Java中个人疑问点总结
目录
1 Maven
1.1 问题
1.1.1 什么是classpath
1.1.2 Maven scope的配置项意义
1.1.3 Maven打包时Javadoc遇到的问题
1.1.4 Mvn打包跳过测试
2 Java
2.1 问题
2.1.1 Idea显示红色的J
2.1.2 什么是函数式编程、闭包、匿名函数
2.1.3 Java中的E、T、K、V、?和object
2.1.4 泛型的详细介绍
2.1.5 toString
2.1.6 Java中到底是传值还是传引用
2.1.7 抽象类
2.1.8 Super关键字
2.1.9 匿名函数与函数式接口
2.1.10 什么是Bean
2.2 Java API
2.2.1 asList
2.2.2 Java反射技术
2.2.3 Stream
2.2.4 Stream API学习
2.2.5 匿名函数(Java的lambda表达式)
2.2.6 CompareTo、Comparable、Comparator
2.2.7 Java中的?是什么
2.2.8 List的toArray接口
2.2.9 Extends和implements
3 Gradle
3.1 什么是gradle
3.2 Gradle使用中的问题
3.3 中文编码问题
3.4 JVM的远程调试
3.5 异步多线程调试
4 Java多线程编程
4.1 进程和线程
4.2 Run和start函数的区别
4.3 多线程的使用与主要概念
4.4 线程池
4.5 Callable
5 Java多态的回顾
5.1 重写
5.2 虚函数的例子解析
6 方法、静态方法、语言、静态语言
简单声明,这一篇仅仅是个人的云笔记,简单记录了之前自己遇到的一些Java问题。希望看到这篇笔记的读者可以直接退出,记得很杂乱,Java连皮毛都没学到,不喜勿喷。
1 Maven
1.1 问题
1.1.1 什么是classpath
顾名思义其即为class的path,就是类的路径。
在指定一些配置/资源文件的时候会使用到classpath。
1.1.2 Maven scope的配置项意义
- Compile
默认即为compile,compile表示被依赖项目需要参与当前项目的编译,当然后续的测试,运行周期也参与其中,是一个比较强的依赖。打包的时候通常需要包含进去。
- Provided
provided意味着打包的时候可以不用包进去,别的设施(Web Container)会提供。事实上该依赖理论上可以参与编译,测试,运行等周期。相当于compile,但是在打包阶段做了exclude
的动作。
1.1.3 Maven打包时Javadoc遇到的问题
Failed to execute goal org.apache.maven.plugins:maven-javadoc-plugin:3.0.1:jar (attach-javadocs) on project graph-algorithms-core: MavenReportException: Error while generating Javadoc:
修改方法如下:
org.apache.maven.plugins
maven-javadoc-plugin
3.0.1
attach-javadocs
jar
false
1.1.4 Mvn打包跳过测试
一 使用maven.test.skip,不但跳过单元测试的运行,也跳过测试代码的编译。
mvn package -Dmaven.test.skip=true
二 使用 mvn package -DskipTests 跳过单元测试,但是会继续编译;如果没时间修改单元测试的bug,或者单元测试编译错误。使用上面的,不要用这个
2 Java
2.1 问题
2.1.1 Idea显示红色的J
Idea显示红色的J而不是浅蓝色的C时,表示路径的设置存在问题,此时无法通过ctrl+B直接跳转,需要到File->Project Structure->modules->sources
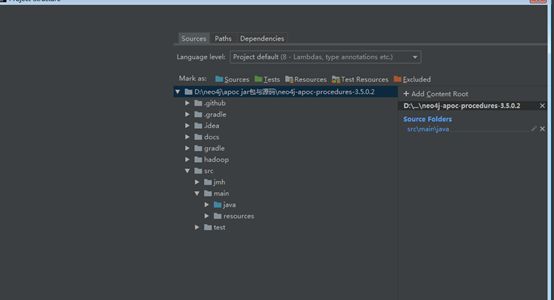
点击src/main/java右键勾选sources。
2.1.2 什么是函数式编程、闭包、匿名函数
而函数式编程(请注意多了一个“式”字)——Functional Programming,虽然也可以归结到面向过程的程序设计,但其思想更接近数学计算。
我们首先要搞明白计算机(Computer)和计算(Compute)的概念。
在计算机的层次上,CPU执行的是加减乘除的指令代码,以及各种条件判断和跳转指令,所以,汇编语言是最贴近计算机的语言。
而计算则指数学意义上的计算,越是抽象的计算,离计算机硬件越远。
