Logstash6.x 同步mysql一对多数据到ES
Logstash 、Kibana、ES版本:6.2.4
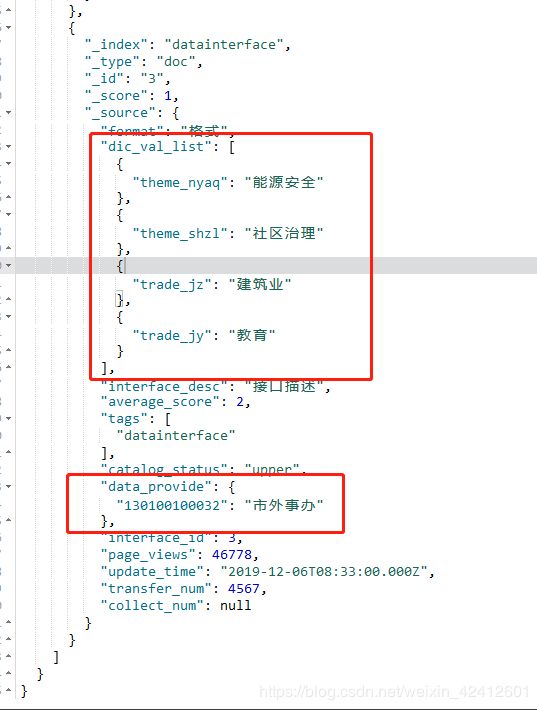
希望的格式:
使用Logstash从mysql同步数据接口表和接口 所属的主题以及部门(在另外一张表中) 到ES中
完整的配置文件jdbc.conf
input {
##数据接口
jdbc {
# mysql 数据库链接,shop为数据库名
jdbc_connection_string => "jdbc:mysql://ip:3306/kf_data_open?useUnicode=true&characterEncoding=utf8&serverTimezone=UTC"
# 用户名和密码
jdbc_user => "root"
jdbc_password => "12345678"
# 驱动
jdbc_driver_library => "/usr/local/logstash-6.2.4/config/mysql-connector-java-5.1.42.jar"
# 驱动类名
jdbc_driver_class => "com.mysql.jdbc.Driver"
#是否分页
jdbc_paging_enabled => "true"
jdbc_page_size => "50000"
#直接执行sql语句,通过id > :sql_last_value去判断上次执行到了哪里
statement =>"select DISTINCT a.interface_id,a.interface_desc,a.format,a.update_time,a.page_views,a.transfer_num,
a.collect_num,a.average_score,b.data_provide,b.catalog_status,c.dic_val,d.dic_label,e.dic_label as dic_label1 from kf_data_interface a
INNER JOIN kf_data_catalog b ON a.catalog_id=b.catalog_id
INNER JOIN kf_catalog_tag c ON a.catalog_id=c.catalog_id
INNER JOIN kf_dictionaries d on d.dic_val=c.dic_val
INNER JOIN kf_dictionaries e on e.dic_val=b.data_provide
where a.update_time > :sql_last_value order by a.update_time asc"
#使用列值进行查询记录追踪
use_column_value => true
#设置跟踪记录的列为:id,要先设置use_column_value=true
tracking_column => "update_time"
#默认为number,如果为日期必须声明为timestamp
tracking_column_type => "timestamp"
# 执行的sql 文件路径+名称
#statement_filepath => "filepath"
#设置监听间隔 各字段含义(由左至右)分、时、天、月、年,全部为*默认含义为每分钟都更新
schedule => "* * * * *"
# 索引类型
type => "datainterface"
#插件会在last_run_metadata_path参数所指示的元数据文件中,持久化sql_last_value参数
last_run_metadata_path=>"/usr/local/logstash-6.2.4/last_run_metadata_path_File/datainterface_last_run_metadata"
}
##数据集
jdbc {
# mysql 数据库链接,shop为数据库名
jdbc_connection_string => "jdbc:mysql://ip:3306/kf_data_open?useUnicode=true&characterEncoding=utf8&serverTimezone=UTC"
# 用户名和密码
jdbc_user => "root"
jdbc_password => "12345678"
# 驱动
jdbc_driver_library => "/usr/local/logstash-6.2.4/config/mysql-connector-java-5.1.42.jar"
# 驱动类名
jdbc_driver_class => "com.mysql.jdbc.Driver"
#是否分页
jdbc_paging_enabled => "true"
jdbc_page_size => "50000"
#直接执行sql语句,通过id > :sql_last_value去判断上次执行到了哪里
statement =>"SELECT DISTINCT a.set_id,a.page_views,a.downloads,a.data_num,a.average_score,a.collect_num
,a.update_time,b.file_format,file_name,c.data_provide,c.catalog_status,d.dic_val,e.dic_label
,f.dic_label as dic_label1 from kf_data_set a
INNER JOIN kf_files_info b on a.set_id=b.set_id
inner JOIN kf_data_catalog c on a.catalog_id=c.catalog_id
INNER JOIN kf_catalog_tag d on a.catalog_id=d.catalog_id
INNER JOIN kf_dictionaries e on e.dic_val=d.dic_val
INNER JOIN kf_dictionaries f on f.dic_val=c.data_provide
where a.update_time > :sql_last_value order by a.update_time asc"
#使用列值进行查询记录追踪
use_column_value => true
#设置跟踪记录的列为:id,要先设置use_column_value=true
tracking_column => "update_time"
#默认为number,如果为日期必须声明为timestamp
tracking_column_type => "timestamp"
# 执行的sql 文件路径+名称
#statement_filepath => "filepath"
#设置监听间隔 各字段含义(由左至右)分、时、天、月、年,全部为*默认含义为每分钟都更新
schedule => "* * * * *"
# 索引类型
type => "dataset"
#插件会在last_run_metadata_path参数所指示的元数据文件中,持久化sql_last_value参数
last_run_metadata_path=>"/usr/local/logstash-6.2.4/last_run_metadata_path_File/dataset_last_run_metadata"
