莫比乌斯:百度凤巢下一代广告召回系统

星标/置顶小屋,带你解锁
最萌最前沿的NLP、搜索与推荐技术
文 | 江城
编 | 夕小瑶
今天聊聊百度在最顶级的数据挖掘会议KDD2019的计算广告track上提出的query-ad匹配模型——莫比乌斯(MOBIUS)。这也是百度凤巢下一代广告召回系统的内部代号(来自论文Figure 1题注)。

这个论文来自百度研究院李平老师团队(CCL实验室),一作范淼老师也是数据挖掘领域的大牛。不得不说模型的名字很有逼格,而且如上图所示,看到论文的Figure 1,才发现百度科技园的鸟瞰图竟然就是一个莫比乌斯环!足以看出这篇论文对百度的分量了。
ps:不清楚莫比乌斯环的小伙伴请自行百度
相比于业界主流仅仅通过优化CTR预估学习query-ad相关性,本文首次在召回层模型训练时将CPM指标纳入附加的优化目标,最后的提升也是非常惊艳。下面来对这个重量级的商业广告模型一探究竟叭。
论文链接:http://t.cn/A629CGa4
公众号「夕小瑶的卖萌屋」后台回复关键词【0723】下载论文PDF
摘要
众所周知,百度是中国最大的商业化网页搜索引擎,每天服务数亿的在线用户。为了构建高效的搜索引擎,并且满足每次query需要从上亿的广告中筛选最相关的几百条的需求,百度凤巢目前的广告架构采取三层结构。当用户进行查询的时候,最上层的匹配层负责找出语义相关的候选集并输出给下一层(即广告召回);最下层的排序层更多需要考虑商业指标譬如CPM、ROI等进行排序。
CPM:即千人成本,全称Cost Per Mille。指的是广告投放过程中,平均每一千人分别听到或者看到某广告一次共需多少广告成本
ROI:即投资回报率,全称Return on Investment。指获得收益和投入成本的比值。
可以看到负责广告召回的匹配层和底部计算商业指标的排序层优化目标是不一致的,因此,会导致明显的商业收益损失,而Mobius项目就是为了解决这个问题的。相比于业界主流仅仅通过优化CTR预估来学习query-ad相关性,本文首次在召回层模型训练时将CPM指标纳入附加的优化目标。
CTR:即点击通过率,全称Click-Through-Rate。指广告的实际点击次数(严格的来说,可以是到达目标页面的数量)除以广告的展现量(Show content)
具体来说,这篇paper一方面引入主动学习(active learning)来克服神经网络离线训练阶段广告点击历史不足的问题;另一方面使用最新的近似最近邻搜索算法(Approximate Nearest Neighbor Search)来更加高效的检索广告。
