Scrapy爬虫实战之新片场爬虫
一、Scrapy通览
1. 简介
Scrapy是一个快速的高级Web爬网和Web爬网框架,用于爬取网站并从其页面提取结构化数据。它可以用于数据挖掘、数据监视和自动化测试。
使用Scrapy之前你要清楚这么一件事,Scrapy框架和你自己编写的区别,我理解的区别就是没什么区别,你编写的爬虫也是为了抓取数据,框架也是为了抓取数据,唯一有一定不同的就是,不管是我们现在所说的Scrapy框架还是其他的爬虫框架都是使爬虫功能模块话,把各种爬虫需求分开来,你只要使用你的项目所需要的模块就够了!
先上一张官方的架构图

图中绿色的是数据的流向。
我们看到图里有这么几个东西,分别是:
- Spiders:爬虫,定义了爬取的逻辑和网页内容的解析规则,主要负责解析响应并生成结果和新的请求。
- Engine:引擎,处理整个系统的数据流处理,出发事物,框架的核心。
- Scheduler:调度器,接受引擎发过来的请求,并将其加入队列中,在引擎再次请求时将请求提供给引擎。
- Downloader:下载器,下载网页内容,并将下载内容返回给spider
- ItemPipeline:项目管道,负责处理spider从网页中抽取的数据,主要是负责清洗,验证和向数据库中存储数据。
- Downloader Middlewares:下载中间件,是处于Scrapy的Request和Requesponse之间的处理模块。
- Spider Middlewares:spider中间件,位于引擎和spider之间的框架,主要处理spider输入的响应和输出的结果及新的请求middlewares.py里实现。
是不感觉东西很多,很乱,有点懵!没关系,框架之所以是框架因为确实很简单
我们再来看下面的这张图!你或许就懂了!
最后我们来顺一下Scrapy框架的整体执行流程:
- Spiders的yeild将request发送给Engine
- Engine对request不做任何处理发送给scheduler
- Scheduler,生成request交给Engine
- Engine拿到request,通过Middleware发送给Downloader
- Downloader在获取到response之后,又经过Middleware发送给Engine
- Engine获取到response之后,返回给spider,spider的parse()方法对获取到的response进行处理,解析出items或者requests
- 将解析出来的items或者requests发送给Engine
- Engine获取到items或者requests,将items发送给ItemPipeline,将requests发送给scheduler(ps,只有调度器中不存在request时,程序才停止,及时请求失败Scrapy也会重新进行请求)
2. 常用命令
常见的Scrapy终端命令如下:
- 创建项目:
scrapy startproject xxx - 进入项目:
cd xxx #进入某个文件夹下 - 创建爬虫:
scrapy genspider xxx(爬虫名) xxx.com (爬取网址) - 生成文件:
scrapy crawl xxx -o xxx.json (生成某种类型的文件) - 运行爬虫:
scrapy crawl XXX - 列出所有爬虫:
scrapy list - 获得配置信息:
scrapy settings [options]
二、项目背景
最近自学了Python爬虫的相关知识,学完之后迫切需要写个项目实战练手。新片场这个网站相对淘宝京东等网站来说简单些许,也比较适合拿来做新手项目。
三、项目需知
-
动态页面:HTML文档中的部分是由客户端运行JS脚本生成的,即服务器生成部分HTML文档内容,其余的再由客户端生成。
-
静态页面:整个HTML文档是在服务器端生成的,即服务器生成好了,再发送给我们客户端。
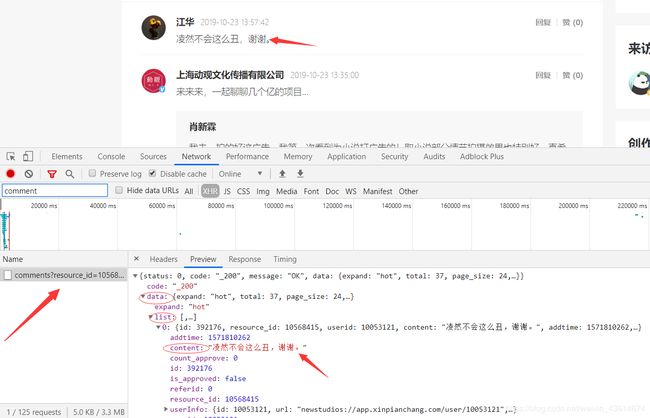
静态页面相对于动态页面简单的多,动态页面需要更加麻烦的解析过程。比如说本项目的视频评论区内容,评论内容是动态加载的,动态加载就是通过ajax请求接口拿到数据喧染在网页上。我们就可以通过游览器的开发者工具分析,在我们向下拉动窗口时就会出现这么个请求,如图所示:
四、项目结构

五、项目配置
- 这是个Scrapy框架爬虫,Scrapy当然是刚需。Scrapy 是一个使用 Python 语言开发,为了爬取网站数据,提取结构性数据而编写的应用框架,它用途广泛,比如:数据挖掘、监测和自动化测试。安装使用终端命令
pip install Scrapy即可。 - 项目所用开发工具为Pycharm,Python版本为3.7.4
- 数据库:本项目采用的数据库为MySQL,版本见图。附安装教程

- 如果是初次使用MySQL,应该会出现时区错误的bug,我这么说当然我也是趟过雷的

解决方法: 亲测有效
六、项目主体
6.1 items.py
- Scrapy中的Items是什么?
