作者|The AI LAB
编译|VK
来源|Medium
对SparseNN模型的过拟合进行研究,并探索了多种正则化方法,如嵌入向量的max-norm/constant-norm、稀疏特征id的dropout、参数的freezing、嵌入收缩等。然而,据我们所知,在单次训练中,没有显著的减少过拟合的效果。
正则化全连接层和稀疏参数
随机梯度下降优化器使用小批量样本来更新全连接层和稀疏参数。给定一个小批量的例子,通常所有的全连接层参数都会被更新(假设没有gate或dropout),而只有一小部分稀疏参数会在正向传播中被激活,从而在反向传播中被更新。例如,假设一个稀疏特征对用户在过去一周内单击的广告id进行编码,虽然我们可能有数百万个惟一的广告id,但是在一个小型批处理中(通常是100个样本)出现的广告id的数量与基数相比非常有限。
正则化稀疏参数与全连接层参数的不同之处在于,我们需要在运行时识别小型批处理中已激活的稀疏参数,然后仅对这些参数进行正则化。
在正则化全连接层参数时需要注意的一点是,全连接层中的偏差通常不需要正则化。因此,需要识别这些偏差,并将它们自动排除在正则化之外。
L2正则化
J(W)是经验损失,||W_dense||²是全连接层稀疏参数(也称为L2正则化器)的L2范数的平方;||W_sparse||²也是如此。
参数W_i的损失L的梯度被分解为经验损失J和所谓的“权重衰减”项λ*W_i的梯度。
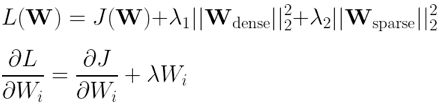
为了实现L2正则器,可通过添加lambda*W_i来更新L关于W_i的梯度。lambda在实现中称为权重衰减。
L2正则化 vs max-norm正则化
- L2正则化可同时应用于全连接层和稀疏参数,这两个参数都可能会过拟合。而max-norm仅适用于稀疏参数,因为在全连接层中,权值矩阵的向量范数没有很好的定义。
- 损失函数中的L2正则化项是可微的,等效于添加一个衰减项以惩罚梯度下降中的大权重;而max-norm打破了前向-后向传播框架,因为如果更新后的嵌入向量的范数大于1,它将嵌入向量进行归一化。
这里有几个实验是由观察到的sparseNN在多次传递训练数据时过拟合引起的。训练设置非常简单,我们只考虑一个用户特征和一个广告特征,而不考虑全连接层特征。
实验概述分为两部分:
(a)描述实验
(b)进一步的假设和检验它们的方法。
让我们以以下设置为例。
设置
- 用户端特征(SPARSE_USER_CLK_AD_IDS)和广告端特征(SPARSE_AD_OBJ_ID)。
- n_train = 1代表训练的天数,n_test = 1天代表测试的天数进行测试;在一次比较中,训练的天数和测试的天数是固定的。
- 第二天绘制测试(平均)标准化熵曲线以模拟生产条件。
Shuffling:将获得相同的结果。
对across_ts_shuffle, shuffle_all, shuffle_within_partition 进行Shuffling
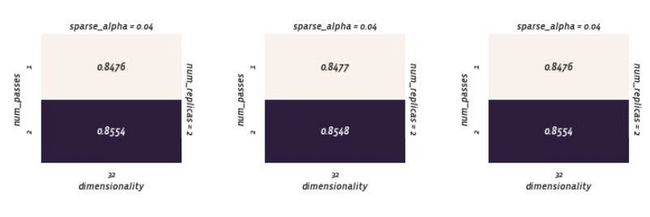
降低学习速率是逻辑回归的一种正则化方法。但这对sparseNN没用。
学习率降低,num_passes = 2
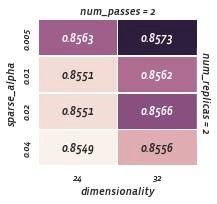
通过限制嵌入范数进行正则化(此处说明const_norm; max_norm结果相似)。这里,成本函数与所应用的正则化无关。
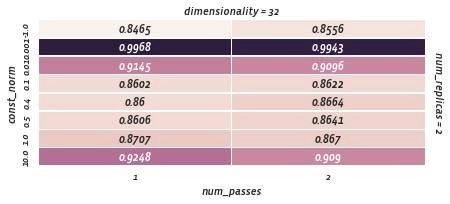
const范数
以最小的容量降低学习率:
当你尝试将尺寸减小为2且num_replicas = 1以最小化模型容量时,你会看到
num_passes=1/sparse_alpha=0.002 时为0.8711
和
num_passes = 2时为0.8703。
最后,在num_passes> 1的情况下,我们取得了成功!
