pandas数据处理实践二(排序(sort_index()、sort_values())、连接(Concatenate(连接,串联)和Combine(结合、联合))
排序:
Series的排序:
Series.sort_index()按位置排序
Series.sort_index()按值排序
Series.sort_index(axis = 0,level = None,ascending = True,inplace = False,kind =' quicksort ',na_position ='last',sort_remaining = True )
Series.sort_values(axis = 0,ascending = True,inplace = False,kind =' quicksort ',na_position ='last' )
举个例子:
>>> s.sort_index(ascending=False) # 对索引降序排序,默认升序
4 d
3 a
2 b
1 c
dtype: object
>>> s.sort_values(ascending=False) # 对值进行降序排序,默认是升序
3 10.0
4 5.0
2 3.0
1 1.0
0 NaN
dtype: float64DataFrame的排序:
DataFrame.sort_index(axis = 0,level = None,ascending = True,inplace = False,kind =' quicksort ',na_position ='last',sort_remaining = True,by = None )
DataFrame.sort_values(by,axis = 0,ascending = True,inplace = False,kind =' quicksort ',na_position ='last' )
功能类似
DataFrame的merge操作:
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None,
left_index=False, right_index=False, sort=True,
suffixes=('_x', '_y'), copy=True, indicator=False,
validate=None)
left:一个DataFrame对象。
right:另一个DataFrame对象。In [1]: import numpy as np^M
...: import pandas as pd^M
...: from pandas import Series,DataFrame
...:
...:
In [38]: left = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],
....: 'A': ['A0', 'A1', 'A2', 'A3'],
....: 'B': ['B0', 'B1', 'B2', 'B3']})
....:
In [39]: right = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],
....: 'C': ['C0', 'C1', 'C2', 'C3'],
....: 'D': ['D0', 'D1', 'D2', 'D3']})
....:
In [40]: result = pd.merge(left, right, on='key')
In [12]: result
 从输出可以看出,拼接是通过键值‘key’进行拼接,
从输出可以看出,拼接是通过键值‘key’进行拼接,
如果想通过其他进行拼接可以通过改变on=即可
In [41]: left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],
....: 'key2': ['K0', 'K1', 'K0', 'K1'],
....: 'A': ['A0', 'A1', 'A2', 'A3'],
....: 'B': ['B0', 'B1', 'B2', 'B3']})
....:
In [42]: right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
....: 'key2': ['K0', 'K0', 'K0', 'K0'],
....: 'C': ['C0', 'C1', 'C2', 'C3'],
....: 'D': ['D0', 'D1', 'D2', 'D3']})
....:
In [43]: result = pd.merge(left, right, on=['key1', 'key2'])
 这是一个包含多个连接键的更复杂的示例。默认情况下,只有出现在
这是一个包含多个连接键的更复杂的示例。默认情况下,只有出现在left和right存在的键(inner)
how='inner'
参数how的用法:
该how参数merge指定如何确定要在结果表中包含哪些键。如果组合键没有出现在左表或右表中,则联接表中的值将为NA。以下是how选项及其SQL等效名称的摘要:
| 合并方法 | SQL加入名称 | 描述 |
|---|---|---|
left |
LEFT OUTER JOIN |
仅使用左框架中的按键 |
right |
RIGHT OUTER JOIN |
仅使用右框架中的按键 |
outer |
FULL OUTER JOIN |
使用两个帧中的键的并集 |
inner |
INNER JOIN |
使用两个帧的交叉键 |
In [44]: result = pd.merge(left, right, how='left', on=['key1', 'key2']) 以left的键为how进行连接,不在left的键直接删除,例如right中的(k2,k0)
以left的键为how进行连接,不在left的键直接删除,例如right中的(k2,k0)
In [45]: result = pd.merge(left, right, how='right', on=['key1', 'key2']) 同上
同上
result = pd.merge(left, right, how='outer', on=['key1', 'key2'])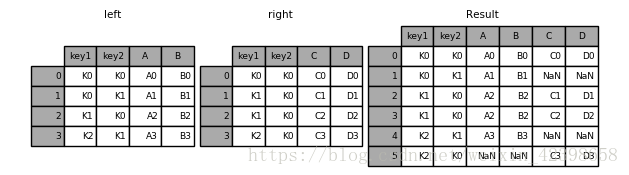 以left和right的并联进行连接
