图像超分中的深度学习网络
图像超分中的深度学习网络
- 质量评估
- 操作通道
- 有监督算法
- 预上采样
- 后采样超分
- 逐步上采样
- 迭代上下采样
- 上采样的学习方式
- 残差块
- 递归学习
- 多路径学习
- 密集连接
- 通道注意力机制
- 其他卷积
- 像素递归网络
- 金字塔池化
- 小波变换
- 损失函数
- Pixel Loss
- Content Loss
- Texture Loss
- Adversarial Loss
- Cycle Consistency Loss
- Total Variation Loss
- Prior-Based Loss
- 提高的策略
- BN批量归一化
- Curriculum Learning
- Multi-supervision
- 基于上下文的网络融合
- 扩大训练集
- 网络插值
- 增强预测
- 非监督学习
- Zero-shot Super-resolution
- Weakly-supervised Super-resolution
- 运用的场景
论文:Deep Learning for Image Super-resolution:A Survey
1.通常,使用深度学习技术的SR算法的系列在以下主要方面彼此不同:不同类型的网络体系结构[、不同类型 损失函数、不同类型的学习原则和策略等
质量评估
2.质量评估:主流的还是PSNR和SSIM
PSNR:通过最大可能像素值(表示为L)和图像之间的平均平方误差(MSE)来定义PSNR。一般情况下
使用8位图像表示,L=255,PSNR的典型值从20到40不等,其中越高越好。但仅关心相同
位置的像素值之间的差异,而不是人的视觉感知(即,图像的外观如何)。
SSIM: 在图像之间的结构相似性,基于三个相对独立的比较,即亮度、对比度和结构。
(也提出了MSSIM,它将图像分割为多个窗口,评估每个窗口的SSIM,最后将它们平均为最终的MSIM。)
MOS:平均意见得分,人主观给图片打分
Task-based Evaluation基于任务的评价:评估重建性能。具体来说,研究人员将原始和重建的HR图像输入一个经过训练的模型,并通过比较对预测性能的影响来评估重建质量。
其他:多尺度结构相似性(MSSSIM)、信息保真度准则(IFC)和视觉信息保真度(VIF)、特征相似度(FSIM)
操作通道
3.操作通道:RGB和YCrCb。较早的模型有利于在YCbCr空间操作,但最近的模型倾向于在RGB通道上操作。
有监督算法
4.有监督算法:它们本质上是一组组件的组合,例如模型框架、上采样方法、网络设计和学习策略等。
预上采样
1)预上采样Pre-upsampling Super-resolution:在所有处理操作前,进行上采样。具体地,使用传统方法(例如,双三次插值)将LR图像向上采样到具有期望大小的粗HR图像,然后在这些图像上应用深度CNN以用于重建高质量图像。
减少了学习难度,且可以输入任意比例图像,但同时也会放大噪声,且由于大多数操作在高维图像上,时间和空间复杂度较高

后采样超分
2)后采样超分Post-Upsampling Super-resolution:上采样层被置于网络末端用来产生输出图像,并带有可学习参数。这样做不仅可以让网络能够自适应的学习上采样过程,还能让特征提取过程在低维空间上进行,极大的降低计算负担。它还带来了相当快的训练速度和推理速度。但这种方法不能适应不同的放大倍数,要为每一种放大倍数重新训练一次模型

逐步上采样
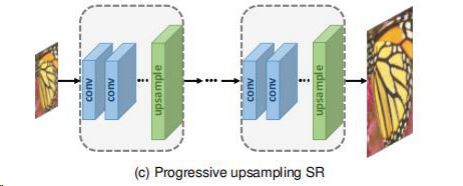
3)逐步上采样Progressive Upsampling Super-resolution:模型通过多次上采样逐步获得目标尺寸的超分辨图像,这种设计不仅能降低学习难度,还能从一定程度上兼容不同的放大倍数。此外,这种多阶段学习的网络结构设计可以结合一些特定的学习方法(诸如课程学习、多监督学习)进一步降低学习难度。拉普拉斯金字塔SR网络Laplacian pyramid SR network (LapSRN)用的这个结构,此框架下的模型基于CNN的级联,并逐渐重建更高分辨率的图像,在每个阶段,图像被向上采样到更高的分辨率,并且被CNN细化。通过将困难的任务分解为简单的任务,该框架下的模型不仅大大降低了学习难度,而且获得了更好的性能,解决了多尺度超分辨率问题,而不引入过多的空间和时间成本,然而,这些模型也遇到了一些问题,例如多个阶段的复杂模型设计和训练难度,因此需要更多的结构设计以及训练策略
