Scala语言基础
一、语言概述
- 编程范式
-
编程范式是指计算机编程的基本风格或典范模式。常见的编程范式主要包括命令式编程和函数式编程。面向对象编程就属于命令式编程,比如C++、Java等
-
命令式语言是植根于冯·诺依曼体系的,一个命令式程序就是一个冯·诺依曼机的指令序列,给机器提供一条又一条的命令序列让其原封不动地执行
-
函数式编程,又称泛函编程,它将计算机的计算视为数学上的函数计算
-
函数编程语言最重要的基础是λ演算。典型的函数式语言包括Haskell、Erlang和Lisp等
-
一个很自然的问题是,既然已经有了命令式编程,为什么还需要函数式编程呢?
-
为什么在C++、Java等命令式编程流行了很多年以后,近些年函数式编程会迅速升温呢?
-
命令式编程涉及多线程之间的状态共享,需要锁机制实现并发控制
-
函数式编程不会在多个线程之间共享状态,不需要用锁机制,可以更好并行处理,充分利用多核CPU并行处理能力
-
Scala是一门类Java的多范式语言,它整合了面向对象编程和函数式编程的最佳特性。具体来讲:
Scala运行于Java虚拟机(JVM)之上,并且兼容现有的Java程序
Scala是一门纯粹的面向对象的语言
Scala也是一门函数式语言


二、Scala基础
2.1.1 基本数据类型
Scala的数据类型包括:Byte、Char、Short、Int、Long、Float、Double和Boolean(注意首字母大写)
和Java不同的是,在Scala中,这些类型都是“类”,并且都是包scala的成员,比如,Int的全名是scala.Int。对于字符串,Scala用java.lang.String类来表示字符串

- 算术运算符:加(+)、减(-) 、乘(*) 、除(/) 、余数(%);
- 关系运算符:大于(>)、小于(<)、等于(==)、不等于(!=)、大于等于(>=)、小于等于(<=)
- 逻辑运算符:逻辑与(&&)、逻辑或(||)、逻辑非(!);
- 位运算符:按位与(&)、按位或(|)、按位异或(^)、按位取反(~)等
- 赋值运算符:=及其与其它运算符结合的扩展赋值运算符,例如+=、%=。
在Scala中,操作符就是方法。例如,5 + 3和(5).+(3)是等价的

富包装类
- 对于基本数据类型,除了以上提到的各种操作符外,Scala还提供了许多常用运算的方法,只是这些方法不是在基本类里面定义,还是被封装到一个对应的富包装类中
- 每个基本类型都有一个对应的富包装类,例如Int有一个RichInt类、String有一个RichString类,这些类位于包scala.runtime中
- 当对一个基本数据类型的对象调用其富包装类提供的方法,Scala会自动通过隐式转换将该对象转换为对应的富包装类型,然后再调用相应的方法。例如:3 max 5
Scala有两种类型的变量:
- val:是不可变的,在声明时就必须被初始化,而且初始化以后就不能再赋值;
- var:是可变的,声明的时候需要进行初始化,初始化以后还可以再次对其赋值。
基本语法:
val 变量名:数据类型 = 初始值
var 变量名:数据类型 = 初始值


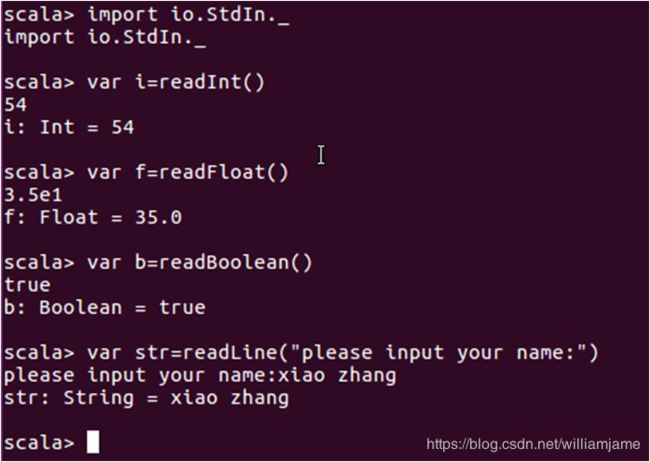
2.2 输入输出
2.2.1 控制台输入输出语句
-
从控制台读写数据方法:readInt、readDouble、readByte、readShort、readFloat、readLong、readChar readBoolean及readLine,分别对应9种基本数据类型,其中前8种方法没有参数,readLine可以不提供参数,也可以带一个字符串参数的提示
-
所有这些函数都属于对象scala.io.StdIn的方法,使用前必须导入,或者直接用全称进行调用
Tips:读取数据时看不到输入的解决办法。用-Xnojline选项禁用控制台读写库Jline,但这时又不能用箭头调用命令历史,所以还需要一个小工具rlwrap。完整命令为“rlwrap scala -Xnojline”,如果提示rlwrap 没有安装,请按提示进行安装。
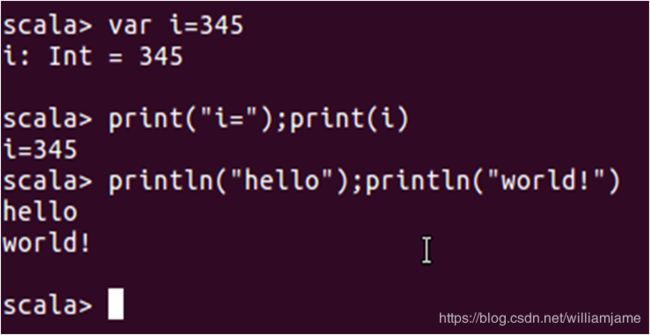
向控制台输出信息方法:
print()和println(),可以直接输出字符串或者其它数据类型,其中println在末尾自动换行。
- C语言风格格式化字符串的printf()函数
print()、println()和printf() 都在对象Predef中定义,该对象默认情况下被所有Scala程序引用,因此可以直接使用Predef对象提供的方法,而无需使用scala.Predef.的形式。
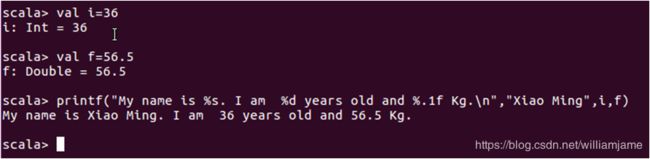
s字符串和f字符串:Scala提供的字符串插值机制,以方便在字符串字面量中直接嵌入变量的值。
基本语法:
s " …$变量名… " 或 f " …$变量名%格式化字符… "

