腾讯云服务器搭建hadoop-2.6.0-cdh5.6.0完全分布式环境
搭建思路:购买服务器,下载上传软件,用户环境配置,系统环境配置,hadoop配置,格式化HDFS,启动hadoop并验证
一、购买服务器
1、由于经济有限,购买的是腾讯云的学生机,且暂时只买了两台,第三台等基本配置完毕后作为结点扩展加进去

2、服务器基本配置——系统:CentOS-7.3 , CPU:1核 , 内存:2G , 硬盘:50G (内存太小是隐患)
二、下载上传软件
1、hadoop是用java实现的,所以需要java jdk,可在官网下载linux版本,此处百度云盘分享jdk1.8.0_40,地址https://pan.baidu.com/s/1Z1Z3Vkq5tgHRVuwqYLsaow 提取码:g9jb
2、hadoop-2.6.0-cdh5.6.0,下载地址https://archive.cloudera.com/cdh5/cdh/5/hadoop-2.6.0-cdh5.6.0.tar.gz
3、前面下载的jdk和hadoop安装包都是利用secureCRT的Zmodem从windows 上传到linux服务器的/opt目录,
但对于jdk,各个服务器节点都要上传,对于hadoop-2.6.0-cdh5.6.0,只需上传到主服务器master,配置好后直接
scp到各节点对应目录
三、用户环境配置
1、修改主机名和用户名(为了用户使用方便)
(1)修改用户名(root用户执行,所有节点都需执行)
添加用户hadoop,输入:
useradd hadoop
设置hadoop用户密码,输入:
passwd hadoop此处统一设置为123456
(2)修改主机名(root用户执行,所有节点都需执行)
输入:
hostname可查看本机的名称。
修改主机名为master
输入:
hostnamectl set-hostname master或者vi编辑/etc/hostname修改,
输入:
vi /etc/hostname然后输入master,保存退出。
其他节点的主机名修改为slave1,slave2....
注:主机名称更改后,需重启(reboot)后才会生效,本人踩过的坑
(3)修改ip和主机名映射(为了让节点之间可以直接通过简易的主机名互相访问)
修改hosts文件(root用户执行,所有节点都需执行)
执行:
vi /etc/hosts在文件末尾加上:
IP地址 主机名
例:
172.16.0.xx master
182.254.xxx.xxx slave1
注:由于使用的是云服务器,和虚拟机配置的映射不一样,可百度查看内网外网区别,
对于本机,需要配置内网地址(ifconfig可查看),如上面的172.16.0.xx master
对于其他节点,外面的机器,需要配置外网地址,如182.254.xxx.xxx slave1
所以,slave1上配置hosts时,slave1需要配置内网地址,master需要配置为外网地址
2、配置SSH无密码连接(hadoop需要通过ssh协议将节点上面的进程启动或停止,不配置也可以,不过每次都要输入用户名密码,已经怀疑人生了)
(1)关闭防火墙(默认已关闭),安装SSH(一般操作系统都有)
(2) 生成SSH公钥(以hadoop用户执行)
在主节点master执行:
ssh-keygen -t rsa遇到提示回车即可。在/home/hadoop/.ssh目录下会自动生成id_rsa,id_rsa.pub即私钥,公钥
公钥长这样子(后面是用户名@主机名):
tips:要实现免密码登陆某节点,只需将公钥id_rsa.pub复制到该节点的authorized_keys文本中(需自己在~/.ssh下创建,对于master的用户hadoop为/home/hadoop/.ssh,此隐藏目录下执行touch authorized_keys)
(3)分发公钥
在主节点master执行:
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop@master
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop@slave1
...
或者直接复制到authorized_keys中。
(4)验证安装(以hadoop用户执行)
主节点master执行:
ssh slave1若没有出现输入密码的提示,则配置成功;
若仍然不成功,可能是权限问题,
以hadoop用户执行:
chmod 700 /home/hadoop/.ssh
chmod 644 /home/hadoop/.ssh/authorized_keys注:实践表明,确实分别需要700,644权限,其他权限貌似不行,即使目录文件拥有者为hadoop
四、系统环境配置
1、配置jdk
(1)先解压
tar -zxvf jdk-8u40-linux-x64.gz(2)配置环境变量(root用户执行,所有节点都执行),对/etc/profile追加:
export JAVA_HOME=/opt/jdk1.8.0_40
export PATH=$PATH:$JAVA_HOME/binsource /etc/profile使环境变量立即生效。
执行 java -version,验证安装。
2、配置hadoop的系统环境变量
(1)从root用户获得/opt文件夹的权限(root用户执行,所有节点都执行),
执行:
chown -R hadoop /opt(2)解压(hadoop用户在主节点master执行,其他节点直接通过在主节点复制配置好的hadoop)
tar -zxvf hadoop-2.6.0-cdh5.6.0.tar(3)配置环境变量(root用户执行,所有节点都执行),对/etc/profile追加:
export HADOOP_HOME=/home/hadoop-2.6.0-cdh5.6.0
export PATH=$PATH:HADOOP_HOME/binsource /etc/profile使环境变量立即生效。
五、hadoop配置(切换到/opt/hadoop-2.6.0-cdh5.6.0/etc/hadoop)
