Lending Club贷款违约预测
目录
- 项目简介及目标
- 数据概览
2.1数据来源
2.2数据结构图
2.3数据变量表
2.4离散型数据分布
2.5连续型数据分布 - 数据处理及特征选择
3.1目标值量化
3.2删除字段
3.3缺失值处理
3.4同值化处理
3.5数据格式转换
3.6标签编码
3.7异常值处理
3.8特征选取 - 模型建立
4.1数据划分
4.2样本不平衡处理
4.3参数最优
4.4建立模型 - 模型评估
5.1ROC曲线AUC值
5.2K-S曲线 - 模型对比
- 分析总结
1. 项目简介及目标
简介: 贷款申请人向Lending Club平台申请贷款时,Lending Club平台通过线上或线下让客户填写贷款申请表,收集客户的基本信息,同时会借助第三方平台如征信机构或FICO等机构的信息。通过这些信息属性来做线性回归 ,生成预测模型,Lending Club平台可以通过预测判断贷款申请是否会违约,从而决定是否向申请人发放贷款。
目标:通过预测判断贷款申请是否会违约,从而决定是否向申请人发放贷款。
2. 数据概览
2.1数据来源
数据集是Lending Club平台发生借贷的业务数据(2019年第二季),共有144 个变量,42537条记录。
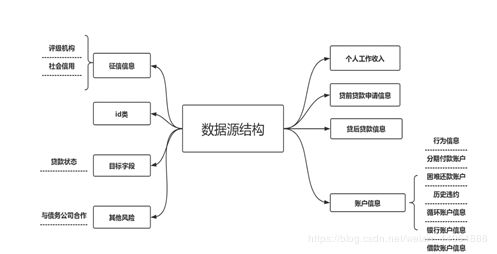
2.2数据结构图
通过查阅资料,将144个变量进行翻译及分类,主要包括以下几个类型的信息
2.3部分变量表
由于变量太多,仅展示部分变量

2.4离散型数据分布(这里展示的只是部分变量)
- 目标变量loan_status
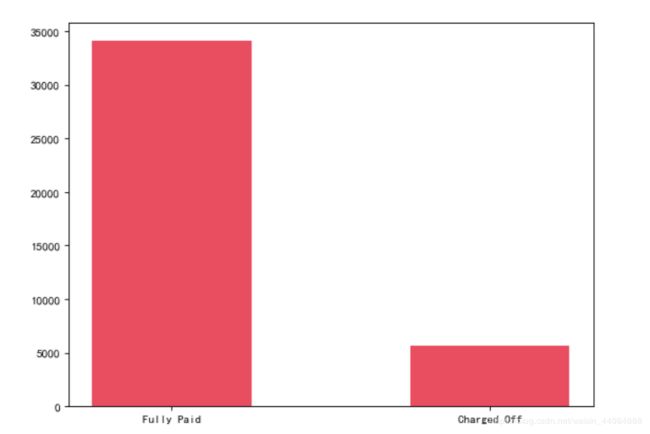
从图中可以看出,相对正常样本,违约样本太少,后续应进行样本不平衡处理以提高模型的预测效果
- term:贷款时长,值以月为单位,可以是36或60