以left和right的并联进行连接
In [47]: result = pd.merge(left, right, how='inner', on=['key1', 'key2']) 以left和right的共有的进行连接
以left和right的共有的进行连接
其他参考官方教程
Concatenate(连接,串联)和Combine(结合、联合):
数组的连接:Concatenate
In [16]: array1 = np.arange(9).reshape(3,3)
In [17]: array2 = np.arange(9).reshape(3,3)
In [18]: np.concatenate([array1,array2]) # 默认是axis=0连接,即行连接
In [19]: array1
Out[19]:
array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])
In [20]: array2
Out[20]:
array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])
连接后:
array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8],
[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])
In [24]: np.concatenate([array1,array2],axis=1) # 列连接
Out[24]:
array([[0, 1, 2, 0, 1, 2],
[3, 4, 5, 3, 4, 5],
[6, 7, 8, 6, 7, 8]])Series的连接方式:concat
In [25]: s1 = Series([1,2,3],index=['X','Y','Z'])^M
...: s2 = Series([4,5],index=['A','B'])
...:
...:
In [26]: s1
Out[26]:
X 1
Y 2
Z 3
dtype: int64
In [27]: s2
Out[27]:
A 4
B 5
dtype: int64
In [28]: pd.concat([s1,s2],axis=0) # 默认行连接
Out[28]:
X 1
Y 2
Z 3
A 4
B 5
dtype: int64
In [29]: pd.concat([s1,s2],axis=1,sort=True) # 列连接 会形成Dataframe结构数据
Out[29]:
0 1
A NaN 4.0
B NaN 5.0
X 1.0 NaN
Y 2.0 NaN
Z 3.0 NaNDataframe连接:concat
In [30]: df1 = DataFrame(np.arange(12).reshape(4,3),columns=['x','y','z'])
In [31]: df2 = DataFrame(np.random.randn(3,3),columns=['x','y','a'])
In [32]: df1
Out[32]:
x y z
0 0 1 2
1 3 4 5
2 6 7 8
3 9 10 11
In [33]: df2
Out[33]:
x y a
0 2.166837 0.011324 1.429738
1 1.446888 0.472470 1.075254
2 -0.688910 -1.895949 0.066047
In [34]: pd.concat([df1,df2],sort=True) # 默认行连接,同时按columns进行排序显示,没有的
# columns,使用nan进行填充
Out[34]:
a x y z
0 NaN 0.000000 1.000000 2.0
1 NaN 3.000000 4.000000 5.0
2 NaN 6.000000 7.000000 8.0
3 NaN 9.000000 10.000000 11.0
0 1.429738 2.166837 0.011324 NaN
1 1.075254 1.446888 0.472470 NaN
2 0.066047 -0.688910 -1.895949 NaNCombine:combine_first
# Series
In [35]: s1 =Series([2,np.nan,4,np.nan], index=['A','B','C','D'])
In [36]: s2 = Series([1,2,3,4], index=['A','B','C','D'])
In [37]: s1
Out[37]:
A 2.0
B NaN
C 4.0
D NaN
dtype: float64
In [38]: s2
Out[38]:
A 1
B 2
C 3
D 4
dtype: int64
In [39]: s1.combine_first(s2) # combine_first用s2填充s1,即s1中出现nan时,s2对应位填充s1对应的nan
Out[39]:
A 2.0
B 2.0
C 4.0
D 4.0
dtype: float64
# DataFrame
In [40]: df1 = DataFrame({^M
...: 'x': [1, np.nan, 3, np.nan],^M
...: 'y': [5, np.nan, 7, np.nan],^M
...: 'z': [9, np.nan, 11, np.nan]^M
...: })
In [41]: df2 = DataFrame({^M
...: 'z':[np.nan, 10, np.nan,12],^M
...: 'a':[1,2,3,4]^M
...: })
In [42]: df1
Out[42]:
x y z
0 1.0 5.0 9.0
1 NaN NaN NaN
2 3.0 7.0 11.0
3 NaN NaN NaN
In [43]: df2
Out[43]:
z a
0 NaN 1
1 10.0 2
2 NaN 3
3 12.0 4
In [44]: df1.combine_first(df2) # 一样的填充效果
Out[44]:
a x y z
0 1.0 1.0 5.0 9.0
1 2.0 NaN NaN 10.0
2 3.0 3.0 7.0 11.0
3 4.0 NaN NaN 12.0