基于Hadoop的WordCount案例实现(Linux版本)
读书无论资性高低,但能勤学好问,凡事思一个所以然,自有义理贯通之日
立身不嫌家世贫贱,但能忠厚老成,所行无一毫苟且处,便为乡党仰望之人
注意事项
- 本分布式集群包含3台虚拟机,操作系统均为Linux
- 本次使用的统计文本大小为4.32MB
- 若使用单台虚拟机,即伪分布式集群,或者分布式集群运算能力较弱,可以使用该4.32MB的文本
- 若想尝试大数据量运算,可将该文本进行自我复制到1GB大小,并以此产生多个副本
- 本分布式集群HDFS架构如下
| 节点 | 主机名 | NameNode | DataNode | Secondary NameNode | Resource Manager | Node Manager |
|---|---|---|---|---|---|---|
| 主节点 | master | √ | √ | √ | √ | |
| 从节点 | slave1 | √ | √ | √ | ||
| 从节点 | slave2 | √ | √ |
准备工作
统计文本
该统计文本大小为4.32MB,也可使用自己生成的统计文本 提取码w3ci
软件
- Xftp (类似的SFTP、FTP文件传输软件均可,如国产的FinalShell)
- Xshell (类似的安全终端模拟软件均可,如SecureCRT)
- Xftp以及Xshell均包含在Xmanager软件产品中 提取码7r9h
- SecureCRT 提取码fcjd
- Xshell以及SecureCRT下载一个即可,建议下载Xshell
具体步骤
注意:以下操作均在主节点虚拟机(master)上执行,无需在各虚拟机均执行
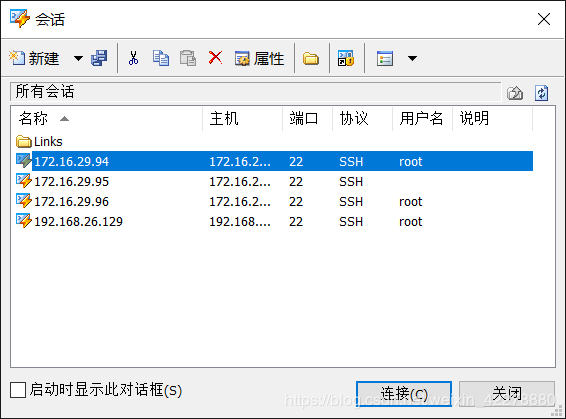
使用Xsehll连接虚拟机
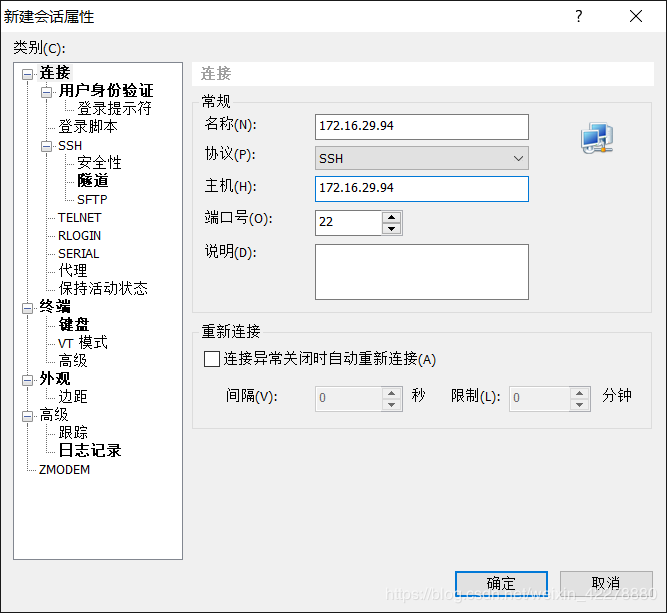
- 点击“文件”→“新建”
- 填写“名称”和“主机”,“主机”为IP地址,“名称”尽量填写IP地址,点击“确定”
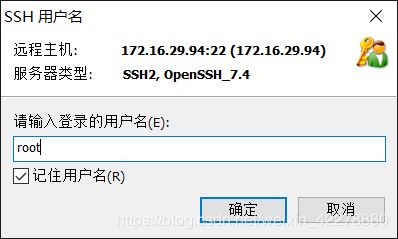
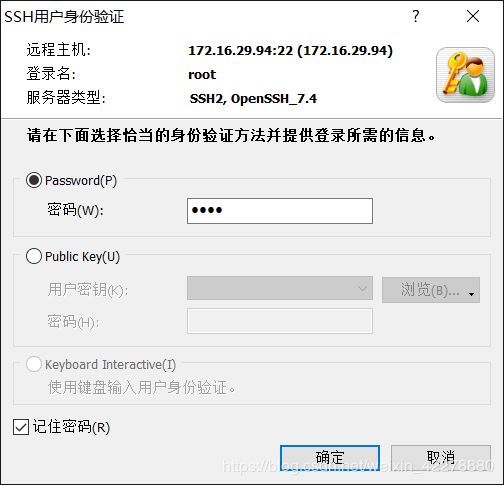
- 在会话中选择“172.16.29.94”,点击“连接”,依次输入“用户名”和“密码”,“用户名”和“密码”为登录该虚拟机的用户名和密码,最后点击“确定”
 在Xshell显示界面显示如下信息即为连接成功
在Xshell显示界面显示如下信息即为连接成功
Connecting to 172.16.29.94:22…
Connection established.
To escape to local shell, press ‘Ctrl+Alt+]’.
Last login: Wed Oct 9 12:07:14 2019 from 172.28.54.186
[root@master ~]#
其中[root@master~]中的master为该虚拟机的主机名,即hostname,每台虚拟机可能会不一样
创建本地存放文件目录
- 输入命令
cd /hadoop/,进入/hadoop目录
([root@master~]# cd /hadoop/) - 输入命令
mkdir localfile,创建本地存放统计文件的目录
([root@master~]# mkdir localfile) - 输入命令
cd localfile,进入localfile目录
使用Xftp导入统计文本
- 打开Xftp,点击“文件”→“新建”
- 填写“名称”、“主机”、“用户名”和“密码”,“主机”填写IP地址,名称尽量填写IP地址,“用户名”和“密码”为登录该虚拟机的用户名和密码
- “协议”更改为“SFTP”
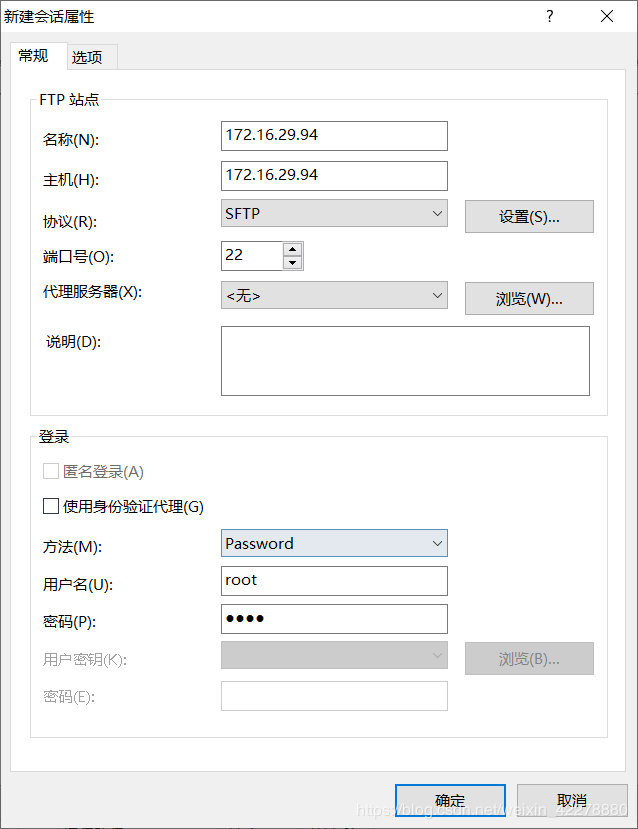
- 点击“选项”,勾选“使用UTF-8”编码,点击“确定”,否则连接时虚拟机中的文件名称会产生乱码
