Pima印第安人数据集上的机器学习-分类算法(根据诊断措施预测糖尿病的发病)
数据集简介
- 该数据集最初来自国家糖尿病/消化/肾脏疾病研究所。数据集的目标是基于数据集中包含的某些诊断测量来诊断性的预测 患者是否患有糖尿病。
- 从较大的数据库中选择这些实例有几个约束条件。尤其是,这里的所有患者都是Pima印第安至少21岁的女性。
- 数据集由多个医学预测变量和一个目标变量组成Outcome。预测变量包括患者的怀孕次数、BMI、胰岛素水平、年龄等。
1 加载库
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
import pandas as pd # 数据科学计算工具
import numpy as np # 数值计算工具
import matplotlib.pyplot as plt # 可视化
import seaborn as sns # matplotlib的高级API
%matplotlib inline # 在Notebook里面作图/嵌图
%config InlineBackend.figure_format = 'retina'
import warnings
warnings.filterwarnings('ignore')2 数据
【1】Pregnancies:怀孕次数
【2】Glucose:葡萄糖
【3】BloodPressure:血压 (mm Hg)
【4】SkinThickness:皮层厚度 (mm)
【5】Insulin:胰岛素 2小时血清胰岛素(mu U / ml
【6】BMI:体重指数 (体重/身高)^2
【7】DiabetesPedigreeFunction:糖尿病谱系功能
【8】Age:年龄 (岁)
【9】Outcome:类标变量 (0或1)
pima = pd.read_csv("diabetes.csv") pima.head()
# panda.head()/panda.tail() 查看Series或者DataFrame对象的小样本;显示的默认元素数量的前五个,当然我们可以传递一个自定义数字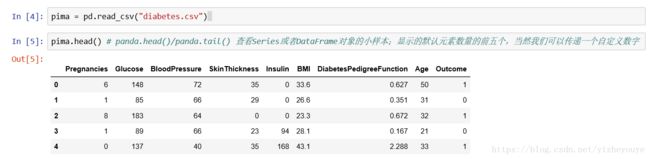
pima.shape # panda的shape形状属性,给出对象的尺寸(行数目,列数目)pima.describe()
# panda的describe描述属性,展示了每一个字段的
#【count条目统计,mean平均值,std标准值,min最小值,25%,50%中位数,75%,max最大值】

Data Visualization - 数据可视化
pima.hist(figsize=(16,14)) #查看每个字段的数据分布;figsize的参数显示的是每个子图的长和宽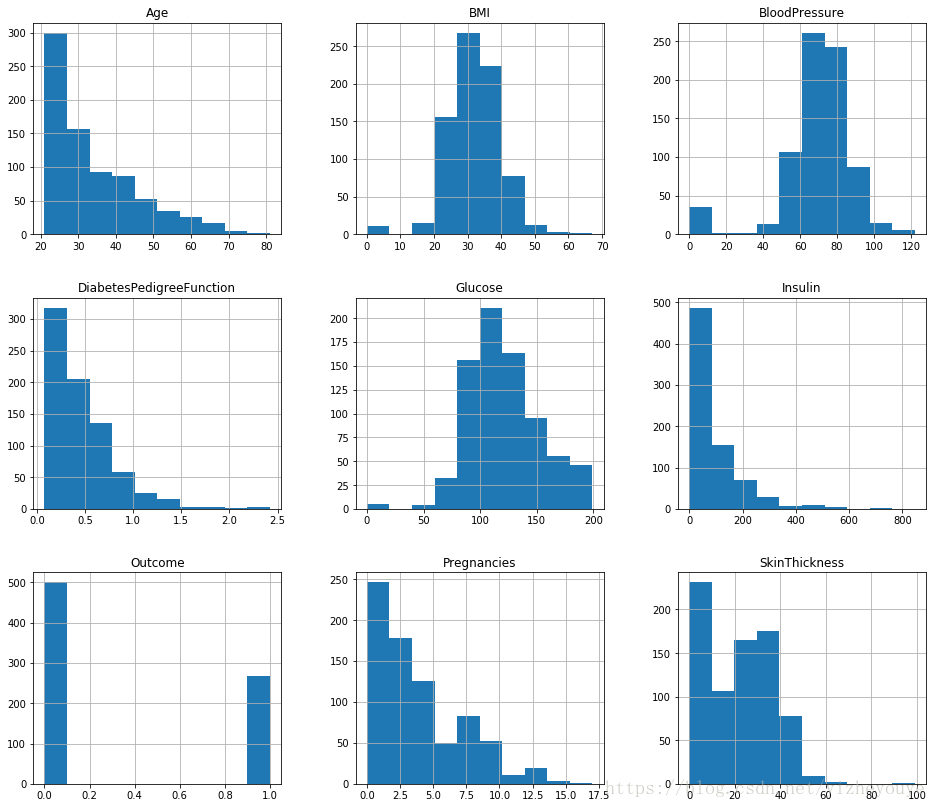