对应到编程语言,就是越低级的语言,越贴近计算机,抽象程度低,执行效率高,比如C语言;越高级的语言,越贴近计算,抽象程度高,执行效率低,比如Lisp语言。
函数式编程就是一种抽象程度很高的编程范式,纯粹的函数式编程语言编写的函数没有变量,因此,任意一个函数,只要输入是确定的,输出就是确定的,这种纯函数我们称之为没有副作用。而允许使用变量的程序设计语言,由于函数内部的变量状态不确定,同样的输入,可能得到不同的输出,因此,这种函数是有副作用的。
函数式编程的一个特点就是,允许把函数本身作为参数传入另一个函数,还允许返回一个函数!
Python对函数式编程提供部分支持。由于Python允许使用变量,因此,Python不是纯函数式编程语言。
简单说,"函数式编程"是一种"编程范式"(programming paradigm),也就是如何编写程序的方法论。
它属于"结构化编程"的一种,主要思想是把运算过程尽量写成一系列嵌套的函数调用。
举例来说,现在有这样一个数学表达式: (1 + 2) * 3 – 4
传统的过程式编程,可能这样写:
var a = 1 + 2;
var b = a * 3;
var c = b - 4;
函数式编程要求使用函数,我们可以把运算过程定义为不同的函数,然后写成下面这样:
var result = subtract(multiply(add(1,2), 3), 4);
这就是函数式编程。
函数式编程的特点:
函数式编程具有五个鲜明的特点。
- 1.函数是"第一等公民"
所谓"第一等公民"(first class),指的是函数与其他数据类型一样,处于平等地位,可以赋值给其他变量,也可以作为参数,传入另一个函数,或者作为别的函数的返回值。
举例来说,下面代码中的print变量就是一个函数,可以作为另一个函数的参数
var print = function(i){ console.log(i);};
[1,2,3].forEach(print);
- 2. 只用"表达式",不用"语句"
"表达式"(expression)是一个单纯的运算过程,总是有返回值;"语句"(statement)是执行某种操作,没有返回值。函数式编程要求,只使用表达式,不使用语句。也就是说,每一步都是单纯的运算,而且都有返回值。
原因是函数式编程的开发动机,一开始就是为了处理运算(computation),不考虑系统的读写(I/O)。"语句"属于对系统的读写操作,所以就被排斥在外。
当然,实际应用中,不做I/O是不可能的。因此,编程过程中,函数式编程只要求把I/O限制到最小,不要有不必要的读写行为,保持计算过程的单纯性。
- 3. 没有"副作用"
所谓"副作用"(side effect),指的是函数内部与外部互动(最典型的情况,就是修改全局变量的值),产生运算以外的其他结果。
函数式编程强调没有"副作用",意味着函数要保持独立,所有功能就是返回一个新的值,没有其他行为,尤其是不得修改外部变量的值。
- 4. 不修改状态
上一点已经提到,函数式编程只是返回新的值,不修改系统变量。因此,不修改变量,也是它的一个重要特点。
在其他类型的语言中,变量往往用来保存"状态"(state)。不修改变量,意味着状态不能保存在变量中。函数式编程使用参数保存状态,最好的例子就是递归。下面的代码是一个将字符串逆序排列的函数,它演示了不同的参数如何决定了运算所处的"状态"。
function reverse(string) {
if(string.length == 0) {
return string;
} else {
return reverse(string.substring(1, string.length)) + string.substring(0, 1);
}
}由于使用了递归,函数式语言的运行速度比较慢,这是它长期不能在业界推广的主要原因。
- 5.引用透明
引用透明(Referential transparency),指的是函数的运行不依赖于外部变量或"状态",只依赖于输入的参数,任何时候只要参数相同,引用函数所得到的返回值总是相同的。
有了前面的第三点和第四点,这点是很显然的。其他类型的语言,函数的返回值往往与系统状态有关,不同的状态之下,返回值是不一样的。这就叫"引用不透明",很不利于观察和理解程序的行为。
2.1.3 Java中的E、T、K、V、?和object
Java泛型中的标记符含义:
E - Element (在集合中使用,因为集合中存放的是元素)
T - Type(Java 类)
K - Key(键)
V - Value(值)
N - Number(数值类型)
? - 表示不确定的java类型,默认是object及其下子类,也就是Java的所有对象了。
S、U、V - 2nd、3rd、4th types
Object跟这些标记符代表的java类型有啥区别呢?
