Presto on CDH
Presto是Facebook开源出来的一个分布式SQL查询引擎,用于查询分布在一个或多个不同数据源中的大数据集。Presto是一款专为使用分布式查询而高效查询海量数据的工具,处理PB级数据。
1. 环境准备jdk,cdh集群安装(省略,需要可以参考我写的CDH集群安装文档)
2.下载presto安装包,https://prestodb.io/docs/current/installation/deployment.html
3. 解压压缩包
tar –zxvf presto-server-0.191.tar.gz
4. 进入解压目录,创建etc目录
mkdir etc
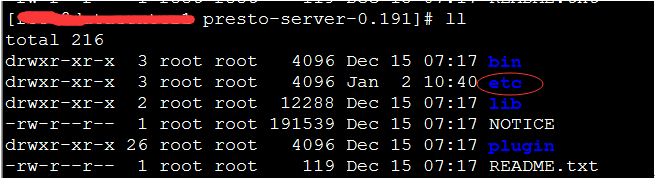
5. 进入etc 目录,编辑配置文件,catalog为创建目录:
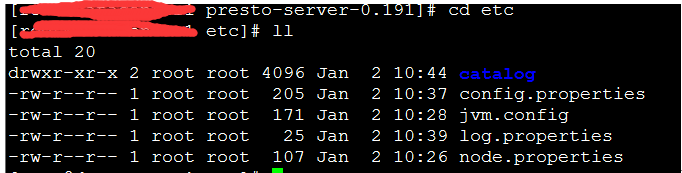
6. 在ect目录下创建配置文件
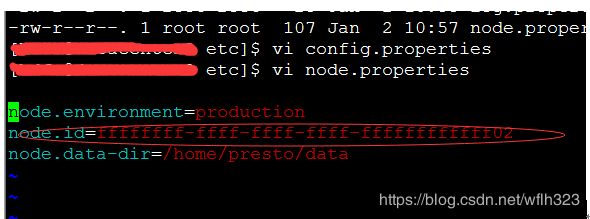
[root@data etc]# vi node.properties
node.environment=production
node.id=ffffffff-ffff-ffff-ffff-ffffffffffff01
node.data-dir=/home/presto/data
- node.environment: 集群名称。所有在同一个集群中的Presto节点必须拥有相同的集群名称。
- node.id: 每个Presto节点的唯一标示。每个节点的node.id都必须是唯一的。在Presto进行重启或者升级过程中每个节点的node.id必须保持不变。如果在一个节点上安装多个Presto实例(例如:在同一台机器上安装多个Presto节点),那么每个Presto节点必须拥有唯一的node.id。
- node.data-dir: 数据存储目录的位置(操作系统上的路径)。Presto将会把日期和数据存储在这个目录下。
[root@datacenter1 etc]# vi jvm.config
-server
-Xmx16G
-XX:+UseG1GC
-XX:G1HeapRegionSize=32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:+ExitOnOutOfMemoryError
由于OutOfMemoryError将会导致JVM处于不一致状态,所以遇到这种错误的时候我们一般的处理措施就是将dump headp中的信息(用于debugging),然后强制终止进程。
Presto会将查询编译成字节码文件,因此Presto会生成很多class,因此我们我们应该增大Perm区的大小(在Perm中主要存储class)并且要允许Jvm class unloading。
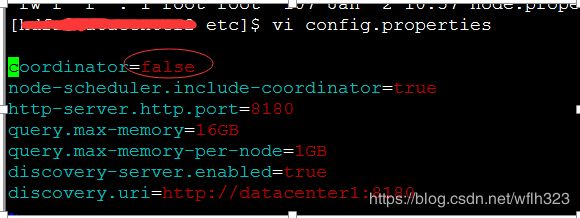
[root@data etc]# vi config.properties
coordinator=true
node-scheduler.include-coordinator=false
http-server.http.port=8180
query.max-memory=16GB
query.max-memory-per-node=1GB
discovery-server.enabled=true
discovery.uri=http://datacenter1:8180
Presto的配置文件:etc/config.properties包含了Presto server的所有配置信息。 每个Presto server既是一个coordinator也是一个worker。 但是在大型集群中,处于性能考虑,建议单独用一台机器作为 coordinator
- coordinator:指定是否运维Presto实例作为一个coordinator(接收来自客户端的查询情切管理每个查询的执行过程)。
- node-scheduler.include-coordinator:是否允许在coordinator服务中进行调度工作。对于大型的集群,在一个节点上的Presto server即作为coordinator又作为worke将会降低查询性能。因为如果一个服务器作为worker使用,那么大部分的资源都不会被worker占用,那么就不会有足够的资源进行关键任务调度、管理和监控查询执行。
- http-server.http.port:指定HTTP server的端口。Presto 使用 HTTP进行内部和外部的所有通讯。
- task.max-memory=1GB:一个单独的任务使用的最大内存 (一个查询计划的某个执行部分会在一个特定的节点上执行)。 这个配置参数限制的GROUP BY语句中的Group的数目、JOIN关联中的右关联表的大小、ORDER BY语句中的行数和一个窗口函数中处理的行数。 该参数应该根据并发查询的数量和查询的复杂度进行调整。如果该参数设置的太低,很多查询将不能执行;但是如果设置的太高将会导致JVM把内存耗光。
- discovery-server.enabled:Presto 通过Discovery 服务来找到集群中所有的节点。为了能够找到集群中所有的节点,每一个Presto实例都会在启动的时候将自己注册到discovery服务。Presto为了简化部署,并且也不想再增加一个新的服务进程,Presto coordinator 可以运行一个内嵌在coordinator 里面的Discovery 服务。这个内嵌的Discovery 服务和Presto共享HTTP server并且使用同样的端口。
- discovery.uri:Discovery server的URI。由于启用了Presto coordinator内嵌的Discovery 服务,因此这个uri就是Presto coordinator的uri。修改example.net:8080,根据你的实际环境设置该URI。注意:这个URI一定不能以“/“结尾。
[root@data etc]# vi log.properties
com.facebook.presto=INFO
进入catalog目录下,创建 hive连接器配置文件:
[root@data catalog]# vi hive.properties
connector.name=hive-hadoop2
hive.metastore.uri=thrift://xxxxx:9083
hive.config.resources=/etc/hadoop/conf/core-site.xml, /etc/hadoop/conf/hdfs-site.xml
hive.allow-drop-table=true
进入catalog目录下,创建 jmx连接器配置文件:
[root@data catalog]# vi jmx.properties
connector.name=jmx
7. scp presto到其它服务器,修改配置文件config.properties,node.properties
8. 每个节点执行bin/launcher start 启动presto程序
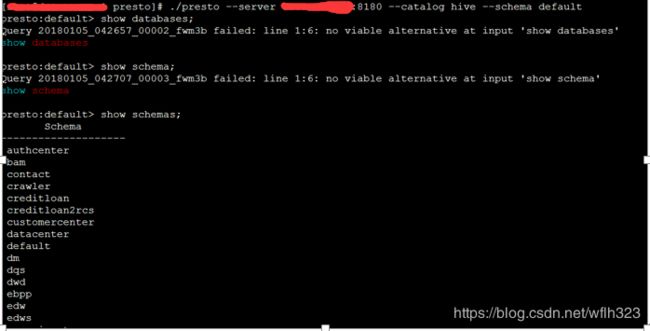
9. 下载 presto-cli-0.100-executable.jar ,重名名为 presto , 使用 chmod +x 命令设置可执行权限,然后执行:
./presto --server xxxx:8180 --catalog hive --schema default