Python获取拉勾网招聘信息(可视化展示)
1、获取拉勾网招聘信息
首先要明确拉勾网的招聘信息存储网页是post形式的,所以必须填写from_data信息。我们这里填的是from_data = {‘first’:‘true’, ‘pn’:‘1’, ‘kd’:‘设计’},其中pn代表当前页码,kd就是我们搜索的职位关键词。 第二就是记得要用Session 获取动态cookies,否则爬下来的数据空空如也,还容易被封IP封号。
爬取结果如下
拉勾网每页有15条数据,默认显示30页,一共450条数据。我这里直接写死啦,大家可以根据需要修改爬取页数。也可以选择不获取“岗位要求”信息,或者其他不需要的信息。保存下来的文件是这个样子的。

原网页点击

先上全部代码:
导入使用的库
import pymongo
import requests
from bs4 import BeautifulSoup
import json
import pandas as pd
import time
from datetime import datetime
from pymongo import MongoClient
# 从职位详情页面内获取职位要求
def getjobneeds(positionId):
'''
:param positionId:
:return:
'''
url = 'https://www.lagou.com/jobs/{}.html'
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36',
'Host': 'www.lagou.com',
'Referer': 'https://www.lagou.com/jobs/list_%E8%AE%BE%E8%AE%A1/p-city_0?px=default',
'Upgrade-Insecure-Requests': '1'
}
s = requests.Session()
s.get(url.format(positionId), headers=headers, timeout=3) # 请求首页获取cookies
cookie = s.cookies # 为此次获取的cookies
response = s.get(url.format(positionId), headers=headers, cookies=cookie, timeout=3) # 获取此次文本
time.sleep(5) # 休息 休息一下
soup = BeautifulSoup(response.text, 'html.parser')
need = ' '.join([p.text.strip() for p in soup.select('.job_bt div')])
return need
# 获取职位具体信息#获取职位具体
def getjobdetails(jd):
'''
:param jd:
:return:返回结果集
'''
results = {}
results['businessZones'] = jd['businessZones']
results['companyFullName'] = jd['companyFullName']# 公司名
results['companyLabelList'] = jd['companyLabelList']#
results['financeStage'] = jd['financeStage']
results['skillLables'] = jd['skillLables']
results['companySize'] = jd['companySize']
results['latitude'] = jd['latitude']
results['longitude'] = jd['longitude']
results['city'] = jd['city']
results['district'] = jd['district']
results['salary'] = jd['salary']
results['secondType'] = jd['secondType']
results['workYear'] = jd['workYear']
results['education'] = jd['education']
results['firstType'] = jd['firstType']
results['thirdType'] = jd['thirdType']
results['positionName'] = jd['positionName'] #职位
results['positionLables'] = jd['positionLables']
results['positionAdvantage'] = jd['positionAdvantage']
positionId = jd['positionId']
results['need'] = getjobneeds(positionId)
time.sleep(2) # 设置暂停时间,控制频率
print(jd, 'get')
return results
# 获取整个页面上的职位信息
def parseListLinks(url_start, url_parse):
'''
:param url_start:
:param url_parse:
:return:
'''
jobs = []
from_data = {'first': 'true',
'pn': '1',
'kd': 'c++'}#c++:设置爬取岗位
headers = {
'Host': 'www.lagou.com',
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Referer': 'https://www.lagou.com/jobs/list_%E8%AE%BE%E8%AE%A1/p-city_0?px=default',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36',
'X-Anit-Forge-Code': '0',
'X-Anit-Forge-Token': 'None',
'X-Requested-With': 'XMLHttpRequest',
}
res = []
for n in range(1):#访问页数
from_data['pn'] = n + 1
s = requests.Session()
s.get(url_start, headers=headers, timeout=3) # 请求首页获取cookies
cookie = s.cookies # 为此次获取的cookies
response = s.post(url_parse, data=from_data, headers=headers, cookies=cookie, timeout=3) # 获取此次文本
time.sleep(5)#设置睡眠时间
res.append(response)
jd = []
for m in range(len(res)):
jd.append(json.loads(res[m].text)['content']['positionResult']['result'])
for j in range(len(jd)):
for i in range(15):
jobs.append(getjobdetails(jd[j][i]))
time.sleep(30)
return jobs
def main():
'''
:return:
'''
url_start = "https://www.lagou.com/jobs/list_Java?city=%E6%88%90%E9%83%BD&cl=false&fromSearch=true&labelWords=&suginput="
url_parse = "https://www.lagou.com/jobs/positionAjax.json?city=&needAddtionalResult=false"
jobs_total = parseListLinks(url_start, url_parse)
now = datetime.now().strftime('%m%d_%H%M%S')
newsname = 'lagou_sj' + now + '.xlsx' # 按时间命名文件
df = pd.DataFrame(jobs_total)
df.to_excel(newsname)
print('文件已保存')
#想尝试保存到MongoDB失败
# client = pymongo.MongoClient(host='localhost', port=27017)
# db = client.zh_db
# collection =db['zh_LG']
# collection.insert(eval(jobs_total))
if __name__ == '__main__':
main()
学历饼图代码:
import pandas as pd
from pyecharts import options as opts
from pyecharts.charts import Pie
from pyecharts.globals import ThemeType
df = pd.read_excel('lagou_sj0624_113314.xlsx')
result=pd.value_counts(df['education'])
resulted=dict(result)
ed = list(resulted.keys())
edvalues = list(resulted.values())
edvaluesint=[]
for i in edvalues:
edvaluesint.append(int(i))
result = pd.value_counts(df['education'])
resulted = dict(result)
ed = list(resulted.keys())
edvalues = list(resulted.values())
edvaluesint = []
for i in edvalues:
edvaluesint.append(int(i))
from pyecharts import options as opts
from pyecharts.charts import Pie
c4 = (
Pie(init_opts=opts.InitOpts(theme=ThemeType.LIGHT))
.add(
"",
[list(z) for z in zip(ed, edvaluesint)],
radius=["30%", "75%"],
# 饼图的半径,数组的第一项是内半径,第二项是外半径
center=["25%", "50%"],
# 饼图的中心(圆心)坐标,数组的第一项是横坐标,第二项是纵坐标
rosetype="radius",
# 选择南丁格尔图类型,radius:扇区圆心角展现数据的百分比,半径展现数据的大小
label_opts=opts.LabelOpts(is_show=False),
)
.add(
"",
[list(z) for z in zip(ed, edvaluesint)],
radius=["30%", "75%"],
center=["75%", "50%"],
rosetype="area", # 选择南丁格尔图类型,area:所有扇区圆心角相同,仅通过半径展现数据大小
)
.set_global_opts(title_opts=opts.TitleOpts(title="学历要求"))
)
c4.render('学历饼图.html')
c4.render_notebook()