Object是所有类的根类,任何类的对象都可以设置给该Object引用变量,使用的时候可能需要类型强制转换,但是用使用了泛型T、E等这些标识符后,在实际用之前类型就已经确定了,不需要再进行类型强制转换。
使用泛型(泛型可以认为是一种变相的通配):
List
T t=list.get(0);
不使用泛型:
List list=new ArrayList();
T t=(T)list.get(0);
相信你已经看出:
a、用泛型只是确定了集合内的元素的类型,但却是在编译时确定了元素的类型再取出来时已经不再需要强转,
增强程序可读性,稳定性和效率
b、不用泛型时,如果是装入集合操作,那么元素都被当做Object对待,失去自己的类型,那么从集合中取出来时,
往往需要转型,效率低,容易产生错误
//这样的方式来定义泛型表示泛型仅仅在函数内使用。与一般函数的定义方式有很大的区别。
private
//注意3:Class
System.out.println(x.getClass().getName());
}
//T与?的泛型紧跟函数修饰符后表示仅仅在该函数内部使用
private
//getcc前面的Class
System.out.println(a.getClass().getName());
//注意5:参数里面的Class
List
System.out.println(aa);
return a;
}
2.1.4 泛型的详细介绍
2.1.5 toString
在Java的某个类的内部实现了toString之后,sout时会直接打印出toString之后的结果。
2.1.6 Java中到底是传值还是传引用
2.1.7 抽象类
2.1.8 Super关键字
super可以理解为是指向自己超(父)类对象的一个指针,而这个超类指的是离自己最近的一个父类。
super也有三种用法:
- 1.普通的直接引用
与this类似,super相当于是指向当前对象的父类,这样就可以用super.xxx来引用父类的成员。
- 2.子类中的成员变量或方法与父类中的成员变量或方法同名
class Country {
String name;
void value() {
name = "China";
}
}
class City extends Country {
String name;
void value() {
name = "Shanghai";
super.value(); //调用父类的方法
System.out.println(name);
System.out.println(super.name);
}
public static void main(String[] args) {
City c=new City();
c.value();
}
}运行结果:
Shanghai
China
可以看到,这里既调用了父类的方法,也调用了父类的变量。若不调用父类方法value(),只调用父类变量name的话,则父类name值为默认值null。
- 3.引用构造函数
super(参数):调用父类中的某一个构造函数(应该为构造函数中的第一条语句)。
this(参数):调用本类中另一种形式的构造函数(应该为构造函数中的第一条语句)。
2.1.9 匿名函数与函数式接口
Java 8为函数式接口引入了一个新注解@FunctionalInterface,主要用于编译级错误检查,加上该注解,当你写的接口不符合函数式接口定义的时候,编译器会报错。
错误例子,接口中包含了两个抽象方法,违反了函数式接口的定义,Eclipse 报错提示其不是函数式接口。
@FunctionalInterface
Interface GreetingService
{
Void aaa();
Void say();
}函数接口里面允许定义默认方法
函数式接口里面可以包含默认方法,因为默认方法不是抽象方法,其有一个默认实现,所以符合函数式接口定义
