Java集合(7)——LinkedList源码解析
类图

官方文档

LinkedList成员变量

LinkedList构造函数
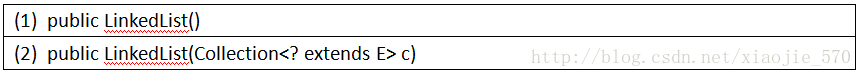
LinkedList内部类

LinkedList成员方法


LinkedList链表
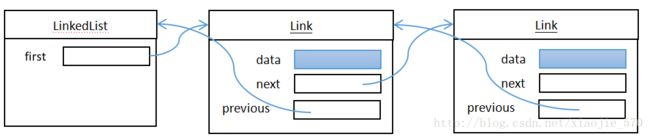
尽管数组在连续的存储位置上存放对象的引用,但链表却将每个对象存放在独立的结点中。每个结点还存放着序列中喜爱个结点的引用。在Java程序设计语言中,所有链表实际上都是双向链接的,即每个结点都存放着指向前驱结点的引用。如上图所示。
链表的各个结点类型由LinkedList类的内部类定义,该内部类为:private static class Node
源代码为:
private static class Node {
E item;
Node next;
Node prev;
Node(Node prev, E element, Node next) {
this.item = element;
this.next = next;
this.prev = prev;
}
} 源码解析:
- 该类有三个成员变量:item(本结点的元素值)、next(指向下一个结点)、prev(指向上一个结点)
- 该类有一个带参数的构造函数(指向前一个元素,当前元素值,指向下一个元素)
LinkedList成员方法源码解析
无参构造函数 public LinkedList()
public LinkedList() {
}带参数构造函数 public LinkedList(Collection c)
public LinkedList(Collection c) {
this();
addAll(c);
}源码解析:
- 调用本类的构造函数,参数是一个集合类型的形式参数,调用
addAll()方法将形参加入到新的LinkedList类型的对象中
1. private void linkFirst(E e)方法
private void linkFirst(E e) {
final Node f = first;
final Node newNode = new Node<>(null, e, f);
first = newNode;
if (f == null)
last = newNode;
else
f.prev = newNode;
size++;
modCount++;
} 源码解析:
- 功能:头插法,向链表中插入元素e
- 源码思路:
- (1)定义一个Node类型的变量f,指向链表的第一个结点。
- (2)定义一个新的Node类型的变量newNode,通过Node类的带参数构造函数将插入的元素的值放在变量中,因为头插法,所以新结点的prev域为null
- (3)更改第一个结点的值,将newNode的值赋给成员变量first
- (4)如果f(链表的第一个结点)是null,那么最后一个结点也是newNode,否则将f的prev域指向newNode
- (5)更改size的大小和modCount的大小
2. void linkLast(E e)方法
void linkLast(E e) {
final Node l = last;
final Node newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
} 源码解析:
- 功能:尾插法,向链表的末尾插入一个元素e
- 源码思路:
- (1)定义一个Node类型的变量l,l指向链表的最后一个结点
- (2)定义一个新的Node类型的变量newNode,通过Node类的带参数构造函数将插入的元素的值放在变量中,因为尾插法,所以新结点的next域为null
- (3)更改最后一个结点,将last的值赋为newNode
- (4)如果l节点为null,则链表的first值为newNode,否则将l结点的next域变为newNode。
- (5)更改size的大小和modCount的大小
3. void linkBefore(E e, Node succ) 方法
void linkBefore(E e, Node succ) {
// assert succ != null;
final Node pred = succ.prev;
final Node newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
} 源码解析:
- 功能:头插法,向链表的头部插入元素
- 源码思路:
- (1) 定义一个Node类型的变量pred,用来指向链表的头结点
- (2) 定义一个Node类型的变量newNode,用来存储新的将要插入的结点信息
- (3) 将当前链表的头结点赋值为newNode结点
- (4) 如果pred为空,即原来链表的头结点为空,表明原链表没有元素,那么刚插入的结点就是链表的第一个结点
- (5) 最后要修改链表的size大小和modCount的值
4. private E unlinkFirst(Node f) 方法
private E unlinkFirst(Node f) {
// assert f == first && f != null;
final E element = f.item;
final Node next = f.next;
f.item = null;
f.next = null; // help GC
first = next;
if (next == null)
last = null;
else
next.prev = null;
size--;
modCount++;
return element;
} 源码解析:
- 功能:将链表的第一个元素取出,并将该结点从链表中删除
- 源码思路:
- (1) 定义一个E类型的element变量,其值等于链表中第一个结点的值
- (2) 定义一个Node类型的next变量,其值等于链表中第一个结点的next域
- (3) 将链表中第一个结点的值赋值为null,并将该结点的next域赋值为null
- (4) 将next值赋值给first,如果next为空,那么链表中不再有元素,否则将链表中第一个结点删除,即赋值next的prev域为null
- (5) 更改链表的size值,更改modCount的值
- (6) 返回链表的第一个结点
5. private E unlinkLast(Node l) 方法
private E unlinkLast(Node l) {
// assert l == last && l != null;
final E element = l.item;
final Node prev = l.prev;
