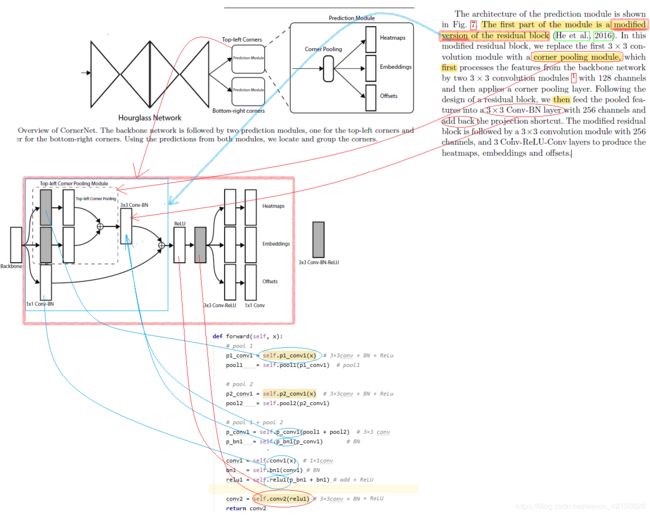
其中剩下没有被箭头指到的部分就是已经在kp_utils.py中给出定义的make_kp_layer. 即上文已经说过的Head的最后的三个分支的输出部分。
整个CornerNet完整的结构图:
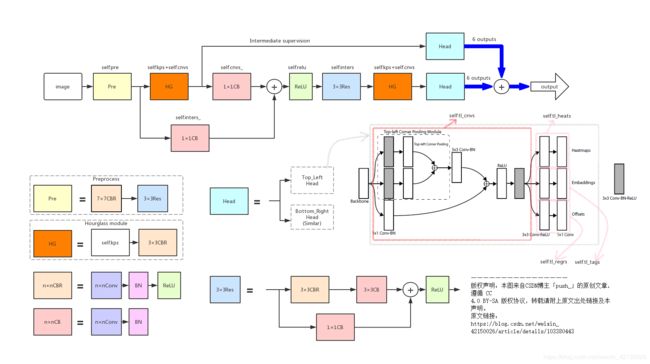
————————————————End————————————————————————————————————
参考文献https://blog.csdn.net/Chunfengyanyulove/article/details/94646724 , 在初次阅读代码的时候,参考了这个作者的这篇博客