- 选择名称为“172.16.29.94”的会话,点击“连接”
- 在虚拟机地址栏输入
/hadoop/localfile,进入该目录 - 将本地统计文件拖拽到虚拟机localfile目录下

传输完成如下

- 在Xshell中输入命令
ll,显示信息如下
([root@master localfile]# ll)
总用量 4436
-rw-r–r-- 1 root root 4538523 10月 9 12:20 data.txt
在HDFS文件系统中创建统计文本数据输入目录
当前目录为localfile时,输入命令hadoop fs -mkdir /input创建统计文本数据输入目录
([root@master localfile]# hadoop fs -mkdir /input)
向输入目录传输统计文本
当前目录为localfile时,输入命令hadoop fs -put data.txt /input,向/input目录传输data.txt文件(该文件名以自己的统计文本名为准)
([root@master localfile]# hadoop fs -put data.txt /input)
传输完成后,输入命令hadoop fs -ls /input,若出现如下信息,则文件传输成功
([root@master localfile]# hadoop fs -ls /input)
Found 1 items
-rw-r–r-- 3 root supergroup 4538523 2019-10-09 12:38 /input/data.txt
使用Hadoop自带的MapReduce编程模型进行统计运算
- 输入命令
cd ~,进入根目录 - 输入命令
cd /hadoop/hadoop-2.7.7/share/hadoop/mapreduce/,进入mapreduce目录
(`[root@master ~]# cd /hadoop/hadoop-2.7.7/share/hadoop/mapreduce/``) - 输入命令
hadoop jar hadoop-mapreduce-examples-2.7.7.jar wordcount /input /output进行统计运算
([root@master mapreduce]# hadoop jar hadoop-mapreduce-examples-2.7.7.jar wordcount /input /output)
19/10/09 12:47:55 INFO client.RMProxy: Connecting to ResourceManager at master/172.16.29.94:8032
19/10/09 12:47:56 INFO input.FileInputFormat: Total input paths to process : 1
19/10/09 12:47:56 INFO mapreduce.JobSubmitter: number of splits:1
19/10/09 12:47:56 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1569750862651_0004
19/10/09 12:47:56 INFO impl.YarnClientImpl: Submitted application application_1569750862651_0004
19/10/09 12:47:56 INFO mapreduce.Job: The url to track the job: http://master:8088/proxy/application_1569750862651_0004/
19/10/09 12:47:56 INFO mapreduce.Job: Running job: job_1569750862651_0004