sns.pairplot(pima, hue = "Outcome")
# seaborn常用命令
#【1】set_style()是用来设置主题的,Seaborn有5个预设好的主题:darkgrid、whitegrid、dark、white、ticks,默认为darkgrid
#【2】set()通过设置参数可以用来设置背景,调色板等,更加常用
#【3】displot()为hist加强版
#【4】kdeplot()为密度曲线图
#【5】boxplot()为箱图
#【6】joinplot()联合分布图
#【7】heatmap()热点图
#【8】pairplot()多变量图,可以支持各种类型的变量分析,是特征分析很好用的工具
pima.plot(kind='box', subplots=True, layout=(3,3), sharex=False,sharey=False, figsize=(16,14))
#pandas.plot作图:数据分为Series 和 DataFrame两种类型;现释义数据为DataFrame的参数
#【0】data:DataFrame
#【1】x:label or position,default None 指数据框列的标签或位置参数
#【2】y:label or position,default None 指数据框列的标签或位置参数
#【3】kind:str(line折线图、bar条形图、barh横向条形图、hist柱状图、
# box箱线图、kde Kernel的密度估计图,主要对柱状图添加Kernel概率密度线、
# density same as “kde”、area区域图、pie饼图、scatter散点图、hexbin)
#【4】subplots:boolean,default False,为每一列单独画一个子图
#【5】sharex:boolean,default True if ax is None else False
#【6】sharey:boolean,default False
#【7】loglog:boolean,default False,x轴/y轴同时使用log刻度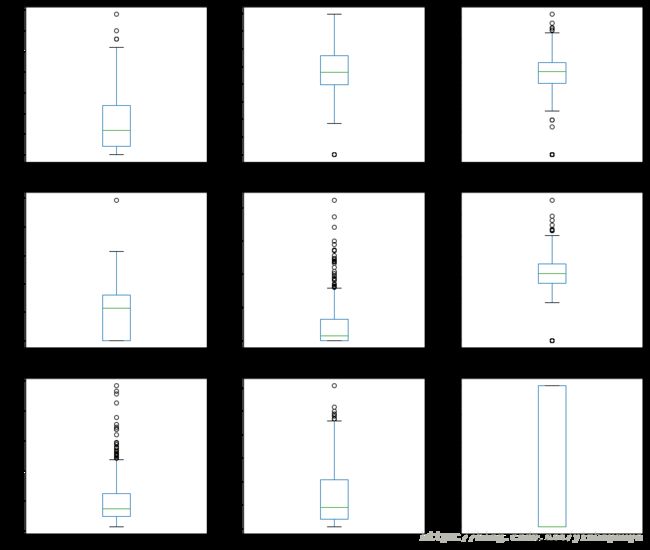
column_x = pima.columns[0:len(pima.columns) - 1] # 选择特征列,去掉目标列column_x # 显示所有特征列信息
corr = pima[pima.columns].corr() # 计算变量的相关系数,得到一个N * N的矩阵plt.subplots(figsize=(14,12)) # 可以先试用plt设置画布的大小,然后在作图,修改
sns.heatmap(corr, annot = True) # 使用热度图可视化这个相关系数矩阵
4 Feature Extraction 特征提取