}
##数据目录
jdbc {
# mysql 数据库链接,shop为数据库名
jdbc_connection_string => "jdbc:mysql://ip:3306/kf_data_open?useUnicode=true&characterEncoding=utf8&serverTimezone=UTC"
# 用户名和密码
jdbc_user => "root"
jdbc_password => "12345678"
# 驱动
jdbc_driver_library => "/usr/local/logstash-6.2.4/config/mysql-connector-java-5.1.42.jar"
# 驱动类名
jdbc_driver_class => "com.mysql.jdbc.Driver"
#是否分页
jdbc_paging_enabled => "true"
jdbc_page_size => "50000"
#直接执行sql语句,通过id > :sql_last_value去判断上次执行到了哪里
statement =>"SELECT a.catalog_id,a.catalog_name,a.catalog_status,a.page_views,a.data_provide,
a.update_time,b.dic_val,c.dic_label,d.dic_label as dic_label1
from kf_data_catalog a
INNER JOIN kf_catalog_tag b on a.catalog_id=b.catalog_id
INNER JOIN kf_dictionaries c ON b.dic_val=c.dic_val
inner JOIN kf_dictionaries d on a.data_provide=d.dic_val
where a.update_time > :sql_last_value order by a.update_time asc"
#使用列值进行查询记录追踪
use_column_value => true
#设置跟踪记录的列为:id,要先设置use_column_value=true
tracking_column => "update_time"
#默认为number,如果为日期必须声明为timestamp
tracking_column_type => "timestamp"
# 执行的sql 文件路径+名称
#statement_filepath => "filepath"
#设置监听间隔 各字段含义(由左至右)分、时、天、月、年,全部为*默认含义为每分钟都更新
schedule => "* * * * *"
# 索引类型
type => "datacatalog"
#插件会在last_run_metadata_path参数所指示的元数据文件中,持久化sql_last_value参数
last_run_metadata_path=>"/usr/local/logstash-6.2.4/last_run_metadata_path_File/datacatalog_last_run_metadata"
}
}
filter {
##数据接口
if [type]=="datainterface" {
aggregate {
task_id => "%{interface_id}"
code => "
map['interface_id'] = event.get('interface_id')
map['interface_desc'] = event.get('interface_desc')
map['format'] = event.get('format')
map['update_time'] = event.get('update_time')
map['page_views'] = event.get('page_views')
map['transfer_num'] = event.get('transfer_num')
map['collect_num'] = event.get('collect_num')
map['average_score'] = event.get('average_score')
#map['data_provide'] = event.get('data_provide')
map['data_provide'] = {event.get('data_provide')=> event.get('dic_label1')}
map['catalog_status'] = event.get('catalog_status')
#map['dic_val_list'] ||=[]
#if (event.get('dic_val') != nil)
# if !(map['dic_val_list'].include? event.get('dic_val'))
# map['dic_val_list'] << event.get('dic_val')
# end
#end
#map['dic_val_list'] ||=[]
#if (event.get('dic_val') != nil && event.get('dic_label') != nil)
##if !(map['dic_val_list'].include? event.get('dic_val')=> event.get('dic_label'))
#map['dic_val_list'] << {event.get('dic_val')=> event.get('dic_label')}
##end
#end
#val_list用来给dic_val_list去重
map['val_list'] ||=[]
map['dic_val_list'] ||=[]
if (event.get('dic_val') != nil && event.get('dic_label') != nil)
if !(map['val_list'].include? event.get('dic_val'))
map['val_list'] << event.get('dic_val')
map['dic_val_list'] << {event.get('dic_val')=> event.get('dic_label')}
end
end
event.cancel()
"
push_previous_map_as_event => true
timeout => 5
}
#json {
# source => "message"
# remove_field => ["message"]
#remove_field => ["message", "type", "@timestamp", "@version"]
#}
mutate {
#将不需要的JSON字段过滤,且不会被存入 ES 中
remove_field => ["@timestamp", "@version","val_list"]
add_tag => ["datainterface"]
}
}
##数据集
if [type]=="dataset" {
aggregate {
task_id => "%{set_id}"