@FunctionalInterface
interface GreetingService
{
void sayMessage(String message);
default void doSomeMoreWork1()
{
// Method body
}
default void doSomeMoreWork2()
{
// Method body
}
}函数式接口中允许含有静态方法
函数式接口里允许定义java.lang.Object里的public方法
2.1.10 什么是Bean
2.2 Java API
2.2.1 asList
容易出现的错误
- 1. 将基本数据类型的数组作为参数
我们知道任何类型的对象都有一个 class 属性,这个属性代表了这个类型本身。原生数据类型,比如 int,short,long等,是没有这个属性的,具有 class 属性的是它们所对应的包装类 Integer,Short,Long。
因此,这个错误产生的原因可解释为:asList 方法的参数必须是对象或者对象数组,而原生数据类型不是对象——这也正是包装类出现的一个主要原因。当传入一个原生数据类型数组时,asList 的真正得到的参数就不是数组中的元素,而是数组对象本身!此时List 的唯一元素就是这个数组。
Java中一切都是对象这句话没错,因为八种基本类型都有对应的包装类(int的包装类是Integer),包装类自然就是对象了。 基本类型一直都是Java语言的一部分,这主要是基于程序性能的考量,基本类型定义定义的变量是存放在栈中,比如int i = 5;而Integer j = new Integer(10);j则只是一个对象的引用,存放在栈中,而实际的数值10则是放在堆里,堆的读写速度远不及栈了。再有就是基本类型定义的变量创建和销毁很快,而类定义的变量还需要JVM去销毁。
所以我们使用8中基本数据类型的包装类即可解决这个问题。
- 2. 试图修改List的大小
AsList方法所生成的list是无法改变的,无法直接做add和remove,原因是因为
这个内部类也叫 ArrayList ,更重要的是在这个内部类中有一个被声明为 final 的数组 a ,所有传入的元素都会被保存在这个数组 a 中。
可以直接创建一个真正的arrayList
public class Test {
public static void main(String[] args) {
String[] myArray = { "Apple", "Banana", "Orange" };
List myList = new ArrayList(Arrays.asList(myArray));
myList.add("Guava");
}
} 2.2.2 Java反射技术
2.2.3 Stream
Stream是什么类型?Stream的具体接口,如何对实现Stream接口的子类进行相应的操作,
在浩哥的指点下,发现if (res.findFirst().get().value.get("p") == null)
对于其具体的API与具体的算子等待后续继续学习。
在使用其来判断二层口的连接时
call apoc.cypher.check2NodesConn('25GE1/0/[email protected]', '25GE1/0/[email protected]'),会出现如下报错
Neo.ClientError.Procedure.ProcedureCallFailed: Failed to invoke procedure `apoc.cypher.check2NodesConn`: Caused by: java.lang.IllegalStateException: stream has already been operated upon or closed
需要进行处理。
这里的Java深拷贝如何处理?