Item对象是用于收集所抓取的数据的简单容器。它们提供了一个类似python字典的API,具有用于声明其可用字段的方便的语法。 - Scrapy中Items存在的好处?
Scrapy爬虫可以将提取的数据作为Python语句返回。虽然方便和熟悉,但由于dict缺乏结构。很容易在字段名称中输入错误或返回不一致的数据,特别是在与许多爬虫的大项目。 - 本项目大致分为四个模块,分别为视频信息模块、视频评论信息模块、视频制作人信息模块和视频制作人结合信息模块。
- 话不多说,直接上代码!
# -*- coding: utf-8 -*-
"""
Author:小安
Create_time: 2019/10/22
"""
import scrapy
# 导入这个库可以让下面的scrapy.Field()简写为Field()
from scrapy import Field
class PostItem(scrapy.Item):
"""保存视频信息的item"""
table_name = 'posts'
pid = Field()
title = Field()
thumbnail = Field()
preview = Field()
video = Field()
video_format = Field()
duration = Field()
category = Field()
created_at = Field()
play_counts = Field()
like_counts = Field()
description = Field()
class CommentItem(scrapy.Item):
"""保存评论信息"""
table_name = 'comments'
commentid = Field()
pid = Field()
cid = Field()
avatar = Field()
uname = Field()
created_at = Field()
content = Field()
like_counts = Field()
reply = Field()
class ComposerItem(scrapy.Item):
"""保存制作人信息"""
table_name = 'composers'
cid = Field()
banner = Field()
avatar = Field()
verified = Field()
name = Field()
intro = Field()
like_counts = Field()
fans_counts = Field()
follow_counts = Field()
location = Field()
career = Field()
class CopyrightItem(scrapy.Item):
"""保存视频和制作人联合信息"""
table_name = 'copyrights'
pcid = Field()
pid = Field()
cid = Field()
roles = Field()
6.2 discovery.py
这是项目的主体解析爬取文件,包括网站的解析,字段的匹配等都是在这个文件中完成的。
代码如下:
# -*- coding: utf-8 -*-
"""
Author:小安
Create_time: 2019/10/22
"""
import re
import random
import string
import json
import scrapy
from scrapy import Request
from xpc.items import ComposerItem, PostItem, CommentItem, CopyrightItem
# strip()删除开头或是结尾的字符
def strip(s):
if s:
return s.strip()
return ''
# 判断元素类型,然后进行转换
def convert_int(s):
if isinstance(s, str):
return int(s.replace(',', ''))
return 0
# 根据自己注册的新片场账号在浏览器中找到cookies
cookies = dict(
Authorization='A37AB29030DC8844A30DC843CB30DC8B2D630DC861E78138BA33'
)
# 创建一个随机的26位的字母和数字的字符串
def gen_sessionid():
return ''.join(random.choices(string.ascii_lowercase + string.digits, k=26))
class DiscoverySpider(scrapy.Spider):
name = 'discovery'
allowed_domains = ['xinpianchang.com', 'openapi-vtom.vmovier.com']
start_urls = ['http://www.xinpianchang.com/channel/index/sort-like?from=tabArticle']
page_count = 0
def parse(self, response):
# from scrapy.shell import inspect_response
# inspect_response(response, self)
self.page_count += 1
if self.page_count >= 100:
# 不断更新cookies
cookies.update(PHPSESSID=gen_sessionid())
self.page_count = 0
# 视频列表
post_list = response.xpath(
'//ul[@class="video-list"]/li')
url = "http://www.xinpianchang.com/a%s?from=ArticleList"
for post in post_list:
# pid为视频url链接中的数字码,对应上面url中的%s
pid = post.xpath('./@data-articleid').get()
request = response.follow(url % pid, self.parse_post)
request.meta['pid'] = pid