迭代上下采样
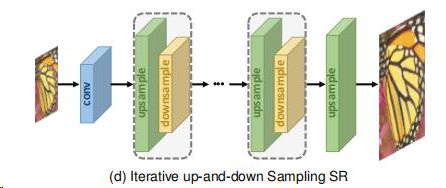
4)迭代上下采样超分辨率Iterative Up-and-down Sampling Super-resolution:更好地挖掘深LR-HR关系,尝试迭代地应用反向投影细化,即,计算重构误差,然后将其重新融合以调整HR图像强度。向上和向下采样层,并提出深背投影网络(DBPN),以交替的方式互相连接上下采样层,使用所有中间重建的HR特征映射的级联重建最终HR结果。DBPN中使用的背投单元(the back-projection units)具有非常复杂的结构并且需要繁重的手动设计。由于这一机制刚刚被引入以深度学习为基础的超分辨率。 他的框架具有巨大的潜力,需要进一步的探索。
上采样的学习方式
5.上采样的学习方式:
1)基于插值:最近邻插值 (Nearest Neibor): 使用中心像素块填充满插值空隙;双线性插值 (Bilinear): 在横竖两个方向上进行线性插值;双三次插值 (Bicubic): 在横竖两个方向上进行三次插值,插值时均为先进行横向插值再进行纵向插值与双线性插值相比,双三次插值的运算量为4×4像素,从而以较少的插值伪迹和较低的速度获得了更平滑的结果。
2)反卷积:具体来说,它通过插入零值和进行卷积来扩展图像,从而提高图像的分辨率。在原始像素周围填充足够数量的0可以保证卷积得到的特征图的尺寸符合放大倍数要求。反卷积层由于其与原始卷积的兼容性而被广泛应用,但反卷积层具有“非均匀重叠效应”,这会导致生成图像带有典型的棋盘纹理,使生成效果变差。
3)亚像素卷积:通过卷积生成多个信道然后再整合它们,亚像素层使用多个卷积核直接在原始图像上(带padding)做卷积,然后将得到的多个特征图进行重排列合成出一张更大的图像,这要求特征图的数量必须是放大倍数的平方。与转置卷积层相比,亚像素层最大的优势是接收域更大,提供了更多的上下文信息以帮助生成更准确的细节。
残差块
6.残差块:shortcut以及元素点积
1)全局残差:它避免了从一个完整的图像到另一个图像的复杂转换,只需要学习一个残差映射来恢复丢失的高频细节。常用于预先上采样框架
2)局部残差:用于缓解网络深度不断增加造成的退化问题,提高学习能力。
前者直接连接输入图像和输出图像,后者通常在网络内部具有不同深度的层之间添加多个shortcut
递归学习
7.递归学习:它指以递归方式多次应用相同的模块。(参数共享机制)
在实践中,递归学习会带来梯度消失或梯度爆炸的梯度问题,因此一些技术,如残差学习(SEC)。和多监督会与递归学习相结合来缓解这些问题。
多路径学习
8.多路径学习:通过模型的多条路径传递特征,这些路径执行不同的操作,以提供更好的建模能力。具体来说,它可以被分割 分为三种类型
1)全局多路径:LapSRN:特征提取+重建;DSRN:低分辨率+高分辨率;condition+prior
2)局部多通道:MSRN:用不同卷积核对图像进行卷积后,concat,再一齐送入同样的操作中,并通过1*1卷积,从多个缩放尺度中提取图像特征并进一步提高性能
3)特定规模的多路径学习:它们共享模型的主要部分(即,用于特征提取的中间部分),并且分别在网络的开始和结束处附加特定的预处理路径和上采样路径。仅使用和更新与选定规模相对应的路径,也利用了参数共享机制
密集连接
9.密集连接:用于融合模块
所有前面层的特征映射被用作输入,并且当前层的特征映射被用作进入所有后续层的输入。可以缓解梯度消失、增强信号传播和鼓励特征重用,而且还可以小的增长速率来减少参数的数量(即密集块中的信道数目)和级联后的可以压缩信道。

通道注意力机制
10.通道注意力机制
通道相互依赖的显式建模,使用全局平均池化将每个输入信道压缩到信道描述符(即常量)中,然后将这些描述符输入到两个全连接层中,从而生成信道级计算因子。显著提高了模型的表示能力,提高了SR的性能。
其他卷积
11.其他卷积
1)Dilated Convolution.不做pooling损失信息的情况下,加大了感受野,让每个卷积输出都包含较大范围的信息。https://www.zhihu.com/question/54149221