对于Stream类的应用和举例
Stream stringStream = Stream.of("A", "B", "C", "D");
Optional result1 = stringStream.findAny();
System.out.println(result1.get());
Optional result2 = stringStream.findFirst(); 这种情况会爆如下错误
A
Exception in thread "main" java.lang.IllegalStateException:
stream has already been operated upon or closed
解决方法:
Supplier的函数接口会非常便利:
Supplier> streamSupplier = () -> Stream.of("A", "B", "C", "D");
Optional result1 = streamSupplier.get().findAny();
System.out.println(result1.get());
Optional result2 = streamSupplier.get().findFirst();
System.out.println(result2.get()); 2.2.4 Stream API学习
Java 8 中的 Stream 是对集合(Collection)对象功能的增强,它专注于对集合对象进行各种非常便利、高效的聚合操作(aggregate operation),或者大批量数据操作 (bulk data operation)。Stream API 借助于同样新出现的 Lambda 表达式,极大的提高编程效率和程序可读性。同时它提供串行和并行两种模式进行汇聚操作,并发模式能够充分利用多核处理器的优势,使用 fork/join 并行方式来拆分任务和加速处理过程。通常编写并行代码很难而且容易出错, 但使用 Stream API 无需编写一行多线程的代码,就可以很方便地写出高性能的并发程序。所以说,Java 8 中首次出现的 java.util.stream 是一个函数式语言+多核时代综合影响的产物。
Stream 不是集合元素,它不是数据结构并不保存数据,它是有关算法和计算的,它更像一个高级版本的 Iterator。原始版本的 Iterator,用户只能显式地一个一个遍历元素并对其执行某些操作;高级版本的 Stream,用户只要给出需要对其包含的元素执行什么操作,比如 “过滤掉长度大于 10 的字符串”、“获取每个字符串的首字母”等,Stream 会隐式地在内部进行遍历,做出相应的数据转换。
Stream 就如同一个迭代器(Iterator),单向,不可往复,数据只能遍历一次,遍历过一次后即用尽了,就好比流水从面前流过,一去不复返。
而和迭代器又不同的是,Stream 可以并行化操作,迭代器只能命令式地、串行化操作。顾名思义,当使用串行方式去遍历时,每个 item 读完后再读下一个 item。而使用并行去遍历时,数据会被分成多个段,其中每一个都在不同的线程中处理,然后将结果一起输出。
流的使用,就是大数据的时候的ETL的过程,extract、transform、load。Extract类似于stream()或者parallelStream(),中间的transform类似于Stream的filter和sorted等接口。最后的load和map与collect接口类似。
流的操作类型
Intermediate:惰性操作。
Terminal:一个流只能有一个terminal操作,当这个操作执行完成之后,流就被用光了,无法再被操作。我们可以这样简单的理解,Stream 里有个操作函数的集合,每次转换操作就是把转换函数放入这个集合中,在 Terminal 操作的时候循环 Stream 对应的集合,然后对每个元素执行所有的函数。
还有一种命名为短路操作,short-circuiting,用以指
对于一个 intermediate 操作,如果它接受的是一个无限大(infinite/unbounded)的 Stream,但返回一个有限的新 Stream。
对于一个 terminal 操作,如果它接受的是一个无限大的 Stream,但能在有限的时间计算出结果。
简单说,对 Stream 的使用就是实现一个 filter-map-reduce 过程,产生一个最终结果,或者导致一个副作用(side effect)。
- Intermediate:
map (mapToInt, flatMap 等)、 filter、 distinct、 sorted、 peek、 limit、 skip、 parallel、 sequential、 unordered
- Terminal:
forEach、 forEachOrdered、 toArray、 reduce、 collect、 min、 max、 count、 anyMatch、 allMatch、 noneMatch、 findFirst、 findAny、 iterator
- Short-circuiting:
anyMatch、 allMatch、 noneMatch、 findFirst、 findAny、 limit
我们下面看一下 Stream 的比较典型用法。
2.2.5 匿名函数(Java的lambda表达式)
2.2.6 CompareTo、Comparable、Comparator
CompareTo是comparable接口下的一个方法,很多Java的类都实现了这个接口。
所以主要需要比较Comparable与Comparator两个接口的区别
Collections.