request.meta['thumbnail'] = post.xpath('./a/img/@_src').get()
yield request
pages = response.xpath(
'//div[@class="page"]/a/@href').extract()
for page in pages:
yield response.follow(page, self.parse, cookies=cookies)
def parse_post(self, response):
pid = response.meta['pid']
post = PostItem(pid=pid)
# 视频预览图
post['thumbnail'] = response.meta['thumbnail']
# 作品名称
post['title'] = response.xpath(
'//div[@class="title-wrap"]/h3/text()').get()
vid, = re.findall('vid: \"(\w+)\"\,', response.text)
video_url = 'https://openapi-vtom.vmovier.com/v3/video/%s?expand=resource,resource_origin?'
# 视频分类
cates = response.xpath(
'//span[contains(@class, "cate")]//text()').extract()
post['category'] = ''.join([cate.strip() for cate in cates])
# 作品发布时间
post['created_at'] = response.xpath(
'//span[contains(@class, "update-time")]/i/text()').get()
# 视频播放次数
post['play_counts'] = convert_int(response.xpath(
'//i[contains(@class, "play-counts")]/@data-curplaycounts').get())
# 视频被喜欢次数
post['like_counts'] = convert_int(response.xpath(
'//span[contains(@class, "like-counts")]/@data-counts').get())
# 视频简介
post['description'] = strip(response.xpath(
'//p[contains(@class, "desc")]/text()').get())
request = Request(video_url % vid, callback=self.parse_video)
request.meta['post'] = post
yield request
comment_url = 'http://www.xinpianchang.com/article/filmplay/ts-getCommentApi?id=%s&page=1'
request = Request(comment_url % pid, callback=self.parse_comment)
request.meta['pid'] = pid
yield request
creator_list = response.xpath(
'//div[@class="user-team"]//ul[@class="creator-list"]/li')
composer_url = 'http://www.xinpianchang.com/u%s?from=articleList'
for creator in creator_list:
# cid为制作人页面链接中的数字码对应上面composer_url中的%s
cid = creator.xpath('./a/@data-userid').get()
request = response.follow(composer_url % cid, self.parse_composer)
request.meta['cid'] = cid
request.meta['dont_merge_cookies'] = True
yield request
cr = CopyrightItem()
cr['pcid'] = '%s_%s' % (pid, cid)
cr['pid'] = pid
cr['cid'] = cid
# 制片人/方承担角色
cr['roles'] = creator.xpath(
'./div[@class="creator-info"]/span/text()').get()
yield cr
def parse_video(self, response):
post = response.meta['post']
result = json.loads(response.text)
data = result['data']
if 'resource' in data:
post['video'] = data['resource']['default']['url']
else:
d = data['third']['data']
# 有的链接为iframe_url做键名也有swf做
post['video'] = d.get('iframe_url', d.get('swf', ''))
post['preview'] = result['data']['video']['cover']
post['duration'] = result['data']['video']['duration']
yield post
def parse_comment(self, response):
result = json.loads(response.text)
for c in result['data']['list']:
comment = CommentItem()
# 评论者姓名
comment['uname'] = c['userInfo']['username']
# 头像链接
comment['avatar'] = c['userInfo']['face']
# ID
comment['cid'] = c['userInfo']['userid']
comment['commentid'] = c['commentid']
