淘宝爬虫之强行登录如何解决Selenium被检测到的问题?
最近遇上一些反Selenium爬虫的情况,爬虫都会碰到某些网站刚刚打开页面就被判定为:非人类行为。
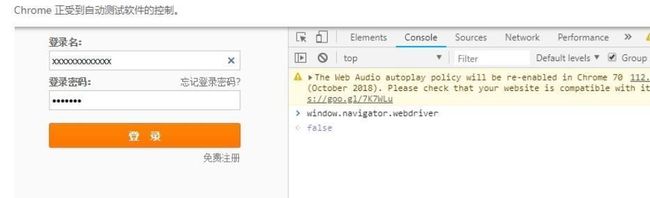
因为不少大网站有对selenium的js监测机制。比如navigator.webdriver,navigator.languages,navigator.plugins.length,
美团,大众,淘宝这些大站点都有这种技术能力。正常情况下 window.navigator.webdriver的值为undefined。

而当我们使用selenium 的时候-window.navigator.webdriver的值为True。 如下图

——-那么如何解决呢?
第一种:使用mitmproxy用中间人的方式截取服务器发送来的js,修改js里面函数的参值方式发送给服务器。相当于在browser和server之间做一层中介的拦截。不过此方法要对js非常熟悉的人才好实施。
第二种方法依旧通过selenium,不过是在服务器在第一次发送js并在本地验证的时候,做好‘第一次’的伪装,从而实现‘第一次登陆’有效。。方法简单,适合小白。
pyppeteer 加 asyncio 绕过selenium检测,实现鼠标滑动后自动登陆(代码很简单。主要熟悉异步模块及pyppeteer模块。pyppeteer模块看不懂就去看puppeteer文档,pyppeteer只是在puppeteer之上稍微包装了下而已 )。
代码如下 main.py
import asyncio
import time,random
from pyppeteer.launcher import launch # 控制模拟浏览器用
from retrying import retry #设置重试次数用的
async def main(username, pwd, url):# 定义main协程函数,
#以下使用await 可以针对耗时的操作进行挂起
browser = await launch({‘headless’: False, ‘args’: [’–no-sandbox’], }) # 启动pyppeteer 属于内存中实现交互的模拟器
page = await browser.newPage() # 启动个新的浏览器页面
await page.setUserAgent(
‘Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36’)
await page.goto(url) # 访问登录页面
# 替换淘宝在检测浏览时采集的一些参数。
# 就是在浏览器运行的时候,始终让window.navigator.webdriver=false
# navigator是windiw对象的一个属性,同时修改plugins,languages,navigator 且让
await page.evaluate('''() =>{ Object.defineProperties(navigator,{ webdriver:{ get: () => false } }) }''') #以下为插入中间js,将淘宝会为了检测浏览器而调用的js修改其结果。
await page.evaluate('''() =>{ window.navigator.chrome = { runtime: {}, }; }''')
await page.evaluate('''() =>{ Object.defineProperty(navigator, 'languages', { get: () => ['en-US', 'en'] }); }''')
await page.evaluate('''() =>{ Object.defineProperty(navigator, 'plugins', { get: () => [1, 2, 3, 4, 5,6], }); }''')
# 使用type选定页面元素,并修改其数值,用于输入账号密码,修改的速度仿人类操作,因为有个输入速度的检测机制
# 因为 pyppeteer 框架需要转换为js操作,而js和python的类型定义不同,所以写法与参数要用字典,类型导入
await page.type('.J_UserName', username, {'delay': input_time_random() - 50})
await page.type('#J_StandardPwd input', pwd, {'delay': input_time_random()})
#await page.screenshot({'path': './headless-test-result.png'}) # 截图测试
time.sleep(2)
# 检测页面是否有滑块。原理是检测页面元素。
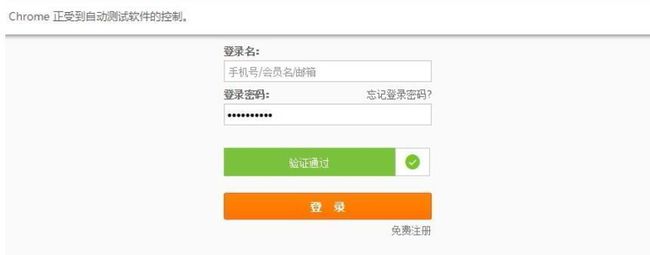
slider = await page.Jeval('#nocaptcha', 'node => node.style') # 是否有滑块
if slider:
print('当前页面出现滑块')
#await page.screenshot({'path': './headless-login-slide.png'}) # 截图测试
flag,page = await mouse_slide(page=page) #js拉动滑块过去。
if flag:
await page.keyboard.press('Enter') # 确保内容输入完毕,少数页面会自动完成按钮点击
print("print enter",flag)