2)group Convention分组卷积
像素递归网络
12.像素递归网络:利用生成像素之间的相互依赖。采用两个网络分别捕获全局上下文信息和串行生成相关性。增加了计算成本和计算难度,不常用
金字塔池化
13.金字塔池化:更好地利用全局和本地上下文信息。每个特征映射被划分为MM块,经过全局平均池化后,用11卷积将输出压缩到一个单通道,采用双线性插值方法,将低维特征图向上采样到与原始特征映射相同的大小。
小波变换
14.小波变换
将图像信号分解为表示纹理细节的高频小波和包含全局拓扑信息的低频小波。
将插值后的LR小波的子带作为输入,并预测相应HR子带的残差。小波变换和逆小波变换分别用于LR输入的分解和HR输出的重构。
有些模型也在小波区域进行超分处理
损失函数
15.损失函数
L2损失函数不能准确地评估实际HR图像和生成的HR图像之间的差距,故提出不同的损失函数
Pixel Loss
1)Pixel Loss 两个图像像素点之间的差异
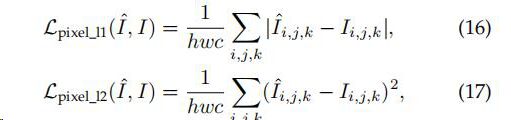
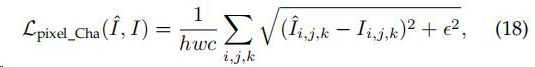
实际中,L1比L2好,整体来说pixel loss它通常缺乏高频细节,并产生明显的不满意的结果与过分平滑的纹理。
Content Loss
2)Content Loss 具体而言,它计算得失使用预先训练的图像分类网络的图像之间的语义差异。
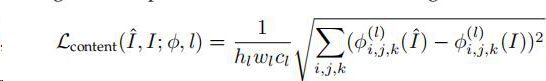
φ是图像分类的网络,content loss传递的是层次图像特征,与像素损失相反,content loss鼓励输出图像I在感知上类似于目标图像I(比如 图像特征),而不是强制它们精确地匹配像素。
Texture Loss
3)Texture Loss
图像的纹理是不同特征通道之间的相关性并且被定义为Gram矩阵
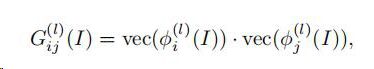
其中vec(·)表示矢量化操作,并且式φi,φj表示图像I的层L上的特征映射的第i,j信道。

Adversarial Loss
4)Adversarial Loss
对抗生成网络GAN中使用的损失函数,在这种情况下,我们只需要将SR模型看作一个生成器,并另外定义一个判别器来判断输入图像是否生成,利用的是交叉熵。不同论文提出了不同的定义,D是鉴别器
①
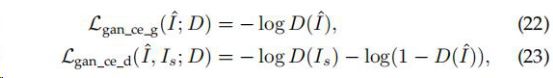 Is表示真实HR图像中随机采样的数据。
Is表示真实HR图像中随机采样的数据。
②
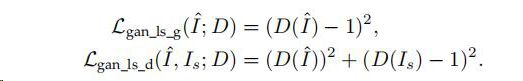
③
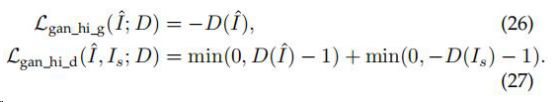
虽然这个损失函数产生的图像的PSNR比pixel loss低,但实际上生成的效果要好很多,鉴别器提取出一些难以学习的真实HR图像的潜在模式,并使得所生成的HR图像符合这些模式。目前,GAN的训练过程仍然比较困难和不稳定。
Cycle Consistency Loss
5)Cycle Consistency Loss.循环一致性损失CycleGAN
仅超解析LR图像到HR图像,还通过cnn将HR降到另一个LR图像。
x -> G(x) -> F(G(x)) ≈ x,称作forward cycle consistency
同理,y -> F(y) -> G(F(y)) ≈ y, 称作 backward cycle consistency

Total Variation Loss
6)Total Variation Loss:抑制生成图像中的噪声
它被定义为相邻像素之间的绝对差值之和,度量图像中多少噪声。
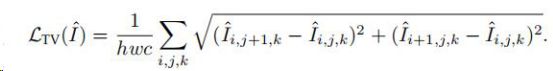
Prior-Based Loss
7)Prior-Based Loss引入了外部先验知识来约束生成过程。
经过预先培训和整合,提供对齐知识(即先验知识)。有些网络,将内容丢失和纹理丢失都引入了分类网络,本质上为SR提供了层次图像特征的先验知识。通过引入更多的先验知识可进一步提高超分的性能。在实践中,研究人员常常通过加权平均组合多个损失函数来约束生成过程的不同方面。但如何合理有效地结合这些损失函数仍然是一个问题。