2.2.2 读写文件
- 写入文件
Scala需要使用java.io.PrintWriter实现把数据写入到文件,PrintWriter类提供了print 和println两个写方法
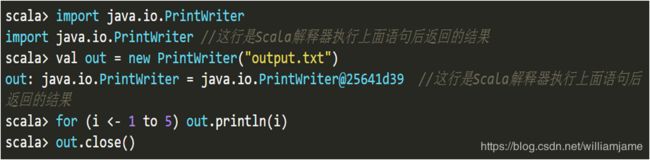
PrintWriter里路径可以是直接路径,也可以是相对路径
- 读取文件
可以使用Scala.io.Source的getLines方法实现对文件中所有行的读取
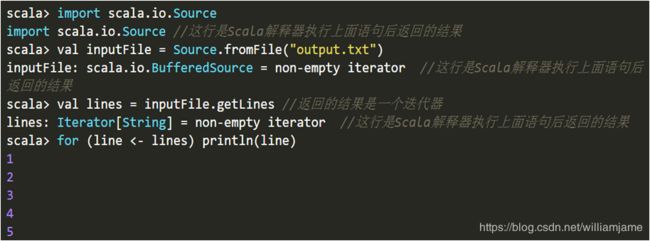
2.3 控制结构
2.3.1 if条件表达式

If(x>0) 1 else -1 相当于c或Java里的三元操作符:x>0? 1: -1
2.3.2 while循环

2.3.3 for循环

by 2 是步长
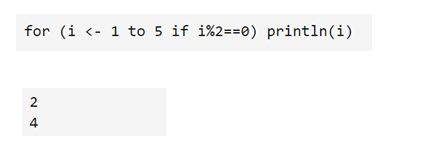
- “守卫(guard)”的表达式:过滤出一些满足条件的结果。基本语法:
for (变量 <- 表达式 if 条件表达式) 语句块
Scala也支持“多个生成器”的情形,可以用分号把它们隔开,比如:

for 推导式
-
for结构可以在每次执行的时候创造一个值,然后将包含了所有产生值的集合作为for循环表达式的结果返回,集合的类型由生成器中的集合类型确定。
for (变量 <- 表达式) yield {语句块}

2.3.4 异常处理
Scala不支持Java中的“受检查异常”(checked exception),将所有异常都当作“不受检异常”(或称为运行时异常)
Scala仍使用try-catch结构来捕获异常
import java.io.FileReader
import java.io.FileNotFoundException
import java.io.IOException
try {
val f = new FileReader("input.txt")
// 文件操作
} catch {
case ex: FileNotFoundException =>
// 文件不存在时的操作
case ex: IOException =>
// 发生I/O错误时的操作
} finally {
file.close() // 确保关闭文件
}
受检查异常和不受检查异常的区别:https://www.cnblogs.com/tjudzj/p/7053980.html
2.3.5 对循环的控制
为了提前终止整个循环或者跳到下一个循环,Scala没有break和continue关键字。Scala提供了一个Breaks类(位于包scala.util.control)。Breaks类有两个方法用于对循环结构进行控制,即breakable和break:
将需要控制的语句块作为参数放在breakable后面,然后,其内部在某个条件满足时调用break方法,程序将跳出breakable方法。


2.4 数据结构
2.4.1 数组(Array)
数组:一种可变的、可索引的、元素具有相同类型的数据集合。
Scala提供了参数化类型的通用数组类Array[T],其中T可以是任意的Scala类型,可以通过显式指定类型或者通过隐式推断来实例化一个数组。