- grade:LC指定贷款等级,LC平台依据多样化的需求,将借贷人分成A-G七个等级,从A到G,贷款的风险越来越高,利率也越来越高。

从图中,我们也可以看出这个趋势。无论是投资人还是借贷者,大多数都是选择较低风险较低收益的类型。
- emp_length:工作年限(以年为单位)。可能的值在0到10之间,其中0表示小于一年,10表示10年或更长时间。
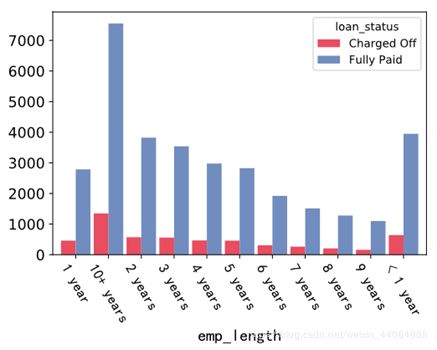
工作时长低于1年与10以上的借款人最多,两者的违约比例相差不大。因此,并非工作年限长信用值越高,越靠谱。除此两类,在2-9年,随着工作年限越长,贷款需求越少,有可能是因为收入越来越稳定。
- purpose: 借款人为贷款请求提供的类别。
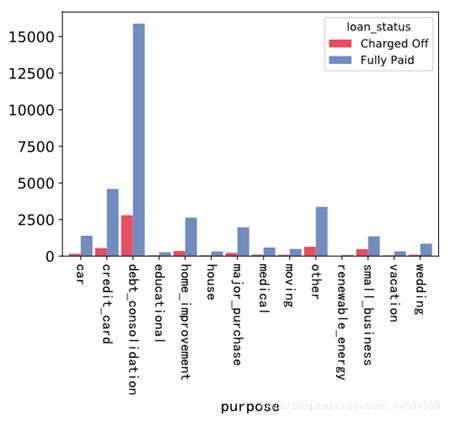
债务整合(举债还债)这类最多。另外3项是:住房改善、汽车、大宗采购,也就是基本生活需求。相对来说,借钱做生意的,违约率较高。
2.5连续型数据分布
- dti: 按借款人每月总偿债额与总债务

分期付款金额基本呈的正态分布,说明贷款额度集中在中小额度。
*annual_inc:年度收入

年收入集中在0-10万美元以内,但是也有极高收入(最高达到600万)的借款人。
3. 数据处理
3.1目标值量化
对于目标变量Loan_status有四个分类,分别是Fully Paid、Charged Off、Does not meet the credit policy. Status:Charged Off和Does not meet the credit policy. Status:Fully Paid,后两者是指不符合信用政策的坏账或者完全支付的状态,我们认为是特殊情况的信贷,因此不予考虑,当缺失值处理,同时用1代表charge off(违约),0代表fully paid(完全支付)
3.2删除字段
由于项目目的是提前预测贷款申请入是否违约,所以需要剔除属于贷款发放后的数据信息。
诸如个人ID、地址、URL地址以及日期等信息,主观判断其对是否违约影响甚微。
当字段缺失值过多时,将会不利于预测模型的拟合结果。故将缺失值超过70%的字段剔除。
#删除贷后信息
drop_lable = ['collection_recovery_fee','initial_list_status','installment','last_pymnt_amnt','last_pymnt_d','loan_amnt',
'next_pymnt_d','out_prncp','out_prncp_inv','policy_code','pymnt_plan','recoveries','total_pymnt','total_pymnt_inv','total_rec_int','total_rec_late_fee',
'total_rec_prncp','sec_app_earliest_cr_line','sec_app_mort_acc','settlement_date','settlement_amount','settlement_percentage','settlement_term',
'sub_grade','emp_title','zip_code','title','desc','last_credit_pull_d','addr_state','issue_d','earliest_cr_line']
Loan_data.drop(columns = drop_lable,axis = 1,inplace = True)
# 删除缺失值超过70%的列
Loan_data.dropna(thresh = len(Loan_data)*0.7,axis = 1,inplace = True)
3.3缺失值处理
对于其他含有缺失值的字段,本次项目采用的方法是删除所有含有空值的记录。主要原因是所使用的数据集有充足的记录,删除少许记录对于模型的建立没有太大的影响,而如果采用平均值、众数或者中位数来填充空值,会使得样本的真实性下降,使建模效果变差。
另外,在删除的记录中,违约记录与正常记录为364:1460,违约记录的占比较低,因此认为对建模效果不会产生太大的影响。
# 删除存在缺失值的行
Loan_data.dropna(axis = 0,inplace = True)
3.4同值化处理
如果一个变量大部分的观测都是相同的特征,那么认为此类特征变量无法显著区分目标变量,可以考虑将其删除。根据排序结果,保留前三个的变量。