code => "
map['set_id'] = event.get('set_id')
map['page_views'] = event.get('page_views')
map['downloads'] = event.get('downloads')
map['data_num'] = event.get('data_num')
map['average_score'] = event.get('average_score')
map['collect_num'] = event.get('collect_num')
map['update_time'] = event.get('update_time')
map['file_name'] = event.get('file_name')
#map['data_provide'] = event.get('data_provide')
map['data_provide'] = {event.get('data_provide')=> event.get('dic_label1')}
map['catalog_status'] = event.get('catalog_status')
map['val_list'] ||=[]
map['dic_val_list'] ||=[]
if (event.get('dic_val') != nil && event.get('dic_label') != nil)
if !(map['val_list'].include? event.get('dic_val'))
map['val_list'] << event.get('dic_val')
map['dic_val_list'] << {event.get('dic_val')=> event.get('dic_label')}
end
end
#[] 数组
map['file_format_list'] ||=[]
if (event.get('file_format') != nil)
if !(map['file_format_list'].include? event.get('file_format'))
map['file_format_list'] << event.get('file_format')
end
end
event.cancel()
"
push_previous_map_as_event => true
timeout => 5
}
#json {
# source => "message"
# remove_field => ["message"]
#remove_field => ["message", "type", "@timestamp", "@version"]
#}
mutate {
#将不需要的JSON字段过滤,且不会被存入 ES 中
remove_field => ["@timestamp", "@version","val_list"]
add_tag => ["dataset"]
}
}
##数据目录
if [type]=="datacatalog" {
aggregate {
task_id => "%{catalog_id}"
code => "
map['catalog_id'] = event.get('catalog_id')
map['catalog_name'] = event.get('catalog_name')
map['catalog_status'] = event.get('catalog_status')
map['page_views'] = event.get('page_views')
map['data_provide'] = {event.get('data_provide')=> event.get('dic_label1')}
map['update_time'] = event.get('update_time')
#map['dic_val_list'] ||=[]
#if (event.get('dic_val') != nil && event.get('dic_label') != nil)
##if !(map['dic_val_list'].include? event.get('dic_val')=> event.get('dic_label'))
#map['dic_val_list'] << {event.get('dic_val')=> event.get('dic_label')}
##end
#end
map['val_list'] ||=[]
map['dic_val_list'] ||=[]
if (event.get('dic_val') != nil && event.get('dic_label') != nil)
if !(map['val_list'].include? event.get('dic_val'))
map['val_list'] << event.get('dic_val')
map['dic_val_list'] << {event.get('dic_val')=> event.get('dic_label')}
end
end
event.cancel()
"
push_previous_map_as_event => true
timeout => 5
}
#json {
# source => "message"
# remove_field => ["message"]
#remove_field => ["message", "type", "@timestamp", "@version"]
#}
mutate {
#将不需要的JSON字段过滤,且不会被存入 ES 中
remove_field => ["@timestamp", "@version","val_list"]
#output的时候用
add_tag => ["datacatalog"]
}
}
}
output {
#将数据库的数据输出在控制台
stdout {
codec => json_lines
}
#将数据库数据存储到es
if "datainterface" in [tags] {
elasticsearch {
#ESIP地址与端口
hosts => ["ip:9200"]
#ES索引名称(自己定义的)
index => "datainterface"
#document_type => "doc"
#自增ID编号
document_id => "%{interface_id}"
}
}
if "dataset" in [tags] {
elasticsearch {
#ESIP地址与端口
hosts => ["ip:9200"]
#ES索引名称(自己定义的)
index => "dataset"
#document_type => "doc"
#自增ID编号
document_id => "%{set_id}"
}
}
if "datacatalog" in [tags] {
elasticsearch {
#ESIP地址与端口
hosts => ["ip:9200"]
#ES索引名称(自己定义的)
index => "datacatalog"
#document_type => "doc"
#自增ID编号
document_id => "%{catalog_id}"