comment['pid'] = c['articleid']
# 评论发表时间
comment['created_at'] = c['addtime_int']
# 点赞数量
comment['like_counts'] = c['count_approve']
# 评论内容
comment['content'] = c['content']
# 评论后的追评
if c['reply']:
comment['reply'] = c['reply']['commentid'] or 0
yield comment
# 翻页爬取
next_page = result['data']['next_page_url']
if next_page:
yield response.follow(next_page, self.parse_comment)
# 解析视频创作人信息
def parse_composer(self, response):
banner = response.xpath(
'//div[@class="banner-wrap"]/@style').get()
composer = ComposerItem()
composer['cid'] = response.meta['cid']
# 创作人主页上面背景图片链接
composer['banner'], = re.findall('background-image:url\((.+?)\)', banner)
composer['avatar'] = response.xpath(
'//span[@class="avator-wrap-s"]/img/@src').get()
# 创作人的名字
composer['name'] = response.xpath(
'//p[contains(@class, "creator-name")]/text()').get()
# 创作人个人简介
composer['intro'] = response.xpath(
'//p[contains(@class, "creator-desc")]/text()').get()
# 创作人人气值
composer['like_counts'] = convert_int(response.xpath(
'//span[contains(@class, "like-counts")]/text()').get())
# 粉丝数
composer['fans_counts'] = convert_int(response.xpath(
'//span[contains(@class, "fans-counts")]/text()').get())
# 关注人数
composer['follow_counts'] = convert_int(response.xpath(
'//span[@class="follow-wrap"]/span[last()]/text()').get())
# 定居地
composer['location'] = response.xpath(
'//span[contains(@class,"icon-location")]/'
'following-sibling::span[1]/text()').get() or ''
# 职业
composer['career'] = response.xpath(
'//span[contains(@class,"icon-career")]/'
'following-sibling::span[1]/text()').get() or ''
yield composer
6.3 piplines.py
当一个item被蜘蛛爬取到之后会被发送给Item Pipeline,然后多个组件按照顺序处理这个item。
Item Pipeline常用场景 :
-
清洗HTML数据
-
验证被抓取的数据(检查item是否包含某些字段)
-
重复性检查(然后丢弃)
-
将抓取的数据存储到数据库中
代码如下:
# -*- coding: utf-8 -*-
"""
Author:小安
Create_time: 2019/10/22
"""
"""
使用Python DB AP访问数据库流程:
开始------->创建数据库连接connection------>获取cursor------>处理数据(增删查改)------->关闭cursor------>关闭connection------>结束
"""
import pymysql
import redis
from scrapy.exceptions import DropItem
class RedisPipeline(object):
def open_spider(self, spider):
self.r = redis.Redis(host='127.0.0.1')
# def close_spider(self, spider):
# self.r.close()
def process_item(self, item, spider):
if self.r.sadd(spider.name, item['name']):
return item
raise DropItem
class MysqlPipeline(object):
def open_spider(self, spider):
self.conn = pymysql.connect(
host='127.0.0.1',
port=3306,
db='xpc',
user='root',
password='199819',
# utf8mb4是为了支持特殊符号,专门用来兼容四字节的unicode
charset='utf8mb4',
)
# 游标对象cursor:用于执行查询和获取结果
self.cur = self.conn.cursor()
def close_spider(self, spider):
self.cur.close()
self.conn.close()
def process_item(self, item, spider):
# keys = item.keys()
# values = [item[k] for k in keys]
keys, values = zip(*item.items())
sql = "insert into `{}` ({}) values ({}) " \