但是,num_passes = 3破坏了我们短暂的快乐;我们一直试图超过0.8488,也就是当前的sparseNN参数能够生成的值(dimensionality=~32, learning rate=0.04 和 num_replicas=2).
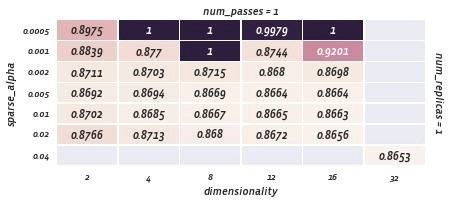
最小容量的学习率num_passes = 1
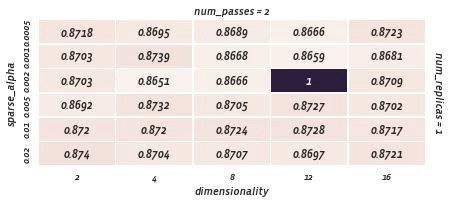
最小容量的学习率,num_passes = 2
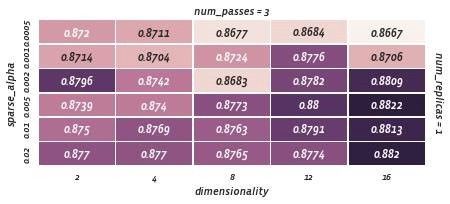
最小容量的学习率,num_passes = 3
SGD优化器
如果学习率被重置,该怎么办?对于这个实验,可以复制连续分区中一天的数据。图(a)表示num passes=1的数据,图(b)表示训练数据的多遍训练,其中num_passes=1表示连续分区上相同的数据;num_passes=2表示同一分区上的多遍训练。结果是一样的。

就dropout而言,sparseNN提供dropout_ration和sparse_dropout_ratio。稀疏的dropout将从嵌入层到全连接层的连接去掉;而全连接层的dropout会在网络中丢失连接。
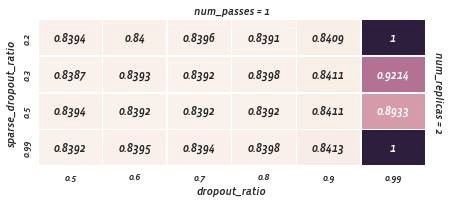
Dropout num_passes = 1

Dropout num_passes = 2
最大熵正则化器?
你可以尝试对嵌入的熵进行正则化,这样嵌入的维数可以保留,而不是记住用户-广告对。例如,在用户-电影推荐问题中,如果电影是用(动作、戏剧、情感、喜剧)来表示,它可以很好地概括,但是如果用户-电影对被记住,它在测试数据中会失败。
通过这些实验:
- 嵌入将用户与广告联系起来。当维数增加时,关于用户对广告的嵌入网络会更好(并且性能会提高,对于测试的维数没有限制)。相反,当维数较低时,广告就会与更多用户相关(并且性能较低)。
- 当哈希值较小时,即将多个广告解析为一个嵌入。他们这样做没有任何语义哈希,即完全不相关的广告被解析为相同的嵌入,因此,性能下降。也许增加维度会恢复性能。也许语义哈希将使我们解决这一难题。
- 训练数据按照每个广告看到的印象进行分层:频繁的广告、中等规模的广告、小批量的广告。。
- 频繁的广告被完美地记住,即每个用户的平均点击率由广告和用户维度来编码。对他们来说,再训练没有坏处,因为他们已经记住了。
- 中等规模的广告引起较大的方差,但它是由大数定律平均出来的。在持续的训练中,中等规模的广告可以获得更多的训练数据并得到改进。在单遍训练中,广告以初始随机性(由于初始化)记忆少量用户;在多遍训练中,广告只记住少数用户,不能推广到其他用户。
通过开始尝试使用这些ML参数进行正则化和存储,你可以成为ML的高级工程师。谁说ML很难学习?
原文链接:https://medium.com/swlh/the-s...
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/