Comparable & Comparator都是用来实现集合中元素的比较、排序的,只是 Comparable 是在集合内部定义的方法实现的排序,Comparator 是在集合外部实现的排序,所以,如想实现排序,就需要在集合外定义Comparator接口的方法或在集合内实现 Comparable接口的方法,Comparator位于包java.util下,而Comparable位于包java.lang下。
作者:Fighting_rain
链接:https://www.jianshu.com/p/81e5c3e88fc6
public class ComparatorDemo {
public static void main(String[] args) {
List people = Arrays.asList(
new Person("Joe", 24),
new Person("Pete", 18),
new Person("Chris", 21)
);
Collections.sort(people, new LexicographicComparator());
System.out.println(people);
//[{name=Chris, age=21}, {name=Joe, age=24}, {name=Pete, age=18}]
Collections.sort(people, new Comparator() {
@Override
public int compare (Person a, Person b) {
// TODO Auto-generated method stub
return a.age < b.age ? -1 : a.age == b.age ? 0 : 1;
}
});
System.out.println(people);
//[{name=Pete, age=18}, {name=Chris, age=21}, {name=Joe, age=24}]
}
}
class LexicographicComparator implements Comparator {
@Override
public int compare(Person a, Person b) {
return a.name.compareToIgnoreCase(b.name);
}
}
class Person {
String name;
int age;
Person(String n, int a) {
name = n;
age = a;
}
@Override
public String toString() {
return String.format("{name=%s, age=%d}", name, age);
}
} 2.2.7 Java中的?是什么
2.2.8 List的toArray接口
2.2.9 Extends和implements
3 Gradle
为什么需要打包?
最初写完了,直接右键run就可以了。但是代码写完是要发布到服务器上或者给别人用的,第一不能让所有人装环境,第二不能把冤案公布给所有人,所以需要把代码发布成二进制形式,让其他环境方便运行,这就是打包。
为什么要用ant?
打包时需要做很多事情,比如配置文件的用户名和密码,以及各种if else的条件配置,每次打包时都要重复做这些事情,ant可以用xml把这些事情写成脚本,然后自动运行。
为什么用maven?
便于不同版本与版本依赖的数量众多的jar包的下载
为什么用gradle?
Maven方便了jar包的下载流程,但是打包的基本逻辑,maven不知道如何实现。于是我们需要一个综合maven与ant功能的工具,而不仅仅是单一的。于是我们用到了gradle,既能干maven的活,又能干ant的活,用groovy语言写脚本,表达能力还更强。
需要注意的是,如果处在内网,maven和gradle都需要设置代理,因为可能需要从官网下载插件。
3.1 什么是gradle
在尝试书写neo4j的存储过程时,遇到了gradle,既不是传统的Java工程,也不是maven工程,在idea要编译这类工程与之前两者都不相同。那么什么是gradle?
随着软件工程的项目的日益复杂,对于软件项目的编译,打包就成为了一大痛点。 以android项目为例,如果要手动配置那么多依赖的第三方库和jar包,自己需要一个一个去网上找资源,然后下载,配置。如果依赖包的版本变更的话,又要重新找资源,下载,配置。 想想都头大。