"ON DUPLICATE KEY UPDATE {}".format(
item.table_name,
','.join(keys),
','.join(['%s'] * len(values)),
','.join(['`{}`=%s'.format(k) for k in keys])
)
self.cur.execute(sql, values * 2)
self.conn.commit()
print(self.cur._last_executed)
return item
6.4 settings.py
一定要取消下面代码段的注释,这样piplines.py文件才会生效。
ITEM_PIPELINES = {
'xpc.pipelines.MysqlPipeline': 300,
}
6.5 数据库文件 db.sql
本项目使用的数据库名称为xpc,命名自行决定。
CREATE DATABASE IF NOT EXISTS `xpc`;
USE `xpc`;
CREATE TABLE IF NOT EXISTS `posts` (
`pid` BIGINT UNSIGNED NOT NULL DEFAULT 0 COMMENT '作品表主键',
`title` VARCHAR(256) NOT NULL COMMENT '作品标题',
`thumbnail` VARCHAR(512) COMMENT '视频缩略图',
`preview` VARCHAR(512) COMMENT '视频预览图',
`video` VARCHAR(512) COMMENT '视频链接',
`video_format` VARCHAR(32) COMMENT '视频格式:4K 等',
`category` VARCHAR(512) NOT NULL DEFAULT '' COMMENT '作品分类',
`duration` INT(11) NOT NULL DEFAULT 0 COMMENT '播放时长',
`created_at` VARCHAR(128) NOT NULL DEFAULT '' COMMENT '发表时间',
`description` text COMMENT '作品描述',
`play_counts` INT(8) NOT NULL DEFAULT 0 COMMENT '播放次数',
`like_counts` INT(8) NOT NULL DEFAULT 0 COMMENT '被点赞次数',
PRIMARY KEY (`pid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT '作品表';
CREATE TABLE IF NOT EXISTS `composers` (
`cid` BIGINT UNSIGNED NOT NULL DEFAULT 0 COMMENT '创作者表主键',
`banner` VARCHAR(512) NOT NULL COMMENT '用户主页banner图片',
`avatar` VARCHAR(512) NOT NULL DEFAULT '' COMMENT '用户头像',
`verified` VARCHAR(128) COMMENT '是否加V',
`name` VARCHAR(128) NOT NULL COMMENT '名字',
`intro` TEXT COMMENT '自我介绍',
`like_counts` INT(8) NOT NULL DEFAULT 0 COMMENT '被点赞次数',
`fans_counts` INT(8) NOT NULL DEFAULT 0 COMMENT '被关注数量',
`follow_counts` INT(8) NOT NULL DEFAULT 0 COMMENT '关注数量',
`location` VARCHAR(512) NOT NULL DEFAULT '' COMMENT '所在位置',
`career` VARCHAR(512) NOT NULL DEFAULT '' COMMENT '职业',
PRIMARY KEY (`cid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT '用户表';
CREATE TABLE IF NOT EXISTS `comments` (
`commentid` int(11) NOT NULL COMMENT '评论表主键',
`pid` BIGINT UNSIGNED NOT NULL DEFAULT 0 COMMENT '评论的作品ID',
`cid` BIGINT UNSIGNED NOT NULL DEFAULT 0 COMMENT '评论人ID',
`avatar` VARCHAR(512) COMMENT '评论人头像',
`uname` VARCHAR(512) COMMENT '评论人名称',
`created_at` VARCHAR(128) NOT NULL DEFAULT '' COMMENT '发表时间',
`content` TEXT COMMENT '评论内容',
`like_counts` INT(8) NOT NULL DEFAULT 0 COMMENT '被点赞次数',
`reply` INT(8) NOT NULL DEFAULT 0 COMMENT '回复其他评论的ID,如果不是则为0',
PRIMARY KEY (`commentid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT '评论表';
CREATE TABLE IF NOT EXISTS `copyrights` (
`pcid` VARCHAR(32) NOT NULL COMMENT '主键,由pid_cid组成',
`pid` BIGINT UNSIGNED NOT NULL DEFAULT 0 COMMENT '对应作品表主键',
`cid` BIGINT UNSIGNED NOT NULL DEFAULT 0 COMMENT '对应作者表主键',
`roles` VARCHAR(32) COMMENT '担任角色',
PRIMARY KEY (`pcid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT '著作权关系表';
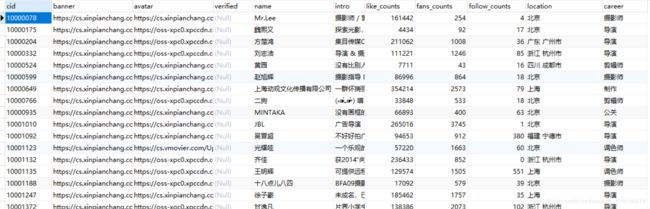
七、爬取成功后的部分数据截图