提高的策略
16-22为提高的策略
BN批量归一化
16.BN批量归一化:为了reduce internal covariate shift of networks,减少网络的内部协变量偏移
https://www.cnblogs.com/guoyaohua/p/8724433.html
在训练过程中,隐层的输入分布老是变来变去,这就是所谓的“Internal Covariate Shift”,Internal指的是深层网络的隐层,是发生在网络内部的事情
使用了BN,整体学习率要高得多,对初始化不用那么小心。
因为深层神经网络在做非线性变换前的激活输入值(就是那个x=WU+B,U是输入)随着网络深度加深或者在训练过程中,其分布逐渐发生偏移或者变动,之所以训练收敛慢,一般是整体分布逐渐往非线性函数的取值区间的上下限两端靠近(对于Sigmoid函数来说,意味着激活输入值WU+B是大的负值或正值),所以这导致反向传播时低层神经网络的梯度消失,这是训练深层神经网络收敛越来越慢的本质原因,而BN就是通过一定的规范化手段,把每层神经网络任意神经元这个输入值的分布强行拉回到均值为0方差为1的标准正态分布,其实就是把越来越偏的分布强制拉回比较标准的分布,这样使得激活输入值落在非线性函数对输入比较敏感的区域,这样输入的小变化就会导致损失函数较大的变化,意思是这样让梯度变大,避免梯度消失问题产生,而且梯度变大意味着学习收敛速度快,能大大加快训练速度。
N操作就是对于隐层内每个神经元的激活值来说,进行如下变换:
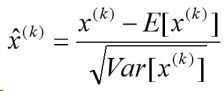
然而,有论文认为,BN丢失了每个图像的比例信息,并且摆脱了网络的范围灵活性。因此,很多网络移除BN层,并实现了性能改进。
Curriculum Learning
17 Curriculum Learning课程学习:https://blog.csdn.net/qq_25011449/article/details/82914803
模仿人类的学习过程,从较简单的子任务开始,逐步增加任务难度,容易使模型找到更好的局部最优,同时加快训练的速度。课程学习,根据训练样本训练的难易程度,给不同难度的样本不同的权重,一开始给简单的样本最高权重,他们有着较高的概率,接着将较难训练的样本权重调高,最后样本权重统一化了,直接在目标训练集上训练。
训练从2×上采样部分开始,在完成训练部分后,具有4×或更大比例因子的部分逐渐加入并与前一个上采样混合。比如8*超分问题涉及三个子问题(即,1×到2×,,2×至4×,4×至8×,SR),并针对每个子问题对单个网络进行训练。然后将其中的两个连接在一起,并进行精调,然后再与另一个连接。
课程学习减少了训练难度,提高了训练效果,尤其是对于大缩放因子,也大大缩短了训练时间。
Multi-supervision
18.Multi-supervision 多监管
多监督是指在模型内增加多个额外的监控信号,以增强梯度传播和避免消失和爆炸梯度
DRCN:对递归单元进行多监督,它们将递归单元的每个输出 输入到一个重构模块中,生成HR图像,并通过加权平均所有这些中间HR图像来构造最终的预测。
LapSRN在渐进上采样SR框架下,在前馈传播过程中产生不同比例的中间上采样结果,它属于多监管,即中间产生的结果也必须与原始HR图像下采样的真实图像相同。
在实践中,这种多重监控技术往往是通过在损失函数中添加一些项来实现的,这样就可以有效地反向传播监控信号,从而从而大大增强了模型训练。
基于上下文的网络融合
19.基于上下文的网络融合(CNF):指将多个SR网络的预测融合在一起的叠加技术(比如多路径学习)。它们分别对具有不同架构的各个SR模型进行训练,将每个模型的预测反馈到各个卷积层,最后将输出求和以作为最终预测。
扩大训练集
20.扩大训练集:随机裁剪,翻转,缩放,旋转,颜色抖动等。
网络插值
21.网络插值:通过训练一个基于psnr的模型和一个基于gan的模型,然后插值所有相应的参数。 这两个网络导出中间模型。
增强预测
22增强预测:(SR常用)在LR图像上应用不同角度的旋转(即0度、90度、180度、270度)和翻转以获得一组8种LR图像,然后将这些图像送到SR模型中,并且将相应的反向变换,重构的HR图像以获得输出。最后的预测结果由 这些输出的平均值或中位数。