各个省市招聘人数条形图.html
import pandas as pd
from pyecharts import options as opts
from pyecharts.charts import Bar
from pyecharts.globals import ThemeType
df = pd.read_excel('lagou_sj0624_113314.xlsx')
dfp = pd.read_excel('province.xlsx')
df_new = pd.merge(df,dfp.loc[:,['city','province']],how='left',on = 'city')
result=pd.value_counts(df_new['province'])
resultp=dict(result)
province = list(resultp.keys())
values = list(resultp.values())
valuesint=[]
for i in values:
valuesint.append(int(i))
c3 = (
Bar(init_opts=opts.InitOpts(theme=ThemeType.LIGHT))#设置主题
.add_xaxis(province)#x轴为省份
.add_yaxis("人数",valuesint)#y轴为人数
.set_global_opts(title_opts=opts.TitleOpts(title="各个省市招聘人数"))
.set_series_opts(
label_opts=opts.LabelOpts(is_show=False),
#插入平均值线
markline_opts=opts.MarkLineOpts(data=[opts.MarkLineItem(type_="average", name="平均值"),]),
#插入最大值最小值点
markpoint_opts=opts.MarkPointOpts(data=[
opts.MarkPointItem(type_="max", name="最大值"),
opts.MarkPointItem(type_="min", name="最小值"),
])
)
)
c3 .render('各个省市招聘人数条形图.html')
c3 .render_notebook()
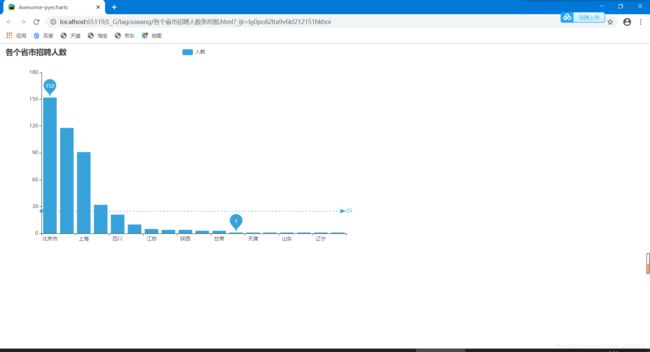
各个省市招聘人数块地图tow.html
我自己找的省市对应表:province.xlsx
提取码:syrb
import pandas as pd
from pyecharts import options as opts
from pyecharts.charts import Geo,Map
from pyecharts.globals import ChartType, SymbolType,ThemeType
df = pd.read_excel('lagou_sj0624_113314.xlsx')
result=pd.value_counts(df['city'])
print(result)
dfp = pd.read_excel('province.xlsx')
df_new = pd.merge(df,dfp.loc[:,['city','province']],how='left',on = 'city')
result=pd.value_counts(df_new['province'])
resultp=dict(result)
province = list(resultp.keys())
values = list(resultp.values())
valuesint=[]
for i in values:
valuesint.append(int(i))
#第一种地图
c1 = (
Geo()
.add_schema(maptype="china")
.add("各个省市招聘人数", #标题
[list(z) for z in zip(province, valuesint)],#省份数据列表,地名不能带“省”字
type_=ChartType.EFFECT_SCATTER)#选择显示类型
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))#不显示标签
.set_global_opts(
visualmap_opts=opts.VisualMapOpts(max_=200,is_piecewise = False),
title_opts=opts.TitleOpts(title="全国各省数据分布"),
)
)
c1.render('各个省市招聘人数点地图one.html')#保存为HTML
c1.render_notebook()#在notebook上显示
#第二种地图
c2 = (
Map(init_opts=opts.InitOpts(bg_color="#fff", theme=ThemeType.ROMANTIC))#设置主题
.add("各个省市招聘人数", [list(z) for z in zip(province, valuesint)], "china",is_map_symbol_show=False)
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
.set_global_opts(title_opts=opts.TitleOpts(title="各个省市招聘人数"),
visualmap_opts=opts.VisualMapOpts(max_=200,is_piecewise = True,#图例分段显示
pieces=[
{"min": 201, "label": '>200人', "color": "#e55039"}, # 不指定 max,表示 max 为无限大(Infinity),指定颜色。
{"min": 101, "max": 200, "label": '101-200人', "color": "#FF4500"},
{"min": 51, "max": 100, "label": '51-100人', "color": "#FF7F50"},
{"min": 10, "max": 50, "label": '10-50人', "color": "#FFA500"},
{"min": 1, "max": 9, "label": '1-9人', "color": "#FFDEAD"},
]
))
)
c2.render('各个省市招聘人数块地图tow.html')
c2.render_notebook()