}
}
}
参考来源:
Logstash同步mysql一对多数据到ES(踩坑日记系列):
https://blog.csdn.net/menglinjie/article/details/102984845
使用 logstash-input-jdbc 同步 mysql 数据 至 ES 最后一条数据未能保存:
https://segmentfault.com/q/1010000016861266
我的备份:
input {
##数据接口
jdbc {
# mysql 数据库链接,shop为数据库名
jdbc_connection_string => "jdbc:mysql://ip:3306/kf_data_open?useUnicode=true&characterEncoding=utf8&serverTimezone=UTC"
# 用户名和密码
jdbc_user => "root"
jdbc_password => "12345678"
# 驱动
jdbc_driver_library => "/usr/local/logstash-6.2.4/config/mysql-connector-java-5.1.42.jar"
# 驱动类名
jdbc_driver_class => "com.mysql.jdbc.Driver"
#是否分页
jdbc_paging_enabled => "true"
jdbc_page_size => "50000"
#直接执行sql语句,通过id > :sql_last_value去判断上次执行到了哪里
statement =>"select DISTINCT a.interface_id,a.interface_desc,a.format,a.update_time,a.page_views,a.transfer_num,
a.collect_num,a.average_score,b.data_provide,b.catalog_status,c.dic_val,d.dic_label,e.dic_label as dic_label1 from kf_data_interface a
INNER JOIN kf_data_catalog b ON a.catalog_id=b.catalog_id
INNER JOIN kf_catalog_tag c ON a.catalog_id=c.catalog_id
INNER JOIN kf_dictionaries d on d.dic_val=c.dic_val
INNER JOIN kf_dictionaries e on e.dic_val=b.data_provide
where a.update_time > :sql_last_value order by a.update_time asc"
#使用列值进行查询记录追踪
use_column_value => true
#设置跟踪记录的列为:id,要先设置use_column_value=true
tracking_column => "update_time"
#默认为number,如果为日期必须声明为timestamp
tracking_column_type => "timestamp"
# 执行的sql 文件路径+名称
#statement_filepath => "filepath"
#设置监听间隔 各字段含义(由左至右)分、时、天、月、年,全部为*默认含义为每分钟都更新 0 3 * * * 凌晨3点同步
schedule => "* * * * *"
# 索引类型
type => "datainterface"
#插件会在last_run_metadata_path参数所指示的元数据文件中,持久化sql_last_value参数
last_run_metadata_path=>"/usr/local/logstash-6.2.4/last_run_metadata_path_File/datainterface_last_run_metadata"
}
##数据集
jdbc {
# mysql 数据库链接,shop为数据库名
jdbc_connection_string => "jdbc:mysql://ip:3306/kf_data_open?useUnicode=true&characterEncoding=utf8&serverTimezone=UTC"
# 用户名和密码
jdbc_user => "root"
jdbc_password => "12345678"
# 驱动
jdbc_driver_library => "/usr/local/logstash-6.2.4/config/mysql-connector-java-5.1.42.jar"
# 驱动类名
jdbc_driver_class => "com.mysql.jdbc.Driver"
#是否分页
jdbc_paging_enabled => "true"
jdbc_page_size => "50000"
#直接执行sql语句,通过id > :sql_last_value去判断上次执行到了哪里
statement =>"SELECT DISTINCT a.set_id,a.page_views,a.downloads,a.data_num,a.average_score,a.collect_num
,a.update_time,b.file_format,file_name,c.data_provide,c.catalog_status,d.dic_val,e.dic_label
,f.dic_label as dic_label1 from kf_data_set a
INNER JOIN kf_files_info b on a.set_id=b.set_id
inner JOIN kf_data_catalog c on a.catalog_id=c.catalog_id
INNER JOIN kf_catalog_tag d on a.catalog_id=d.catalog_id
INNER JOIN kf_dictionaries e on e.dic_val=d.dic_val
INNER JOIN kf_dictionaries f on f.dic_val=c.data_provide
where a.update_time > :sql_last_value order by a.update_time asc"
#使用列值进行查询记录追踪
use_column_value => true
#设置跟踪记录的列为:id,要先设置use_column_value=true
tracking_column => "update_time"
#默认为number,如果为日期必须声明为timestamp
tracking_column_type => "timestamp"
# 执行的sql 文件路径+名称
#statement_filepath => "filepath"
#设置监听间隔 各字段含义(由左至右)分、时、天、月、年,全部为*默认含义为每分钟都更新
schedule => "* * * * *"
# 索引类型
type => "dataset"
#插件会在last_run_metadata_path参数所指示的元数据文件中,持久化sql_last_value参数
