zookeeper、hive的安装以及hive的简单应用
一、zookeeper以及hive的安装
1、首先下载安装包(我这的是zookeeper-3.4.5-cdh5.14.2.tar.gz和hive-1.1.0-cdh5.14.2.tar.gz安装包)
2、将其上传到linux系统下,并压缩文件(我放到/opt/文件夹下)
tar -zxf zookeeper-3.4.5-cdh5.14.2.tar.gz
tar -zxf hive-1.1.0-cdh5.14.2.tar.gz
3、移动并将文件改名
mv zookeeper-3.4.5-cdh5.14.2 soft/zk345
mv hive-1.1.0-cdh5.14.2 soft/hive110
4、进入对应的zookeeper中conf配置文件下
cd /opt/soft/zk345/conf
5、复制一份文件
cp zoo_sample.cfg zoo.cfg
6、修改重要配置
vi zoo.cfg
dataDir=/opt/soft/zk345/tmp\
最后一行添加
server.1=192.168.56.138:2258:3358 (你的ip加不重复的端口号)
7、配置环境变量
vi /etc/profile
最后添加
export ZOOKEEPER_HOME=/opt/soft/zk345
export PATH=$PATH:$ZOOKEEPER_HOME/bin
配置完source
source /etc/profile
8、进入hive下的配置文件
cd /opt/soft/hive110/conf
9、配置文件内容
进入文件
vi hive-site.xml
内容
hive.metastore.warehouse.dir
/usr/hive/warehouse
hive.metastore.local
false
javax.jdo.option.ConnectionURL
jdbc:mysql://192.168.56.138:3306/hive?createDatabaseIfNotExist=true //ip自己改
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
javax.jdo.option.ConnectionUserName
root
javax.jdo.option.ConnectionPassword
139129 //密码自己改
hive.server2.authentication
NONE
hive.server2.thrift.client.user
root
hive.server2.thrift.client.password
139129 //密码自己改
10、再次更新环境变量
vi /etc/profile
最后一行加入
export HIVE_HOME=/opt/soft/hive110
export PATH=$PATH:$HIVE_HOME/bin
不能忘
保存退出后source /etc/profile
11、启动hadoop
start-all.sh
输入jps命令可以看到包括jps在内5个名称
12、启动zookeeper
zkServer.sh start
成功如下图
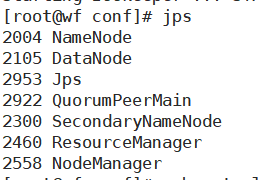
13、第一次安装需初始化hive(以后不需要)
schematool -dbType mysql -initSchema
初始化成功如下

14、启动hive
hive --service metastore
启动成功如下图

15、hive后可以输入sql语句
hive
16、也可以进入beeline输入sql语句
hiveserver2
beeline -u jdbc:hive2://192.168.56.138:10000 -n root
二、数据库举例以及外表创建
1、创建数据库
hive>create database mydemo;
2、创建表
create table classes(clss_id int,class_name string) row fromat delimited fields terminated by ',' stored as textfile;
3、插入数据
insert into classes values(1,'KB01'),(2,'KB02');
4、查看文件是否存在
!hdfs dfs -text /usr/hive/warehousse/mydemo.db/classes/000000_0;
会显示1,KBO1
2,KB02
5、外表创建
本地创建一个csv文件,把它上传到linux系统下
在linux下创建一个文件夹
hdfs dfs -mkdir /data
把csv文件上传到/data/目录下
hdfs dfs -put d1.csv /data/
创建一个外表
create external table customs(
> cust_id string,
> cust_name string,
> age int
> )
> row format delimited fields terminated by ','
> location '/data';
把它的定位定位到data下
输入select * from customs;就能查到表中的信息
6、在上一表继续添加数据
继续在本地创建一个同样的表,把里面的数据改成你要的数据
上传到hadoop上
hdfs dfs -put d2.csv /data/
输入select * from customs;就能查到表中的信息(包含添加信息)
浏览器查看地址:http://192.168.56.138:50070/explorer.html#/
内部表和外部表的区别
内部表(管理表)
HDFS中位所属数据库目录下的子文件夹
数据完全由Hive管理,删除表(元数据)会删除数据
外部表
数据保存在指定位置的HDFS路径中
Hive不完全管理数据,删除表(元数据)不会删除数据