l.item = null;
l.prev = null; // help GC
last = prev;
if (prev == null)
first = null;
else
prev.next = null;
size--;
modCount++;
return element;
}
源码解析:
该方法与unlinkFirst方法类似,再次不赘述
6. E unlink(Node x) 方法
E unlink(Node x) {
// assert x != null;
final E element = x.item;
final Node next = x.next;
final Node prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
} 源码解析:
- 功能: 从链表中删除结点x,该方法主要是为了其他方法提供服务的。
- 源码思路:
- (1) 定义一个E类型的变量element,其值等于删除的结点的值
- (2) 定义一个Node类型的变量next,其值等于删除结点的next域的值
- (3) 定义一个Node类型的变量prev,其值等于删除结点的prev域的值
- (4) 如果prev域的值为null,即删除结点的前面没有结点,那么将next的值赋值给first
- (5) 如果prev域的值不为null,即删除结点的前面有结点,那么将next的值赋值给prev的next域,并将x结点本身的prev域赋值为null,目的是将x结点与链表前面元素断开
- (6) 如果next域为null,即删除结点的后面没有结点,那么将prev的值赋值给last
- (7) 如果next域的值不为null,即删除结点的后面有结点,那么将next变量的prev域设置为prev, 并将x结点本身的next域赋值为null,目的是将x结点域链表后面元素断开
- (8) 最后将x结点的item值域设置为null,更改链表的大小,修改modCount的值,返回删除结点的值
7. public E getFirst()方法
public E getFirst() {
final Node f = first;
if (f == null)
throw new NoSuchElementException();
return f.item;
} 源码解析:
- 功能:获取链表的第一个结点值
- 源码思路:
- (1) 定义一个Node类型的变量f,该变量的值等于first,即当前链表的头结点
- (2) 如果结点f为null,说明链表中没有元素,则抛出异常
- (3) 最后返回f的item域的值,即返回第一个结点的值
8. public E getLast()方法
public E getLast() {
final Node l = last;
if (l == null)
throw new NoSuchElementException();
return l.item;
} 源码解析:
- 功能:回去链表的最后一个结点值
- 源码思路:
- (1) 定义一个Node类型的变量l,该变量的值等于last,即当前链表的尾结点
- (2) 如果变量l的值为null,说明该链表没有尾结点,因此抛出异常
- (3) 返回变量l的item域的值,即返回最后一个结点的值
9. public E removeFirst()方法
public E removeFirst() {
final Node f = first;
if (f == null)
throw new NoSuchElementException();
return unlinkFirst(f);
} 源码解析:
- 功能:移除链表中的第一个结点
- 源码思路:
- (1) 定义一个Node类型的变量f,该变量的值等于first,即当前链表的第一个结点
- (2) 如果变量f的值为null,则抛出异常
- (3) 如果变量f的值不为null,则调用unlinkFirst方法,将f的值作为形式参数传递进去
10. public E removeLast()方法
public E removeLast() {
final Node l = last;
if (l == null)
throw new NoSuchElementException();
return unlinkLast(l);
} 源码解析:
- 功能:移除链表中的最后一个结点
- 源码思路:
- (1) 定义一个Node类型的变量l,该变量的值等于last,即当前链表的最后一个结点
- (2) 如果变量l的值等于null,则抛出异常
- (3) 如果变量的值不为null,则调用unlinkFirst方法,将l的值作为形式参数传递进去
11. public void addFirst(E e)方法
public void addFirst(E e) {
linkFirst(e);
}源码解析:
- 功能:向链表中增加一个值为e的结点
- 源码思路:
- (1) 该方法不做任何操作,只是调用linkFirst(e)方法,利用头插法将元素插入链表中
12. public void addLast(E e)方法
public void addLast(E e) {
linkLast(e);
}源码解析:
- 功能:向链表中增加一个值为e的结点
- 源码思路:
- (1) 该方法不做任何操作,只是调用linkLast(e)方法,利用尾插法将元素插入链表中
13. public boolean contains(Object o)方法
public boolean contains(Object o) {
return indexOf(o) != -1;
}源码解析:
- 功能:判断链表中是否有元素o
- 源码思路:
- (1) 该方法不做任何操作,只是调用indexOf方法,来判断indexOf方法的返回值,如果返回值为-1,说明不包含,那么contains返回false,否则返回true
14. public int size()方法
public int size() {
return size;
}源码解析:
- 功能:返回链表中的结点个数
- 源码思路:
- (1) 直接返回该类的size变量的值
15. public boolean add(E e)方法
public boolean add(E e) {
linkLast(e);
return true;
}源码解析:
- 功能:向链表中插入一个元素e,如果插入成功返回true,否则返回false
- 源码思路:
- (1)直接调用linkLast(e)方法,利用尾插法插入元素
16. public boolean remove(Object o)方法
public boolean remove(Object o) {