last_run_metadata_path=>"/usr/local/logstash-6.2.4/last_run_metadata_path_File/dataset_last_run_metadata"
}
##数据目录
jdbc {
# mysql 数据库链接,shop为数据库名
jdbc_connection_string => "jdbc:mysql://ip:3306/kf_data_open?useUnicode=true&characterEncoding=utf8&serverTimezone=UTC"
# 用户名和密码
jdbc_user => "root"
jdbc_password => "12345678"
# 驱动
jdbc_driver_library => "/usr/local/logstash-6.2.4/config/mysql-connector-java-5.1.42.jar"
# 驱动类名
jdbc_driver_class => "com.mysql.jdbc.Driver"
#是否分页
jdbc_paging_enabled => "true"
jdbc_page_size => "50000"
#直接执行sql语句,通过id > :sql_last_value去判断上次执行到了哪里
statement =>"SELECT a.catalog_id,a.catalog_name,a.catalog_status,a.page_views,a.data_provide,
a.update_time,b.dic_val,c.dic_label,d.dic_label as dic_label1
from kf_data_catalog a
INNER JOIN kf_catalog_tag b on a.catalog_id=b.catalog_id
INNER JOIN kf_dictionaries c ON b.dic_val=c.dic_val
inner JOIN kf_dictionaries d on a.data_provide=d.dic_val
where a.update_time > :sql_last_value order by a.update_time asc"
#使用列值进行查询记录追踪
use_column_value => true
#设置跟踪记录的列为:id,要先设置use_column_value=true
tracking_column => "update_time"
#默认为number,如果为日期必须声明为timestamp
tracking_column_type => "timestamp"
# 执行的sql 文件路径+名称
#statement_filepath => "filepath"
#设置监听间隔 各字段含义(由左至右)分、时、天、月、年,全部为*默认含义为每分钟都更新
schedule => "* * * * *"
# 索引类型
type => "datacatalog"
#插件会在last_run_metadata_path参数所指示的元数据文件中,持久化sql_last_value参数
last_run_metadata_path=>"/usr/local/logstash-6.2.4/last_run_metadata_path_File/datacatalog_last_run_metadata"
}
}
filter {
##数据接口
if [type]=="datainterface" {
aggregate {
task_id => "%{interface_id}"
code => "
map['interfaceId'] = event.get('interface_id')
map['interfaceDesc'] = event.get('interface_desc')
map['format'] = event.get('format')
map['updateTime'] = event.get('update_time')
map['pageViews'] = event.get('page_views')
map['transferNum'] = event.get('transfer_num')
map['collectNum'] = event.get('collect_num')
map['averageScore'] = event.get('average_score')
#map['dataProvide'] = event.get('data_provide')
map['dataProvide'] = {event.get('data_provide')=> event.get('dic_label1')}
map['catalogStatus'] = event.get('catalog_status')
#map['dic_val_list'] ||=[]
#if (event.get('dic_val') != nil)
# if !(map['dic_val_list'].include? event.get('dic_val'))
# map['dic_val_list'] << event.get('dic_val')
# end
#end
#map['dic_val_list'] ||=[]
#if (event.get('dic_val') != nil && event.get('dic_label') != nil)
##if !(map['dic_val_list'].include? event.get('dic_val')=> event.get('dic_label'))
#map['dic_val_list'] << {event.get('dic_val')=> event.get('dic_label')}
##end
#end
map['val_list'] ||=[]
map['dicValList'] ||=[]
if (event.get('dic_val') != nil && event.get('dic_label') != nil)
if !(map['val_list'].include? event.get('dic_val'))
map['val_list'] << event.get('dic_val')
map['dicValList'] << {event.get('dic_val')=> event.get('dic_label')}
end
end
event.cancel()
"
push_previous_map_as_event => true
timeout => 5
}
#json {
# source => "message"
# remove_field => ["message"]
#remove_field => ["message", "type", "@timestamp", "@version"]
#}
mutate {
#将不需要的JSON字段过滤,且不会被存入 ES 中
remove_field => ["@timestamp", "@version","val_list"]
add_tag => ["datainterface"]
}
}
##数据集
if [type]=="dataset" {