# 导入和特征选择相关的包
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2X = pima.iloc[:, 0:8] # 特征列 0-7列,不含第8列
Y = pima.iloc[:, 8] # 目标列为第8列
select_top_4 = SelectKBest(score_func=chi2, k =4) # 通过卡方检验选择4个得分最高的特征
# SelectKBest() 只保留K个最高分的特征
# SelectPercentile() 只保留用户指定百分比的最高得分的特征
# 使用常见的单变量统计检验:假正率SelectFpr,错误发现率SelectFdr,或者总体错误率SelectFwe
# GenericUnivariateSelect通过结构化策略进行特征选择,通过超参数搜索估计器进行特征选择
# SelectKBest()和SelectPercentile()能够返回特征评价的得分和P值
#
# sklearn.feature_selection.SelectPercentile(score_func=, percentile=10)
# sklearn.feature_selection.SelectKBest(score_func=, k=10)
# 其中的参数score_func有以下选项:
#【1】回归:f_regression:相关系数,计算每个变量与目标变量的相关系数,然后计算出F值和P值
# mutual_info_regression:互信息,互信息度量X和Y共享的信息:
# 它度量知道这两个变量其中一个,对另一个不确定度减少的程度。
#【2】分类:chi2:卡方检验
# f_classif:方差分析,计算方差分析(ANOVA)的F值(组间均方/组内均方);
# mutual_info_classif:互信息,互信息方法可以捕捉任何一种统计依赖,但是作为非参数方法,
# 需要更多的样本进行准确的估计。fit = select_top_4.fit(X, Y) # 获取特征信息和目标值信息
features = fit.transform(X) # 特征转换features[0:5] #新特征列
pima.head()
# 因此,表现最佳的特征是:Glucose-葡萄糖、Insulin-胰岛素、BMI指数、Age-年龄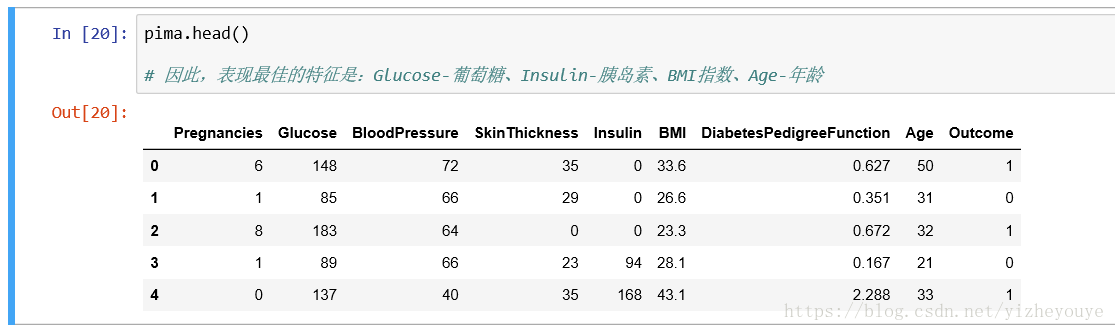
X_features = pd.DataFrame(data = features, columns=["Glucose","Insulin","BMI","Age"]) # 构造新特征DataFrameX_features.head()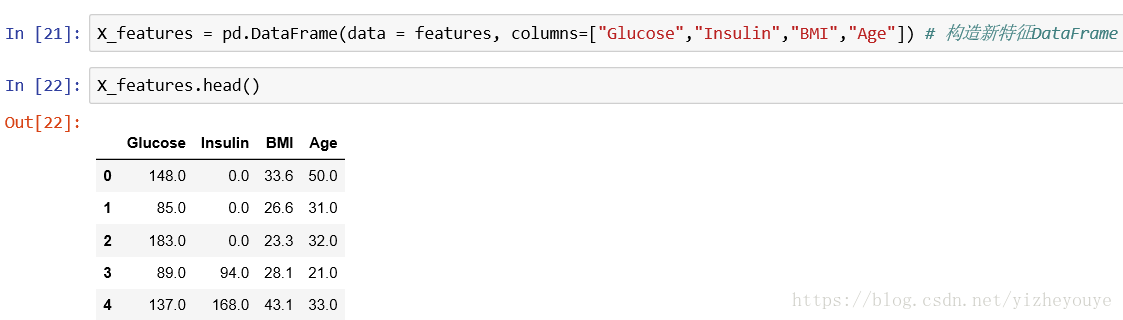
5 Standardization - 标准化
它将属性值更改为 均值为0,标准差为1 的 高斯分布.