19/10/09 12:48:01 INFO mapreduce.Job: Job job_1569750862651_0004 running in uber mode : false
19/10/09 12:48:01 INFO mapreduce.Job: map 0% reduce 0%
19/10/09 12:48:07 INFO mapreduce.Job: map 100% reduce 0%
19/10/09 12:48:12 INFO mapreduce.Job: map 100% reduce 100%
19/10/09 12:48:12 INFO mapreduce.Job: Job job_1569750862651_0004 completed successfully
19/10/09 12:48:12 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=483860
(省略)
File Input Format Counters
Bytes Read=4538523
File Output Format Counters
Bytes Written=356409
注意:由于各个虚拟机版本不一致,hadoop-mapreduce-examples-2.7.7.jar需要根据自己虚拟机的mapreduce目录中的JAR包来写,可以在写hadoop-mapreduce-examples时使用Tab键自动补全,或者在mapreduce目录下使用ll命令查找虚拟机上自带的JAR包名,如下所示
[root@master mapreduce]# ll
总用量 4984
-rw-r–r-- 1 user ftp 540117 7月 19 2018 hadoop-mapreduce-client-app-2.7.7.jar
-rw-r–r-- 1 user ftp 773735 7月 19 2018 hadoop-mapreduce-client-common-2.7.7.jar
-rw-r–r-- 1 user ftp 1556812 7月 19 2018 hadoop-mapreduce-client-core-2.7.7.jar
-rw-r–r-- 1 user ftp 189951 7月 19 2018 hadoop-mapreduce-client-hs-2.7.7.jar
-rw-r–r-- 1 user ftp 27831 7月 19 2018 hadoop-mapreduce-client-hs-plugins-2.7.7.jar
-rw-r–r-- 1 user ftp 62388 7月 19 2018 hadoop-mapreduce-client-jobclient-2.7.7.jar
-rw-r–r-- 1 user ftp 1556921 7月 19 2018 hadoop-mapreduce-client-jobclient-2.7.7-tests.jar
-rw-r–r-- 1 user ftp 71617 7月 19 2018 hadoop-mapreduce-client-shuffle-2.7.7.jar
-rw-r–r-- 1 user ftp 296044 7月 19 2018 hadoop-mapreduce-examples-2.7.7.jar
drwxr-xr-x 2 user ftp 4096 7月 19 2018 lib
drwxr-xr-x 2 user ftp 30 7月 19 2018 lib-examples
drwxr-xr-x 2 user ftp 4096 7月 19 2018 sources
查看程序运行结果并导出文件
- 输入命令
cd ~,进入根目录 - 输入命令
hadoop fs -ls /output,显示如下信息
([root@master ~]# hadoop fs -ls /output)