aggregate {
task_id => "%{set_id}"
code => "
map['setId'] = event.get('set_id')
map['pageViews'] = event.get('page_views')
map['downloads'] = event.get('downloads')
map['dataNum'] = event.get('data_num')
map['averageScore'] = event.get('average_score')
map['collectNum'] = event.get('collect_num')
map['updateTime'] = event.get('update_time')
map['fileName'] = event.get('file_name')
#map['dataProvide'] = event.get('data_provide')
map['dataProvide'] = {event.get('data_provide')=> event.get('dic_label1')}
map['catalogStatus'] = event.get('catalog_status')
map['val_list'] ||=[]
map['dicValList'] ||=[]
if (event.get('dic_val') != nil && event.get('dic_label') != nil)
if !(map['val_list'].include? event.get('dic_val'))
map['val_list'] << event.get('dic_val')
map['dicValList'] << {event.get('dic_val')=> event.get('dic_label')}
end
end
#[] 数组
map['fileFormatList'] ||=[]
if (event.get('file_format') != nil)
if !(map['fileFormatList'].include? event.get('file_format'))
map['fileFormatList'] << event.get('file_format')
end
end
event.cancel()
"
push_previous_map_as_event => true
timeout => 5
}
#json {
# source => "message"
# remove_field => ["message"]
#remove_field => ["message", "type", "@timestamp", "@version"]
#}
mutate {
#将不需要的JSON字段过滤,且不会被存入 ES 中
remove_field => ["@timestamp", "@version","val_list"]
add_tag => ["dataset"]
}
}
##数据目录
if [type]=="datacatalog" {
aggregate {
task_id => "%{catalog_id}"
code => "
map['catalogId'] = event.get('catalog_id')
map['catalogName'] = event.get('catalog_name')
map['catalogStatus'] = event.get('catalog_status')
map['pageViews'] = event.get('page_views')
map['dataProvide'] = {event.get('data_provide')=> event.get('dic_label1')}
map['updateTime'] = event.get('update_time')
#map['dic_val_list'] ||=[]
#if (event.get('dic_val') != nil && event.get('dic_label') != nil)
##if !(map['dic_val_list'].include? event.get('dic_val')=> event.get('dic_label'))
#map['dic_val_list'] << {event.get('dic_val')=> event.get('dic_label')}
##end
#end
map['val_list'] ||=[]
map['dicValList'] ||=[]
if (event.get('dic_val') != nil && event.get('dic_label') != nil)
if !(map['val_list'].include? event.get('dic_val'))
map['val_list'] << event.get('dic_val')
map['dicValList'] << {event.get('dic_val')=> event.get('dic_label')}
end
end
event.cancel()
"
push_previous_map_as_event => true
timeout => 5
}
#json {
# source => "message"
# remove_field => ["message"]
#remove_field => ["message", "type", "@timestamp", "@version"]
#}
mutate {
#将不需要的JSON字段过滤,且不会被存入 ES 中
remove_field => ["@timestamp", "@version","val_list"]
add_tag => ["datacatalog"]
}
}
}
output {
#将数据库的数据输出在控制台
stdout {
codec => json_lines
}
#将数据库数据存储到es
if "datainterface" in [tags] {
elasticsearch {
#ESIP地址与端口
hosts => ["ip:9200"]
#ES索引名称(自己定义的)
index => "datainterface"
#document_type => "doc"
#自增ID编号
document_id => "%{interfaceId}"
}
}
if "dataset" in [tags] {
elasticsearch {
#ESIP地址与端口
hosts => ["ip:9200"]
#ES索引名称(自己定义的)
index => "dataset"
#document_type => "doc"
#自增ID编号
document_id => "%{setId}"
}
}
if "datacatalog" in [tags] {
elasticsearch {
#ESIP地址与端口
hosts => ["ip:9200"]
#ES索引名称(自己定义的)
index => "datacatalog"
#document_type => "doc"
#自增ID编号
document_id => "%{catalogId}"
}
}
}