词云:
ciyun.png ##:是一张任意的图片,作为字体背景色采取
import imageio
import matplotlib
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from jedi.api.refactoring import inline
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']
# %matplotlib inline
plt.show()
from wordcloud import WordCloud, ImageColorGenerator
import jieba
import jieba.analyse
df = pd.read_excel('lagou_sj0624_165511.xlsx')
# 将职位需求合并成一个长字符串
needs = []
for i in df['need']:
needs.append(i)
set_need = str(needs)
# 用jieba分词,将岗位需求切割成词语
cut = jieba.lcut(set_need)
need_cut = ' '.join(cut)
# 设置停止词,删除跟岗位需求无关的词
stopwords = ['nan', '具备', '岗位职责', '任职', '相关', '公司', '进行', '工作', '根据', '提供', '作品', '以上学历', '优先', '计算', '经验', '学历', '上学',
'熟练', '使用', '以上',
'熟悉', '能力', '负责', '完成', '能够', '要求', '项目', '制作', '具有', '良好', '行业', '专业', '设计', '团队', '岗位', '优秀', '我们', '关注'
, 'n1', 'n2', 'n3', 'n4', 'n5', 'xao', 'xa0', '产品', '软件', 'n6', '视频', '创意', '游戏', '需求', '视觉', '大专', '本科', '各种',
'以及', 'n7', '了解', '职位', '结果'
]
# 读取背景图片
mk = imageio.imread('alice_color.png')
wordcloud = WordCloud(background_color='white',
# 设置字体为中文字体!!!
#SIMLI.TTF:设置字体为自己电脑的字体
font_path="/Library/Fonts/SIMLI.TTF",
# 设置清晰度
scale=15, mask=mk, stopwords=stopwords).generate(need_cut)
image_colors = ImageColorGenerator(mk)
# 将图片颜色应用到词云中
wc_color = wordcloud.recolor(color_func=image_colors)
#设置词云图片名
wc_color.to_file('ciyun.png')
plt.imshow(wc_color)

python 获取拉勾网招聘信息(全图汇总)