if (o == null) {
for (Node x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
} 源码解析:
- 功能: 从链表中移除元素o
- 源码思路:
- (1) 分两个情况判断,元素o为null,和元素o不为null,这两种情况下执行移除操作的方法是类似的
- (2) 如果元素o为null,使用for循环进行遍历,直到遍历到链表中有结点的值为null,调用unlink方法,将null元素从链表中删除
- (3) 如果元素o不为null,使用for循环进行遍历,直到遍历到链表中结点的值等于o的值(使用equals方法进行判断两个元素的值相等),调用unlink方法,将o元素从链表中删除
17. public boolean addAll(Collection c)方法
public boolean addAll(Collection c) {
return addAll(size, c);
}
源码解析:
- 功能:向链表中添加集合元素
- 源码思路:
- (1) 直接调用addAll方法执行该操作
18. public boolean addAll(int index, Collection c)方法
public boolean addAll(int index, Collection c) {
checkPositionIndex(index);
Object[] a = c.toArray();
int numNew = a.length;
if (numNew == 0)
return false;
Node pred, succ;
if (index == size) {
succ = null;
pred = last;
} else {
succ = node(index);
pred = succ.prev;
}
for (Object o : a) {
@SuppressWarnings("unchecked") E e = (E) o;
Node newNode = new Node<>(pred, e, null);
if (pred == null)
first = newNode;
else
pred.next = newNode;
pred = newNode;
}
if (succ == null) {
last = pred;
} else {
pred.next = succ;
succ.prev = pred;
}
size += numNew;
modCount++;
return true;
} 源码解析:
- 功能:向链表中插入集合元素
- 源码功能:
- (1) 首先调用checkPositionIndex方法来判断index下标是否符合范围
- (2) 定义一个Object类型的数组a,将集合c通过调用toArray方法变成数组,定义一个int类型的numNew变量,用来存储数组a的长度
- (3) 如果数组的长度为0,说明链表中没有元素,则返回false
- (4) 定义两个Node类型的变量pred(存储前驱结点)和succ(存储后继结点)
- (5) 如果index的值等于size,说明链表已经存满了,将succ设置为null,将pred设置为last链表最后一个结点
- (6) 通过增强for循环遍历数组a,定于一个Node类型的新变量newNode,通过Node构造函数,设置每个遍历元素的值,如果pred前驱的值为null,则说明该结点是链表的第一个结点,否则设置pred的next域为newNode
- (7) 如果succ的值为null,说明链表中没有元素,否则将链表的后两个元素链接在一起。
- (8) 更改链表的size值,更改modCount的值
19. public void clear()方法
public void clear() {
for (Node x = first; x != null; ) {
Node next = x.next;
x.item = null;
x.next = null;
x.prev = null;
x = next;
}
first = last = null;
size = 0;
modCount++;
} 源码解析:
- 功能:清楚链表中的所有元素
- 源码思路:
- (1) 通过for循环将链表中所有元素清除,以下操作都在for循环中进行
- (2) 定义一个Node类型的变量next,将x的next域的值赋值给next变量,目的是当前的结点要设置成null,即从链表中删除,要记录当前结点的后一个结点,不然会脱节
- (3) 将x的item域、next域和prev域都设置为null,将x的值变为next的值,这样下次循环就可以删除当前结点的下一个节点了
- (4) 最后要把first和last设置为null,将链表的size设置为0,modCount自加
20. public E get(int index)方法
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}源码解析:
- 功能: 通过index索引获取链表中结点的值
- 源码思路:
- (1) 首先调用函数检查index索引值是否符合范围
- (2) 调用node(index)方法,该方法返回Node类型的元素,再调用其item方法,返回该元素的值
21. public E set(int index, E element)方法
public E set(int index, E element) {
checkElementIndex(index);
Node x = node(index);
E oldVal = x.item;
x.item = element;
return oldVal;
} 源码解析:
- 功能:通过index索引,来修改链表中索引值为index的元素值
- 源码思路:
- (1) 首先调用函数检查index是否符合范围
- (2) 定义一个Node类型的x变量,将node(index)方法返回值赋值给该变量
- (3) 定义一个E类型的变量oldVal用来存储x变量的值,即存储更改前的元素值。
- (4) 将新值element赋值给x的item域
- (5) 最后将索引值为index的结点的旧值返回
22. public void add(int index, E element)方法
public void add(int index, E element) {
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}源码解析:
- 功能:通过index索引,向链表中索引值为index的位置添加元素element
- 源码思路:
- (1) 首先调用函数检查index是否符合范围
- (2) 如果想要插入的元素的索引值为链表的size值,说明想要插入到链表中的最后一个位置,则直接调用linkLast(element)方法
- (3) 否则调用linkBefore方法执行该操作
23. public E remove(int index)方法
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
}源码解析:
- 功能:从链表中移除下标值为index的元素
- 源码思路:
- (1) 首先调用函数检查index是否符合范围
- (2) 调用unlink方法,使用node(index)方法返回元素的结点信息,将该结点信息传递到unlink方法中
24. private boolean isElementIndex(int index)方法
private boolean isElementIndex(int index) {
return index >= 0 && index < size;
}源码解析:
- 功能:判断索引是否符合范围,该方法主要用于其他方法的功能方法
- 源码思路:
- 符合链表范围的索引值应该大于等于0,并且小于链表的size值
25. private boolean isPositionIndex(int index)方法
private boolean isPositionIndex(int index) {
return index >= 0 && index <= size;
}源码解析:
- 功能:判断索引值是否是链表的位置信息,(这里与isElementIndex不同是因为,isElementIndex下标是从0开始,而位置信息是从1开始)
- 源码思路:
- 符合链表的位置信息的值应该大于等于0,并且小于等于链表的size值
26. private String outOfBoundsMsg(int index)方法
private String outOfBoundsMsg(int index) {
return "Index: "+index+", Size: "+size;
}源码解析:
- 功能:返回index索引值出界信息
27. private void checkElementIndex(int index)方法
private void checkElementIndex(int index) {
if (!isElementIndex(index))
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}源码解析:
- 功能:判断index值是否符合范围
- 源码思路:调用isElementIndex方法,如果返回值为假则抛出异常,异常中有outOfBoundsMsg方法中的异常信息
28. private void checkPositionIndex(int index)方法
private void checkPositionIndex(int index) {
if (!isPositionIndex(index))
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}源码解析:
- 功能:判断index值是否符合位置信息
- 源码思路:调用isPositionIndex方法,如果返回值为假则抛出异常,异常中有outOfBoundsMsg方法中的异常信息
29. public int indexOf(Object o)方法
public int indexOf(Object o) {
int index = 0;
if (o == null) {
for (Node x = first; x != null; x = x.next) {
if (x.item == null)
return index;
index++;
}
} else {
for (Node x = first; x != null; x = x.next) {
if (o.equals(x.item))
return index;
index++;
}
}
return -1;
} 源码思路:
- 功能:从链表头开始遍历,返回指定结点的索引值
- 源码思路:
- (1)定义一个变量index,用来存储元素的索引值
- (2)如果指定结点为null,则for循环直到找到链表中为空的结点,返回结点的下标,否则index值自加
- (3)如果指定结点不为null,则for循环直到找到链表中结点值等于指定结点的值,返回结点的下标,否则index值自加
30 public int lastIndexOf(Object o)方法
public int lastIndexOf(Object o) {
int index = size;
if (o == null) {
for (Node x = last; x != null; x = x.prev) {
index--;
if (x.item == null)
return index;
}
} else {
for (Node x = last; x != null; x = x.prev) {
index--;
if (o.equals(x.item))
return index;
}
}
return -1;
} 源码解析:
功能:从链表尾开始遍历,返回指定结点的索引值
public E peek()方法
public E peek() {
final Node f = first;
return (f == null) ? null : f.item;
} 源码解析:
- 功能:返回链表头结点值,如果头结点是null,则返回null
源码思路:
- (1)定义一个Node类型的变量f,其值等于链表第一个结点的值(first)
(2)如果变量f的值等于null,即链表的第一个结点是null,则返回null,否则返回f的元素值
public E element()方法
public E element() {
return getFirst();
}源码解析:
- 功能:返回链表的第一个结点信息
源码思路:
直接调用getFirst方法,执行该操作
public E poll()方法
public E poll() {
final Node f = first;
return (f == null) ? null : unlinkFirst(f);
} 源码解析:
- 功能:将链表的第一个结点从链表中删除
- 源码思路:
- (1)定义一个Node类型的变量f,其值等于链表的第一个结点的值
- (2)如果链表的第一个结点值为null,则返回null,否则调用unlinkFirst方法,将链表的第一个结点从链表中删除