可以不给出数组类型,Scala会自动根据提供的初始化数据来推断出数组的类型

多维数组的创建:调用Array的ofDim方法
val myMatrix = Array.ofDim[Int](3,4) //类型实际就是Array[Array[Int]]
val myCube = Array.ofDim[String](3,2,4) //类型实际是Array[Array[Array[Int]]]
可以使用多级圆括号来访问多维数组的元素,例如myMatrix(0)(1)返回第一行第二列的元素
2.4.2 元组(Tuple)
元组是对多个不同类型对象的一种简单封装。定义元组最简单的方法就是把多个元素用逗号分开并用圆括号包围起来。
使用下划线“_”加上从1开始的索引值,来访问元组的元素。
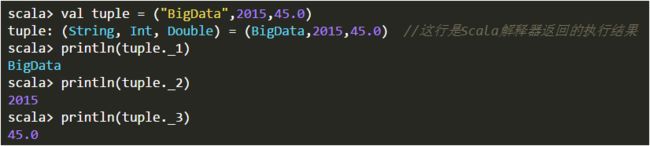
如果需要在方法里返回多个不同类型的对象,Scala可以通过返回一个元组实现。
2.4.3 容器(collection)
-
Scala提供了一套丰富的容器(collection)库,包括序列(Sequence)、集合(Set)、映射(Map)等。
-
Scala用了三个包来组织容器类,分别是scala.collection 、scala.collection.mutable和scala.collection.immutable。scala.collection包中的容器通常都具备对应的不可变实现和可变实现。
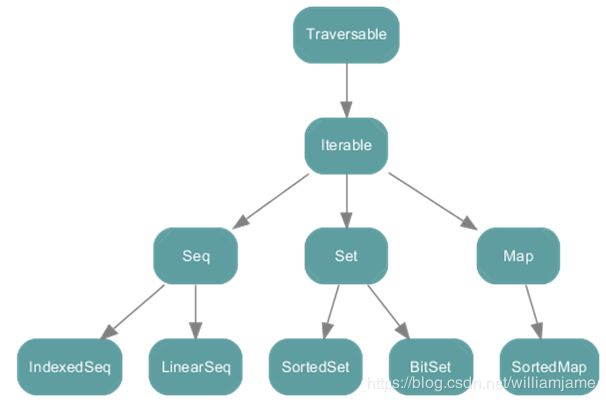
scala.collection包中容器的宏观层次结构
-
所有容器的根为Traverable特质,表示可遍历的,它为所有的容器类定义了抽象的foreach方法,该方法用于对容器元素进行遍历操作。混入Traverable特质的容器类必须给出foreach方法的具体实现。Traverable的下一级为Iterable特质,表示元素可一个个地依次迭代,该特质定义了一个抽象的iterator方法,混入该特质的容器必须实现iterator方法,返回一个迭代器(Iterator),另外,Iterable特质还给出了其从Traverable继承的foreach方法的一个默认实现,即通过迭代器进行遍历。
-
在Iterable下的继承层次包括三个特质,分别是序列(Seq)、映射(Map)和 集合(Set),这三种容器最大的区别是其元素的索引方式,序列是按照从0开始的整数进行索引的,映射是按照键值进行索引的,而集合是没有索引的。
2.4.4 序列(Sequence)
序列(Sequence): 元素可以按照特定的顺序访问的容器。序列中每个元素均带有一个从0开始计数的固定索引位置。
序列容器的根是collection.Seq特质。其具有两个子特质 LinearSeq和IndexedSeq。LinearSeq序列具有高效的 head 和 tail 操作,而IndexedSeq序列具有高效的随机存储操作。
实现了特质LinearSeq的常用序列有列表(List)和队列(Queue)。实现了特质IndexedSeq的常用序列有可变数组(ArrayBuffer)和向量(Vector)。
-
序列–列表(List)
-
列表: 一种共享相同类型的不可变的对象序列。定义在scala.collection.immutable包中
-
不同于Java的java.util.List,scala的List一旦被定义,其值就不能改变,因此声明List时必须初始化
var strList=List("BigData","Hadoop","Spark")
-
列表有头部和尾部的概念,可以分别使用head和tail方法来获取
-
head返回的是列表第一个元素的值
-
tail返回的是除第一个元素外的其它值构成的新列表,这体现出列表具有递归的链表结构
-
strList.head将返回字符串”BigData”,strList.tail返回List (“Hadoop”,“Spark”)
-
不能用new来建立List(原型:sealed abstract class List[+A] )
-
补充相同类型:对于包括List在内的所有容器类型,如果没有显式指定元素类型,Scala会自动选择所有初始值的最近公共类型来作为元素的类型。因为Scala的所有对象都来自共同的根Any,因此,原则上容器内可以容纳任意不同类型的成员。例如:val x=List(1,3.4,“Spark”)
构造列表常用的方法是通过在已有列表前端增加元素,使用的操作符为::,例如:
val otherList="Apache"::strList
执行该语句后strList保持不变,而otherList将成为一个新的列表:
List(“Apache”,“BigData”,“Hadoop”,“Spark”)
Scala还定义了一个空列表对象Nil,借助Nil,可以将多个元素用操作符::串起来初始化一个列表
val intList = 1::2::3::Nil 与 val intList = List(1,2,3)等效
注意:除了head、tail操作是常数时间O(1),其它按索引访问的操作都需要从头开始遍历,因此是线性时间复杂度O(N)。
::是向右结合的(:结尾的操作符都是向右结合)
序列–向量(vector)
Vetor可以实现所有访问操作都是常数时间。

+: 和 :+ 是Seq的方法,执行后vector本身没变
序列–ListBuffer和ArrayBuffer
ListBuffer和ArrayBuffer是List和Vector对应的可变版本,这两个序列都位于scala.collection.mutable中。
常用操作符:
+=
Insert
-=
remove

序列—Range
-
Range类:一种特殊的、带索引的不可变数字等差序列。其包含的值为从给定起点按一定步长增长(减小)到指定终点的所有数值。
-
Range可以支持创建不同数据类型的数值序列,包括Int、Long、Float、Double、Char、BigInt和BigDecimal等
(1)创建一个从1到5的数值序列,包含区间终点5,步长为1
![]()