3.5数据格式转换
由于部分所选的数据特征存在百分号或是其他字符,需要对其进行数据格式的转换,为后续分析做准备。
#特征格式变换
Loan_data['term'] = Loan_data['term'].str.replace(' months','').astype('float')
Loan_data['int_rate'] = Loan_data['int_rate'].str.replace('%','').astype('float')
Loan_data['revol_util'] = Loan_data['revol_util'].str.replace('%','').astype('float')
3.6标签编码
因项目所采用随机森林与逻辑回归模型不支持字符型的数据变量,故对此类变量进行编码。为了使所研究的数据清晰简洁,本文采用类别标签方法对下图所示数据变量进行标签化编码。
# 标签编码
le_dict = {
'emp_length':{
'< 1 year':0,
'1 year':1,
'2 years':2,
'3 years':3,
'4 years':4,
'5 years':5,
'6 years':6,
'7 years':7,
'8 years':8,
'9 years':9,
'10+ years':10
},
'grade':{
'A':1,
'B':2,
'C':3,
'D':4,
'E':5,
'F':6,
'G':7
},
'home_ownership':{
'MORTGAGE':1,
'RENT':2,
'OTHER':3,
'OWN':4,
'NONE':5
},
'verification_status':{
'Not Verified':1,
'Source Verified':2,
'Verified':3
},
'purpose':{
'car':1,
'credit_card':2,
'small_business':3,
'other':4,
'wedding':5,
'debt_consolidation':6,
'home_improvement':7,
'major_purchase':8,
'moving':9,
'vacation':10,
'house':11,
'medical':12,
'renewable_energy':13,
'educational':14,
},
'debt_settlement_flag':{
'N':1,
'Y':2
}
}
Loan_data = Loan_data.replace(le_dict)
3.7 异常值处理
格式转换之后发现revol_util字段有些许值大于100,按理说这个变量的值不应该超过100,所以将超过100的异常记录删除。
Loan_data.drop(Loan_data[Loan_data['revol_util'] > 100].index,inplace = True)
3.8 特征提取
本项目将利用多重共线性+VIF值进行变量筛选,利用随机森林进行特征选择
通过相关系数矩阵得到高于0.8的三对变量如下图:

随机森林重要性排序结果如下,剔除重要系数小于0.01的变量:

具体步骤: 首先剔除相关系数大且VIF值大的变量,计算剔除变量后的VIF,再重复上面原则,步骤简单但是一步一步图太多,就直接说结果吧。经过3.7步前的操作,剩余21个变量,经过多重共线性筛选剩余17个变量,经过随机森林重要性筛选得到16个变量(不包括目标变量)。
4. 模型建立
4.1数据划分
本次项目我们采用交叉验证法划分数据集,将数据划分为训练集、验证集和测试集,让模型在训练集上进行学习,在验证机上进行参数调优,最后使用测试集数据评估模型的性能。
将样本数据以7:3的比例进行训练集和测试集的划分。
4.2样本不平衡处理
上面我们提到过正负例样本不平衡,我们对训练集进行上采样,得到训练模型,并在测试集上进行检验。本次上采样采用SMOTE算法
# SMOTE算法平衡数据,种子数=2
sm=SMOTE(random_state=2)
x,y=sm.fit_sample(x_train,y_train)
print("通过SMOTE方法后平衡的正负样本")
n_sample=y.shape[0]
n_pos_sample=y[y==1].shape[0]
n_neg_sample=y[y==0].shape[0]
# print("样本个数:{};正样本{:.2%};负样本{:.2%}".format(n_sample,n_pos_sample/n_sample,n_neg_sample/n_sample))
4.3参数最优—网格搜索法
模型调优我们采用网格搜索调优参数,通过构建参数候选集合,网格搜索会穷举各种参数组合,根据设定评分机制找到最好的一组参数。本次我们得到最优超参数C为0.1,惩罚项为l1正则。
# 网格搜索,并使用5折交叉验证获取最优参数值(选择标准“auc”最大),logistic模型随机数种子=2
penaltys = ["l1","l2"]
Cs = [0.001, 0.01, 0.1, 1, 10, 100, 1000]
tuned_parameters = dict(penalty = penaltys, C = Cs)
lr_penalty= LogisticRegression(random_state=2)
grid= GridSearchCV(lr_penalty, tuned_parameters,cv=5, scoring='roc_auc')
grid.fit(x_train,y_train) #运行
print(u'最优超参数为:',grid.best_params_)
grid.best_score_ #最好的分数
4.4模型建立
由于本次项目目的是为了预测贷款申请人是否会违约,属于分类问题且为二分类预测,因此采用逻辑回归。我们之前设违约为1,全额付清为0,利用违约的概率与不违约的概率进行比值然后取对数,构造该变量与各变量间的模型。
model = LogisticRegression(C=0.1,penalty='l1',random_state=2)
model.fit(x_train, y_train)
5. 模型评估
- 精确率、召回率及F1值
| 样本 | 精确率 | 召回率 | F1值 |
|---|---|---|---|
| 训练集 | 0.597 | 0.500 | 0.464 |
| 测试集 | 0.788 | 0.501 | 0.466 |
- ROC曲线及AUC值

| 样本 | AUC值 |
|---|---|
| 训练集 | 0.685 |
| 测试集 | 0.692 |
- K-S曲线
k-s曲线能够直观地看出是否违约事件的区分程度,ks值越大,表示模型能够将正、负客户区分开的程度越大。通常来讲,ks值大于0.2表示模型有较好的预测准确性,逻辑回归的ks值为0.27,说明该模型是可行的。

6. 模型对比
对于分类问题,决策树也有较好的预测效果,因此我们将处理好的数据用决策树算法进行预测,结果发现利用基尼系数划分节点时,深度为4的树训练出来的模型,在测试集上的精确率为0.43,AUC值达到0.671,ks值为0.26,说明模型能够区分正负客户区,但是从auc值和ks值看,决策树的预测效果并没有逻辑回归好,所以逻辑回归模型的预测效果还是不错的。


7. 分析总结
- 在特征选择方面,我们最终留下16个特征,包括贷前贷款申请信息6个,分别是grade、term、dti、funded_amnt、purpose、verification_status,个人信息3个,分别是annual_inc、emp_length、home_ownership,借款账户信息2个,分别是open_acc、total_acc,循环账户信息2个,分别是revol_bal、revol_util,行为信息、历史违约及社会信用各1个,分别是inq_last_6mths、delinq_2yrs、pub_rec。贷前贷款申请信息和个人信息占比超过50%,这说明贷款申请人填写申请表是很有必要的,另外通过随机森林算法我们可以得到影响违约最重要的前5个变量是LC指定的贷款等级、年度收入、借款人相对于所有可用循环信贷的信贷金额、贷款时长、借款人每月总偿债额与总债额之比,其中年度收入与目标变量是正相关的,也就是说,借款人的年收入越高,违约的优势比越低,而其他四个变量的值越大或等级越高,违约的优势比也越大,因此要着重注意借款人的这些信息.
- 在模型方面,我们采用了逻辑回归和决策树2种算法进行预测,虽然2个模型的ks值都超过了0.2,但是决策树的预测效果并没有逻辑回归靠谱。逻辑回归模型的AUC值为0.69,k-s值为0.27,说明模型是可行的且是可靠,因此我们建议采用逻辑回归的模型进行贷款违约预测。
结束语
本项目为个人学习成果,若有不对之处,还请各位读者给予指正~