Vue源码之模板编译原理
目录
- 模板编译整体流程
- 解析器——AST
- HTML解析器
- 文本解析器
- 过滤器解析器
- 优化器
- 代码生成器
模板编译整体流程
在Vue中我们有三种方式来创建HTML
- 模板
- 手动写渲染函数
- JSX
渲染函数是最原始的方法,而模板最终会通过编译转换陈渲染函数。渲染函数执行后,会得到一份vnode用来渲染真实DOM。所以,模板编译其实是配合虚拟DOM进行渲染,想详细了解虚拟DOM,可以参考Vue中的虚拟DOM
先看下模板到真正用户看到的界面过程中经历了什么:
模板———>模板编译——>渲染函数——>vnode——>用于界面
vue.js提供了模板语法,允许我们声明式的描述状态和DOM之间的绑定关系。
将模板编译为渲染函数,就是模板编译要做的事,模板编译可以分为三个阶段:
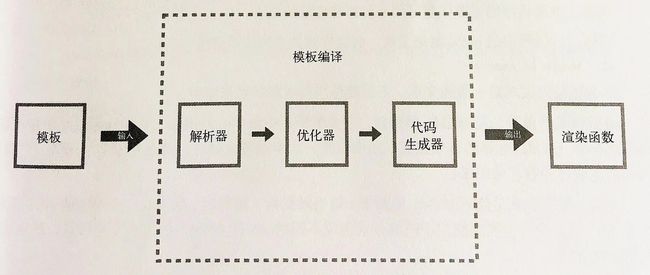
- 将模板解析为AST(抽象语法树)—— 解析器
- 遍历AST标记静态节点 —— 优化器
- 使用AST生成渲染函数 —— 代码生成器
关于模板编译的源码可以在vue-template-compiler包中查看。
解析器——AST
解析器做的事情就是:将模板解析成AST
那么AST是什么?
其实 AST 和 Vnode 类似,都是使用JavaScript对象来描述节点。更准确的说,一个用对象来描述的节点树就是 AST
DOM
<div>
<p>{{name}}</p>
</div>
转换成AST
{
tag: 'div',
type: 1,
staticRoot: false,
static: false,
plain: true, // 标记节点有没有属性
parent: undefined,
attrList: [],
attrMap: {},
children: [
{
tag: 'p',
type: 1,
staticRoot: false,
static: false,
plain: true,
parent: { tag: "div", ...},
attrList: [],
attrMap: {},
children: [
{
type: 2,
text: '{{name}}',
static: false,
expression: "_s(name)"
}
]
}
]
}
解析器分为几个子解析器
- HTML解析器
- 文本解析器 —— 解析带变量的文本
- 过滤器解析器
HTML解析器
例如:
<div>
<p>我是 AST</p>
</div>
解析HTML模板是一个循环的过程,每轮循环都通过正则匹配截取一小段字符串,然后重复以上过程,直到变成一个空字符串。
整体逻辑
function parseHTML(html, options) {
// 变量定义...
while (html) {
last = html;
if (!lastTag || !isPlainTextElement(lastTag)) {
// 父元素为正常元素的处理逻辑
// 根据`<`及出现的位置来判断html是文本还是标签类
var textEnd = html.indexOf('<');
if (textEnd === 0) {
// 注释Comment
if (comment.test(html)) {
var commentEnd = html.indexOf('-->');
continue
}
// 条件注释
if (conditionalComment.test(html)) {
var conditionalEnd = html.indexOf(']>');
continue
}
// Doctype:
if (html.match(doctype)) {
continue
}
// 结束标签:
if (html.match(endTag)) {
continue
}
// 开始标签:
if (parseStartTag()) {
continue
}
var text = (void 0), rest = (void 0), next = (void 0);
if (textEnd >= 0) {
// 解析文本
rest = html.slice(textEnd);
// ...