1 to 10 by 2 等效于1.to(10).by(2),调用了Range的by方法
2.4.5 集客(Set)
-
集合(set):不重复元素的容器(collection)。
-
列表中的元素是按照插入的先后顺序来组织的,但是,“集合”中的元素并不会记录元素的插入顺序,而是以“哈希”方法对元素的值进行组织,所以,它允许你快速地找到某个元素。
-
集合包括可变集和不可变集,分别位于scala.collection.mutable包和scala.collection.immutable包,缺省情况下创建的是不可变集。
var mySet = Set("Hadoop","Spark")
mySet += "Scala"
如果要声明一个可变集,则需要提前引入scala.collection.mutable.Set
import scala.collection.mutable.Set
val myMutableSet = Set("Database","BigData")
myMutableSet += "Cloud Computing"
2.4.6 映射(Map)
- 映射(Map):一系列键值对的容器。键是唯一的,但值不一定是唯一的。可以根据键来对值进行快速的检索。
- Scala 的映射包含了可变的和不可变的两种版本,分别定义在包scala.collection.mutable 和scala.collection.immutable 里。默认情况下,Scala中使用不可变的映射。如果想使用可变映射,必须明确地导入scala.collection.mutable.Map
val university = Map("XMU" -> "Xiamen University", "THU" -> "Tsinghua University","PKU"->"Peking University")
其中,操作符”->”是定义二元组的简写方式,它会返回一个包含调用者和传入参数的二元组
如果要获取映射中的值,可以通过键来获取

对于这种访问方式,如果给定的键不存在,则会抛出异常,为此,访问前可以先调用contains方法确定键是否存在


- 迭代器(Iterator)不是一个容器,而是提供了按顺序访问容器元素的数据结构。
- 迭代器包含两个基本操作:next和hasNext。next可以返回迭代器的下一个元素,hasNext用于检测是否还有下一个元素

建议:除next和hasnext方法外,在对一个迭代器调用了某个方法后,不要再次使用该迭代器。
-
尽管构造一个迭代器与构造一个容器很类似,但迭代器并不是一个容器类,因为不能随机访问迭代器的元素,而只能按从前往后的顺序依次访问其元素。
-
实际上,迭代器的大部分方法都会改变迭代器的状态,例如,调用length方法会返回迭代器元素的个数,但是,调用结束后,迭代器已经没有元素了,再次进行相关操作会报错。
三、面向对象编程基础
作为一个运行在JVM上的语言,Scala毫无疑问首先是面向对象的语言。尽管在具体的数据处理部分,函数式编程在Scala中已成为首选方案,但在上层的架构组织上,仍然需要采用面向对象的模型,这对于大型的应用程序尤其必不可少。
3.1 类
3.1.1 类的定义
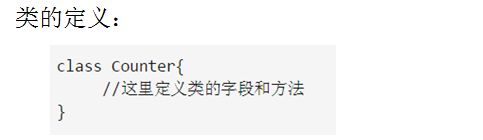
字段用val或var关键字进行定义
方法定义:def 方法名(参数列表):返回结果类型={方法体}

使用new关键字创建一个类的实例。

3.1.2 类成员的可见性
Scala类中所有成员的默认可见性为公有,任何作用域内都能直接访问公有成员。除了默认的公有可见性,Scala也提供private和protected,其中,private成员只对本类型和嵌套类型可见;protected成员对本类型和其继承类型都可见。
为了避免直接暴露public字段,建议将字段设置为private,对于private字段,Scala采用类似Java中的getter和setter方法,定义了两个成对的方法value和value_=进行读取和修改。


Scala语法中有如下规范,当编译器看到以value和value_=这种成对形式出现的方法时,它允许用户去掉下划线_,而采用类似赋值表达式的形式
![]()
如果class Counter{}中,使用 private var value =0,那么,使用scalac命令编译该程序,会出现myCounter.value=3变量无法访问的错误,因为是私有变量,不能从外部访问。
3.1.3 方法的定义
基本语法:def 方法名(参数列表):返回结果类型={方法体}
- 方法参数前不能加上val或var,所有的方法参数都是不可变类型。
- 无参数的方法定义时可以省略括号,这时调用时也不能带有括号;如果定义时带有括号,则调用时可以带括号,也可以不带括号。
- 方法名后面的圆括号()可以用大括号{}来代替。
- 如果方法只有一个参数,可以省略点号(.)而采用中缀操作符调用方法。
- 如果方法体只有一条语句,可以省略方法体两边的大括号
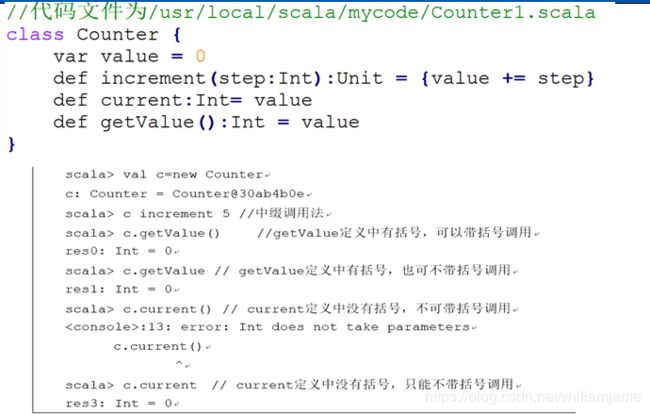
- 当方法的返回结果类型可以从最后的表达式推断出时,可以省略结果类型;
- 如果方法返回类型为Unit,可以同时省略返回结果类型和等号,但不能省略大括号。