Motivation
下图为百度凤巢广告系统以前的三层系统架构图。最底层为匹配层,这一层的输入是用户query和用户画像,然后通过查询扩展(query expansion)和一系列NLP技术来从十亿级的广告池中找到最相关的广告候选;最底层则基于对上一层的数千的广告候选计算出的CTR、CPM、ROI等商业指标来进行广告排序。
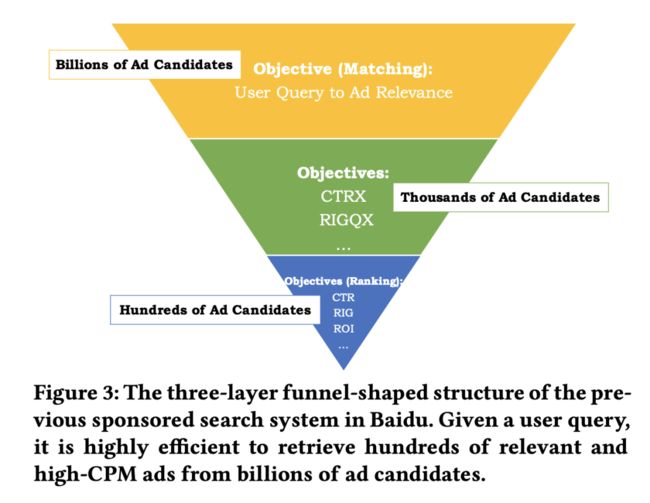
这个架构从降低响应延迟和节省计算资源的角度来说完全没有问题。但这时最上层的Matching算法与最下层的Ranking算法的目标是不一致的,因此在Ranking阶段,可能最相关的广告并不在候选集合中,即便排的再好也无济于事。
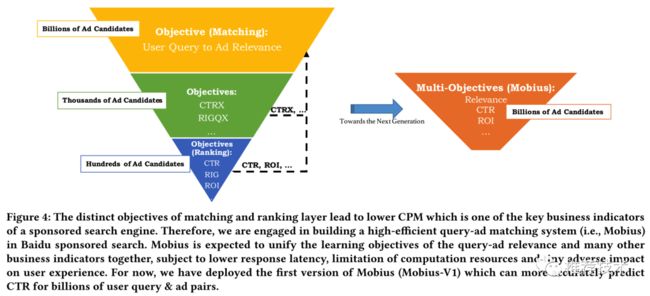
建立Mobius项目就是为了解决上述的问题,解决的方法自然是在Matching层需要同时考虑query-ad相关性以及其他方面的商业指标。也就是说,Mobius-V1有能力针对数以十亿的query-ad对进行精准的CTR预估。为了达到这个目的,这篇论文主要解决下述两个问题:
Insufficient click history。 之前ranking层的模型是基于高频的query-ad pairs进行训练的,得到的模型对高频query和ad的评分较高(即使它们的相关性可能很低);
高计算量存储量需求。 Mobius预期需要针对上亿的query-ad pairs进行多种商业指标的预估,因此自然就需要巨大的计算资源的消耗;
因此,本文的主要贡献点如下:
受主动学习的启发设计了“teature-student”框架,对训练数据做数据增强与合成,同时将原有匹配层的模型作为teacher,指导训练一个student模型,得到能够更准确针对稀疏数据进行预估的模型;
采用目前最新的ANN(Approximate Nearest Neighbor)和MIPS(Maximum Inner Product Search)算法进行更快速有效的检索;
Mobius匹配系统框架
问题描述
原有三层系统架构中的匹配层可以形式化为如下的优化目标:
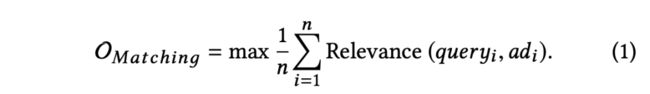
在匹配层将商业化指标引入优化目标的形式化表示:

从上面这个优化目标可以看出,问题的挑战变成了如何给十亿级query-ad pairs精准地计算CTR。
基于主动学习的CTR模型
在莫比乌斯中加入CTR目标,一个很自然的想法就是直接复用百度之前的CTR模型。在过去的6年时间里,百度这个搜索引擎排序层的CTR模型一直使用一个“特别能记”的超大规模且稀疏的DNN,包含了上百亿、千亿级别的特征。但是这个模型有一个问题,就是对于长尾和冷启动的用户或者ad,会存在比较严重的估计偏差。这一点会体现在对低频样本的预测上。
举例来说,如下图所示,Tesla Model 3和Mercedes-Benz都是出现比较高频的数据,White Rose 则不是。这里Tesla Model 3和Mercedes-Benz能够给出正确的相关度和CTR预估,但对于White Rose而言,即便其相关度很低,但是对于出现频繁的Mercedes-Benz的CTR评分可能却很高,导致了不正确的广告出现。

为了解决上述的问题,本文认为主要是怎么让模型识别出`低相关性且高ctr`的query-ad pair作为bad case。为了学习出稀疏的bad case样本,首先就需要构造出足够的bad case样本,再通过在模型的目标函数中加上额外的bad case这个目标来进行学习。因此总体的解决方案是,原来三层结构中的匹配层的相关性模型被用来当做teacher模型用来识别相关性低的query-ad对,同时指导Mobius-V1中的排序模型student在引入额外主动学习进行数据增强后的bad case样本上更好地训练。整体流程如下图所示。分为两个步骤:
数据增强
点击率模型学习
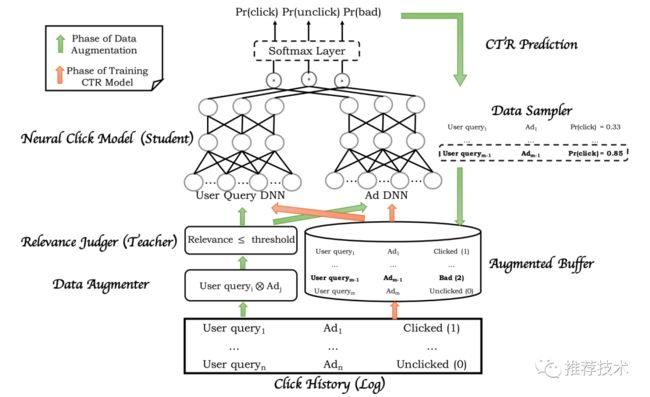
在数据增强阶段,首先,载入用户点击历史,得到query-ad对,然后拆分为query的集合和ad的集合,并且去做笛卡尔积。假设在用户的点击历史中有m个query和n个ad,那么经过数据增强后可以得到m x n个query-ad对。然后teacher模型给每一个query-ad对一个评分,用一个threshold来把低相关度的query-ad对找到。再把这些query-ad对fed给CTR模型,找到低相关度高CTR的数据作为bad case。
在模型训练阶段,点击历史中的click、unclick数据和数据增强中的bad case都被输入给模型,模型由两个子网络构成,左侧输入的是user history等信息,右侧则是广告信息,两个子网络分别输出三个长度为32的向量,然后三个向量分别去做内积,得到的三个结果输入给softmax层得到概率。
快速Ads检索查询
上面说到,三层结构是为了速度考虑,而变成Mobius系统之后,在线实时给全量上亿个广告去做点击率的估计是不现实的。
因而论文采用了ANN去做近似搜索,常规的做法是如下图左所示的策略:user query被embedding成三个向量,而ad也被embedding成三个向量,经过ANN搜索后再针对商业指标进行重排(上图中的Re-Rank by BRW模块);
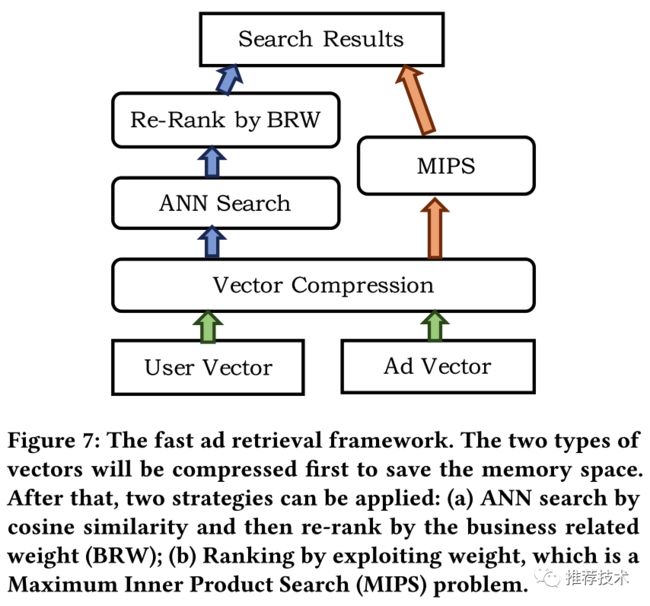
本文为了进一步节省性能,采用了右侧的MIPS方案,而在MIPS(最大内积搜索)中,将business weight调整融合到ANN的cos检索中。对于ANN和MIPS以及向量压缩的的优化内容,不在本文的介绍之内。但是大家可以预想到的是,这些优化可以使大规模搜索成为了可能。
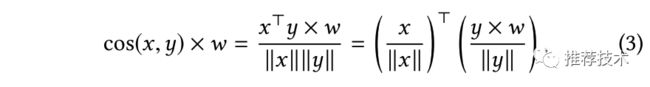
实验结论
首先是线下实验,收集了800亿训练集合100亿的测试集点击历史。对比的baseline是如下图所示的二分类CTR模型,以及包含随机标记bad case的3分类模型。

从上图可以看到,本文提出的方案可以保证AUC有些许损失的情况下,相关度大大提升。

此外,响应时间也在可控范围内:

从最后的这个表格可以看出,经过线上7天的A/B test,发现莫比乌斯系统在移动端的百度APP上提升了3.8个点的CPM,在PC端的百度搜索上CPM提升3.5个点。
文末福利
后台回复关键词【入群】
加入卖萌屋NLP/IR/Rec与求职讨论群
有顶会审稿人、大厂研究员、知乎大V和妹纸
等你来撩哦~

夕小瑶的卖萌屋
关注&星标小夕,带你解锁AI秘籍
订阅号主页下方「撩一下」有惊喜