text = html.substring(0, textEnd);
}
if (textEnd < 0) {
// 纯文本
text = html;
}
if (options.chars && text) {
options.chars(text);
}
} else {
// 父元素为纯文本内容(script/style)的处理逻辑
// 会被当做文本来处理,只需要将文本截取出来并触发钩子函数charts()即可
var stackedTag = lastTag.toLowerCase();
var reStackedTag = reCache[stackedTag] || (reCache[stackedTag] = new RegExp('([\\s\\S]*?)( + stackedTag + '[^>]*>)', 'i'));
var rest = html.replace(reStackedTag, function (all, text) {
endTagLength = endTag.length;
if (options.chars) {
options.chars(text);
}
return ''
});
html = rest;
options.end(stackedTag);
}
}
}
函数parseHTML(html, options)接受两个参数——模板和选项,通过循环截取解析,根据解析到不同的内容,调用选项中不同的钩子函数构建AST节点。
parseHTML(template, {
start (tag, attrs, unary) {
// 每当解析到标签的开始位置时,触发该函数‘
// unary标记是否为自闭合标签
},
end(){
// 每当解析到标签的结束位置,触发该函数
},
charts(text) {
// 解析到文本时,触发
},
comemnt() {
// 解析到注释时,触发
}
})
HTML解析器拿到模板字符串,从前向后解析,解析到开始标签如我是 AST 、结束标签
在start钩子函数中构建元素类型的AST节点;在charts钩子函数中构建文本类型的AST节点;在comment()钩子函数中构建注释类型的节点。
function createASTElement (
tag,
attrs,
parent
) {
return {
type: 1,
tag: tag,
attrsList: attrs,
attrsMap: makeAttrsMap(attrs),
rawAttrsMap: {},
parent: parent,
children: []
}
}
parseHTML(template, {
start(tag,attrs,unary){
// 标签
var element = createASTElement(tag, attrs, currentParent);
},
charts(text) {
// 文本
var element = {type: 3, text}
},
comemnt() {
// 注释
var element = {type: 3, text, isComemnt: true}
}
})
建立层级关系
在解析HTML时,节点被拉平了,没有层级关系,我们通过一个栈(stack)来记录DOM的层级关系
有了这个栈,我们可以很快找到节点的父元素,还可以检测标签是否正确闭合。
逻辑:每解析到开始标签时,就将此标签推进栈中,每解析到结束标签时,就从栈里面弹出来一个,所以栈中的最后一项就是父元素。
如当我们解析到div的结束标签时,这时就应该将栈中的div标签弹出,若从栈顶的元素却是p,则说明p标签没有正确的闭合。
文本解析器
文本解析器解析带变量的文本
Hello {{name}}
通过正则表达式匹配代码中的文本,解析的结果都放入一个数组中
tokens = ['"Hello"','_s(name)']
最后合并成字符串,用+连接
'"Hello"'+'_s(name)'
优化器
优化器的作用是在AST中找出静态子树并打标记。
标记静态节点的好处:
- 每次重新渲染,不需要为静态子树创建新节点
- 可以跳过虚拟DOM中patching过程
优化器主要干了两件事:
- 在AST中找出所有静态节点并打标记
- 在AST中找出所有静态根节点并打标记
AST中分别用 static 和 staticRoot 属性来标记节点是否为静态节点和静态根节点。
- 静态节点:不会发生变化的节点
- 静态根节点:它的子节点都是静态节点,它的父级是动态节点。
判断静态节点函数:
function isStatic (node) {
if (node.type === 2) { // 带变量的文本
return false
}
if (node.type === 3) { // text
return true
}
return !!(node.pre || (
!node.hasBindings && // no dynamic bindings
!node.if && !node.for && // not v-if or v-for or v-else
!isBuiltInTag(node.tag) && // not a built-in
isPlatformReservedTag(node.tag) && // not a component
!isDirectChildOfTemplateFor(node) &&
Object.keys(node).every(isStaticKey)
))
}
判断一个节点是否为静态节点,然后通过递归的方式来判断其子节点。
我们不得不考虑,在循环的过程中,根据子节点是否静态,来重新决定父节点是否是静态节点。
function markStatic (node) {
node.static = isStatic(node);
if (node.type === 1) {
for (var i = 0, l = node.children.length; i < l; i++) {
var child = node.children[i];
markStatic(child);
if (!child.static) {
node.static = false;
}
}
}
}
静态根节点:从根节点开始遍历,从上到下,找到第一个静态节点,其一定是静态根节点。因为静态节点的子节点必然是静态节点。
function markStaticRoots (node, isInFor) {
if (node.type === 1) {
if (node.static || node.once) {
node.staticInFor = isInFor;
}
// For a node to qualify as a static root, it should have children that
// are not just static text. Otherwise the cost of hoisting out will
// outweigh the benefits and it's better off to just always render it fresh.
if (node.static && node.children.length && !(
node.children.length === 1 &&
node.children[0].type === 3
)) {
node.staticRoot = true;
return
} else {
node.staticRoot = false;
}
if (node.children) {
for (var i = 0, l = node.children.length; i < l; i++) {
markStaticRoots(node.children[i], isInFor || !!node.for);
}
}
}
}
有两种特殊的情况,不会被标记为静态根节点
- 根节点只有一个文本节点
- 一个没有子节点的静态节点
这两种情况,优化成本大于收益。
代码生成器
生成器的作用是将AST转换成渲染函数中的内容,这个内容也叫代码字符串。
代码字符串被包装进渲染函数,执行渲染函数后,可以得到一份vnode
代码字符串:
'with(this){return _c('div',{attr:{"id":"el"}},[_v("hello"+ _s(name))])}'
//格式化之后
with(this) {
return _c(
"div",
{attrs:{"id":"el"}},
[_v("Hello"+_s(name))]
)
}
渲染函数之所以可以生成vnode,是因为代码字符串中包含了很多函数调用。_c是createElement的别名,渲染函数其实是执行了createElement,而createElement可以创建一个vnode。
生成代码字符串
这是一个自上而下递归AST节点的过程。
每处理一个AST节点,就会生成一个对应类型的代码字符串,进行嵌套。
- 元素AST节点 —— _c(, , )
- 文本AST节点 —— _v(“Hello”+_s(name))
- 注释节点 —— _e(text)
如下模板
<div id="el">
<div>
<p>Hello {{name}}</p>
</div>
</div>
这里省略生成的AST,则最后生成的嵌套字符串是这样:
_c("div",{attrs:{"id":"el"}},[_c("div",[_c("p",[_v("Hello"+_s(name))])])])
递归结束时,将这段代码包裹在with语句
`with(this){return ${code}}`
最后将代码字符串包裹在render中。
const str = `with(this){return ${code}}`
const render = new Function(str)
render()