Scala允许方法重载。只要方法的完整签名(包括方法名、参数类型列表、返回类型)是唯一的,多个方法可以使用相同的方法名。
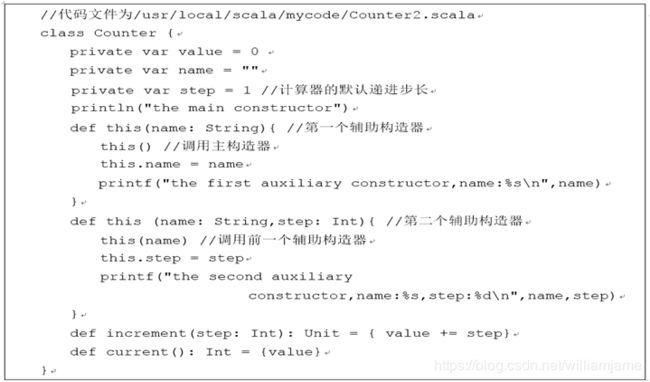
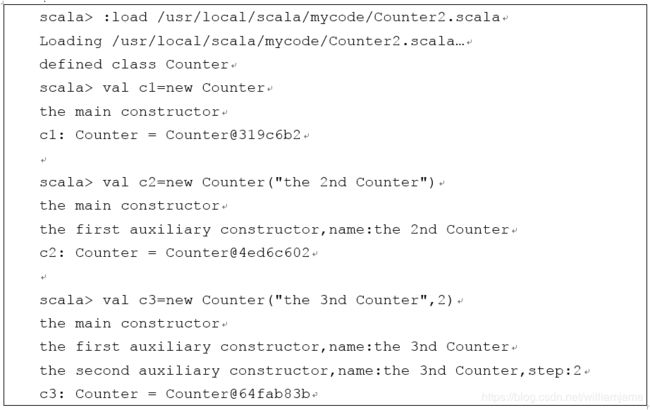
3.1.4 构造器
- Scala类的定义主体就是类的构造器,称为主构造器。在类名之后用圆括号列出主构造器的参数列表。
- 主构造器的参数前可以使用val或var关键字,Scala内部将自动为这些参数创建私有字段,并提供对应的访问方法

-
如果不希望将构造器参数成为类的字段,只需要省略关键字var或者val
-
Scala类可以包含零个或多个辅助构造器(auxiliary constructor)。辅助构造器使用this进行定义,this的返回类型为Unit。
-
每个辅助构造器的第一个表达式必须是调用一个此前已经定义的辅助构造器或主构造器,调用的形式为“this(参数列表)”
3.2 对象
3.2.1 单例对象
- Scala采用单例对象(singleton object)来实现与Java静态成员同样的功能。
- 使用object 关键字定义单例对象。

单例对象的使用与一个普通的类实例一样:

定义单例对象不是定义类型,即不能实例化Person类型的变量,这也是被称为“单例”的原因。
3.2.1 单例对象—伴生对象和孤立对象
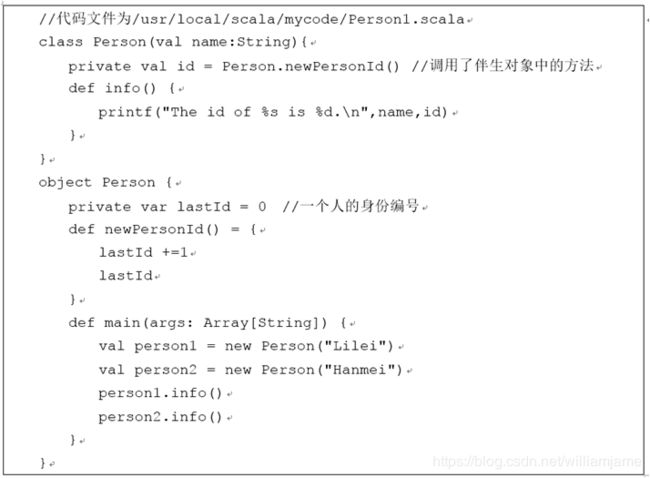
- 当一个单例对象和它的同名类一起出现时,这时的单例对象被称为这个同名类的“伴生对象” (companion object)。相应的类被称为这个单例对象的“伴生类”
- 类和它的伴生对象必须存在于同一个文件中,可以相互访问私有成员。
- 没有同名类的单例对象,被称为孤立对象(standalone object)。一般情况下,Scala程序的入口点main方法就是定义在一个孤立对象里。

-
从上面结果可以看出,伴生对象中定义的newPersonId()实际上就实现了Java中静态(static)方法的
-
Scala源代码编译后都会变成JVM字节码,实际上,在编译上面的源代码文件以后,在Scala里面的class和object在Java层面都会被合二为一,class里面的成员成了实例成员,object成员成了static成员
3.2.2 apply方法和update方法
-
思考下行代码的执行过程:
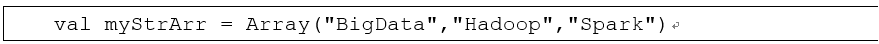
-
Scala自动调用Array类的伴生对象Array中的一个称为apply的方法,来创建一个Array对象myStrArr。
-
apply方法调用约定:用括号传递给类实例或单例对象名一个或多个参数时,Scala 会在相应的类或对象中查找方法名为apply且参数列表与传入的参数一致的方法,并用传入的参数来调用该apply方法。
例:类中的apply方法


- 伴生对象中的apply方法:将所有类的构造方法以apply方法的形式定义在伴生对象中,这样伴生对象就像生成类实例的工厂,而这些apply方法也被称为工厂方法。