1、修改hadoop-env.sh。在文件末尾追加环境变量:
export JAVA_HOME=/opt/jdk1.8.0_40
export HADOOP_HOME=/opt/hadoop-2.6.0-cdh5.6.02、修改core-site.xml。(设置HDFS服务的主机名和端口号,也是指定了NameNode所运行的节点)如下:
fs.default.name
hdfs://master:9000
3、修改hdfs-site.xml。(replication即文件副本数,dfs.name.dir为NamaNode的元数据存放路径,dfs.data.dir为DataNode存放数据的路径)改为:
dfs.replication
1
dfs.name.dir
/opt/hdfs/name
dfs.data.dir
/opt/hdfs/data
dfs.secondary.http.address
master:50090
4、修改mapred-site.xml。(指明MapReduce基于YARN工作,但对于CDH5,如果服务器内存不足会导致问题,见末尾问题)改为:
mapreduce.framework.name
yarn
5、修改yarn-site.xml。(设置ResourceManager服务的主机名和端口号,指明mapreduce_shuffle的类。8088端口开放有安全隐患,见末尾问题)
改为:
yarn.resourcemanager.address
master:8080
yarn.resourcemanager.webapp.address
master:8088
yarn.resourcemanager.resource-tracker.address
master:8082
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
httpshuffle
6、修改slaves文件。(此处指明运行DataNode、NodeManager进程的节点,即所有从节点)改为:
slave1
# 如还有其他从节点,如slave2,则为:
# slave1
# slave2
7、将安装文件夹分发到从节点的相同路径:
scp -r /opt/hadoop-2.6.0-cdh5.6.0 hadoop@slave1:/opt
...六、格式化HDFS
1、第一次启动hadoop时,需先格式化HDFS,执行:
hadoop namenode -format按照提示输入Y,格式化成功后会有相应的提示信息。
执行:
hadoop dfsadmin -report可查看hdfs情况,如下:
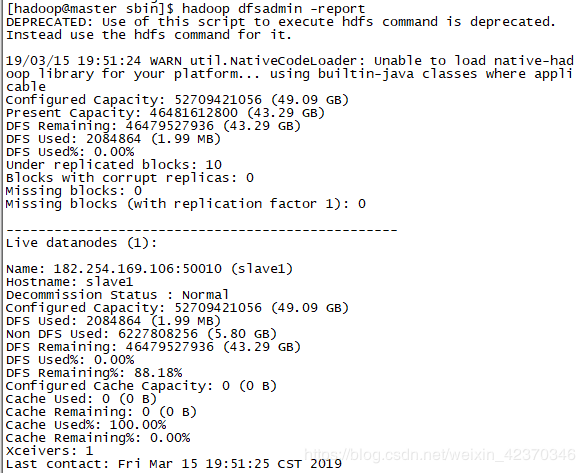
如出现全为0的情况,可删除hdfs目录重新执行格式化,也有可能为端口占用问题,可查看日志。
七、启动hadoop并验证
1、获得执行权限(如已有,可忽略),(hadoop用户,所有节点都执行)
chmod +x -R /opt/hadoop-2.6.0-cdh5.6.0/sbin2、执行启动脚本,以hadoop用户在主节点master执行:
./opt/hadoop-2.6.0-cdh5.6.0/sbin/start-all.sh再执行:
jps查看显示和java有关的进程名和进程号,
在master会出现:

在slave1会出现:
![]()
3、验证是否成功。(以执行一个mapreduce作业,wordcount验证)
在/home/hadoop目录下新建文本words,并编辑保存内容“I believe that I will be successful”,执行:
hdfs dfs -mkdir -p /user/hadoop/input
hdfs dfs -put /home/hadoop/words /user/hadoop/input
hadoop jar /opt/hadoop-2.6.0-cdh5.6.0/share/hadoop/mapreduce2/hadoop-mapreduce-examples-2.6.0-cdh5.6.0.jar wordcount /user/hadoop/input /user/hadoop/output再执行:
hdfs dfs -cat /user/hadoop/output/part-r-00000可查看单词统计结果。
八、可能遇见的问题
1、执行wordcount时,一直停留在run状态不动,如下:
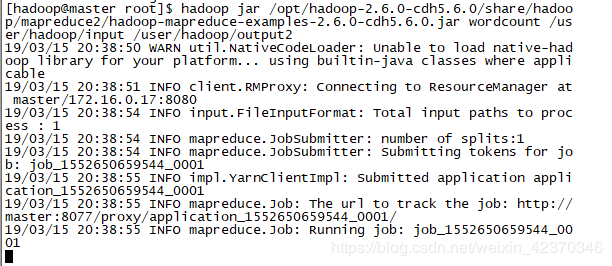
因为是在mapreduce过程产生问题,所以可查看resourcemanager和nodemanager日志,但有时发现并无异常
(1)网上原因一,说是hosts配置问题;
(2)内存资源不足,本人觉得原因在此,因为cdh5要求默认内存为8G,cpu为8核,解决办法有三,一提升配置
二修改mapred-site.xml,去掉yarn,如下(采用往版本的job.tracker):
mapreduce.job.tracker
hdfs://master:8001
true
三不使用cdh版本,下载单个的hadoop(见往后的文章)
2、NodeManager一段时间后莫名挂掉
在slave1查看/opt/hadoop-2.6.0-cdh5.6.0/logs/yarn-hadoop-nodemanager-slave1.log
发现dr.who不断提交application
在http://master:8088/查看,多出很多由dr.who提交的任务。
猜测是资源不足,导致nodemanager挂掉,但莫名自动提交任务很可疑
网上查找答案,是黑客利用漏洞,注入8088端口攻击来挖矿,top可查看cpu使用情况,但由于服务器太烂,资源不足挂掉了
hadoop没运行起来,所以cpu占用倒不高。
策略之一是修改yarn-site.xml,resourcemanager的默认访问端口8088为其他端口:
yarn.resourcemanager.webapp.address
master:8077