还有ant的编译规则是基于xml的,用xml你是很难描述类似if(如果条件成立,编译某文件)else{如果条件不成立,编译某文件}这样不同条件的任务的。
那Gradle呢, 首先Gradle是支持自动下载的依赖包的,
然后呢,Gradle脚本不是像传统的xml文件那样,而是一种基于Groovy的动态DSL,而Groovy语言是一种基于jvm的动态语言。 基于这种设计呢, gradle是支持我们像写脚本一样的去写项目的构建规则。
3.2 Gradle使用中的问题
Github上下载了neo4j的Java源码,中间遇到不少问题,之前的红色Java的下标已经解决。Gradle工程,下载gradle包,其配置与jdk环境配置类似,新建系统环境GRADLE_HOME,在path中添加对应的bin。一般为了不影响其他用户,在环境变量的用户变量
测试:在cmd中如果输入gradle –v可以打出相应的版本号,说明对应的环境配置完毕。
在idea中的配置,在d盘对应的文件夹下,新建一个文件夹作为gradle下载的jar包仓库的主目录,在idea中配置gradle的编译配置
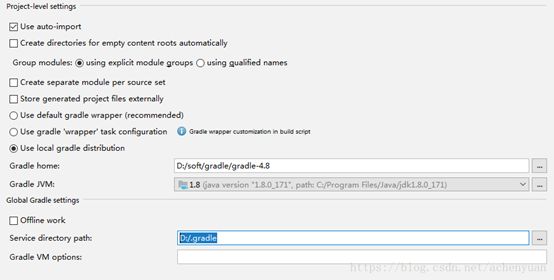
特别注意:这里的create separate module groups,gradle默认是勾选的,需要去勾选,如上图,否则会报如下错误
exception during working with external system: java.lang.AssertionError at org.jetbrains.plugins.gradle.service.project.BaseGradleProjectResolverExtension.populateModuleContentRoots(BaseGradleProjectResolverExtension.java:272)
在配置好gradle在idea中的基本配置之后,需要对gradle的仓库进行设置,
repositories {
mavenLocal()
maven { url "http://maven.aliyun.com/nexus/content/groups/public/"}
mavenCentral()
jcenter()
maven { url "https://repo.spring.io/snapshot" }
maven { url "https://repo.spring.io/milestone" }
maven { url 'http://oss.jfrog.org/artifactory/oss-snapshot-local/' } //转换pdf使用
}注意:文档中虽然如此书写,但是在全局配置下,maven仅仅需要留一个地址,即去掉mavenlocal(),mavenCentral()与jcenter(),直接留下公司内网私服的地址即可。
因为如果留下多个地址,如果第一个地址无法连接会搜索第二个地址,但是如果第一个地址可以连接的话,会从第一个地址里面获取依赖的jar包。如果无法获取,会引发报错如下:
Error:Could not resolve all dependencies for configuration ':classpath'
解决办法:这种情况将gradle的全局配置文件和对应项目的build.gradle都配置成对应的maven仅为私服maven仓库的地址。
3.3 中文编码问题
报错错误: 编码GBK的不可映射字符
将含有中文注释的代码先从utf-8 convert成gbk,再从gbk转换为utf-8即可。
3.4 JVM的远程调试
3.5 异步多线程调试
4 Java多线程编程
4.1 进程和线程
很多同学都听说过,现代操作系统比如Mac OS X,UNIX,Linux,Windows等,都是支持“多任务”的操作系统。
什么叫“多任务”呢?简单地说,就是操作系统可以同时运行多个任务。打个比方,你一边在用浏览器上网,一边在听MP3,一边在用Word赶作业,这就是多任务,至少同时有3个任务正在运行。还有很多任务悄悄地在后台同时运行着,只是桌面上没有显示而已。
现在,多核CPU已经非常普及了,但是,即使过去的单核CPU,也可以执行多任务。由于CPU执行代码都是顺序执行的,那么,单核CPU是怎么执行多任务的呢?