await page.evaluate('''document.getElementById("J_SubmitStatic").click()''') # 如果无法通过回车键完成点击,就调用js模拟点击登录按钮。
time.sleep(2)
#cookies_list = await page.cookies()
#print(cookies_list)
await get_cookie(page) # 导出cookie 完成登陆后就可以拿着cookie玩各种各样的事情了。
else:
print("")
await page.keyboard.press('Enter')
print("print enter")
await page.evaluate('''document.getElementById("J_SubmitStatic").click()''')
await page.waitFor(20)
await page.waitForNavigation()
try:
global error # 检测是否是账号密码错误
print("error_1:",error)
error = await page.Jeval('.error', 'node => node.textContent')
print("error_2:",error)
except Exception as e:
error = None
finally:
if error:
print('确保账户安全重新入输入')
# 程序退出。
loop.close()
else:
print(page.url)
await get_cookie(page)
#time.sleep(100)
# 获取登录后cookie
async def get_cookie(page):
#res = await page.content()
cookies_list = await page.cookies()
cookies = ‘’
for cookie in cookies_list:
str_cookie = ‘{0}={1};’
str_cookie = str_cookie.format(cookie.get(‘name’), cookie.get(‘value’))
cookies += str_cookie
print(cookies)
return cookies
def retry_if_result_none(result):
return result is None
@retry(retry_on_result=retry_if_result_none,)
async def mouse_slide(page=None):
await asyncio.sleep(2)
try :
#鼠标移动到滑块,按下,滑动到头(然后延时处理),松开按键
await page.hover(’#nc_1_n1z’) # 不同场景的验证码模块能名字不同。
await page.mouse.down()
await page.mouse.move(2000, 0, {‘delay’: random.randint(1000, 2000)})
await page.mouse.up()
except Exception as e:
print(e, ‘:验证失败’)
return None,page
else:
await asyncio.sleep(2)
# 判断是否通过
slider_again = await page.Jeval(’.nc-lang-cnt’, ‘node => node.textContent’)
if slider_again != ‘验证通过’:
return None,page
else:
#await page.screenshot({‘path’: ‘./headless-slide-result.png’}) # 截图测试
print(‘验证通过’)
return 1,page
def input_time_random():
return random.randint(100, 151)
if name == ‘main’:
username = ‘xxxxxxxxx’ # 淘宝用户名
pwd = ‘xxxxxxxxxxx’ #密码
url = ‘https://login.taobao.com/member/login.jhtml?style=mini&css_style=b2b&from=b2b&full_redirect=true&redirect_url=https://login.1688.com/member/jump.htm?target=https://login.1688.com/member/marketSigninJump.htm?Done=http://login.1688.com/member/taobaoSellerLoginDispatch.htm®= http://member.1688.com/member/join/enterprise_join.htm?lead=http://login.1688.com/member/taobaoSellerLoginDispatch.htm&leadUrl=http://login.1688.com/member/’
loop = asyncio.get_event_loop() #协程,开启个无限循环的程序流程,把一些函数注册到事件循环上。当满足事件发生的时候,调用相应的协程函数。
loop.run_until_complete(main(username, pwd, url)) #将协程注册到事件循环,并启动事件循环
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116