为什么要设计apply方法?
- 保持对象和函数之间使用的一致性。
- 面向对象:“对象.方法” VS 数学:“函数(参数)”
- Scala中一切都是对象,包括函数也是对象。Scala中的函数既保留括号调用样式,也可以使用点号调用形式,其对应的方法名即为apply。
- Scala的对象也可以看成函数,前提是该对象提供了apply方法

update方法的调用约定:当对带有括号并包括一到若干参数的对象进行赋值时,编译器将调用对象的update方法,并将括号里的参数和等号右边的值一起作为update方法的输入参数来执行调用。

3.3 继承
3.3.1 抽象类
如果一个类包含没有实现的成员,则必须使用abstract关键词进行修饰,定义为抽象类。

关于上面的定义,说明几点:
(1)定义一个抽象类,需要使用关键字abstract。
(2)定义一个抽象类的抽象方法,也不需要关键字abstract,只要把方法体空着,不写方法体就可以。
(3)抽象类中定义的字段,只要没有给出初始化值,就表示是一个抽象字段,但是,抽象字段必须要声明类型,否则编译会报错。
3.3.2 扩展类(子类)
Scala只支持单一继承,而不支持多重继承。在类定义中使用extends关键字表示继承关系。定义子类时,需要注意:
- 重载父类的抽象成员(包括字段和方法)时,override关键字是可选的;而重载父类的非抽象成员时,override关键字是必选的。
- 只能重载val类型的字段,而不能重载var类型的字段。因为var类型本身就是可变的,所以,可以直接修改它的值,无需重载;
- 子类不仅仅可以派生自抽象类,还可以派生自非抽象类,如果某个类不希望被其它类派生出子类,则需要在类定义的class关键字前加上final关键字。
- 子类如果没有显式地指明父类,则其默认的父类为AnyRef。
建议在重载抽象成员时不省略override关键字,这样做的好处是,如果随着业务的进展,父类的抽象成员被实现了而成为非抽象成员时,子类相应成员由于没有override关键字,会出现编译错误,使用户能及时发现父类的改变,而如果子类成员原来就有override关键字,则不会有任何提醒;

编译执行后,结果为:

3.3.3 类的层级结构
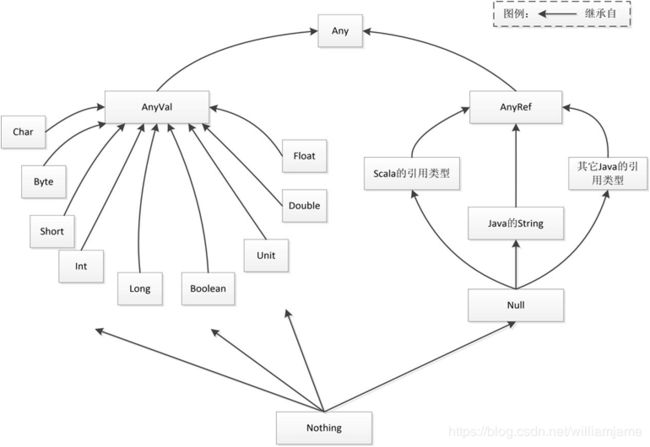
- Null是所有引用类型的子类,其唯一的实例为null,表示一个“空”对象,可以赋值给任何引用类型的变量,但不能赋值给值类型的变量。
- Nothing是所有其它类型的子类,包括Null。Nothing没有实例,主要用于异常处理函数的返回类型。
3.3.4 Option类
- Scala提供null是为了实现在JVM与其它Java库的兼容性,但是,除非明确需要与Java库进行交互,否则,Scala建议尽量避免使用这种可能带来bug的null,而改用Option类。
- Option是一个抽象类,有一个具体的子类Some和一个对象None,其中,前者表示有值的情形,后者表示没有值。
- 当方法不确定是否有对象返回时,可以让方法Option[T],其中,T为类型参数。对于这类方法,如果确实有T类型的对象需要返回,会将该对象包装成一个Some对象并返回;如果没有值需要返回,将返回None。

3.4 特质(trait)
3.4.1 特质概述
- Java中提供了接口,允许一个类实现任意数量的接口。
- Scala中没有接口的概念,而是提供了“特质(trait)”,它不仅实现了接口的功能,还具备了很多其他的特性
- Scala的特质是代码重用的基本单元,可以同时拥有抽象方法和具体方法
- Scala中,一个类只能继承自一个超类,却可以实现多个特质,从而重用特质中的方法和字段,实现了多重继承
3.4.2 特质的定义
特质的定义:使用关键字trait。

- 特质既可以包含抽象成员,也可以包含非抽象成员。包含抽象成员时,也不需要abstract关键字。
- 特质可以使用extends继承其它的特质,并且还可以继承类。
- 特质的定义体就相当于主构造器,与类不同的是,不能给特质的主构造器提供参数列表,而且也不能为特质定义辅助构造器。
3.4.3 把特质混入类中
可以使用extends或with关键字把特质混入类中。如果特质中包含抽象成员,则该类必须为这些抽象成员提供具体实现,除非该类被定义为抽象类。


当使用extends关键字混入特质时,相应的类就隐式地继承了特质的超类。如果想把特质混入到需要显式指定了父类的类里,则可以用 extends 指明待继承的父类,再用 with 混入特质。

3.4.4 把多个特质混入类中


3.5 模式匹配
3.5.1 match语句
最常见的模式匹配是match语句,match语句用在当需要从多个分支中进行选择的场景。

通配符_相当于Java中的default分支。
match结构中不需要break语句来跳出判断,Scala从前往后匹配到一个分支后,会自动跳出判断。
- case后面的表达式可以是任何类型的常量,而不要求是整数类型。