非监督学习
23.非监督学习用于SR:由HR退化而成的LR图像这些数据集进行培训的SR模型更有可能学习预定义过程的反向过程,对真实图像效果不好。
Zero-shot Super-resolution
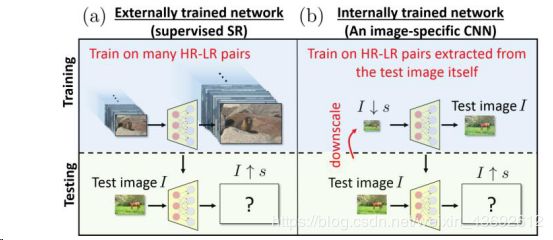
1)Zero-shot Super-resolution:该超分辨率算法不依赖任何其他图片样本和预先训练,使用图像的内部自相似信息,测试时训练一个特定图片的CNN网络。在超分辨率一张LR图片时,对该图再度降采样,学习二者之间的超分辨参数,再用于LR的进行超分辨。在test测试的同时训练的。**先将测试图片缩小scale倍进行训练,待网络收敛,再将测试图片输入,得到放大scale倍的超分输出。**然而,由于该方法在测试过程中需要对每幅图像进行单一的网络训练,使得它的测试时间比其他具有深度学习的SR模型要长得多。
Weakly-supervised Super-resolution
2)Weakly-supervised Super-resolution具有弱监督学习的SR模型,即使用未配对的LRHR图像。
①学习HR-LR的退化过程:用未配对的图像学习HR-LR退化过程,HR图像被输入生成器以产生LR输出,这些输出不仅需要匹配通过缩小HR图像(平均池)而获得的LR图像,而且还需要匹配 真实的LR图像。生成器训练结束后,被当作生成LR-HR图像对的退化模型。之后对于LR-to HR ,生成器(即SR模型)将生成的LR图像作为输入并预测HR输出。
②循环学习:无监督超分的另一种方法是将LR空间和HR空间视为两个域,并使用循环结构来学习彼此之间的映射。
CinCGAN:四个生成器和两个判别器,noisy LR -> clean LR and clean LR ->clean HR在第一个circleGAN中,噪声的LR图像被输入到一个生成器中,并且输出必须与真实的干净LR图像的分布相一致,然后它被送入另一个生成器并要求恢复原来的输入(the original input),第二个GAN设计与前面一个一样,只不过作用域不同。性能不错,但是训练难度较大,且不稳定。
24.Deep Image Prior:具体而言,它们定义了一个以随机向量z为输入的生成器网络,并试图生成目标HR图像。目的是对网络进行训练生成的图像Iy,使得Iy下采样得到的图像与输入的LR图像Ix相同。因为网络是随机初始化的,并且从未对数据集进行过培训,所以结果由CNN结构本身决定。这个算法虽然比有监督的差,但比传统线性插值效果要好,这个算法关注的是CNN架构本身的合理性,并促使我们通过将深度学习方法与自己设计的Prior先验(如CNN结构或自相似)相结合来提高图像超分。
运用的场景
25.可以运用的场景:
1)深度图超分:深度信息在许多任务中起着重要的作用,深度图记录场景中视点与物体之间的距离,深度传感器制作的深度图通常是低分辨率的,故可以将超分运用到深度图中。
目前,一般利用另一个rgb相机(而不是传感器)获取相同场景的HR图像,以引导LR深度图的超分辨率。
可以利用景深统计,低分辨率的深度图与RGB图像之间的局部相关性来约束全局统计和局部结构;另一种方法,利用两个cnn,同时上采样LR深度图和下采样HR rgb图像,然后以rgb特征作为相同分辨率的上采样过程的指导;图像提取法提取HR边缘图和预测缺失高频分量;用功能强大的变分模型的形式将CNNs与能量最小化模型相结合,以恢复HR深度图,而无需其他参考图像
2)人脸图像超分:面部图像具有更多的面部相关结构化信息,可以用做先验知识,约束生成的图像。不同的方法对先验知识的处理不一样。
有些网络将解码-编码-解码网络与面部生成相结合;有些利用注意力机制;对抗学习;
3)高光谱图像超分辨率:提出了一种稀疏的去噪自编码器,用于学习带盘的LR-to-HR映射,并将其用于高光谱图像;采用SRCNN并结合若干非线性辐射测量指数图,以提高性能;基于残差学习的DRPNN;在全色图像和高光谱图像上,联合训练两个编解码网络执行超分任务,并通过共享解码器和应用约束将全色图像域中的SR知识转移到HS I域。