其中output目录下的part-r-00000为统计结果
Found 2 items
-rw-r–r-- 3 root supergroup 0 2019-10-09 12:48 /output/_SUCCESS
-rw-r–r-- 3 root supergroup 356409 2019-10-09 12:48 /output/part-r-00000
- 输入命令
hadoop fs -get /output/part-r-00000 result.txt,将part-r-00000文件从HDFS复制到root目录中,重命名为result,文本格式为txt
([root@master ~]# hadoop fs -get /output/part-r-00000 result.txt) - 打开Xftp并连接到主节点虚拟机,进入根目录,将result.txt文件传输到本地
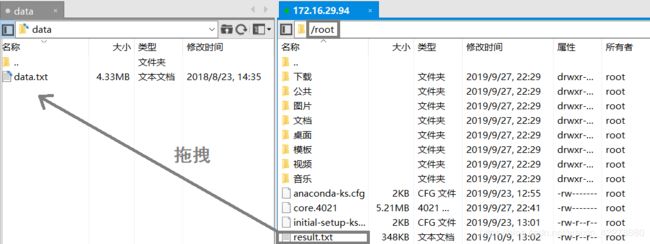
传输完成如下
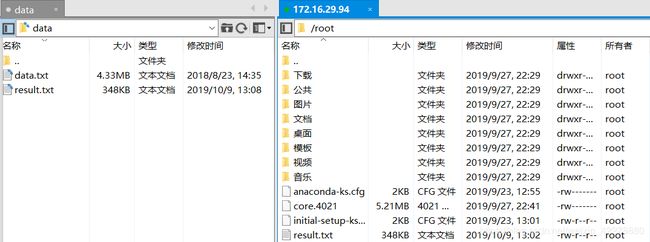
- 查看本地运行结果文件
打开result.txt,内容如下
! 10526
!’ 183
!'By 1
!'t 1
!'twas 1
!, 1
!About 1
(省略)
zodiac 1
zodiacs 1
zone 1
zur 2
zwaggered 1
删除HDFS中output目录中的内容
输入命令hadoop fs -rm -r /output,删除output目录,显示如下信息
19/10/09 13:20:46 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 0 minutes, Emptier interval = 0 minutes.
Deleted /output
输入命令hadoop fs -ls /output,若output目录删除成功则会显示如下信息
ls: `/output’: No such file or directory
若不删除该目录,程序会在下一次执行WordCount程序时报错
命令为[root@master mapreduce]# hadoop jar hadoop-mapreduce-examples-2.7.7.jar wordcount /input /output
错误内容如下
19/10/09 13:17:15 INFO client.RMProxy: Connecting to ResourceManager at master/172.16.29.94:8032
org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://master:9000/output already exists
at org.apache.hadoop.mapreduce.lib.output.FileOutputFormat.checkOutputSpecs(FileOutputFormat.java:146)
at org.apache.hadoop.mapreduce.JobSubmitter.checkSpecs(JobSubmitter.java:266)
at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:139)
(省略)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.util.RunJar.run(RunJar.java:226)
at org.apache.hadoop.util.RunJar.main(RunJar.java:141)
错误信息为output目录在HDFS中已存在
基于Hadoop的WordCount案例实现到此就告一段落
有疑问的朋友可以在下方留言或者私信我,我尽量尽早回答
欢迎各路大神指点、交流!
求关注!求点赞!求转发!