当算法期望输入特征处于高斯分布时,它非常有用
from sklearn.preprocessing import StandardScalerrescaledX = StandardScaler().fit_transform(X_features) # 通过sklearn的preprocessing数据预处理中StandardScaler特征缩放 标准化特征信息X = pd.DataFrame(data = rescaledX, columns = X_features.columns) # 构建新特征DataFrameX.head()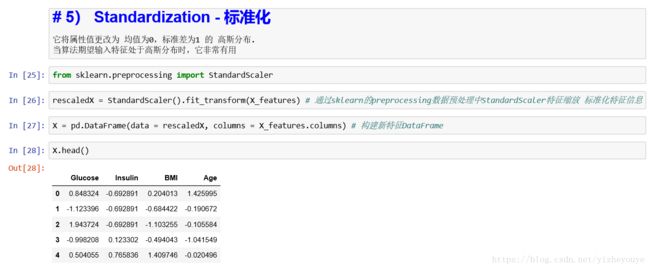
6 机器学习 - 构建二分类算法模型
from sklearn.model_selection import train_test_split
# 切分数据集为:特征训练集、特征测试集、目标训练集、目标测试集
X_train,X_test,Y_train,Y_test = train_test_split(X,Y, random_state = 22, test_size = 0.2)from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LogisticRegression
from sklearn.naive_bayes import GaussianNB
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import SVCmodels = []
models.append(("LR", LogisticRegression())) #逻辑回归
models.append(("NB", GaussianNB())) # 高斯朴素贝叶斯
models.append(("KNN", KNeighborsClassifier())) #K近邻分类
models.append(("DT", DecisionTreeClassifier())) #决策树分类
models.append(("SVM", SVC())) # 支持向量机分类results = []
names = []
for name, model in models:
kflod = KFold(n_splits=10, random_state=22)
cv_result = cross_val_score(model, X_train,Y_train, cv = kflod,scoring="accuracy")
names.append(name)
results.append(cv_result)
for i in range(len(names)):
print(names[i], results[i].mean)基于PCA和网格搜索SVM参数
# 【1】 Applying Kernel PCA
from sklearn.decomposition import KernelPCA
kpca = KernelPCA(n_components = 2, kernel = 'rbf')
X_train_pca = kpca.fit_transform(X_train)
X_test_pca = kpca.transform(X_test)plt.figure(figsize=(10,8))
plt.scatter(X_train_pca[:,0], X_train_pca[:,1],c=Y_train,cmap='plasma')
plt.xlabel("First principal component")
plt.ylabel("Second principal component")
# 【2】SVC
from sklearn.svm import SVC
from sklearn.metrics import classification_report, confusion_matrix
classifier = SVC(kernel = 'rbf')
classifier.fit(X_train_pca, Y_train)
# 使用SVC预测生存
y_pred = classifier.predict(X_test_pca)
cm = confusion_matrix(Y_test, y_pred)
cm
print(classification_report(Y_test, y_pred))# 使用 网格搜索 来提高模型
from sklearn.model_selection import GridSearchCV
param_grid = {'C':[0.1, 1, 10, 100], 'gamma':[1, 0.1, 0.01, 0.001]}
grid = GridSearchCV(SVC(),param_grid,refit=True,verbose = 2)
grid.fit(X_train_pca, Y_train)
# 预测
grid_predictions = grid.predict(X_test_pca)
# 分类报告
print(classification_report(Y_test,grid_predictions))7 可视化结果
ax = sns.boxplot(data = results)
ax.set_xticklabels(names)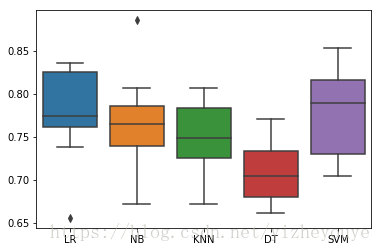
8 使用测试数据预测
# 使用逻辑回归预测
lr = LogisticRegression() # LR模型构建
lr.fit(X_train, Y_train) #
predictions = lr.predict(X_test) # 使用测试值预测from sklearn.metrics import accuracy_score
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrixprint(accuracy_score(Y_test, predictions)) # 打印评估指标(分类准确率)print(classification_report(Y_test,predictions)) conf = confusion_matrix(Y_test, predictions) # 混淆矩阵label = ["0","1"] #
sns.heatmap(conf, annot = True, xticklabels=label, yticklabels=label)