除了匹配特定的常量,还能匹配某种类型的所有值。


可以在match表达式的case中使用守卫式(guard)添加一些过滤逻辑

执行结果:

3.5.2 case类的匹配
- case类是一种特殊的类,它们经过优化以被用于模式匹配。
- 当定义一个类时,如果在class关键字前加上case关键字,则该类称为case类。
- Scala为case类自动重载了许多实用的方法,包括toString、equals和hashcode方法。
- Scala为每一个case类自动生成一个伴生对象,其包括模板代码
- 一个apply方法,因此,实例化case类无需使用new的时候关键字;
- 一个unapply方法,该方法包含一个类型为伴生类的参数,返回的结果是Option类型,对应的类型参数是N元组,N是伴生类中主构造器参数的个数。Unapply方法用于对对象进行解构操作,在case类模式匹配中,该方法被自动调用,并将待匹配的对象作为参数传递给它。
例如,假设有如下定义的一个case类:
![]()
则编译器自动生成的伴生对象是:


- 每一个case子句中的Car(…),都会自动调用Car.unapply(car),并将提取到的值与Car后面括号里的参数进行一一匹配比较。
- 第一个case和第二个case是与特定的值进行匹配。
- 第三个case由于Car后面跟的参数是变量,因此将匹配任意的参数值。

3.6 包
3.6.1 包的定义
- 为了解决程序中命名冲突问题,Scala也和Java一样采用包(package)来层次化、模块化地组织程序。
- 包可以包含类、对象和特质的定义,但是不能包含函数或变量的定义

-
为了在任意位置访问MyClass类,需要使用autodepartment.MyClass。
-
Scala的包和源文件之间并没有强制的一致层次关联关系。
-
通过在关键字package后面加大括号,可以将程序的不同部分放在不同的包里。这样可以实现包的嵌套,相应的作用域也是嵌套的

3.6.2 引用包成员
-
可以用import 子句来引用包成员,这样可以简化包成员的访问方式

-
使用通配符下划线(_)引入类或对象的所有成员

-
Scala 隐式地添加了一些引用到每个程序前面,相当于每个Scala程序都隐式地以如下代码开始:

java.lang 包定义了标准Java类;scala包定义了标准的Scala类库;Predef 对象包含了许多Scala程序中常用到的类型、方法和隐式转换的别名定义,例如,前文讲到的输出方法,可以直接写println,而不是Predef.println。
四、函数式编程基础
4.1 函数定义与使用
4.1.1 函数式编程简介
- 函数式编程将计算视为数学上的函数计算
函数成为了和普通的值一样的“头等公民”,可以像任何其他数据类型的值一样被传递和操作
- 函数式编程成为越来越流行的编程范式
大数据应用和并发需求的驱动;
纯函数的行为表现出与上下文无关的透明性和无副作用性,避免了多线程并发应用中最复杂的状态同步问题。
- Scala在架构层面上提倡上层采用面向对象编程,而底层采用函数式编程。
也就是说,函数的使用方式和其他数据类型的使用方式完全一致,可以将函数赋值给变量,也可以将函数作为参数传递给其它函数,还可以将函数作为其它函数的返回值。
4.1.2 匿名函数
定义函数最通用的方法是作为某个类或者对象的成员,这种函数被称为方法,其定义的基本语法为:
def 方法名(参数列表):结果类型={方法体}
匿名函数(函数字面量):函数变量的值


- counter的类型是“(Int) => Int”,表示具有一个整数类型参数并返回一个整数的函数;
- “{ value => value + 1 }”为函数字面量,作为counter的初始化值,“=>”前面的value是参数名,“=>”后面是具体的运算语句或表达式,

- 使用类型推断系统,可以省略函数类型


4.1.3 占位符语法
当函数的每个参数在函数字面量内仅出现一次,可以省略“=>”并用下划线“_”作为参数的占位符来简化函数字面量的表示,第一个下划线代表第一个参数,第二个下划线代表第二个参数,依此类推。

4.1.4 高阶函数
高阶函数:当一个函数包含其它函数作为其参数或者返回结果为一个函数时,该函数被称为高阶函数。
例:假设需要分别计算从一个整数到另一个整数的“连加和”、“平方和”以及“2的幂次和”。
方案一:不采用高阶函数

方案二:采用高阶函数


4.1.5 闭包
闭包:当函数的执行依赖于声明在函数外部的一个或多个变量时,则称这个函数为闭包。

闭包可以捕获闭包之外对自由变量的变化,反过来,闭包对捕获变量作出的改变在闭包之外也可见。

4.2 针对容器的操作
4.2.1 遍历操作
- Scala容器的标准遍历方法foreach


简化写法:“list foreach(i=>println(i))”或“list foreach println”
所有容器的根为Traverable特质,表示可遍历的,它为所有的容器类定义了抽象的foreach方法

4.2.2 映射操作
-
映射是指通过对容器中的元素进行某些运算来生成一个新的容器。两个典型的映射操作是map方法和flatMap方法。
-
map方法(一对一映射):将某个函数应用到集合中的每个元素,映射得到一个新的元素,map方法会返回一个与原容器类型大小都相同的新容器,只不过元素的类型可能不同。

-
flatMap方法(一对多映射):将某个函数应用到容器中的元素时,对每个元素都会返回一个容器(而不是一个元素),然后,flatMap把生成的多个容器“拍扁”成为一个容器并返回。返回的容器与原容器类型相同,但大小可能不同,其中元素的类型也可能不同。