答案就是操作系统轮流让各个任务交替执行,任务1执行0.01秒,切换到任务2,任务2执行0.01秒,再切换到任务3,执行0.01秒……这样反复执行下去。表面上看,每个任务都是交替执行的,但是,由于CPU的执行速度实在是太快了,我们感觉就像所有任务都在同时执行一样。
真正的并行执行多任务只能在多核CPU上实现,但是,由于任务数量远远多于CPU的核心数量,所以,操作系统也会自动把很多任务轮流调度到每个核心上执行。
对于操作系统来说,一个任务就是一个进程(Process),比如打开一个浏览器就是启动一个浏览器进程,打开一个记事本就启动了一个记事本进程,打开两个记事本就启动了两个记事本进程,打开一个Word就启动了一个Word进程。
有些进程还不止同时干一件事,比如Word,它可以同时进行打字、拼写检查、打印等事情。在一个进程内部,要同时干多件事,就需要同时运行多个“子任务”,我们把进程内的这些“子任务”称为线程(Thread)。
总结一下就是,多任务的实现有3种方式:
多进程模式;
多线程模式;
多进程+多线程模式。
线程是最小的执行单元,而进程由至少一个线程组成。如何调度进程和线程,完全由操作系统决定,程序自己不能决定什么时候执行,执行多长时间。
多进程和多线程的程序涉及到同步、数据共享的问题,编写起来更复杂。
4.2 Run和start函数的区别
start方法是启动一个线程,而线程中的run方法来完成实际的操作。
如果开发人员直接调用run方法,那么就会将这个方法当作一个普通函数来调用,并没有多开辟线程,开发人员如果希望多线程异步执行,则需要调用start方法。
start() 创建新进程
run() 没有
static是类变量,为类内成员共有
基本上实现Thread和实现Runnable接口是一样的,都需要在类中实现start和run方法,一般start方法中都是做一个实例化操作,t = new Thread (this, threadName);在run方法中写主要的代码体。
4.3 多线程的使用与主要概念
线程同步、线程间通信、线程死锁、线程控制:挂起、停止和恢复
如果你创建太多的线程,程序执行的效率实际上是降低了,而不是提升了。
请记住,上下文的切换开销也很重要,如果你创建了太多的线程,CPU 花费在上下文的切换的时间将多于执行程序的时间!
Cpu是以分时的状态在进行工作,上下文切换又称线程颠簸,即cpu从一个线程切换到另一个线程,需要先保存当前线程的状态,再读取下一线程的状态,这种切换即称为上下文切换。
4.4 线程池
线程池:基本思想还是一种对象池的思想,开辟一块内存空间,里面存放了众多(未死亡)的线程,池中线程执行调度由池管理器来处理。当有线程任务时,从池中取一个,执行完成后线程对象归池,这样可以避免反复创建线程对象所带来的性能开销,节省了系统的资源。
4.5 Callable
5 Java多态的回顾
5.1 重写
多态存在的三个必要条件:继承、重写、父类引用指向子类对象(子类实例)。
比如: Parent p = new Child();
在实际的工程代码中,往往会利用接口实现多继承,这里的形参都是父类,传入参数的实参基本是子类,从而实现了实参的向上转型。
当使用多态方式调用方法时,首先检查父类中是否有该方法(这里的方法基本上都是抽象方法或者接口中的方法,没有实际的方法体),如果没有,则编译错误;如果有,再去调用子类的同名方法。
多态的好处:可以使程序有良好的扩展,并可以对所有类的对象进行通用处理。
虚函数的存在是为了多态。
Java 中其实没有虚函数的概念,它的普通函数就相当于 C++ 的虚函数,动态绑定是Java的默认行为。如果 Java 中不希望某个函数具有虚函数特性,可以加上 final 关键字变成非虚函数。
重写
我们将介绍在 Java 中,当设计类时,被重写的方法的行为怎样影响多态性。
我们已经讨论了方法的重写,也就是子类能够重写父类的方法。
当子类对象调用重写的方法时,调用的是子类的方法,而不是父类中被重写的方法。
要想调用父类中被重写的方法,则必须使用关键字 super。
5.2 虚函数的例子解析
实例中,实例化了两个 Salary 对象:一个使用 Salary 引用 s,另一个使用 Employee 引用 e。
当调用 s.mailCheck() 时,编译器在编译时会在 Salary 类中找到 mailCheck(),执行过程 JVM 就调用 Salary 类的 mailCheck()。
因为 e 是 Employee 的引用,所以调用 e 的 mailCheck() 方法时,编译器会去 Employee 类查找 mailCheck() 方法 。
在编译的时候,编译器使用 Employee 类中的 mailCheck() 方法验证该语句, 但是在运行的时候,Java虚拟机(JVM)调用的是 Salary 类中的 mailCheck() 方法。
以上整个过程被称为虚拟方法调用,该方法被称为虚拟方法。
Java中所有的方法都能以这种方式表现,因此,重写的方法能在运行时调用,不管编译的时候源代码中引用变量是什么数据类型。