4)视频超分:帧内空间相关性,以及帧间时间依赖(运动、亮度和颜色变化等)。因此,现有的工作主要集中于光流、运动补偿、以及使用递归方法来捕获时空依赖。
5)其他:细粒度判别,小目标检测,边缘检测、语义分割、数字和场景识别等视觉应用,遥感图片。
26.SR未来研究方向:
1)Network Design(网络结构设计)
可考虑从如下方面改进网络结构:
Combining Local and Global Information,结合局部和全局信息,大的感受野可以提供更多的纹理信息,这样可生成更加真实的的HR图像。
Combining Low- and High-level Information,结合低层和高层信息,deep CNNs中的较浅层易于抽取如颜色和边缘等低层特征,而较高层更易获得如目标识别等高层次的特征表示,结合低层网络抽取的低层细节信息和高层网络抽取到的高层纹理信息可获得效果更好的HR图像。
Context-specific Attention,结合特定内容的注意力机制,增强主要特征,使生成的HR图像具有更加真实的细节。
Lightweight Architectures,目前网络结构日趋复杂,如何减少模型大小,加快预测时间并保持性能仍然是一个研究课题。
Upsampling Layers,如何设计出有效并有效率的上采样层是值得研究的,特别是在放大倍数较大的图像超分辨率问题上。
2)Learning Strategies(学习策略)
Loss Functions,目前的损失函数是建立于 LR/HR/SR 图像之间的限制并优化层面上的。在实际应用上,通常把这些损失函数进行加权得到,对SR问题来说,最有效的损失函数还不明确。当前任务,如何找到 LR/HR/SR 图像间的潜在联系并找到更加准确的损失函数。
Normalization,虽然BN在视觉问题上大量使用,但是在SR问题上,BN并不是最佳的规范化效果,有时使用BN反而会得到不好的效果。因此,在SR领域,其他有效的规范化技术是需要被提出的。
Evaluation Metrics(评价方法)
More Accurate Metrics,传统的PSNR/SSIM图像质量评价方法并不能客观反应图像的主观效果,MOS方法需要大量的人力成本并且不能再现。因此,更加精确的图像质量评价方法亟待提出。
Blind IQA Methods,目前所提到的SR问题,都是LR-HR图像对做出的,但是,在这类数据集是很难获得的,大部分都是通过人工手段获得的LR-HR图像对。这样,在评价这类问题时,就变成了反向预测退化问题的过程,因此,无依赖的图像质量评价方法是有很大需要的。
4)Unsupervised Super-resolution(无监督图像超分辨率)
目前大量的SR方法都是使用Matlab Bicubic(双三次插值)方法获得LR图像,用LR-HR作为SR网络的训练数据,这样SR问题会变成预先定义图像退化过程的逆过程,在自然低分辨率图像上应用这类SR方法,效果会很不好。因此,在未来的研究领域,没有LR-HR图像对的无监督图像超分辨率问题是有意义的研究方向。
5)Towards Real-world Scenarios(面向真实场景)
Image super-resolution在真实场景上,往往会受到“不明确的图像退化过程”,“缺少LR-HR图像对”等的条件限制,使得现有的SR算法难以实际应用。
Dealing with Various Degradation,解决多种图像退化问题(压缩、模糊、退化)。目前已有一部分这方面的工作,但是存在一些固有缺点,如模型难以训练,过于理想的假设条件。
Domain-specific Applications,特定领域的应用,SR算法不一定非要用于特定领域数据或场景中,SR算法同样可协助处理其他视觉问题,如视频监控、人脸识别、目标跟踪、医学图像、场景渲染等。SR算法可用于这类视觉问题的预处理或后处理。
Multi-scale Super-resolution,目前大部分SR网络是针对固定放大尺寸训练的,实际应用中,有一定局限性。使用单一网络的进行多尺度图像超分辨率,有一定的研究价值。最近在CVPR 2019上,旷视提出了“Meta-SR: A Magnification-Arbitrary Network for Super-Resolution”:单一模型实现任意缩放因子。是这一研究方向的最新进展。