4.2.3 过滤操作
-
过滤:遍历一个容器,从中获取满足指定条件的元素,返回一个新的容器。
-
filter方法:接受一个返回布尔值的函数f作为参数,并将f作用到每个元素上,将f返回真值的元素组成一个新容器返回。

-
filterNot方法过滤出不符合条件的元素;exists方法判断是否存在满足给定条件的元素;find方法返回第一个满足条件的元素。

4.2.4 规约操作
-
规约操作是对容器元素进行两两运算,将其“规约”为一个值。
-
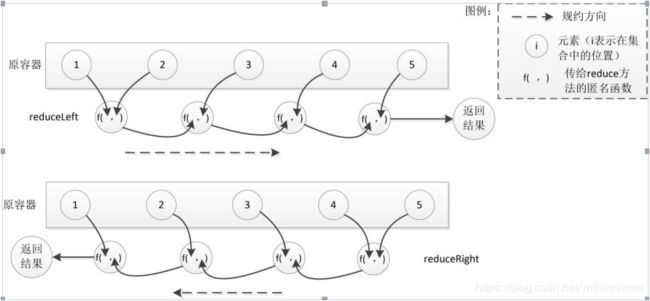
reduce方法:接受一个二元函数f作为参数,首先将f作用在某两个元素上并返回一个值,然后再将f作用在上一个返回值和容器的下一个元素上,再返回一个值,依此类推,最后容器中的所有值会被规约为一个值。

-
reduceLeft和reduceRight:前者从左到右进行遍历,后者从右到左进行遍历

- fold方法:一个双参数列表的函数,从提供的初始值开始规约。第一个参数列表接受一个规约的初始值,第二个参数列表接受与reduce中一样的二元函数参数。
- foldLeft和foldRight:前者从左到右进行遍历,后者从右到左进行遍历。
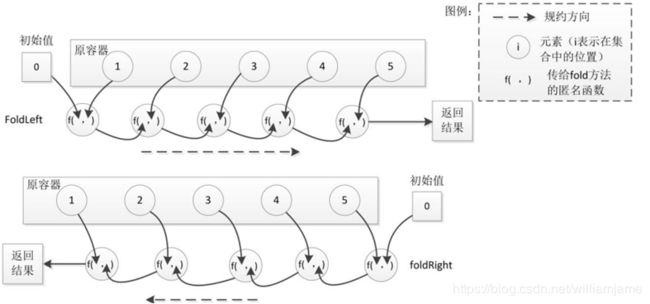

4.2.5 拆分操作
- 拆分操作是把一个容器里的元素按一定的规则分割成多个子容器。常用的拆分方法有partition、groupedBy、grouped和sliding。
- partition方法:接受一个布尔函数对容器元素进行遍历,以二元组的形式返回满足条件和不满足条件的两个集合。
- groupedBy方法:接受一个返回U类型的函数对容器元素进行遍历,将返回值相同的元素作为一个子容器,并与该相同的值构成一个键值对,最后返回的是一个映射。
- grouped和sliding方法:接受一个整型参数n,将容器拆分为多个与原容器类型相同的子容器,并返回由这些子容器构成的迭代器。其中,grouped按从左到右的方式将容器划分为多个大- 小为n的子容器(最后一个的大小可能小于n);sliding使用一个长度为n的滑动窗口,从左到右将容器截取为多个大小为n的子容器。

4.3 函数式编程实例(词频统计)
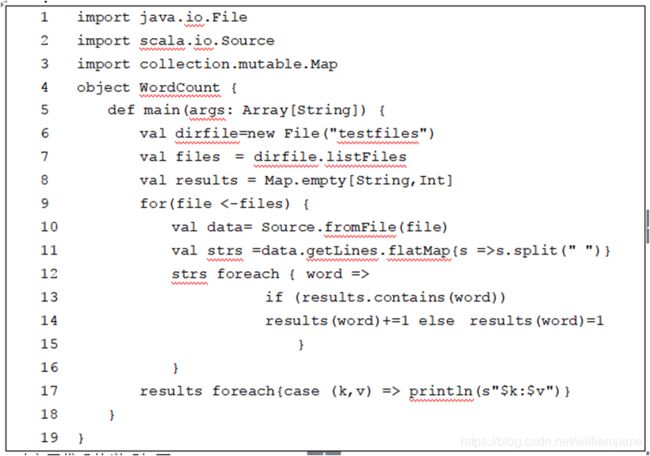
- 行1-3:导入需要的类;
- 行6:建立一个File对象,这里假设当前文件夹下有一个testfiles文件夹,且里面包含若干文本文件;
- 行7:调用File对象的listFiles方法,得到其下所有文件对象构成的数组,files的类型为Array[java.io.File];
- 行8:建立一个可变的空的映射(Map)对象results,保存统计结果。映射中的条目都是一个(key,value)键值对,其中,key是单词,value是单词出现的次数;
- 行9:通过for循环对文件对象进行循环,分别处理各个文件;
- 行10:从File对象建立Source对象(参见2.2.2节介绍),方便文件的读取;
- 行11:getLines方法返回文件各行构成的迭代器对象,类型为Iterator[String],flatMap进一步将每一行字符串拆分成单词,再返回所有这些单词构成的新字符串迭代器;
- 行12-15:对上述的字符串迭代器进行遍历,在匿名函数中,对于当前遍历到的某个单词,如果这个单词以前已经统计过,就把映射results中以该单词为key的映射条目的value增加1。如果以前没有被统计过,则为这个单词新创建一个映射条目,只需要直接对相应的key进行赋值,就实现了添加新的映射条目;
- 行17:对Map对象results进行遍历,输出统计结果。
